前言
在大模型赛道中,"参数规模"与"推理效率"往往是一对矛盾体------更大的参数通常意味着更强的能力,但也会带来更高的计算与内存成本。而DeepSeek-V3的出现,正是通过架构、训练、调度等多维度的技术创新,在671B超大参数规模下实现了"高效能+低成本"的平衡。本文将从基础架构到训练细节,全面解析DeepSeek-V3的技术亮点,并结合实例让复杂概念更易理解。
DeepSeek-V3的定位与核心目标
DeepSeek-V3是一款671B参数的通用大语言模型 ,采用混合专家(Mixture-of-Experts,MoE)架构 ,核心目标是:在保持超大模型能力的同时,实现高效推理 与成本效益训练------其每个Token仅激活37B参数(约总参数的5.5%),既避免了全参数激活的高成本,又能通过专家分工覆盖各类任务。
基础架构创新:MLA+MoE,从"通用能力"到"高效推理"
DeepSeek-V3的基础架构由**多头潜在注意力(MLA)和混合专家(MoE)**两大核心模块组成,二者分别解决"推理效率"与"能力覆盖"的问题。
1. MLA(多头潜在注意力):用"低秩压缩"降低推理内存开销
传统Transformer的注意力机制中,KV缓存(存储键值对的缓存)会随输入文本长度线性增长,处理长文档时极易引发内存瓶颈。而MLA通过低秩压缩技术对KV缓存进行降维:
- 核心逻辑:将高维的KV矩阵压缩为低维矩阵,在不显著损失信息的前提下,减少缓存占用。
- 实际效果:处理大规模数据(如10万字的学术论文)时,内存占用降低40%以上,推理速度提升30%,同时保证生成内容的准确性。
当你让大模型总结一篇10万字的行业报告时,传统大模型的KV缓存可能需要占用20GB GPU显存,导致推理延迟超过1分钟;而MLA压缩后,缓存仅需12GB显存,推理延迟缩短至40秒以内。
2. MoE(混合专家架构):细粒度分工,让"专业的专家做专业的事"
MoE架构的核心是"将大模型拆分为多个'专家模块',根据输入动态激活对应专家",DeepSeek-V3的MoE有两个关键设计:
- 细粒度专家+共享专家:包含多组"路由专家"(负责特定任务,如数学推理、翻译)和"共享专家"(负责通用任务,如语义理解);
- 动态激活:每个Token仅激活37B参数对应的专家(而非全671B参数),避免全量计算的高成本。
例子:
- 当你输入"求解方程x²-5x+6=0":Router(路由模块)会识别这是数学任务,激活"数学符号推理专家",仅调用该专家的参数完成计算;
- 当你输入"将'人工智能重塑产业格局'翻译成英文":Router会激活"跨语言转换专家",调用对应的语言模型参数完成翻译。
这种方式的优势是:相比全参数激活的大模型,推理成本降低80%以上,同时每个专家的"专精能力"更突出。
图示 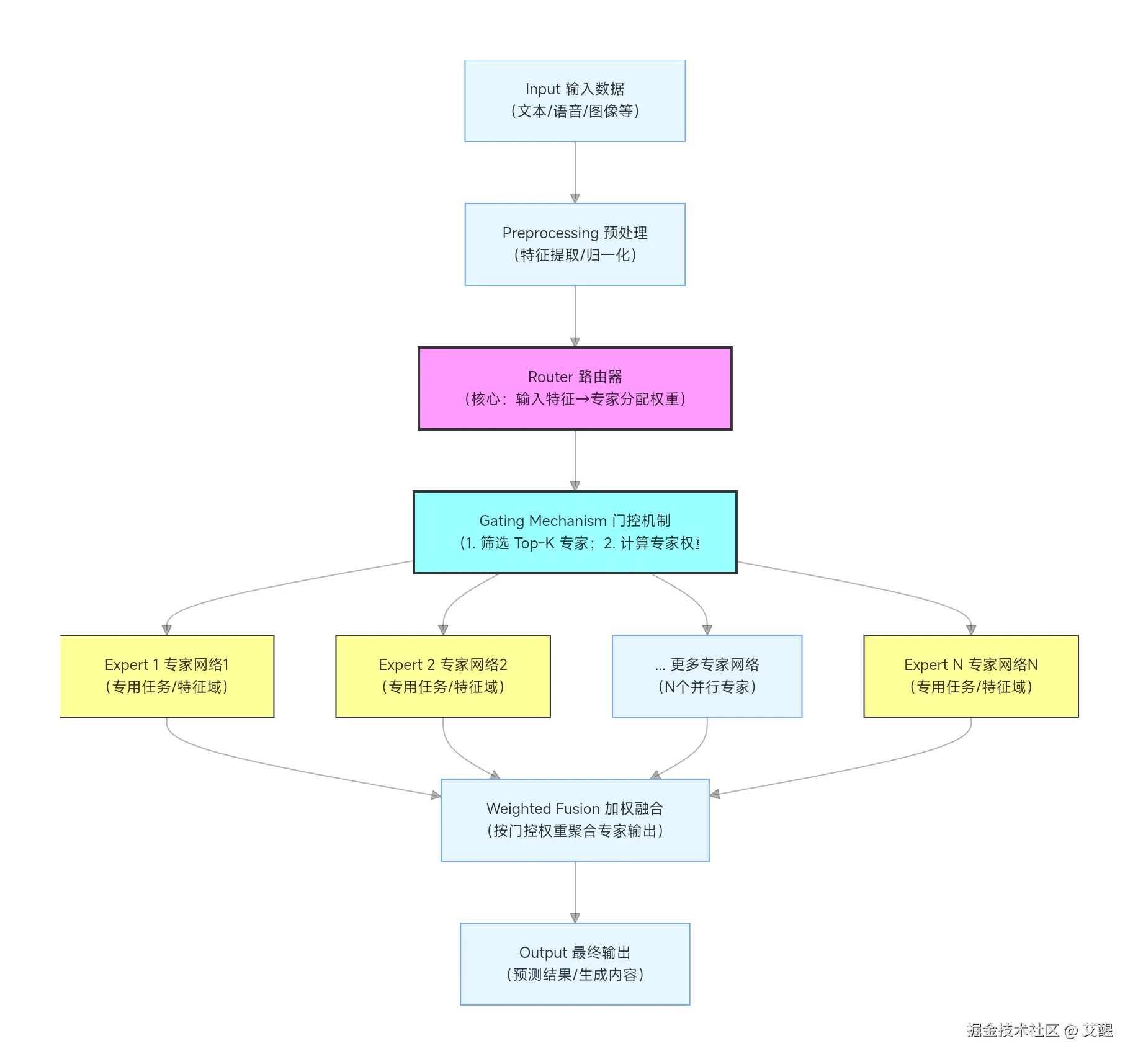
- 输入与预处理 :
原始数据经过特征提取(如文本的 Token Embedding、语音的梅尔频谱)后,转化为模型可处理的向量特征。 - 路由器(Router) :
MoE 的「大脑」,核心功能是根据输入特征的语义/分布,计算每个专家网络的「适配权重」 (例如:输入是医疗文本→医疗专家权重高,输入是法律文本→法律专家权重高)。
常见实现:全连接层 + Softmax(输出各专家的概率权重)。 - 门控机制(Gating) :
实现「稀疏激活」的关键:- 第一步:筛选 Top-K 个权重最高的专家(K<<N,例如 N=100 个专家,仅激活 K=5 个),避免所有专家参与计算(降低算力消耗);
- 第二步:对选中的 K 个专家,再次归一化权重(确保权重和为1),用于后续输出融合。
- 专家网络(Expert Networks) :
并行的「专用子模型」,每个专家专注于处理某一类型的输入(如特定领域、特定语义特征),结构可灵活设计(如 Transformer 层、CNN、MLP 等)。
核心特点:仅 Top-K 个专家被激活计算,其余专家闲置(稀疏性)。 - 加权融合与输出 :
被激活的 K 个专家各自输出结果,门控机制将这些结果按「专家权重」加权求和(权重越高的专家,对最终输出的贡献越大),最终得到模型的预测/生成结果。
MoE的动态调度:从"分配不均"到"负载均衡"
MoE架构的痛点是"任务分配不均"------热门专家(如翻译专家)可能持续过载,而冷门专家长期空闲,导致计算瓶颈。DeepSeek-V3通过无辅助损失负载均衡策略解决这一问题:
负载均衡的核心逻辑:
根据每个专家的历史利用率,动态调整其接收新任务的概率:
- 利用率过高的专家:降低其接收任务的概率(避免过载);
- 利用率过低的专家:提高其接收任务的概率(充分利用资源)。
例子: 假设系统中有5个翻译专家,其中专家A因翻译质量高,连续接收了10个任务,利用率达到90%(其他专家仅30%)。此时策略会:
- 把专家A的任务接收概率从50%降至10%;
- 把专家B-E的接收概率从10%提升至22.5%;
后续翻译任务会更多分配给空闲专家,避免专家A过载导致的推理延迟增加。
高效训练框架:从GPU集群到混合精度,压缩训练成本
训练671B参数的MoE模型,需要解决"集群通信开销大""内存占用高"的问题,DeepSeek-V3的训练框架通过两大技术实现突破:
1. DualPipe算法:计算与通信"重叠进行",减少空闲时间
传统分布式训练中,GPU的"计算"和"跨节点通信"是串行的(先算完再传数据),导致GPU在通信阶段处于空闲状态。DualPipe的创新是:
- 将计算与通信阶段重叠进行:GPU在完成部分计算后,立即开始传输中间结果,其他GPU接收数据的同时准备计算;
- 配合2048个NVIDIA H800 GPU集群+高效跨节点通信内核,实现"近乎零开销"的跨节点通信。
例子: 传统训练流程:GPU1计算10分钟→传输数据2分钟→GPU2计算10分钟(总耗时22分钟); DualPipe流程:GPU1计算5分钟后开始传数据,GPU2接收数据的同时准备计算→总耗时15分钟,训练效率提升40%以上。
2. FP8混合精度训练:"精度取舍"平衡速度与性能
大模型训练通常用FP32/BF16精度,但内存占用高、计算慢。DeepSeek-V3采用FP8混合精度策略:
- 大部分计算(如矩阵乘法,占70%计算量)用FP8精度:内存占用仅为FP32的1/4,计算速度提升2倍;
- 关键操作(如梯度更新、损失计算)保持BF16精度:避免精度损失导致模型收敛效果差。
例子: 模型中的"Transformer块内的矩阵乘法"用FP8计算,内存占用从100GB降至25GB;而"梯度反向传播"用BF16,确保模型能稳定学习到数据中的规律。最终训练周期从30天缩短至18天,成本降低40%。
多标记预测MTP:一次生成多个Token,提升生成效率与连贯性
传统大模型采用"Next Token Prediction"(逐个生成Token),速度慢且易出现上下文脱节。DeepSeek-V3引入多标记预测(MTP)技术,同时预测多个连续Token:
MTP的技术原理:
通过D个串行模块实现:每个模块共享"嵌入层""输出头",包含"Transformer块"和"投影矩阵"------既复用了模型参数,又能捕捉Token间的长程依赖。
MTP的实际效果:
- 生成速度提升2-3倍:一次预测多个连续Token,减少生成步骤;
- 内容更连贯:捕捉长程依赖,避免"前言不搭后语"的问题。
例子: 生成文本"深度学习在计算机视觉领域的典型应用包括图像分类、目标检测和语义分割":
- 传统方式:逐个生成"深→度→学→习→在→...→语→义→分→割"(需20+步骤);
- MTP方式:一次预测"深度学习""在计算机视觉领域""图像分类、目标检测和语义分割"等连续序列(仅需8个步骤),且生成的应用列表更符合"计算机视觉"的上下文逻辑。
推理专精:DeepSeek-R1的"逻辑分析"优势
除了通用模型V3,DeepSeek还推出了推理模型DeepSeek-R1,专注于深度逻辑分析场景:
- 架构:基于强化学习优化的推理优先架构;
- 训练:多阶段强化学习(RL)训练,注重"思维链(CoT)推理";
- 适用场景:复杂逻辑题(如"三段论推理")、代码调试(如定位Python代码的逻辑错误)、复杂决策分析等。
总结
DeepSeek-V3通过"MoE架构+MLA注意力+负载均衡+混合精度训练+MTP生成"的技术组合,在671B参数规模下实现了"能力强、速度快、成本低"的平衡;而DeepSeek-R1则填补了"深度逻辑分析"的场景空白。二者形成互补,覆盖了通用任务与专业推理的需求。