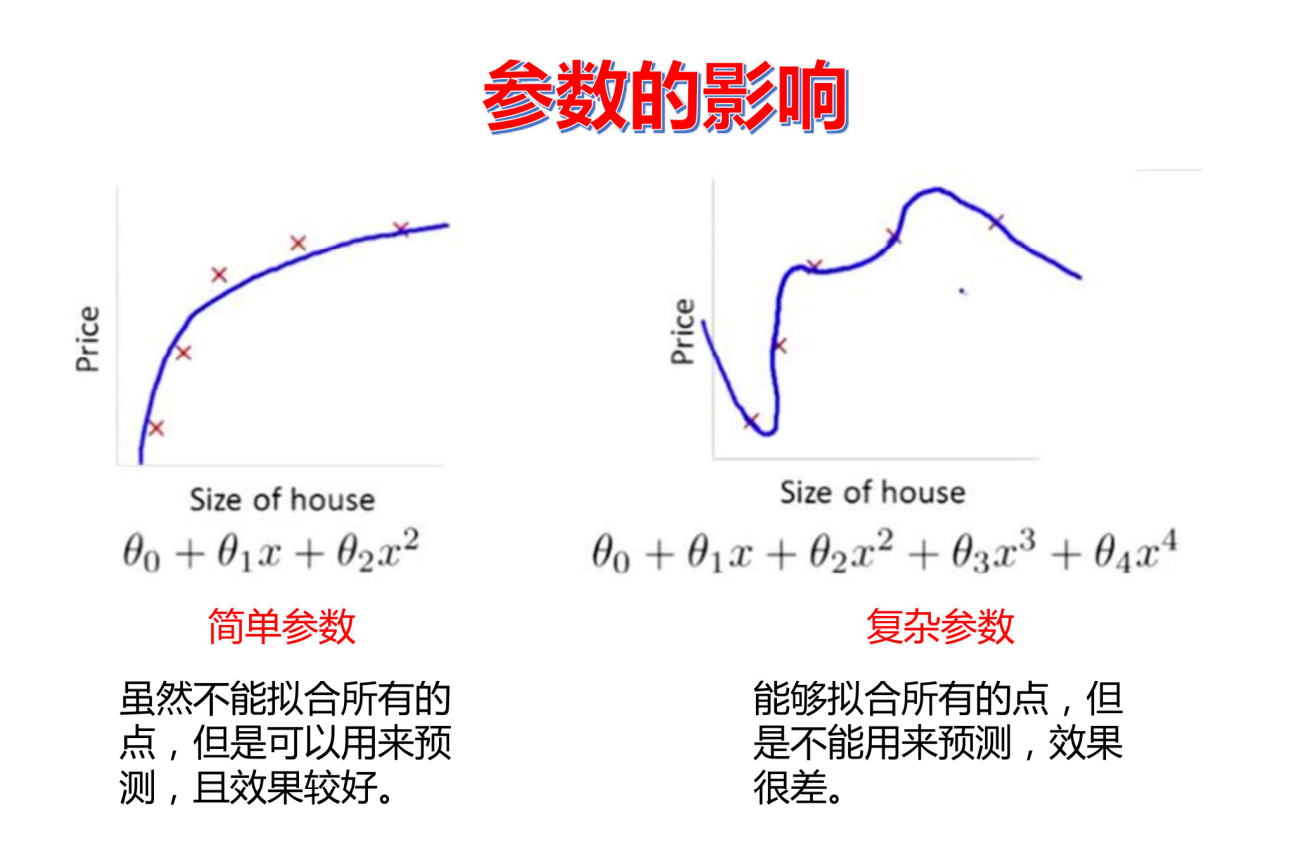
欠拟合
模型没有训练好
过拟合
模型在训练集上的表现良好,在数据集上就不行了
造成这种情况可能有以下原因:
1.模型参数过于复杂
2.训练集上为了追求好的效果(损失小,准确率高)
交叉验证
交叉验证是一种评估机器学习模型性能的统计方法,主要用于解决数据量不足时的模型泛化能力评估问题。其核心思想是将数据集划分为训练集和测试集多次,通过多次训练和测试的平均结果来评估模型。
基本流程:将原始数据随机分为训练集和测试集,用训练集训练模型,用测试集评估性能。重复多次后取平均结果,减少数据划分偶然性带来的偏差。
k折交叉验证
k折交叉验证是交叉验证的一种具体实现方式,通过将数据划分为k个大小相似的子集(称为"折"),每次使用其中k-1个子集作为训练集,剩余1个子集作为测试集,重复k次直至所有子集均被用作测试集。
具体步骤:
- 将数据集随机划分为k个互不重叠的子集。
- 对于第i次迭代(i从1到k),使用第i个子集作为测试集,其余k-1个子集合并为训练集。
- 训练模型并在测试集上评估性能,记录评估指标(如准确率、均方误差等)。
- 计算k次评估指标的平均值作为最终模型性能估计。

典型应用场景:
- 模型超参数调优(如网格搜索配合k折验证)
- 小数据集场景下减少评估结果的方差
- 对比不同算法的稳定性
常见k值选择:
- 小数据集:k=5或k=10
- 极大数据集:k=2(即留出法)
- 特殊需求:k=n(留一法,LOOCV)
优点:
- 充分利用有限数据
- 减少因数据划分随机性导致的评估波动
缺点:
- 计算成本随k值线性增长
- 数据分布不均时可能引入偏差
参数的影响
过采样
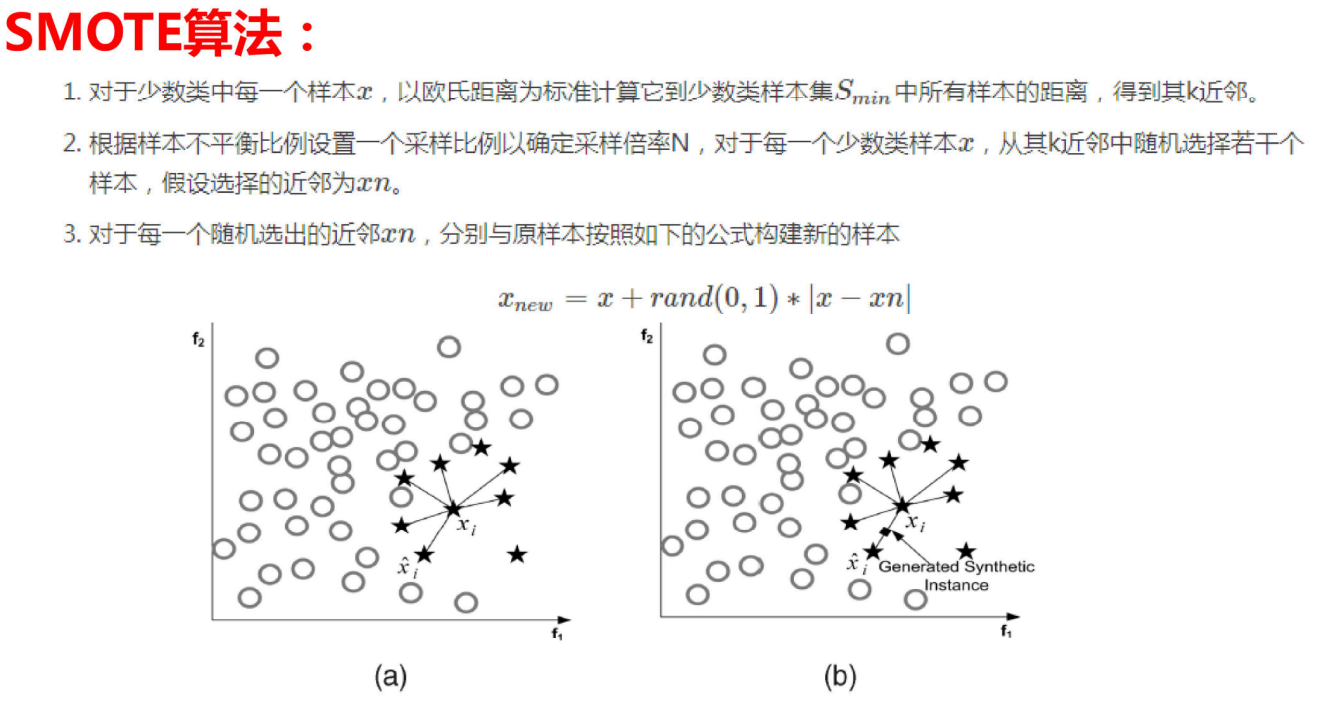
SMOTE算法:
SMOTE(Synthetic Minority Oversampling Technique)即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
项目案例:银行贷款
数据不处理
python
import pandas as pd
"读取数据"
data = pd.read_csv(r"./creditcard.csv")#出现编码问题加上encoding='utf8',无法识别加上engine='python'
print(data.head())#前5行的数据
"数据标准化处理"
from sklearn.preprocessing import StandardScaler#z标准换的函数
scaler = StandardScaler() #实例化 标准化 对象scaler
a = data[['Amount']]
b = data['Amount']
data['Amount'] = scaler.fit_transform(data[['Amount']]) #将计算后的标准差 存入data中,dataframe
print(data.head())#打印data这个表格数据的前5行
data = data.drop(['Time'],axis=1) #删除Time列的内容,axis为1表示列。
"""绘制图形,查看正负样本个数"""
import matplotlib.pyplot as plt
from pylab import mpl #matplotlib不能显示中文,借助于pylab实现中文显示
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #显示中文
mpl.rcParams['axes.unicode_minus'] = False
labels_count = pd.value_counts(data['Class'])#统计data['class']中每类的个数
print(labels_count)
plt.title("正负例样本数") #设置标题
plt.xlabel("类别") #设置x轴标题
plt.ylabel("频数") #设置y轴标题
labels_count.plot(kind='bar') #设置图像类型为bar
plt.show() #显示数据极度样本不均衡
"""建立模型"""
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
#对原始数据集进行切分
X_whole = data.drop('Class', axis=1) #删除class列,其余数据作为特征集
y_whole = data.Class #class列作为标签(label标注)
#返回的4个值,第1个:训练数据集的x特征,第2个:测试数据集的x特征。第3个:训练数据集的标签,第4个:测试数据集的标签
x_train_w, x_test_w, y_train_w, y_test_w = \
train_test_split(X_whole, y_whole, test_size = 0.3, random_state = 1000)#对数据集进行切分。
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=0.01) #先调用这个类创建一个逻辑回归对象lr C=0.001 0.01 0.1 1 10 100
lr.fit(x_train_w, y_train_w) #传入训练数据,之后的模型就会自动保存到变量lr
'''训练集预测结果'''
test_predicted = lr.predict(x_test_w)#测试集
result = lr.score(x_test_w,y_test_w)#准确率
'''打印结果'''
from sklearn import metrics
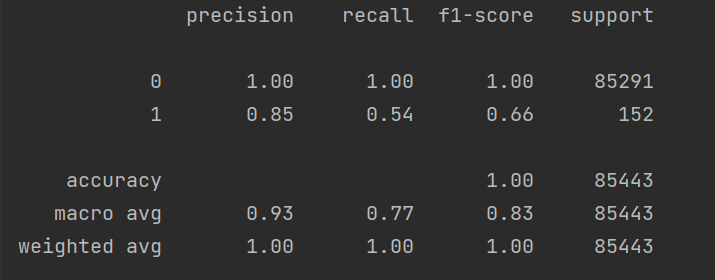
print(metrics.classification_report(y_test_w, test_predicted))可以得到模型的召回率为0.54
参数选择
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
import matplotlib.pyplot as plt
data = pd.read_csv('creditcard.csv')
scaler=StandardScaler()
data['Amount']=scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'],axis=1)
# class_=pd.value_counts(['Class'])
# class_.plot(kind='bar')
# plt.show()
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.3,random_state=400)
# train_x['Class']=train_y
# train_data = train_x
# positive_eg =train_data[train_data['Class']==0]
# negative_eg =train_data[train_data['Class']==1]
# positive_eg = positive_eg.sample(len(negative_eg))
# train_data=pd.concat([positive_eg,negative_eg])
# train_x=train_data.iloc[:,:-1]
# train_y=train_data.iloc[:,-1]
from imblearn.over_sampling import SMOTE
over_sample=SMOTE(random_state=0)
os_train_x,os_train_y = over_sample.fit_resample(train_x,train_y)
train_x,test_x,train_y,test_y=train_test_split(os_train_x,os_train_y,test_size=0.3,random_state=400)
scores=[]
c_programs=[0.01,0.1,1,10,100]
for i in c_programs:
lr=LogisticRegression(C=i,penalty='l2',max_iter=1000)
score = cross_val_score(lr,train_x,train_y,scoring='recall',cv=5)
score_ave=sum(score)/len(score)
scores.append(score_ave)
best_c=c_programs[np.argmax(scores)]
print('best_C=',best_c)
lr=LogisticRegression(C=best_c)
lr.fit(train_x,train_y)
predicted=lr.predict(test_x)
print('未调整阈值的报告:'+'\t'+metrics.classification_report(test_y,predicted))
recalls=[]
th=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
for i in th:
predicted_proba = lr.predict_proba(test_x)
predicted_proba=pd.DataFrame(predicted_proba)
predicted_proba.drop([0],axis=1)
predicted_proba[predicted_proba[[1]]>=i]=1
predicted_proba[predicted_proba[[1]]<i]=0
recall= metrics.recall_score(test_y,predicted)
recalls.append(recall)
best_th=th[np.argmax(recalls)]
print('最优阈值为:',best_th)
print('recall=',max(recalls))
# from sklearn.ensemble import RandomForestClassifier
# rf= RandomForestClassifier(
# n_estimators=80, max_features=0.8, random_state=0
# )
# rf.fit(train_x,train_y)
# print('===============自测报告==============')
# self_predicted=rf.predict(train_x)
# print(metrics.classification_report(train_y,self_predicted))
# print('===============测试报告==============')
# test_predicted=rf.predict(test_x)
# print(metrics.classification_report(test_y,test_predicted))对数据进行下采样
python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
data = pd.read_csv('creditcard.csv')
scaler=StandardScaler()
data['Amount']=scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'],axis=1)
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.3,random_state=400)
train_x['Class'] = train_y
train_data=train_x
'''下采样操作'''
positive_eg=train_data[train_data['Class']==0]
negative_eg=train_data[train_data['Class']==1]
positive_eg=positive_eg.sample(len(negative_eg))
# 拼接数据
data_c=pd.concat([positive_eg,negative_eg])
train_x=data_c.iloc[:,:-1]
train_y=data_c.iloc[:,-1]
# 交叉验证
scores=[]
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:
lr = LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score = cross_val_score(lr,train_x,train_y,cv=5,scoring='recall')
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best_c=c_param_range[np.argmax(scores)]
print('best_c=',best_c)
lr=LogisticRegression(C=best_c)
lr.fit(train_x,train_y)
predicted=lr.predict(test_x)
print(metrics.classification_report(test_y,predicted,digits=4))
# 更改阈值
thresholds=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
recalls=[]
for i in thresholds:
y_predicted_proba=lr.predict_proba(test_x)
y_predicted_proba=pd.DataFrame(y_predicted_proba)
y_predicted_proba=y_predicted_proba.drop([0],axis=1)
y_predicted_proba[y_predicted_proba[[1]] > i] = 1
y_predicted_proba[y_predicted_proba[[1]] <= i] = 0
recall=metrics.recall_score(test_y,y_predicted_proba)
recalls.append(recall)
print("{} Recall metric in the testing dataset:{:.3f}".format(i,recall))
best_t = thresholds[np.argmax(recalls)]
best_calls = max(recalls)
print("最佳阈值为:{} 对应的recalls为:{:.3f}".format(best_t,best_calls))结果如下:
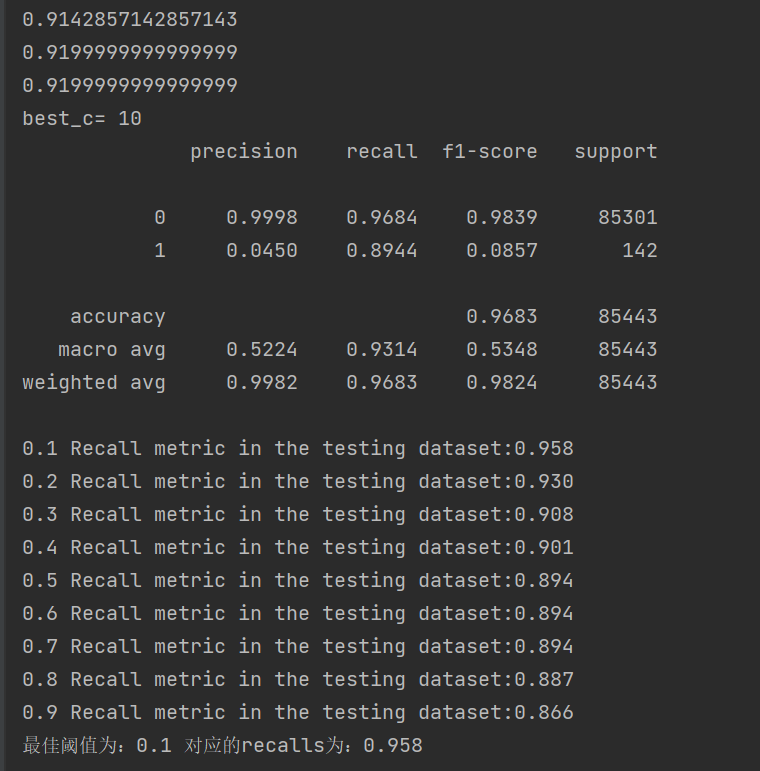
很显然,召回率有明显的上升,下采样可对模型优化的更好
对数据进行过采样
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
import time # 标准库
"""第一步:数据预处理"""
data = pd.read_csv(r"E:\xwechat_files\wxid_qi43v1w2nqcb12_e432\msg\file\2025-12\creditcard.csv", encoding='utf8', engine='python')
"""数据标准化:Z标准化"""
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'], axis=1) # 删除无用列
"""切分数据集"""
from sklearn.model_selection import train_test_split
X_whole = data.drop('Class', axis=1)
y_whole = data.Class
x_train_w, x_test_w, y_train_w, y_test_w = \
train_test_split(X_whole, y_whole, test_size=0.2, random_state=0)
"""进行过采样操作"""
from imblearn.over_sampling import SMOTE # imblearn这个库里面调用,
oversampler = SMOTE(random_state=0) # 保证数据拟合效果,随机种子
os_x_train, os_y_train = oversampler.fit_resample(x_train_w, y_train_w) # 人工拟合数据
"""绘制图形,查看正负样本个数"""
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
labels_count = pd.value_counts(os_y_train)
plt.title("正负例样本数")
plt.xlabel("类别")
plt.ylabel("频数")
labels_count.plot(kind='bar')
plt.show()
'''拟合数据集'''
os_x_train_w, os_x_test_w, os_y_train_w, os_y_test_w = \
train_test_split(os_x_train, os_y_train, test_size=0.2, random_state=0)
"""执行交叉验证操作
scoring:可选"accuracy"(精度)、recall(召回率)、roc_auc(roc值)
neg_mean_squared_error(均方误差)、
"""
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# 交叉验证选择较优惩罚因子
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
z = 1
for i in c_param_range:
start_time = time.time() #
lr = LogisticRegression(C=i, penalty='l2', solver='lbfgs', max_iter=1000)
score = cross_val_score(lr, os_x_train_w, os_y_train_w, cv=5, scoring='recall') # 没有对拟合后的数据进行切分
score_mean = sum(score) / len(score)
scores.append(score_mean)
end_time = time.time()
print("第{}次...".format(z))
print("time spend:{:.2f}".format(end_time - start_time))
print("recall:{}".format(score_mean))
z += 1
best_c = c_param_range[np.argmax(scores)]
print("最优惩罚因子为: {}".format(best_c))
"""建立最优模型"""
lr = LogisticRegression(C=best_c, penalty='l2', solver='lbfgs', max_iter=1000)
lr.fit(os_x_train, os_y_train)
from sklearn import metrics
# #训练集预测概率【大数据集】#人工拟合45w
train_predicted = lr.predict(os_x_test_w)
print(metrics.classification_report(os_y_test_w, train_predicted))
# 训练集预测概率【小数据集】 原始 28w
test_predicted = lr.predict(x_test_w)
print(metrics.classification_report(y_test_w, test_predicted))