二维图像数据处理
单图像数据处理
数据排序方式
张量中图像数据类型的排列顺序为C×H×W(分别表示通道、高度和宽度),可以看出这和之前使用opencv读取的图片数据排列顺序不太一样,为HWC排序,并且大多数的数据库中都是与之相同的
库 默认格式 说明 OpenCV HWC 所有图像操作都基于 HWC PIL/Pillow HWC Image.open()返回对象,转 NumPy 后是 HWC RGBMatplotlib HWC plt.imshow()期望 HWC RGBscikit-image HWC 图像处理函数接受 HWC imageio HWC 读取图像为 NumPy 数组,HWC pytorch CHW 大部分函数使用 HWC
排序方式转化
由于数据排序方式的不同,因此在读取图像后首先就需要进行数据排序方式的转化
CHW转HWC
permute函数
output = torch.permute(input, dim)/output = input.permute(dim)
input:待转化的张量
dim:要变化的维度,如下面的dim=(2, 0, 1),即是将原本位于第三列的数据放在第一列,第一列的数据放在第二列,第二列的数据放在第三列
output:转化完成的张量
permute函数在前面文章中提到过,其转化的数据类型都是张量,因此使用permute之前都需要将数据转化为张量
import cv2 import torch img = cv2.imread('./images/ship.bmp') print(img.shape) img = torch.from_numpy(img) img = torch.permute(img, (2, 0, 1)) # img = img.permute(2, 0, 1) print(img.shape) # (48, 60, 3) torch.Size([3, 48, 60])
ToTensor函数
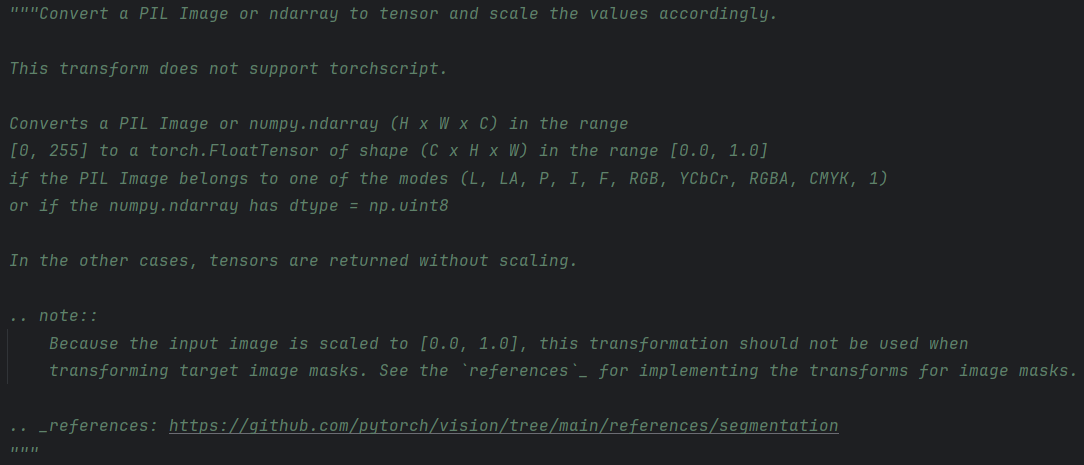
ToTensor函数是torchvision.transforms中的一个类,其是专用于将其余的数据转化为适用与pytorch的数据,其仅含有__call__和__repr__函数,如下是官方定义文档
其主要可以转化PIL图像和ndarray数组,同时在转化后还可以将数据进行归一化处
from torchvision.transforms import ToTensor tensor = ToTensor()(hwc_array) # 自动转为CHW并归一化这是简略写法,对此我们可以展开来说一下
该写法是python的链式写法,上述代码等价于
from torchvision.transforms import ToTensor to_tensor_transform = ToTensor() # 实例化 tensor = to_tensor_transform(hwc_array) # 调用__call__函数__call__函数是python的特殊函数,被称为魔术方法,该函数在你创建实例后会自动调用,而适用其他函数都需要适用显式指定方法名
class MyClass: def normal_method(self): return "normal_method" def __call__(self): return "__call__ method" obj = MyClass() # 不同调用方式的区别: print(obj.normal_method()) # 正常方法调用,输出: "normal_method" print(obj()) # 调用实例,自动调用__call__,输出: "__call__ method" print(obj.__call__()) # 显式调用__call__,输出: "__call__ method"
多图像数据处理
一般来说,神经网络都需要多个图像进行同时的处理,因此一般需要一个张量表示多个图像数据以进行后续的处理,其数据顺序为NCHW即(图像个数、通道数、高度、宽度)
import cv2 import torch from torchvision.transforms import ToTensor import os data_path = './images/' filenames = [] for name in os.listdir(data_path): if os.path.splitext(name)[-1] == '.jpg': # 分离文件名和扩展名,扩展名中包含. filenames.append(name) batch_size = len(filenames) batch = torch.zeros(batch_size, 3, 480, 640, dtype = torch.float) for i, name in enumerate(filenames): # enumerate函数用于遍历一个迭代对象,返回索引和对应的值 img = cv2.imread(data_path + name) img = ToTensor()(img)[:3] batch[i] = img
三维图像数据处理
三维图像在现实生活中也处处存在,其中较为典型的便是医院中CT断面图,CT断面图便是将人体的一部分通过X射线的测量计算得出,不难想象最后得出的图像除了前文的通道数、高度、宽度以外,还有一个便是计算移动的距离,也就是该仪器拍摄了多大的一个部分,在图像中我们称为深度,从而得到一个五维的张量。形状为NCDHW即图像数量、通道数、深度、高度、宽度
import imageio import torch dir_path = './volumetric-dicom/2-LUNG 3.0 B70f-04083' vol_arr = imageio.volread(dir_path, 'DICOM') print(vol_arr.shape) vol = torch.from_numpy(vol_arr).float() vol = torch.unsqueeze(vol, 0) print(vol.shape) # Reading DICOM (examining files): 99/99 files (100.0%) Found 1 correct series. Reading DICOM (loading data): 99/99 (100.0%) (99, 512, 512) torch.Size([1, 99, 512, 512])这便读取了单个数据,可以通过如之前的方法一样便可推叠成一个五维的数据集
由于opencv只支持二维图像的处理,因此引入了一个新的数据库imageio,由于目前所说主要针对于pytorch,同时对于该库不熟悉,因此不细讲
表格数据
表格数据也是我们常用的数据处理类型,而针对于表格数据来说,首先便是确定时间对其数据是否有影响,没有影响则正常处理,有影响则需要一些特殊方法,而针对于这些被时间影响的数据我们一般称之为时间序列
此外表格数据也可能存在缺失值影响数据的转化,因此除了判断是否为时间序列以外,还有一个针对于所有表格都需要做的事情便是数据的预处理,数据的预处理往往包括但不限于处理数据的缺失值,还会处理数据的异常值,甚至画出图像的直方图等等,对于简单的数据处理我们可以使用软件SPSS来帮助我们
数据类型
连续值
用数字表示是最直观的,它们是严格有序的,不同值之间的差异具有严格的意义。无论A包裹的质量是3千克还是 10 千克,说A包裹比B包裹重2千克是有固定意义的。如果你用单位来计算或测量某物,它可能是一个连续的值。
序数值
比如点一份小杯、中杯或大杯的饮料,将小杯映射为 1、中杯为 2、大杯为 3。大杯饮料比中杯大,就像3比2大一样,但它没有告诉我们大了多少。如果我们将1、2、3 转换为实际体积,那么它们将转换为区间值。重要的是,除了对这些值进行排序,我们无法对它们进行"数学运算"即试图将大杯等于3、小杯等于1的平均值计算不会得到中杯饮料的体积。
分类值
分类值对其值既没有排序意义,也没有数字意义,通常只是分配任意数字的可能性的枚举。将水设定为 1、咖啡设定为 2、苏打水设定为 3、牛奶设定为 4。每一个映射关系都没有内在的逻辑,只是需要不同的值来区分它们。
非时间序列
由于表格数据一般都会在第一列中描述每一行的数字的含义,因此加载后的张量可能是一个字符串类型,而由于其又含有数字类型,因此一般称之为异构数据,其不同的列具有不同的类型,比如一列可以显示苹果的重要,另一列可以显示苹果的颜色
但是由于张量的所有元素类型一致,尽管可以是浮点数、整数或者bool型,但是总的来说都是数,而表格数据则不同,其包括但不限于数字,还有字符串、日期等
加载数据张量--连续值
对于数据表格的处理,我们可以使用numpy库和python的内置csv库,但是功能更加强大的是pandas库,由于pandas库内容过多,在此不在细讲,直接使用numpy库
import torch import numpy import csv wine_path = './tabular-wine/winequality-white.csv' # 加载数据文件数据,但是不包含数据文件的第一列 wineq_numpy = numpy.loadtxt(wine_path, dtype = numpy.float32, delimiter = ';', skiprows = 1) wineq = torch.from_numpy(wineq_numpy) # 加载数据文件每一列数据的意义 with open(wine_path, 'r', newline = '', encoding = 'utf-8') as f: reader = csv.reader(f, delimiter = ';') col_list = next(reader)
表征分类值
表征序数值一般有两种方式,一种便是直接使用整数表示,如上文所举例一样,另一种便是使用独热编码
整数编码
整数编码即是将序列数视为一个连续变量,并尝试在分类任务中根据化学特征分析猜测标签,比如葡萄酒的种类,其本身的值不属于连续值,它的大小也没有意义,但是可以直接使用整数来表示
独热编码
独热编码即是将10个得分中的每个分数分别编码到一个由10个元素组成的向量中,除了其中一个元素设置为1,其他元素都设置为0,每个序列数都有一个不同的索引。例如对于一个1~5分的评分,对于1分可以表示为(1, 0, 0, 0, 0),5分可以表示为(0, 0, 0, 0, 1),其中1的位置对于每个评分来说并不固定,但是1~5这5个数必须采取不同的表示方式,因此为了方便,一般就令最小的序列数的第1位为1,最大的序列数的最后一位为1
我们一般使用scatter_()方法来获得一个独热编码,其功能是据一个索引张量,将源张量中的值分散到当前张量的指定位置
tensor.scatter_(dim, index, src)
tensor:源张量
dim:分散的维度,即在那个维度上进行"分散操作"
index:索引张量,它定义了src中的每个值应该被放到tensor的哪个位置上。它的形状通常与src相同。
src:源数据,它包含了要放入tensor的值。可以是一个张量,也可以是一个标量。
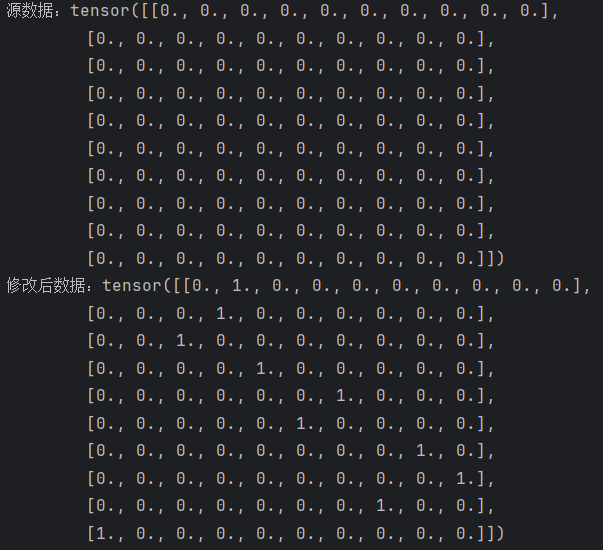
import torch target_onehot = torch.zeros(10, 10) # 创建源数据 print(f'源数据:{target_onehot}') target = torch.tensor([1, 3, 2, 4, 6, 5, 8, 9, 7, 0]) # 创建索引张量 target_onehot.scatter_(0, target.unsqueeze(1), 1.0) print(f'修改后数据:{target_onehot}')由上图可以看到最后的输出都是target_onehot,因此该函数会直接覆盖原本的数据,该函数中其这个作用的便是_,函数名中的下划线
_表示这是一个原地操作,它会直接修改调用该方法的张量本身,而不会创建一个新的张量。
假设我们源数据tensor为二维数据,其数学表示即为一个二维矩阵,为tensor(i, j)对于dim,当dim取值为0时,我们是按照行来进行分散,即是对于tensor(i, j)的i起作用;如果dim取值为1时,我们是按照列来进行分散,即是对于tensor(i, j)的j起作用
对于index、src、tensor这三者的关系来说
1、如果index和src都是多维的,那么index和src这两者的行数和列数应该完全一样,否则会出现报错
2、此外对于index和tensor的关系,首先需要保证index和tensor的维度应该相同的,因此上例中使用了unsqueeze(1)来创建一个二维的张量
3、当dim等于1时,其内在的操作逻辑是对于src(i, j)这个值,将它放到 tensor(i, idx(i, j)) 这个位置。反之dim等于0时,其内在的操作逻辑是对于src(i, j)这个值,将它放到 tensor(idx(i, j), j)) 这个位置。
import torch # 创建一个3x5的"目标张量"(储物柜),初始为0 tensor = torch.zeros(3, 5, dtype=torch.long) # shape: [3, 5] print("初始目标张量:") print(tensor) # 创建"索引张量"(地址簿)。它的形状是 [3, 3] idx = torch.tensor([ [0, 2, 1], [2, 0, 1], [1, 2, 0] ]) # 创建"源张量"(物品),形状也是 [3, 3] src = torch.tensor([ [100, 200, 300], [400, 500, 600], [700, 800, 900] ]) # 执行分散操作 tensor.scatter_(dim=1, index=idx, src=src) print("\n分散后的目标张量:") print(tensor)
表征序数值
序数值的表征没有通用的方法,最常见的便是将这些数据视为分类数据或者连续数据
但是将序数值视为分类数据会损失排序部分,视为连续数据则会多引入一个距离的变量,即标签编码
标签编码
标签编码中最为重要的便是阈值,例如葡萄酒的质量,它可能在0~3为差,4~7为中,8~10为好,而这个范围则是区分葡萄酒质量的关键因素,也是给它们贴上该标签的原因
毫无疑问,这个标签变量就是通过对于各个数据的比较得来的,因此需要使用pytorch中张量的比较函数
import numpy as np import torch # 原始有序数据 sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL'] # 创建映射字典 size_to_int = {'XS': 0, 'S': 1, 'M': 2, 'L': 3, 'XL': 4, 'XXL': 5} # 转换为整数 int_encoded = np.array([size_to_int[s] for s in sizes]) print(f"标签映射: {int_encoded}") # 转换为PyTorch张量 tensor_encoded = torch.tensor(int_encoded, dtype=torch.float32) print(f"PyTorch张量: {tensor_encoded}")如上述代码即是将衣服的尺码大小通过标签编码得出的适用于机器学习的张量
但是标签编码有一个非常重要的缺点,其定义了一段距离,但是这段距离在不同的相邻标签之间是完全相等的,这有时并不符合现实,就比如说我们的食物,我们可以分为{还有很久才过期、还要一段时间才过期、马上过期、已经过期},很明显,对于食品安全来说,只要由任何一个过期的商品这个商品的整体分数就会大大下降,但是使用标签编码则会导致当"还有很久才过期"的食品很多时,可能会忽略"已经过期"的食品
自定义间距映射
解决上述问题也很容易想到,既然间距相同,那我们让间距不同即可,这样不同的间距其实就可以看作我们熟悉的一个名词--权重
import numpy as np import torch # 原始有序数据 sizes = ['很不满意', '不满意', '一般', '满意', '很满意', '一般'] # 创建映射字典 size_to_int = {'很不满意': 0, '不满意': 1, '一般': 2, '满意': 4, '很满意': 8} # 转换为整数 int_encoded = np.array([size_to_int[s] for s in sizes]) print(f"标签映射: {int_encoded}") # 转换为PyTorch张量 tensor_encoded = torch.tensor(int_encoded, dtype=torch.float32) print(f"PyTorch张量: {tensor_encoded}")
非线性映射
但某些有序数符合某些非线性函数是,可以直接使用numpy的函数创建相应的数组
# 使用对数函数或指数函数进行非线性变换 int_encoded = np.array([size_to_int[s] for s in sizes]) # 方法3.1:对数变换(压缩大值之间的差距) log_transformed = np.log1p(int_encoded) # log(1+x) 避免log(0) print(f"对数变换: {log_transformed}") # 方法3.2:指数变换(放大差距) exp_transformed = np.exp(int_encoded / max(int_encoded)) - 1 print(f"指数变换: {exp_transformed}")
对于1~5的评分ordered_levels = np.array(1, 2, 3, 4, 5)
|------|----------------------------------------|----------|
| 线性 | ordered_levels | 等距编码 |
| 对数强调 | np.log(ordered_levels) | 压缩高端差异 |
| 指数强调 | np.exp(ordered_levels / 5) - 1 | 放大高端差异 |
| 平方强调 | ordered_levels ** 2 | 强烈放大所有差异 |
| 正弦强调 | np.sin(2 * np.pi * ordered_levels/5) | 周期性编码 |
模型
除了上述方法之外,还有一些比较麻烦,但是效果非常好的方法,即是使用模型进行处理,比如随机森林、XGBoost等,这里不过多细说
时间序列
提取时间维度
当表格文件中含有时间,而我们也需要提取时间作为一个维度从而构成时间序列,则可以使用numpy中的loadtext和genfromtxt函数中的converts系数,该系数主要可以对任意一列或多列的元素转化为指定自定义函数,该函数一般使用匿名函数
pythonimport torch import numpy bikes_numpy = numpy.loadtxt('./bike-sharing-dataset/hour-fixed.csv', dtype = numpy.float32, delimiter = ',', skiprows = 1, converters = {1: lambda x: float(x.split('-')[2])}) bikes = torch.from_numpy(bikes_numpy)其表格中的第二列是时间,其排列表示方式为2011-01-01
调整时间数据
表格中的数据过多时,比如出现几个月乃至几年的数据时,有时需要一天一天的进行分析,那么就需要提取一天的时间出来,一天24个小时,一定要是连续时间
同时对于这种数据的表达方式为NCL(有C个通道,N个序列,一天中的L个小时)
# 24表示一天的24小时,bikes.shape[1]是值数据表格的列数即它的纪录的数据的种类 daily_bikes = bikes.view(-1, 24, bikes.shape[1]) daily_bikes = daily_bikes.transpose(1, 2) # ans:torch.Size([730, 17, 24])
准备训练
使用张量的拼接函数cat()将一天中各个信息都拼接起来,从而组成一天的数据集,对于变量我们可以进行多个维度的调整,比如将它们的维度范围映射到0.0, 1.0或者减去平均值(mean)再除以标准差(std)
拼接张量
out = torch.cat(tensor, dim)
tensor:一个张量序列(列表或元组)
dim:指定的维度,沿着该维度进行拼接。默认为0
out:输出张量
除了拼接维度dim外,其他所有张量的维度大小也必须相同输出张量的维数不变,但在dim维度上的大小是各个张量在该维度上的大小之和