本篇文章主要讲解数据结构中的二叉搜索树(BST,Binary Search Tree)
目录
[1 二叉搜索树的概念](#1 二叉搜索树的概念)
[2 二叉搜索树的性能](#2 二叉搜索树的性能)
[3 二叉搜索树的增删查改(不同值的 BST)](#3 二叉搜索树的增删查改(不同值的 BST))
[1) 二叉搜索树的结构](#1) 二叉搜索树的结构)
[(1) 二叉搜索树的节点](#(1) 二叉搜索树的节点)
[(2) 二叉搜索树的结构](#(2) 二叉搜索树的结构)
[2) 二叉搜索树的插入](#2) 二叉搜索树的插入)
[3) 二叉搜索树的查找](#3) 二叉搜索树的查找)
[4) 二叉搜索树的删除](#4) 二叉搜索树的删除)
[(1) 要删除的节点左右孩子都为空](#(1) 要删除的节点左右孩子都为空)
[(2) 要删除的节点左孩子为空,但是右孩子不为空](#(2) 要删除的节点左孩子为空,但是右孩子不为空)
[(3) 要删除的节点右孩子为空,但左孩子不为空](#(3) 要删除的节点右孩子为空,但左孩子不为空)
[(4) 要删除的节点左右孩子都不为空](#(4) 要删除的节点左右孩子都不为空)
[(5) 代码实现](#(5) 代码实现)
[4 二叉搜索树的 key-value 场景](#4 二叉搜索树的 key-value 场景)
[1) key-value 二叉搜索树的存在意义](#1) key-value 二叉搜索树的存在意义)
[2) key-value 二叉搜索树的实现](#2) key-value 二叉搜索树的实现)
[3) key-value BST 代码](#3) key-value BST 代码)
[5 总结](#5 总结)
1 二叉搜索树的概念
二叉搜索树,英文名称叫做 Binary Search Tree,简称为BST。其是二叉树的一种,其要么是一棵空树,要么是一棵具有下列性质的二叉树:
1) 若根节点的左子树不为空,那么左子树所有节点的值都小于或者等于根节点的值
2) 若根节点的右子树不为空,那么右子树所有节点的值都大于或者等于根节点的值
3) 根节点的左右子树又是一棵二叉搜索树
比如下面的两棵树就是二叉搜索树:
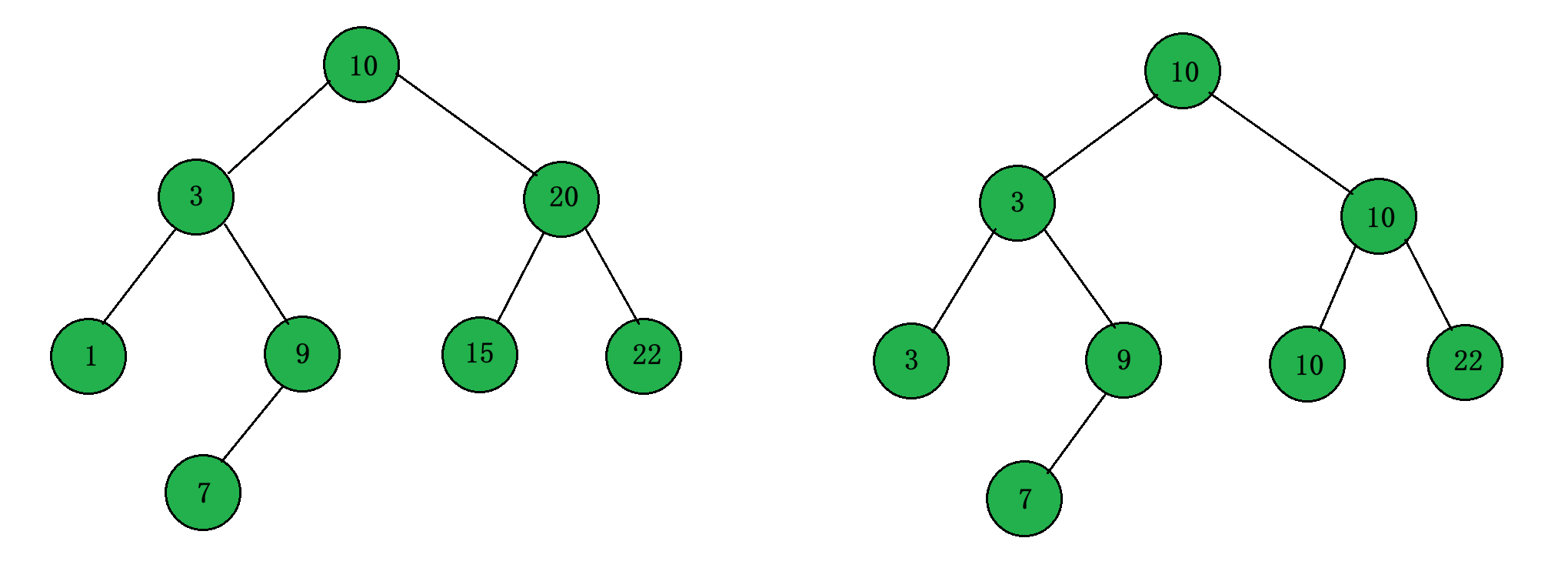
而下面这棵树就不是一棵二叉搜索树:
而且根据二叉搜索树的性质,左子树节点的值 <= 根节点的值 <= 右子树节点的值,所以如果对一棵 BST 进行中序遍历,那么遍历后的序列就是一个升序排列的序列。
2 二叉搜索树的性能
为什么会存在二叉搜索树这么一个数据结构呢?最主要的原因就是因为这个数据结构能够加快搜索的速度,因为根据二叉搜索树的性质,左子树节点的值 <= 根节点的值,右子树节点的值 >= 根节点的值,所以当我们查找一个值 x 时,只需要判断该值与根节点的关系,如果 root > x,那么就往左子树走;如果 root < x,那就往右子树走,查找次数就是二叉搜索树的高度。一棵二叉搜索树具备以下性能:
1) 在插入节点的最优情况下,二叉搜索树是一棵完全二叉树或者近似是一棵完全二叉树,其高度为
2) 在插入节点的最坏情况下,比如插入值的先后顺序为 9, 8, 7, 6, 5, 4, 3, 2, 1,该搜索二叉树就会退化为一棵单叉树,树的高度就是 N(如下面的图所示)
3) 综合而言,二叉搜索树的增删查改的时间复杂度为 O(N)
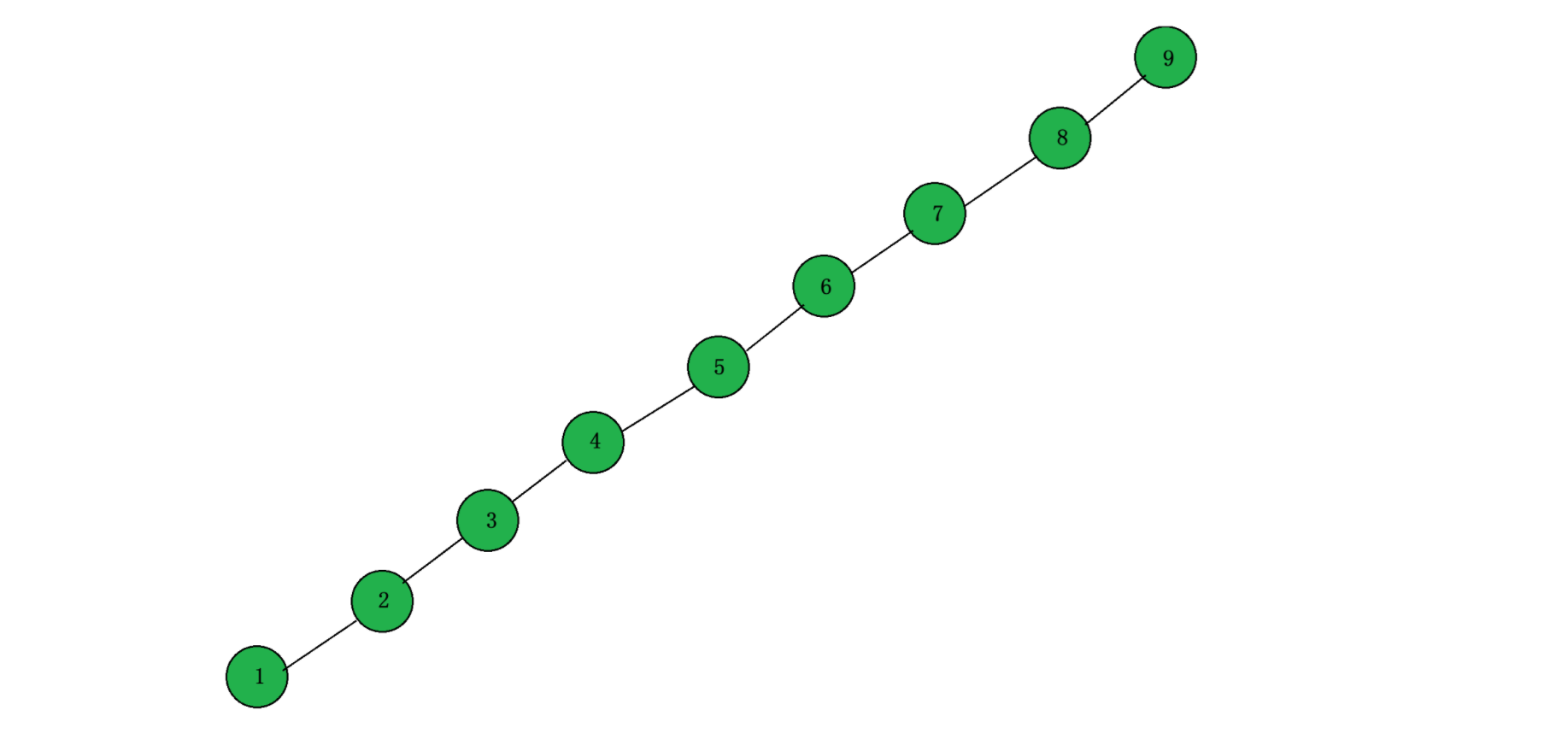
所以对于一棵普通的二叉搜索树来说,其查找的效率并不能满足我们的要求,后面我们会讲解两种特殊的二叉搜索树,分别是平衡二叉树(AVLTree)与红黑树(RBTree),这两种树效率都是 logN 级别,会比 BST 效率更高。
值得一提的是,二分查找算法的时间复杂度也是 O(logN),但是二分查找算法的限制条件限制了其应用场景:
(1) 值需要存储在支持随机访问的数据结构中,一般为数组或者顺序表
(2) 插入和删除效率很低,因为需要大量移动元素
相比之下,AVLTree 与 RBTree 就自由很多,没有太多限制,所以AVLTree 与 RBTree 是比二分查找算法更适合查找场景的两种数据结构。
3 二叉搜索树的增删查改(不同值的 BST)
基于之前的二叉树,二叉搜索树采取的依然是链式结构。所以在讲解二叉搜索树的增删查改之前,我们需要先创建其结构。
1) 二叉搜索树的结构
(1) 二叉搜索树的节点
对于二叉搜索树来说,我们并不需要知道每一个节点的父亲是谁,所以我们这里依然采用之前二叉树中的节点,也就是一个数据,两个指针,一个指向左孩子,一个指向右孩子,这里我们需要设计成模板的形式,以实现泛型编程:
cpp
template<class K>
struct BSTNode
{
K _key;
BSTNode<K>* _left;
BSTNode<K>* _right;
BSTNode(const K& key = K())
:_key(key)
,_left(nullptr)
,_right(nullptr)
{}
};这里写一个构造函数以便于我们在 BST 的实现中构造节点。
(2) 二叉搜索树的结构
对于整棵二叉搜索树来说,如果我们找到了其根节点,那么我们就知道整棵树的结构了,所以二叉搜索树的类的成员变量就是一个根节点:
cpp
template<class K>
class BSTree
{
typedef BSTNode<K> Node;
public:
//增删查改方法
private:
//只需要有一个根节点
//不要忘记设置缺省值,当然写个构造函数也是可以的
Node* _root = nullptr;
};2) 二叉搜索树的插入
二叉搜索树的插入只需要按照我们之前的逻辑,将一个新的节点插入到二叉搜索树中即可,具体逻辑如下(要插入的值为 key):
(1) 如果根节点为空,那就将该值作为整棵树的根
(3) 如果根节点不为空,保存当前子树的根节点的指针 cur,将要插入的值与 cur 的值进行比较,如果 cur->_key > key,那就需要将 key 插入到 cur 的左子树,也就是 cur = cur->_left;如果 cur->_key < key,那就需要将 key 插入到 cur 的右子树,也就是 cur = cur->_right。但是需要注意插入时需要保存 cur 的父节点 parent,以便于最后进行链接
(4) 走到根节点的子树之后,cur 继续作为当前子树的根,重复上述逻辑,直到 cur 为空
(5) 以 key 为值创建新节点,插入到 cur 位置
比如要插入的节点值分别为 8, 3, 1, 10, 12, 7, 11, 20,插入过程如图所示:

cpp
bool Insert(const K& key)
{
//如果根节点为空,当前值直接作为根节点
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root, *parent = nullptr;
//寻找插入位置
while (cur)
{
if (cur->_key > key)
{
// key 比根节点值小,插入到左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
//key 比根节点大,插入到右子树
parent = cur;
cur = cur->_right;
}
else
return false;
}
//找到了该插入的位置
Node* newnode = new Node(key);
if (parent->_key > key)
parent->_left = newnode;
else
parent->_right = newnode;
return true;
}3) 二叉搜索树的查找
二叉搜索树的查找很简单,要查找一个值 key,如果本身树为空,那直接返回 false。如果树不为空,我们只需要跟每个子树的根节点进行比较,如果 cur->_key > key,那就去左子树,也就是 cur = cur->_left;如果 cur->_key < key,那就去右子树查找,也就是 cur = cur->_right;如果 cur->_key == key,那就说明找到了,直接返回 true;如果 cur 为空了还没有返回,说明没有 key,返回 false。
cpp
bool Find(const K& key)
{
//树为空树,直接返回 false
if (_root == nullptr)
return false;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
//根节点的值大于 key,去左子树
cur = cur->_left;
else if (cur->_key < key)
//根节点的值小于 key,去右子树
cur = cur->_right;
else
//根节点的值与 key 相等,找到了
return true;
}
//cur 为空还没有找到,直接返回 false
return false;
}4) 二叉搜索树的删除
如果我们要删除一个值为 key 的节点,首先我们需要先在 BST 中找到值为 key 的节点,如果找不到,那么我们就直接返回 false。如果找到了,总共有四种情况,我们一一来分析:
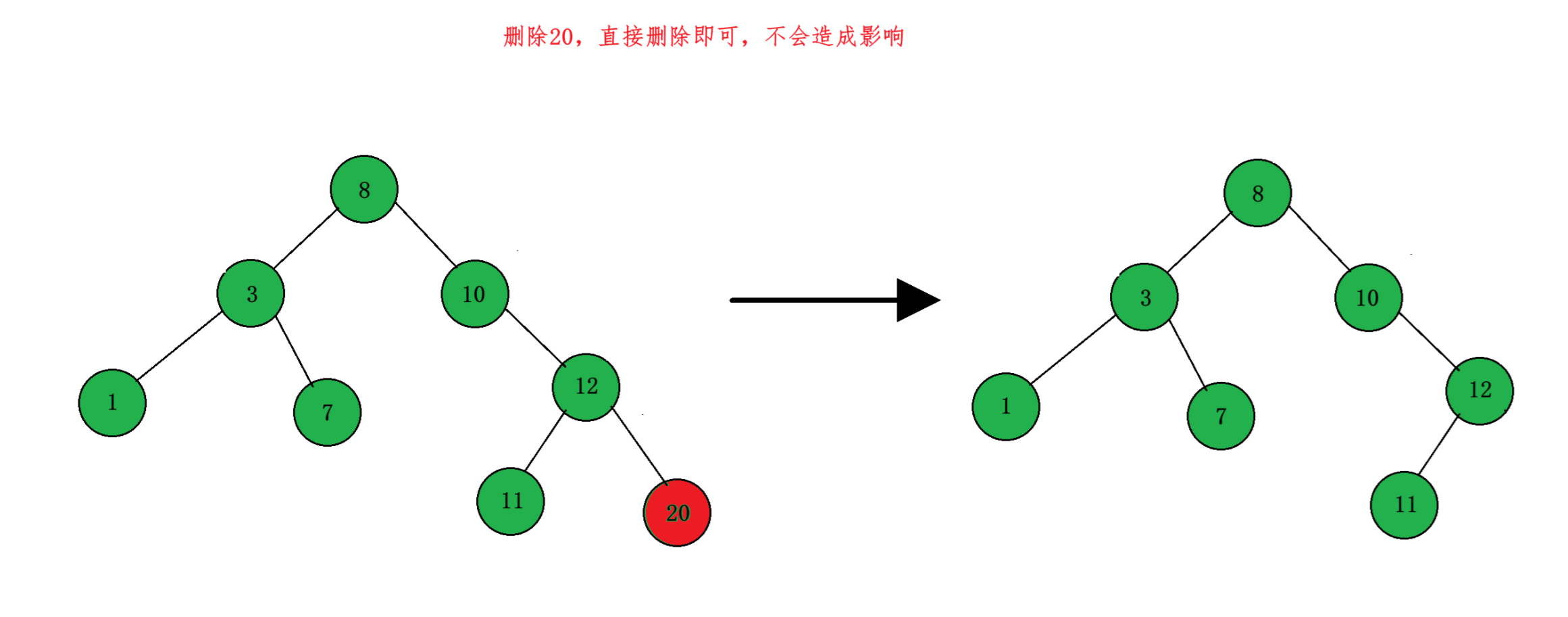
(1) 要删除的节点左右孩子都为空
这种情况最好处理,如果左右孩子都为空,直接删除该节点之后也不会对 BST 整体结构造成影响,所以直接删除就可以了:
(2) 要删除的节点左孩子为空,但是右孩子不为空
在这种情况下,要删除该节点 cur,我们需要先找到 cur 的父节点 parent,如果 parent->_left == cur,那么这种情况下,cur 右子树的所有节点的值都会小于 parent 的值,所以我们直接让 parent->_left = cur->_right,然后删除掉 cur 节点,这样也不会破坏整个 BST 的结构;同理,如果 parent->_right == cur,直接让 parent->_right = cur->_right,然后删除掉 cur 就可以了:
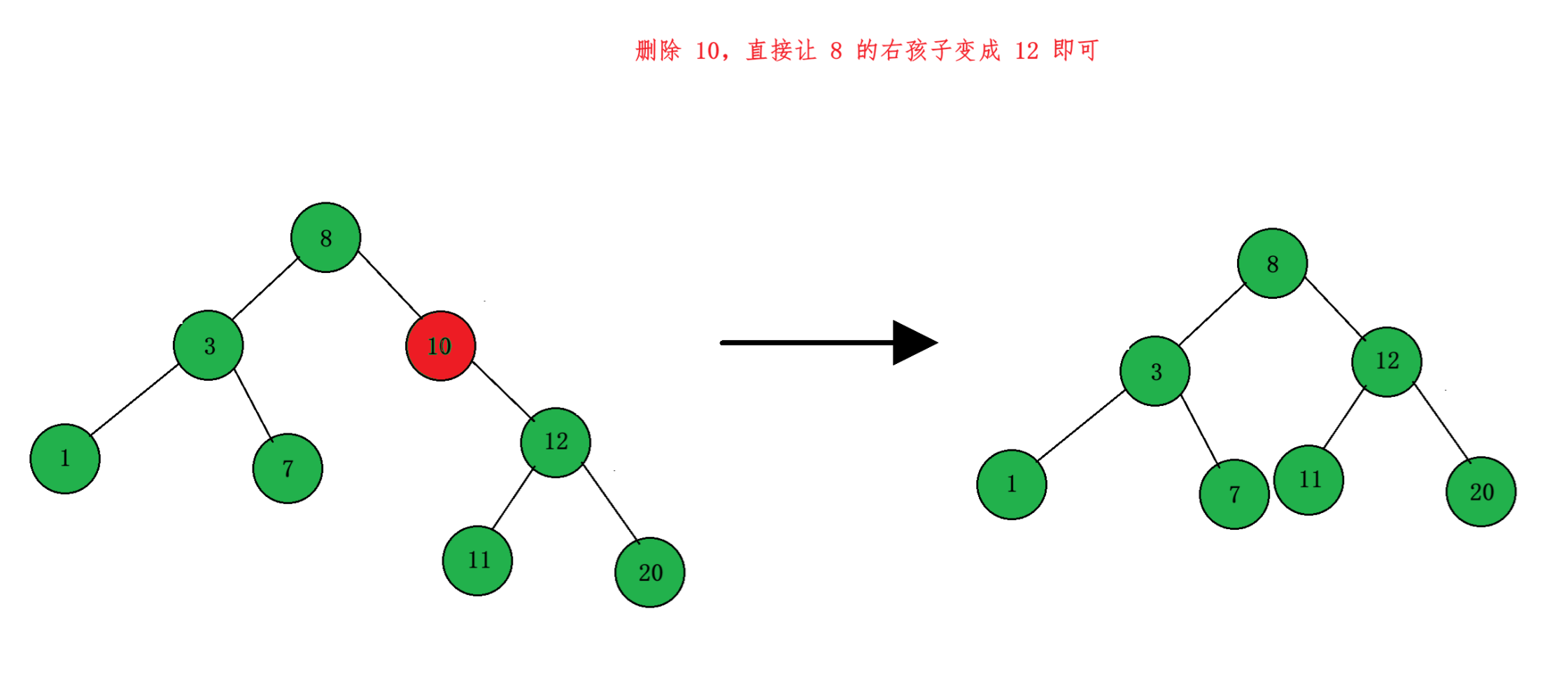
(3) 要删除的节点右孩子为空,但左孩子不为空
这种情况与上面是一样的,直接让 parent 对应的孩子指针指向 cur->_left,然后删除掉 cur 即可。
(4) 要删除的节点左右孩子都不为空
这种情况最为复杂,首先我们不能像前面一样直接删除节点或者用左孩子或者用孩子来替换该节点,如果你直接用孩子来替换节点,那就会破坏之前的 BST 结构,比如下面这棵二叉搜索树:
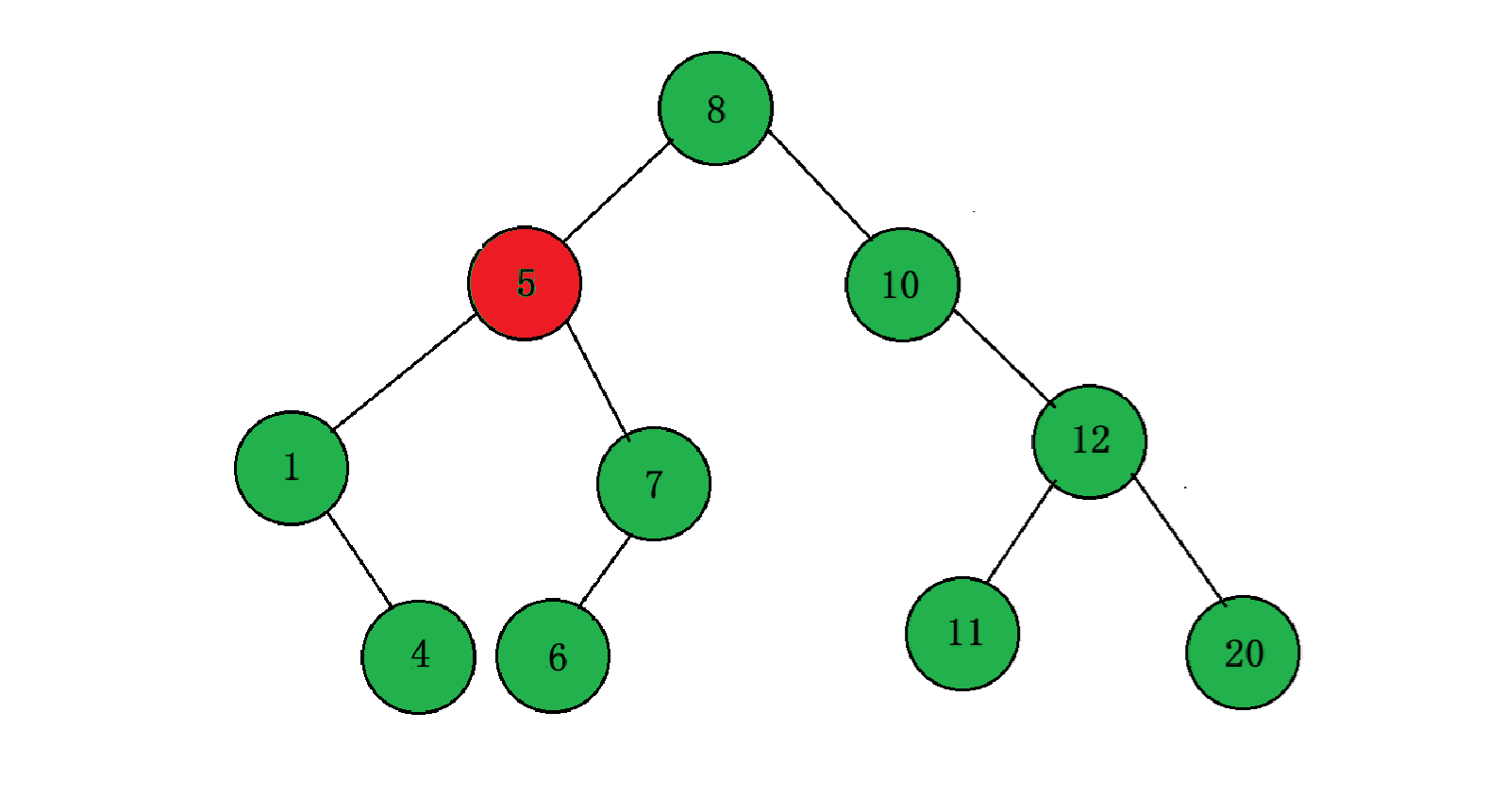
如果你要删除 5 这个节点,其左右子树都不为空,如果用 1 来替换 5,那么 1 的右子树会和 7 发生冲突;如果要用 7 来替换 5,那么 6 会与 1 发生冲突,所以是不能直接替换的。
正确的做法是我们应该找到其左子树的最大节点或者是右子树的最小节点来替换这个要删除的节点。因为对于要删除节点来说,左子树的最大节点是左子树里面最大的节点,而左子树的最大节点又会小于右子树的所有节点,所以这个节点替换掉要删除的节点之后就不会发生冲突,右子树的最小节点是一样的。那么左子树的最大节点是哪个节点呢?其实就是左子树的最右下的那个节点,因为对于每个子树,其右子树节点的始终是最大的。同样的,右子树的最小节点就是右子树最左下的那个节点,这里我们选择使用左子树的最大节点来进行替换:
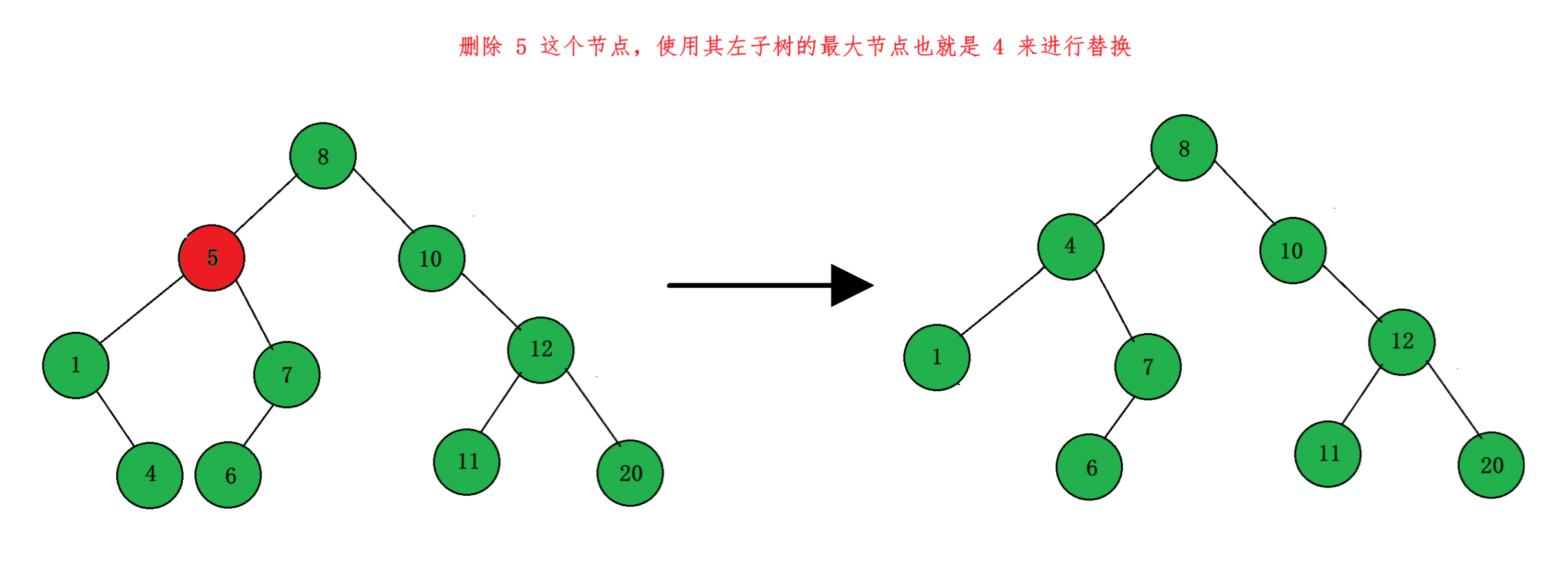
cpp
bool Erase(const K& key)
{
//如果树为空,那就直接返回 false
if (_root == nullptr)
return false;
Node* cur = _root;
Node* parent = nullptr;
//开始查找 key
while (cur)
{
if (cur->_key > key)
{
//去左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
//去右子树
parent = cur;
cur = cur->_right;
}
else
{
if (cur->_left == nullptr)
{
//左子树为空
//直接让父亲的对应指针指向右孩子
if (parent->_key > key)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else if (cur->_right == nullptr)
{
//右子树为空
//直接让父亲的对应指针指向左孩子
if (parent->_key > key)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else
{
//左右子树都不为空
//先寻找左子树最大节点
//一定要走 maxleft 的父亲节点,因为 maxleft可能有左孩子
Node* maxleftp = cur;
Node* maxleft = cur->_left;
while (maxleft->_right)
{
maxleftp = maxleft;
maxleft = maxleft->_right;
}
//替换 cur 节点
cur->_key = maxleft->_key;
//删除 maxleft 节点
//这里需要进行判断,因为 maxleft 也可能是 maxleftp 左子树的第一个节点
if (maxleftp->_right == maxleft)
maxleftp->_right = maxleft->_left;
else
maxleftp->_left = maxleft->_left;
delete maxleft;
maxleft = nullptr;
}
return true;
}
}
//没找到 key, 直接返回 false
return false;
}(5) 代码实现
cpp
//BSTree.hpp
#pragma once
#include <iostream>
using namespace std;
//BST 节点
template<class K>
struct BSTNode
{
K _key;
BSTNode<K>* _left;
BSTNode<K>* _right;
BSTNode(const K& key = K())
:_key(key)
, _left(nullptr)
, _right(nullptr)
{}
};
//BSTree
template<class K>
class BSTree
{
typedef BSTNode<K> Node;
public:
//使用编译器默认生成的构造函数
BSTree() = default;
//拷贝构造函数
BSTree(const BSTree<K>& t)
{
_root = Copy(t._root);
}
//赋值重载函数
BSTree<K>& operator=(BSTree<K> t)
{
if (this != &t)
{
swap(_root, t._root);
return *this;
}
}
//析构函数
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
//增删查改方法
bool Insert(const K& key)
{
//如果根节点为空,当前值直接作为根节点
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root, * parent = nullptr;
//寻找插入位置
while (cur)
{
if (cur->_key > key)
{
// key 比根节点值小,插入到左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
//key 比根节点大,插入到右子树
parent = cur;
cur = cur->_right;
}
else
return false;
}
//找到了该插入的位置
Node* newnode = new Node(key);
if (parent->_key > key)
parent->_left = newnode;
else
parent->_right = newnode;
return true;
}
bool Find(const K& key)
{
//树为空树,直接返回 false
if (_root == nullptr)
return false;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
//根节点的值大于 key,去左子树
cur = cur->_left;
else if (cur->_key < key)
//根节点的值小于 key,去右子树
cur = cur->_right;
else
//根节点的值与 key 相等,找到了
return true;
}
//cur 为空还没有找到,直接返回 false
return false;
}
bool Erase(const K& key)
{
//如果树为空,那就直接返回 false
if (_root == nullptr)
return false;
Node* cur = _root;
Node* parent = nullptr;
//开始查找 key
while (cur)
{
if (cur->_key > key)
{
//去左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_key < key)
{
//去右子树
parent = cur;
cur = cur->_right;
}
else
{
if (cur->_left == nullptr)
{
//左子树为空
//直接让父亲的对应指针指向右孩子
if (parent->_key > key)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else if (cur->_right == nullptr)
{
//右子树为空
//直接让父亲的对应指针指向左孩子
if (parent->_key > key)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else
{
//左右子树都不为空
//先寻找左子树最大节点
//一定要走 maxleft 的父亲节点,因为 maxleft可能有左孩子
Node* maxleftp = cur;
Node* maxleft = cur->_left;
while (maxleft->_right)
{
maxleftp = maxleft;
maxleft = maxleft->_right;
}
//替换 cur 节点
cur->_key = maxleft->_key;
//删除 maxleft 节点
if (maxleftp->_right == maxleft)
maxleftp->_right = maxleft->_left;
else
maxleftp->_left = maxleft->_left;
delete maxleft;
maxleft = nullptr;
}
return true;
}
}
//没找到 key, 直接返回 false
return false;
}
//添加中序遍历方法
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << ' ';
_InOrder(root->_right);
}
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newroot = new Node(root->_key);
newroot->_left = Copy(root->_left);
newroot->_right = Copy(root->_right);
return newroot;
}
void Destroy(Node* root)
{
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
//只需要有一个根节点
//不要忘记设置缺省值,当然写个构造函数也是可以的
Node* _root = nullptr;
};
//test.cpp
//测试代码
#include "BSTree.hpp"
int main()
{
BSTree<int> t;
//8, 3, 1, 10, 12, 7, 11, 20
t.Insert(8);
t.Insert(3);
t.Insert(1);
t.Insert(10);
t.Insert(12);
t.Insert(7);
t.Insert(11);
t.Insert(20);
t.InOrder();
cout << t.Find(1) << endl;
cout << t.Find(100) << endl;
//删除节点
t.Erase(20);
t.InOrder();
t.Erase(10);
t.InOrder();
t.Erase(3);
t.InOrder();
return 0;
}以上实现的不允许插入相同值版本的 BST,如果想要实现允许插入相同值版本的 BST,只要在插入时修改一下逻辑,也就是在寻找 while (cur) 循环里面,如果 cur->_key == key,那么我们可以将 key 插入到 cur 节点的左子树或者右子树都可以;在查找时一般都是查找中序遍历的第一个值,也就是找到了一个值相同节点之后,不能立即返回,要继续判断其左子树里面有没有相同节点(因为左子树里面的节点在中序遍历中会先遍历到),如果有,那就是左子树里面的节点;没有才是这个节点;删除时也需要删除中序遍历的第一个节点。
4 二叉搜索树的 key-value 场景
1) key-value 二叉搜索树的存在意义
上一部分是只有一个关键字 key 的 BST,其将 key 作为关建字的同时,也作为值来进行搜索。其支持插入、删除、搜索但是不支持 key 的修改,因为一旦 key 被修改了,那么整棵二叉树的结构也就被破坏了。其应用场景主要是用来判断一个关键字 key 在不在二叉搜索树中。比如 word 里面的语法检查。在进行语法检查前,word 里面有一棵用所有英文单词构建的 BST,当你输入一个单词之后,word 会在 BST 里面检查你这个单词在不在里面,如果不在,那就画出红线。
但是还有一些应用场景是需要 key 来匹配,但是里面存储的值并不是 key,而是 value。比如中英词典互译。在词典对应 BST 中,key 为中文或者英文,value 为对应的英文或者中文,当你输入一个英文单词时,二叉树会将你输入的英文单词作为关键字 key 来进行搜索,最终返回的值为 其对应的中文意思,也就是 value。其对应的结构为(这里字符串的大小与 strcmp 函数比较规则相同):
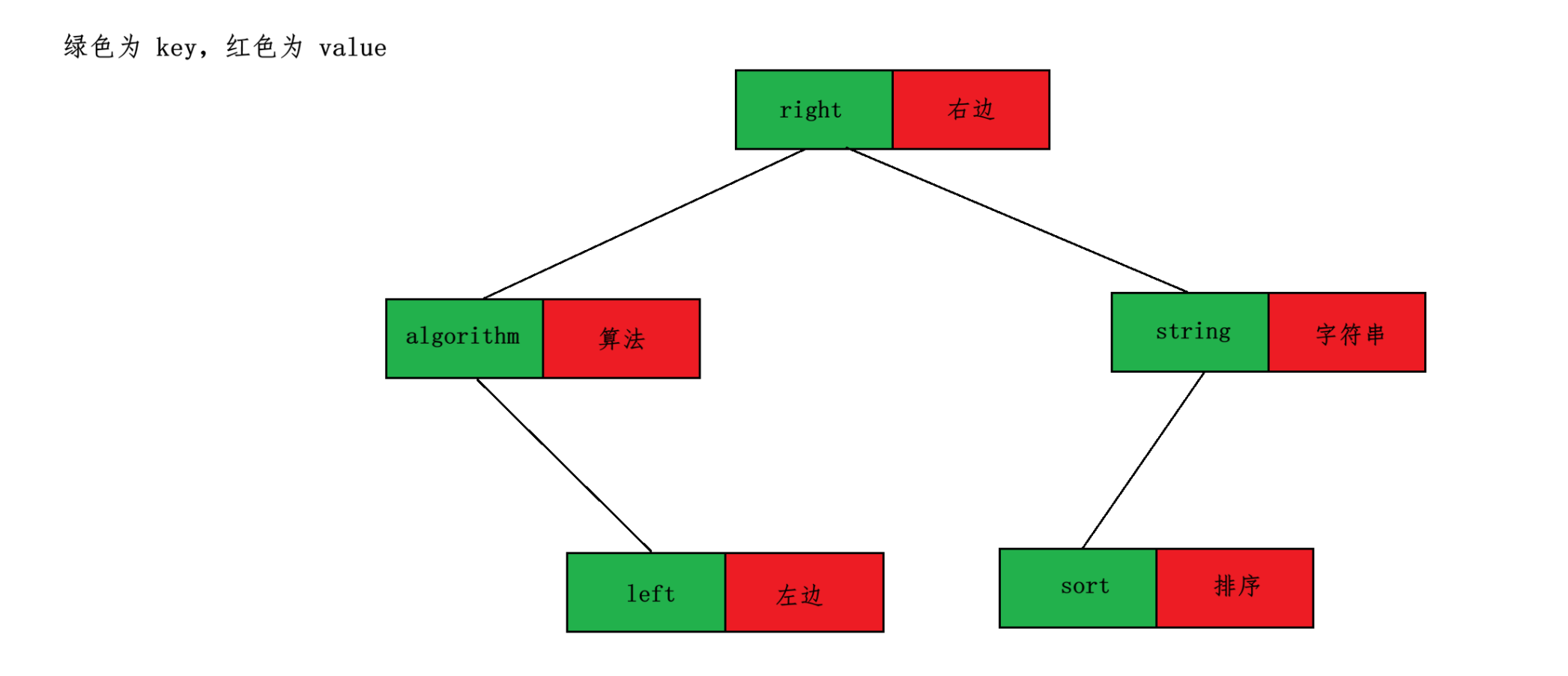
在 key-value 结构的 BST 中,因为 key 要作为关键字来比较大小,所以 key 是不支持修改的,但是 value 确是可以修改的。
2) key-value 二叉搜索树的实现
在讲解 key-value 结构的二叉搜索书实现之前,我们先来讲解一下C++库中的一个 struct 类 pair 结构体:
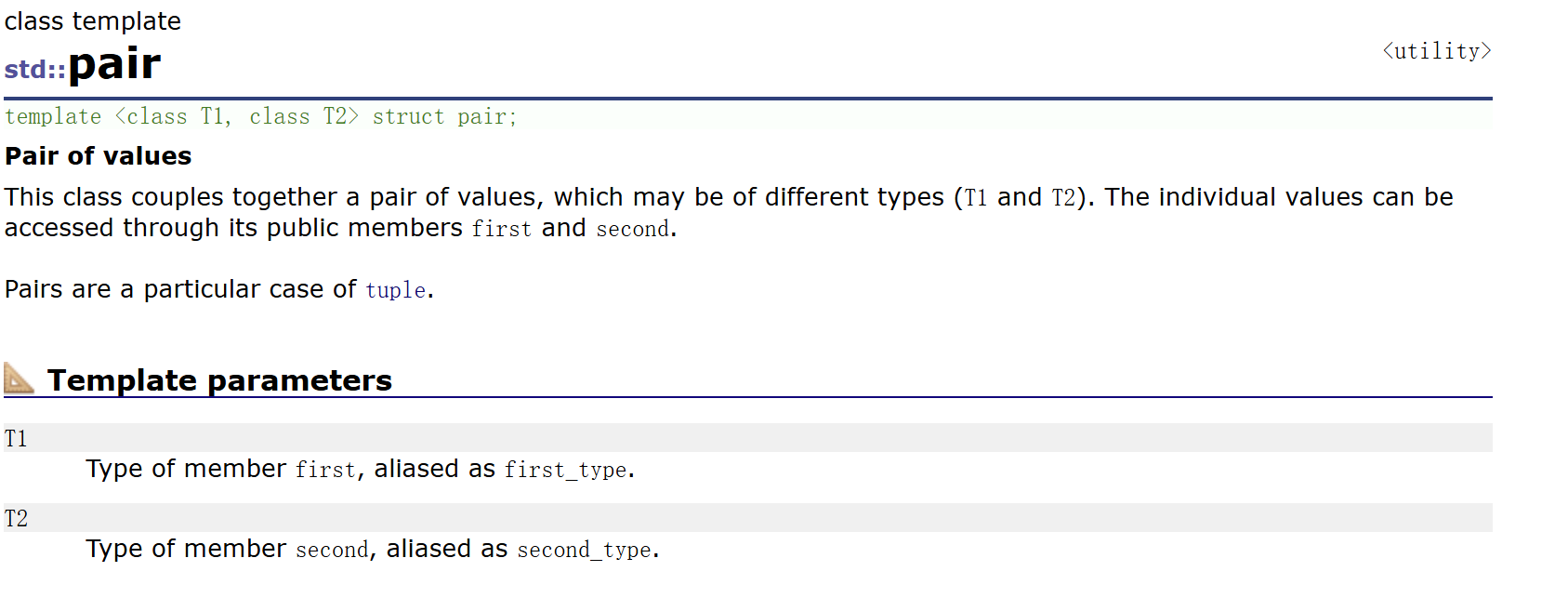
pair 是一个模板,其有两个参数,第一个参数类型是 T1,名字为 first,第二个参数类型是 T2,名字为 second,而且 pair 为 struct 类,所以我们可以直接访问其成员变量。
所以相比于单个 key 的 BST,在 key-value BST 的节点结构中,其值就不是 _key 了,而是一个 pair 结构体,其中 first 为 key 关键字,second 就是 value 值。key-value 与 key 的实现只是节点结构不太相同,其余的完全相同,这里就不再赘述。
3) key-value BST 代码
cpp
//BSTree.hpp
#pragma once
#include <iostream>
using namespace std;
//BST 节点
template<class K, class V>
struct BSTNode
{
pair<K, V> _data;
BSTNode<K, V>* _left;
BSTNode<K, V>* _right;
BSTNode(const pair<K,V>& data)
:_data(data)
, _left(nullptr)
, _right(nullptr)
{}
};
//BSTree
template<class K,class V>
class BSTree
{
typedef BSTNode<K,V> Node;
public:
BSTree() = default;
//拷贝构造函数
BSTree(const BSTree<K, V>& t)
{
_root = Copy(t._root);
}
//赋值重载函数
BSTree<K, V>& operator=(BSTree<K, V> t)
{
if (this != &t)
{
swap(_root, t._root);
return *this;
}
}
~BSTree()
{
Destroy(_root);
_root = nullptr;
}
//增删查改方法
bool Insert(const pair<K,V>& data)
{
//如果根节点为空,当前值直接作为根节点
if (_root == nullptr)
{
_root = new Node(data);
return true;
}
Node* cur = _root, * parent = nullptr;
//寻找插入位置
while (cur)
{
if (cur->_data.first > data.first)
{
// key 比根节点值小,插入到左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_data.first < data.first)
{
//key 比根节点大,插入到右子树
parent = cur;
cur = cur->_right;
}
else
return false;
}
//找到了该插入的位置
Node* newnode = new Node(data);
if (parent->_data.first > data.first)
parent->_left = newnode;
else
parent->_right = newnode;
return true;
}
Node* Find(const K& key)
{
//树为空树,直接返回 false
if (_root == nullptr)
return nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_data.first > key)
//根节点的值大于 key,去左子树
cur = cur->_left;
else if (cur->_data.first < key)
//根节点的值小于 key,去右子树
cur = cur->_right;
else
//根节点的值与 key 相等,找到了
return cur;
}
//cur 为空还没有找到,直接返回 false
return nullptr;
}
bool Erase(const K& key)
{
//如果树为空,那就直接返回 false
if (_root == nullptr)
return false;
Node* cur = _root;
Node* parent = nullptr;
//开始查找 key
while (cur)
{
if (cur->_data.first > key)
{
//去左子树
parent = cur;
cur = cur->_left;
}
else if (cur->_data.first < key)
{
//去右子树
parent = cur;
cur = cur->_right;
}
else
{
if (cur->_left == nullptr)
{
//左子树为空
//直接让父亲的对应指针指向右孩子
if (parent->_data.first > key)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else if (cur->_right == nullptr)
{
//右子树为空
//直接让父亲的对应指针指向左孩子
if (parent->_data.first > key)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
//删除 cur 节点
delete cur;
cur = nullptr;
}
else
{
//左右子树都不为空
//先寻找左子树最大节点
//一定要走 maxleft 的父亲节点,因为 maxleft可能有左孩子
Node* maxleftp = cur;
Node* maxleft = cur->_left;
while (maxleft->_right)
{
maxleftp = maxleft;
maxleft = maxleft->_right;
}
//替换 cur 节点
cur->_data = maxleft->_data;
//删除 maxleft 节点
if (maxleftp->_right == maxleft)
maxleftp->_right = maxleft->_left;
else
maxleftp->_left = maxleft->_left;
delete maxleft;
maxleft = nullptr;
}
return true;
}
}
//没找到 key, 直接返回 false
return false;
}
//添加中序遍历方法
void InOrder()
{
_InOrder(_root);
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_data.first << ':' << root->_data.second << endl;
_InOrder(root->_right);
}
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* newroot = new Node(root->_data);
newroot->_left = Copy(root->_left);
newroot->_right = Copy(root->_right);
return newroot;
}
void Destroy(Node* root)
{
if (root == nullptr)
return;
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
//只需要有一个根节点
//不要忘记设置缺省值,当然写个构造函数也是可以的
Node* _root = nullptr;
};
//test.cpp
//测试代码
#include "BSTree.hpp"
#include <string>
int main()
{
BSTree<string, string> t;
t.Insert({ "right", "右边" });
t.Insert({ "algorithm", "算法" });
t.Insert({ "left", "左边" });
t.Insert({ "string", "字符串" });
t.Insert({ "sort", "排序" });
t.InOrder();
return 0;
}5 总结
这篇文章呢,主要讲解了二叉搜索树这一数据结构。最重要的就是二叉搜索树的特点,左子树 <= 根节点 <= 右子树,这一结构就可以使得查找速率变为 logN 级别,但是在极端情况下,二叉搜索树可能会退化为单支树,综合来说,二叉搜索树的增删查改的时间复杂度还是 O(N) 的,不能满足要求。所以后面我们会讲解另外两种二叉搜索书 -- 二叉平衡树与红黑树,这两种数据结构会使得查找速率稳定在 O(N)。