前言
pandas 读取数据后,以 DataFrame 数据结构存储在内存中,可以通过 DdataFrame 自带的属性和方法对数据的大小、类型、分布、摘要等基本情况,进行查看。
本文以读取 Excel 文件数据为以下示例数据:
python
import pandas as pd
df = pd.read_excel('zpxx.xlsx')一、获取数据形状(行列数)
df.shape:返回几行几列(行,列),元组格式,如:(395, 23)。
可结合 len() 函数分别获取行数和列数:
行数:len(df) ,列数:len(df.columns)
python
print('数据的形状:', df.shape)
print('数据的行数', len(df))
print('数据的列数:', len(df.columns))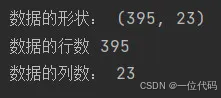
二、获取数据类型
pandas 数据类型指的是某一列所有数据的共性,默认数值型数据类型为 int64 或 float64,文本类型为 object。
df.dtypes:查看所有列的数据类型
df. 列名.dtype:查看指定列的数据类型
df.dtypes.value_counts():各个数据类型的列数(字段个数)
python、numpy、pandas数据类型对比:

三、获取数据摘要
**df.info()**函数,获取数据集摘要,语法如下:
python
DataFrame.info(verbose=None,buf=None, max_cols=None, memory_usage=None, null_counts=None)|--------------|------------------------------------------------------------------------------------|
| 常用参数 | 释义 |
| verbose | 该参数决定是否打印完整的摘要。如果为True,显示所有列的信息;如果为False,那么会省略一部分。 |
| null_counts | 该参数决定是否显示非空计数。值为True始终显示计数,而值为False则不显示计数。 |
| memory_usage | 该参数决定是否应显示DataFrame元素(包括索引)的总内存使用情况。默认情况下为True。True始终显示内存使用情况,False不会显示内存使用情况。 |
示例:显示数据的简要摘要。
python
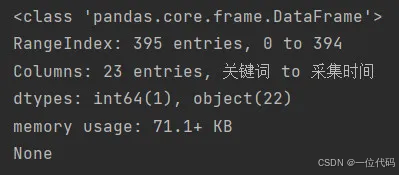
print(df.info(verbose=False)) # 简要摘要结果包括:行数(RangeIndex)、列数(Columns)、各个数据类型的列数(dtypes)等信息。
四、数据描述性统计
**describe()**函数用于生成描述性统计信息,语法如下:
python
DataFrame.describe (percentiles=None, include=None,exclude=None)描述性统计数据:
一是:数值型数据,则包括均值、标准差、最大值、最小值、四分位数等;
二是:非数值型数据,则包括类别的个数、最高数量的类别及出现次数等。
|-------------|--------------------------------------------------------------------------------------|
| 参数 | 释义 |
| percentiles | 该参数决定要包含在输出中的百分位数。所有值都应介于0和1之间。默认值为.25,.5,.75,它返回第25、50和75个百分位数。 |
| include | 该参数决定要包含在结果中的数据类型的白名单。'all':所有列将包含在输出中。dtypes的列表:将结果限制为提供的数据类型。默认情况下, 只统计数值类型数据。 |
| exclude | 该参数决定要从结果中忽略的数据类型的黑名单。dtypes的列表:从结果中排除提供的数据类型。默认情况下, 结果将不排除任何内容。 |
示例:不加任何参数,默认为只统计数值类型数据,包括均值、标准差、最大值、最小值、四分位数等。
python
print(df.describe()) # 描述性统计信息,默认只是数字列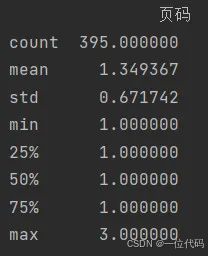
如果需要查看所有列的数据统计,可以加入参数:include='all'
python
print(df.describe(include='all')) # 所有列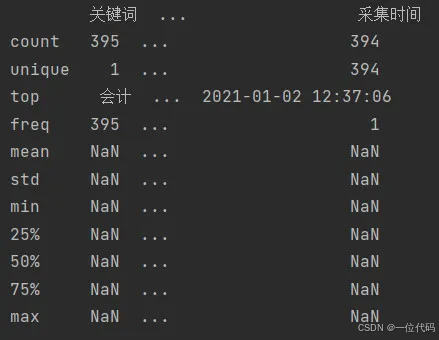
五、查看数据元素个数
**df.size:**数据中元素的个数,指的是数据的行数(395)乘以数据的列数(25)
python
print('表的元素个数::', df.size)
六、查看数据的维度
**df.ndim:**DataFrame 是一种二维表格型数据的结构,既有行索引,也有列索引。
python
print('表的维度数:', df.ndim)
七、数据转置
df.T:T属性可以实现DataFrame的转置(行列转换)
python
print('表转置后形状:', df.T.shape)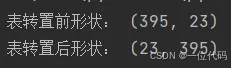
以上就是pandas查看数据大小、类型、摘要、分布的一些属性和方法,可供参考。
-end-