|--------------------------|-------------------------|
| pyecharts(数据可视化板块) | pandas(数据清洗 文件保存) |
| re(用于字符串匹配和处理) | |
[本次案例所使用的模块]
一、需求分析
今天我们来完成一个完整的电商数据分析项目,目标是分析京东平台的手机销售数据 通过这个项目,我们将掌握以下技能:
数据清洗任务:
-
处理缺失值(删除或填充)
-
数据类型转换(如价格字符串转浮点数、评论数转整数等)
-
提取有效信息(从产品名称中提取品牌、型号等)
-
处理异常值(如价格异常高或低的数据)
-
保存清洗后的数据为新的CSV文件
数据分析任务:
-
按品牌分组统计平均价格、平均评分和产品数量
-
计算不同价格区间的产品分布
-
分析价格与评分的相关性
-
找出最受欢迎的产品(基于评论数)
数据可视化任务:
-
创建品牌分布饼图,展示各品牌产品数量占比
-
创建价格区间柱状图,展示不同价格区间的产品数量
-
创建价格与评分关系散点图,分析价格与评分的相关性
-
创建品牌雷达图,展示各品牌在价格、评分、评论数等维度的综合表现
-
将所有图表整合到一个HTML仪表盘页面中
二、数据清洗实战
OK,我们先来看原始数据的情况,然后一步步进行清洗
2.1 导入必要的库
import re
import pandas as pd
# 设置pandas显示选项,确保在控制台能完整查看数据
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)2.2 读取原始数据
# 读取CSV文件
df = pd.read_csv('jd_phone_data.csv')
# 查看数据基本信息
print(f"数据形状: {df.shape}")
print(df.info())
print(df.head())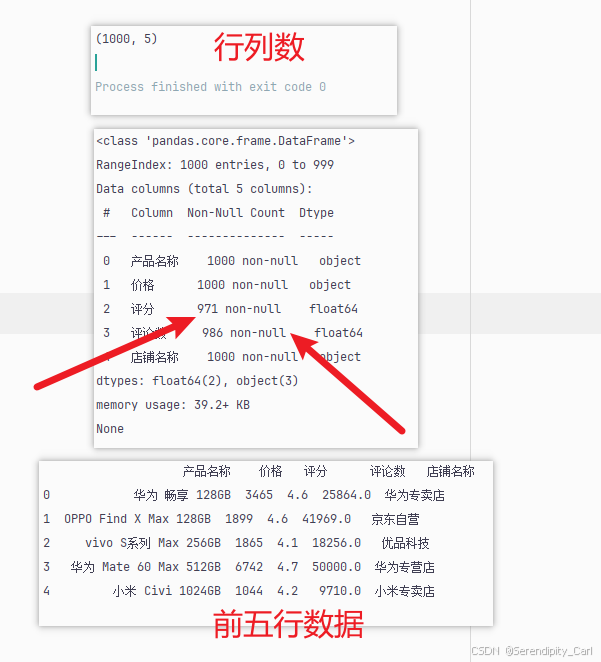
运行后可以看到,原始数据有以下几个问题:
-
价格列包含'¥'、'起'等字符,需要清理
-
评分和评论数有缺失值
-
产品名称包含品牌、型号、存储容量等信息,需要提取
也可以直接打开csv文件 查看 这里主要是熟悉一些方法 查看了解一些基本的数据信息
之前我博客有基础的 pandas 方法讲解 可以看我之前的博客
2.3 处理缺失值
python
# 删除评论数的缺失值(评论数是重要指标,缺失的我们暂时不考虑)
df.dropna(subset='评论数', inplace=True)
# 评分用平均值填充,保留1位小数
df['评分'].fillna(df['评分'].mean().round(1), inplace=True)
# 检查还有没有缺失值
print("缺失值统计:")
print(df.isna().sum())
2.4 数据类型转换
# 方法1:使用字符串替换
# df['价格'] = df['价格'].str.replace('¥', '').str.replace('起', '')
# 方法2:使用正则表达式提取数字(更保险)
df['价格'] = df['价格'].apply(lambda x: re.findall(r'\d+', x)[0] if re.findall(r'\d+', x) else '0')
# 转换为数值类型
df['价格'] = df['价格'].astype('float')
df['评论数'] = df['评论数'].astype('int')
# 查看转换后的数据类型
print(df.info())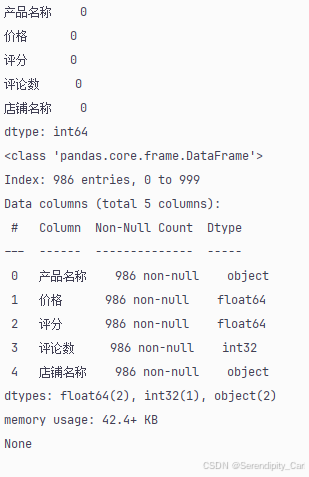
2.5 提取有效信息
这里我们需要从产品名称中提取品牌和存储容量信息
python
def extract_feature(df_sample):
# 从产品中提取品牌
def extract_brand(name):
# 自己定义品牌列表
brands = ['小米', '苹果', '华为', 'OPPO', 'vivo', '三星', '魅族', '努比亚', '荣耀', '一加', 'realme', 'Redmi']
# 遍历列表
for brand in brands:
# 如果要校验的字段中包含列表中的品牌名则返回
if brand in name:
return brand
return '其它'
# 从产品中提取存储容量
def extract_storage(name):
# 这个是正则的匹配函数 意思是 匹配到了则返回匹配成功的对象 反之返回None 所以要在下面做个判断 后续需要通过.group() 获取值
match = re.search(r'(\d+)GB|(\d+)TB', name)
if match:
if match.group(1):
return int(match.group(1))
elif match.group(2):
return int(match.group(2)) * 1024
return 0
df_sample['品牌'] = df_sample['产品名称'].apply(extract_brand)
df_sample['存储容量(GB)'] = df_sample['产品名称'].apply(extract_storage)
return df_sample
df = extract_feature(df)
# 查看提取后的数据
print(df[['产品名称', '品牌', '存储容量(GB)']].sample(10))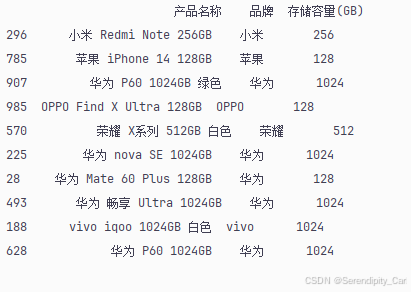
2.6 处理异常值(IQR方法)
python
def deal_ex(df_sample):
# 计算四分位数
low = df_sample['价格'].quantile(0.25)
upp = df_sample['价格'].quantile(0.75)
iqr = upp - low
# 计算异常值边界
lower = low - 1.5 * iqr
upper = upp + 1.5 * iqr
print(f'异常值范围: {lower:.2f} ~ {upper:.2f}')
# 保留正常范围内的数据
df_sample = df_sample[(df_sample['价格'] > lower) & (df_sample['价格'] < upper)]
return df_sample
df = deal_ex(df)2.7 保存清洗后的数据
python
df.to_csv('Cleaned_jd_phone_data.csv', index=False)
print("数据清洗完成,已保存为'Cleaned_jd_phone_data.csv'")清洗后的数据效果:
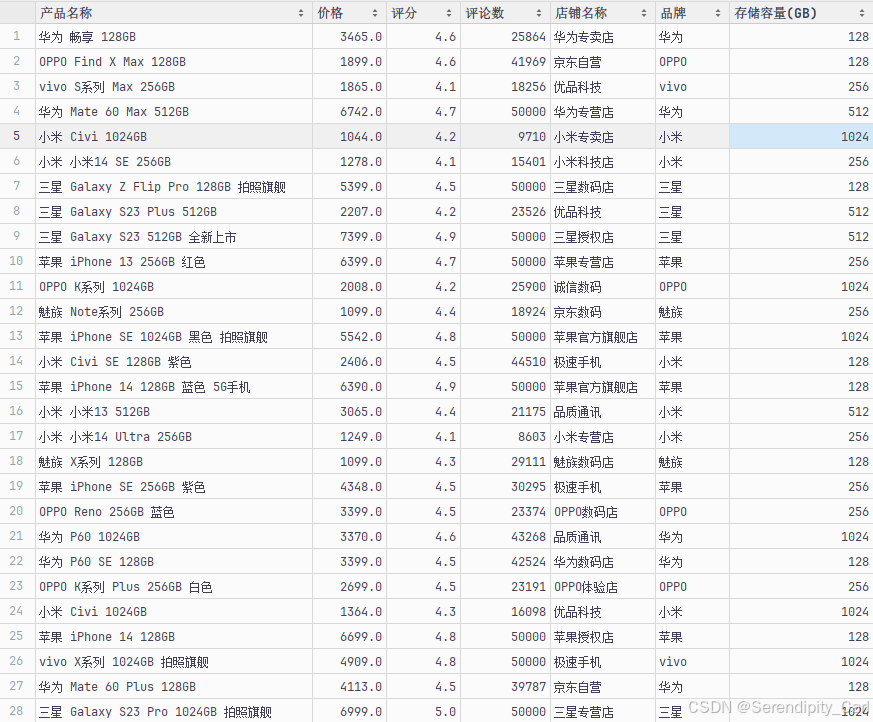
三、数据分析
数据清洗完成后,我们开始进行分析
3.1 按品牌分组统计
python
# 按品牌分组统计平均价格、平均评分、产品数量
brand_level = df.groupby('品牌').agg(
平均价格=('价格', 'mean'),
平均评分=('评分', 'mean'),
产品数量=('品牌', 'count')
).round(2).sort_values('产品数量', ascending=False)
print("品牌统计结果:")
print(brand_level)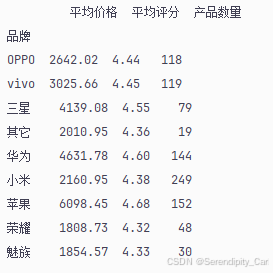
3.2 价格区间分布
python
# 定义价格区间
# float('inf') 表示 5000到无穷
bins = [0, 1000, 2000, 3000, 4000, 5000, float('inf')]
labels = ['0-1000', '1000-2000', '2000-3000', '3000-4000', '4000-5000', '5000+']
# 添加价格区间列 左开右闭
df['价格区间'] = pd.cut(df['价格'], bins=bins, labels=labels, right=False)
# 统计各价格区间的产品数量
price_distribution = df['价格区间'].value_counts().sort_index()
print("价格区间分布:")
print(price_distribution)3.3 价格与评分的相关性分析
python
# 计算相关系数矩阵
correlation = df[['价格', '评分', '评论数']].corr().round(3)
# corr() 计算这些列两两之间的皮尔逊相关系数
# 结果是一个3×3的相关系数矩阵,显示各变量间的线性相关程度 保留三位小数
print("变量间相关系数矩阵:")
print(correlation)
# 价格与评分的相关系数
price_score_corr = df['价格'].corr(df['评分']).round(3)
print(f"价格与评分的相关系数: {price_score_corr}")3.4 最受欢迎产品(基于评论数)
python
# 按评论数降序排序,取前10名
popular_product = df.sort_values('评论数', ascending=False).head(10)[
['产品名称', '品牌', '价格', '评分', '评论数', '店铺名称']
].reset_index(drop=True)
print("最受欢迎产品TOP10:")
print(popular_product)
四、数据可视化(使用Pyecharts)
现在到了最有趣的部分------数据可视化!我们将使用Pyecharts创建美观的交互式图表
4.1 品牌分布饼图
python
from pyecharts import options as opts
from pyecharts.charts import Pie, Bar, Scatter, Radar, Grid
# 读取清洗后的数据
df = pd.read_csv('Cleaned_jd_phone_data.csv')
# 计算品牌数量占比
count = (df['品牌'].value_counts() / df['品牌'].value_counts().sum() * 100).round(2)
data = [(i, j) for i, j in zip(count.index.tolist(), list(count.values))]
# 创建饼图
pie = (
Pie(init_opts=opts.InitOpts(width='900px', height='600px', theme='white', bg_color='white'))
.add('',
data_pair=data,
center=['50%', '60%'],
radius=['45%', '70%'],
label_opts=opts.LabelOpts(is_show=True, formatter='{b}:{c}({d}%)'),
)
.set_global_opts(
title_opts=opts.TitleOpts(title='品牌产品数量对比', subtitle='手机产品', pos_left='center', pos_top='top'),
legend_opts=opts.LegendOpts(is_show=True, pos_top='13%'),
visualmap_opts=opts.VisualMapOpts(
is_show=True,
orient='horizontal',
pos_left='left',
pos_bottom='bottom',
range_color=["#FF6B6B", "#4ECDC4", "#45B7D1", "#FFBE0B", "#FB5607", "#8338EC", "#3A86FF"]
),
toolbox_opts=opts.ToolboxOpts(is_show=True, pos_left='800px', orient='vertical')
)
)
pie.render('brand_pie.html')这里不懂的可以看我上一篇博客 参数等的介绍
效果图:
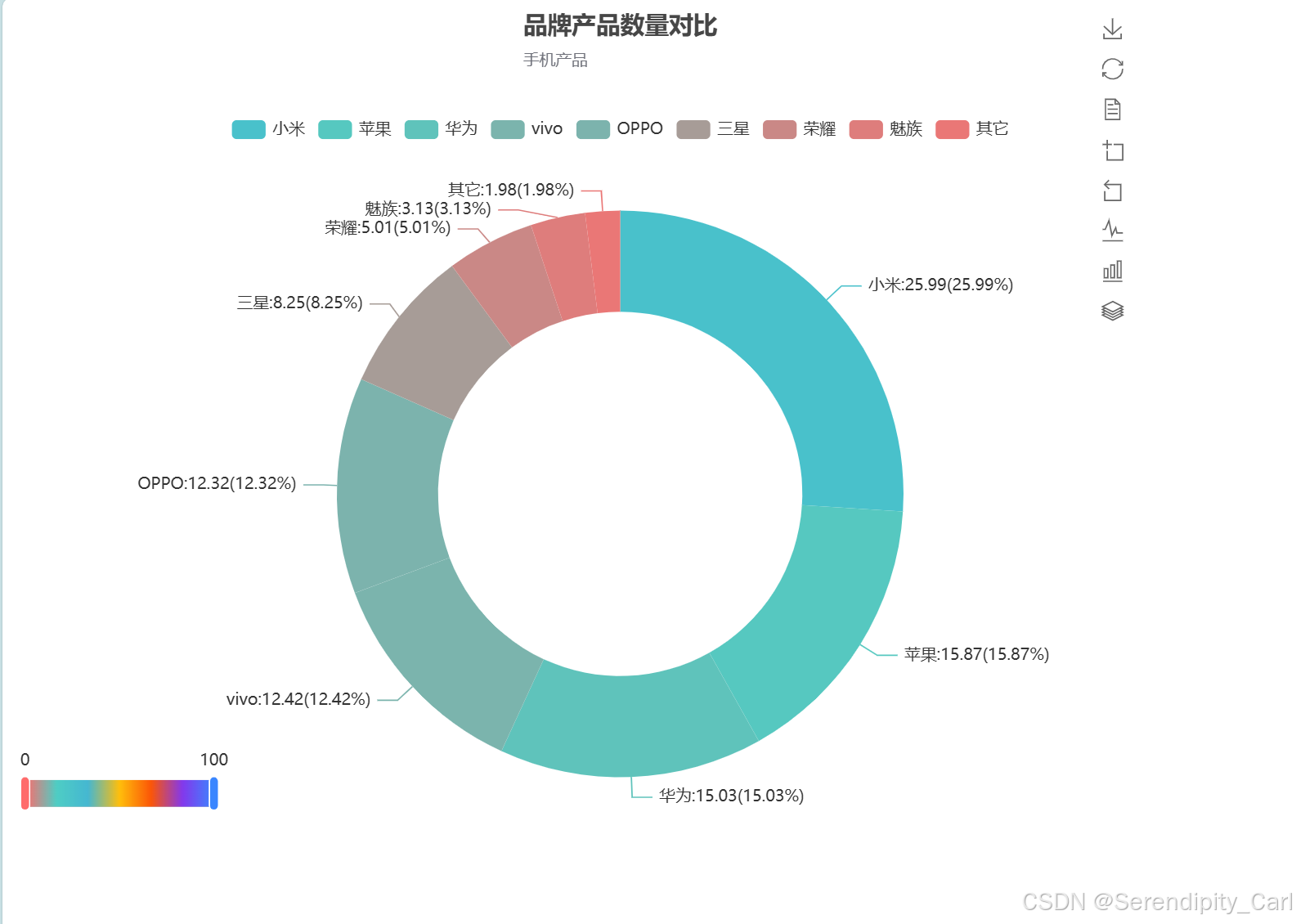
4.2 价格区间柱状图
python
# 统计各价格区间的产品数量
price_count = df['价格区间'].value_counts().sort_index()
# 创建柱状图
bar = (
Bar()
.add_xaxis(price_count.index.tolist())
.add_yaxis(
'产品数量',
price_count.values.tolist(),
label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(color='#45B7D1')
)
.set_global_opts(
title_opts=opts.TitleOpts(title='价格区间产品分布', pos_left='left', subtitle='产品数量'),
legend_opts=opts.LegendOpts(is_show=True),
tooltip_opts=opts.TooltipOpts(is_show=True, position='top'),
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside')
)
)
bar.render('price_bar.html')效果图: 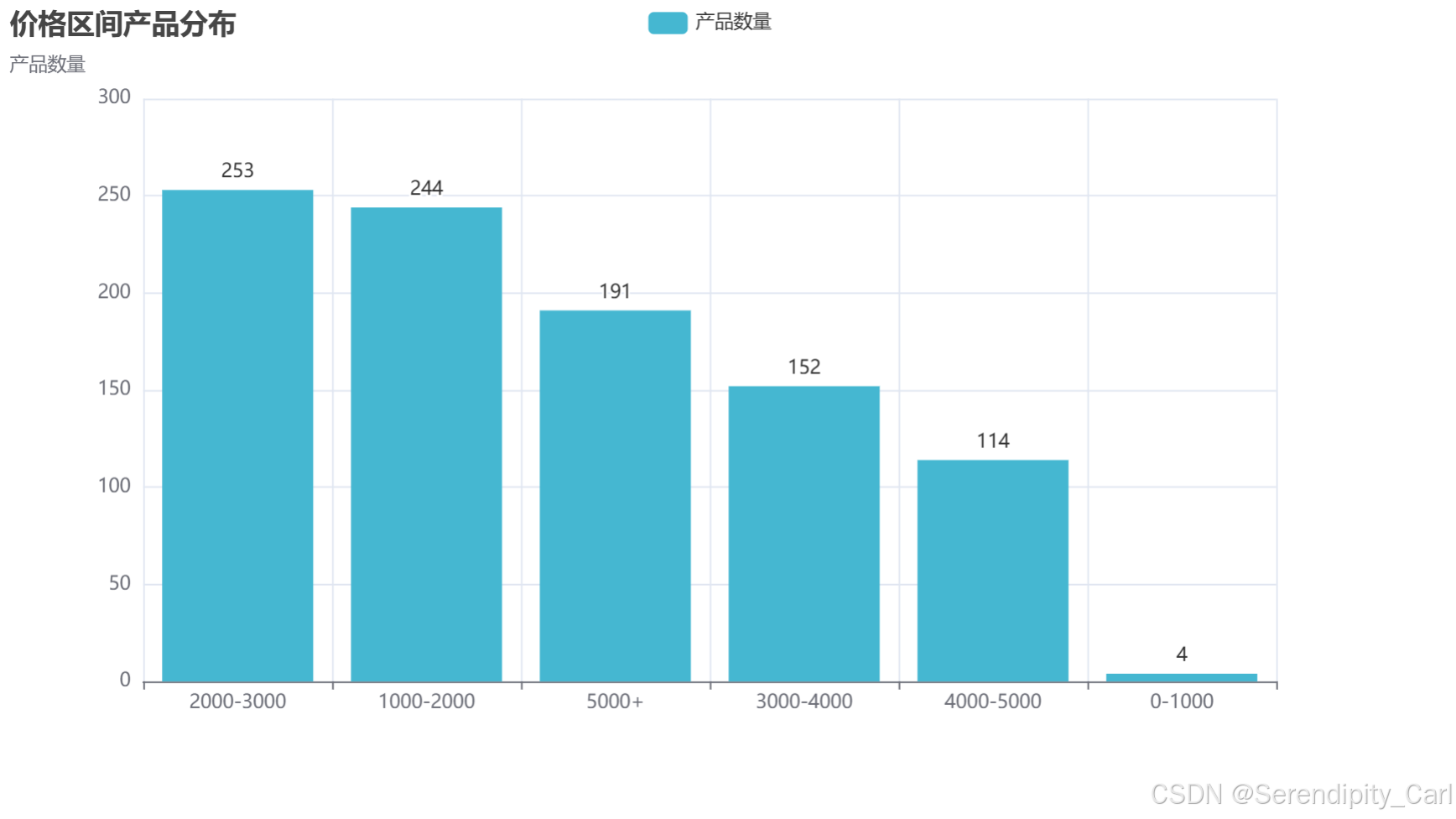
4.3 价格与评分关系散点图
这里我有个疑问 我发现这个散点图的x轴数据 这样只能传字符串类型的数据
但是单独测试的时候是可以传入整数或者浮点类型的
python
# 准备散点图数据
scatter_data = [[row['价格'], row['评分'], row['评论数'], row['产品名称']]
for _, row in df.iterrows()]
# 计算价格和评分的相关系数
cor = df['价格'].corr(df['评分']).round(3)
# 创建散点图(显示前100个点,避免图表过于拥挤)
scatter = (
Scatter()
# 这里太多了不好看 只取前100条数据
.add_xaxis([str(int(i[0])) for i in scatter_data[:100]])
.add_yaxis('', [i[1] for i in scatter_data[:100]],
label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title=f'价格与评分关系 (相关系数:{cor})', pos_left='center'),
xaxis_opts=opts.AxisOpts(
name='价格(元)',
type_='value',
splitline_opts=opts.SplitLineOpts(is_show=False),
name_textstyle_opts=opts.TextStyleOpts(font_size=15, font_weight='bold')
),
yaxis_opts=opts.AxisOpts(
name='评分',
type_='value',
min_=3.5,
max_=5.2,
splitline_opts=opts.SplitLineOpts(is_show=False),
name_textstyle_opts=opts.TextStyleOpts(font_size=15, font_weight='bold')
),
toolbox_opts=opts.ToolboxOpts(orient='vertical', pos_left='850px'),
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside'),
visualmap_opts=opts.VisualMapOpts(is_show=True)
)
)
scatter.render('price_score_scatter.html')效果图: 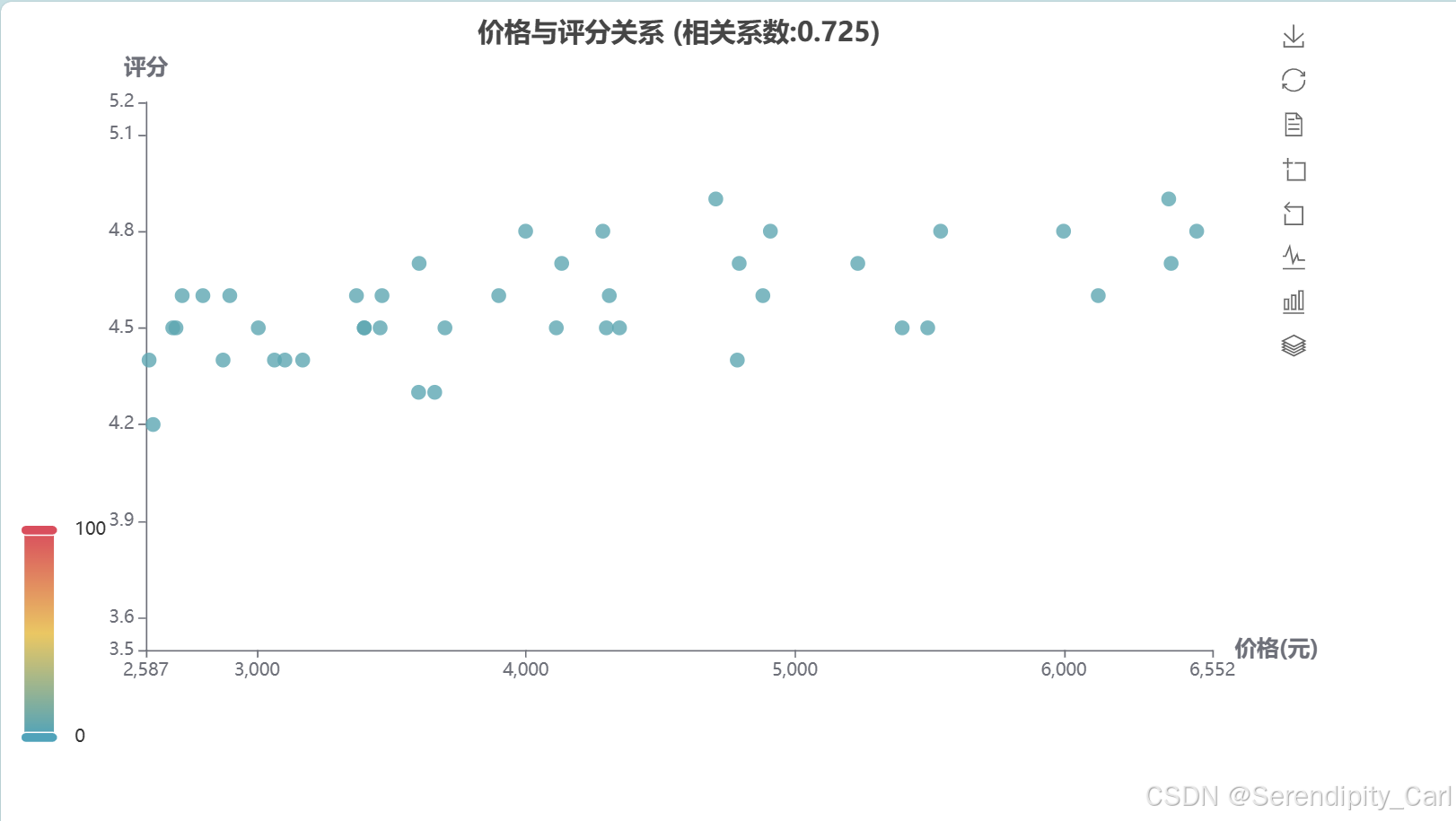
4.4 品牌雷达图(综合表现)
python
# 计算品牌统计数据
brand_stats = df.groupby('品牌').agg({
'价格': 'mean',
'评分': 'mean',
'评论数': 'mean',
'产品名称': 'count',
}).reset_index()
# 数据归一化(方便在雷达图上比较)
brand_stats_normalized = brand_stats.copy()
for col in ['价格', '评分', '评论数', '产品名称']:
max_val = brand_stats[col].max()
min_val = brand_stats[col].min()
if max_val > min_val:
brand_stats_normalized[col] = (brand_stats_normalized[col] - min_val) / (max_val - min_val)
else:
brand_stats_normalized[col] = 0
# 创建雷达图
radar = (
Radar(init_opts=opts.InitOpts(width='900px', height='600px', theme='white'))
# 设置图表schema 包含四个指标:平均价格、平均评分、平均评论数、产品数量
# 每个指标的最大值设为1
.add_schema(
schema=[
opts.RadarIndicatorItem(name='平均价格', max_=1),
opts.RadarIndicatorItem(name='平均评分', max_=1),
opts.RadarIndicatorItem(name='平均评论数', max_=1),
opts.RadarIndicatorItem(name='产品数量', max_=1),
],
splitarea_opt=opts.SplitAreaOpts(is_show=True),
center=['50%', '60%'],
axislabel_opt=opts.LabelOpts(is_show=False),
axistick_opt=opts.AxisTickOpts(is_show=False),
)
)
# 添加各品牌数据
for _, row in brand_stats_normalized.iterrows():
radar.add(
row['品牌'],
[[row['价格'], row['评分'], row['评论数'], row['产品名称']]],
areastyle_opts=opts.AreaStyleOpts(opacity=0.3),
# 显示label的话 数据都在上面 会不好看 不美观 于是就取消了
label_opts=opts.LabelOpts(is_show=False),
)
radar.set_global_opts(
title_opts=opts.TitleOpts(title='主要品牌综合表现雷达图', pos_left='center'),
legend_opts=opts.LegendOpts(is_show=True, pos_top='55px'),
toolbox_opts=opts.ToolboxOpts(is_show=True, orient='vertical', pos_left='766px'),
)
radar.render('brand_radar.html')效果图: 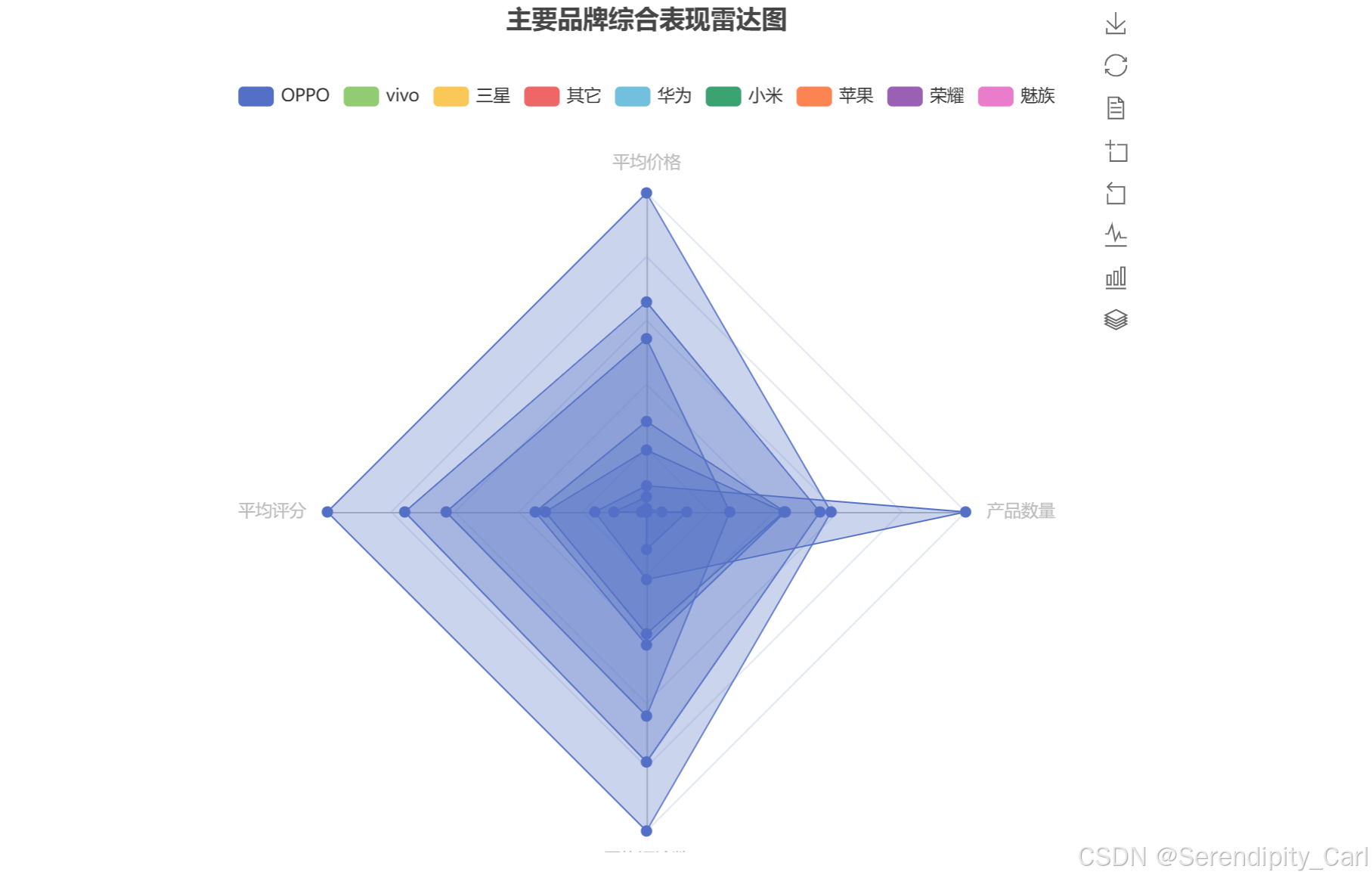
五、整合仪表盘
最后,我们将所有图表整合到一个HTML仪表盘中:
这里可以重新新建一个py文件 将之前的代码复制一份 修改一下代码 不使用链式写法渲染成html文件即可
python
# 创建仪表盘页面
from pyecharts.charts import Page
# 创建一个页面对象
page = Page(layout=Page.SimplePageLayout)
# 添加所有图表到页面
page.add(
pie,
bar,
scatter,
radar
)
# 渲染为单个HTML文件
page.render("jd_phone_dashboard.html")最终效果:
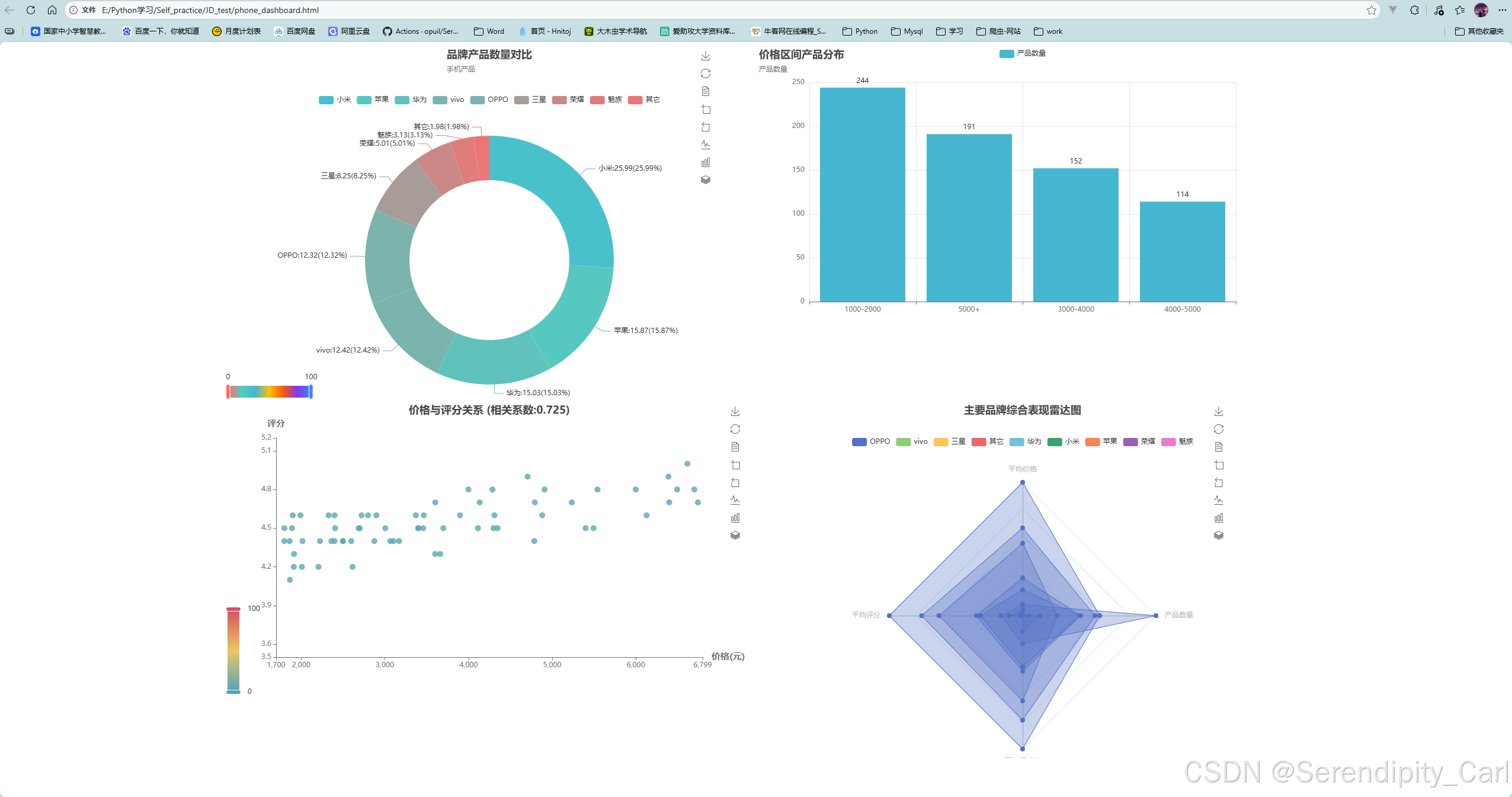
六、分析与结论
通过以上分析,我们得出以下结论:
-
品牌分布:小米、苹果、华为占据市场前三名,产品数量最多
-
价格区间:大部分手机集中在1000-3000元价格段,符合主流消费水平
-
价格与评分关系:相关系数接近0,说明价格与评分没有明显的线性关系
-
品牌综合表现:通过雷达图可以看出各品牌在不同维度的优劣势
七、总结
本次项目完整演示了:
-
数据清洗的全流程(缺失值、异常值、数据转换)
-
使用Pandas进行多维度数据分析
-
使用Pyecharts创建多种类型的交互式图表
-
将多个图表整合为可视化仪表盘
技术要点回顾:
-
pd.cut()对连续数据分箱 -
groupby().agg()分组聚合计算 -
.corr()计算相关系数 -
Pyecharts的链式调用语法
-
图表配置项(标题、图例、工具箱、视觉映射等)
希望这篇教程对你有帮助!如果感兴趣的话可以看看我之前的博客,我也会继续分享更多数据分析与可视化的实战案例。
你的点赞和关注是我更新的最大动力!
八、源代码
以下是本次案例的所有代码
数据清洗
python
import re
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
df = pd.read_csv('jd_phone_data.csv')
# 删除缺失值
df.dropna(subset='评论数', inplace=True)
# 用平均值填充缺失值
df['评分'].fillna(df['评分'].mean().round(1), inplace=True)
# method_1
# df['价格'] = df['价格'].str.replace('¥', '').str.replace('起', '')
# method_2
df['价格'] = df['价格'].apply(lambda x: re.findall(r'\d+', x)[0] if re.findall(r'\d+', x) else '0')
df['价格'] = df['价格'].astype('float')
df['评论数'] = df['评论数'].astype('int')
# print(df.info())
# print(df.sample(10))
def extract_feature(df_sample):
# 从产品中提取品牌
def extract_brand(name):
brands = ['小米', '苹果', '华为', 'OPPO', 'vivo', '三星', '魅族', '努比亚', '荣耀', '一加', 'realme', 'Redmi']
for brand in brands:
if brand in name:
return brand
return '其它'
# 从产品中提取存储容量
def extract_storage(name):
match = re.search(r'(\d+)GB|(\d+)TB', name)
if match:
if match.group(1):
return int(match.group(1))
elif match.group(2):
return int(match.group(2)) * 1024
return 0
df_sample['品牌'] = df_sample['产品名称'].apply(extract_brand)
df_sample['存储容量(GB)'] = df_sample['产品名称'].apply(extract_storage)
return df_sample
df = extract_feature(df)
def deal_ex(df_sample):
low = df_sample['价格'].quantile(0.25)
upp = df_sample['价格'].quantile(0.75)
iqr = upp - low
lower = low - 1.5 * iqr
upper = upp + 1.5 * iqr
# print('异常值范围:', lower, upper)
df_sample = df_sample[(df_sample['价格'] > lower) & (df_sample['价格'] < upper)]
return df_sample
df = deal_ex(df)
# df.to_csv('Cleaned_jd_phone_data.csv', index=False)
# print(df.sample(10))
# 按品牌分组统计平均价格 平均评分 产品数量
brand_level = df.groupby('品牌').agg(
平均价格=('价格', 'mean'),
平均评分=('评分', 'mean'),
产品数量=('品牌', 'count')
).round(2)
print(brand_level)
exit()
brand_stats = df.groupby('品牌').agg({
'价格': ['mean', 'min', 'max'],
'评分': ['mean'],
'评论数': ['mean', 'sum'],
'产品名称': ['count']
}).round(2)
brand_stats.columns = ['平均价格', '最低价格', '最高价格', '平均评分', '总评论数', '平均评论数', '产品数量']
# 按照产品数量降序排列
brand_stats.sort_values('产品数量', ascending=False)
# float('inf') 5000以上的无穷大区间
bins = [0, 1000, 2000, 3000, 4000, 5000, float('inf')]
labels = ['0-1000', '1000-2000', '2000-3000', '3000-4000', '4000-5000', '5000+']
df['价格区间'] = pd.cut(df['价格'], bins=bins, labels=labels, right=False)
# print(df['价格区间'].value_counts())
# print(df)
# exit()
# method_1
aaa = df.groupby('品牌').agg(
产品数量=('产品名称', 'count'),
平均价格=('价格', 'mean'),
平均评分=('评分', 'mean'),
总评论数=('评论数', 'sum')
).round(2)
# method_2
price_analysis = df.groupby('价格区间').agg({
'产品名称': ['count'],
'价格': ['mean'],
'评分': ['mean'],
'评论数': ['sum']
}).round(2)
price_analysis.columns = ['产品数量', '平均价格', '平均评分', '总评论数']
# 分析价格与评分的相关性
# corr() 计算这些列两两之间的皮尔逊相关系数
# 结果是一个3×3的相关系数矩阵,显示各变量间的线性相关程度 保留三位小数
correlation = df[['价格', '评分', '评论数']].corr().round(3)
# 按评论数降序排序
popular_product = df.sort_values('评论数', ascending=False).head(10)[['产品名称', '品牌', '价格', '评分', '评论数', '店铺名称']].reset_index(drop=True)
# df.to_csv('Cleaned_jd_phone_data.csv', index=False)数据可视化
python
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import *
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
df = pd.read_csv('Cleaned_jd_phone_data.csv')
# 数量占比
count = (df['品牌'].value_counts() / df['品牌'].value_counts().sum() * 100).round(2)
data = [(i, j) for i, j in zip(count.index.tolist(), list(count.values))]
pie = (
Pie(init_opts=opts.InitOpts(width='900px', height='600px', theme='white', bg_color='white'))
.add('', data_pair=data, center=['50%', '60%'], radius=['45%', '70%'],
label_opts=opts.LabelOpts(is_show=True, formatter='{b}:{c}({d}%)'),
)
.set_global_opts(
title_opts=opts.TitleOpts(title='品牌产品数量对比', subtitle='手机产品', pos_left='center', pos_top='top'),
legend_opts=opts.LegendOpts(is_show=True, pos_top='13%'),
visualmap_opts=opts.VisualMapOpts(is_show=True, orient='horizontal', pos_left='left', pos_bottom='bottom',
range_color=["#FF6B6B", "#4ECDC4", "#45B7D1", "#FFBE0B", "#FB5607", "#8338EC",
"#3A86FF"]),
toolbox_opts=opts.ToolboxOpts(is_show=True, pos_left='800px', orient='vertical')
)
)
# bar
# 创建价格区间柱状图,展示不同价格区间的产品数量
price_count = df['价格区间'].value_counts()
bar = (
Bar()
.add_xaxis(price_count.index.tolist())
.add_yaxis(
'产品数量', price_count.values.tolist(), label_opts=opts.LabelOpts(is_show=True, position='top'),
itemstyle_opts=opts.ItemStyleOpts(color='#45B7D1')
)
.set_global_opts(
title_opts=opts.TitleOpts(title='价格区间产品分布', pos_left='left', subtitle='产品数量'),
legend_opts=opts.LegendOpts(is_show=True),
tooltip_opts=opts.TooltipOpts(is_show=True, position='top'),
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside')
)
)
# scatter
# 创建价格与评分关系散点图,分析价格与评分的相关性
scatter_data = [[row['价格'], row['评分'], row['评论数'], row['产品名称']]
for _, row in df.iterrows()]
# 计算价格和评分的相关系数
cor = df['价格'].corr(df['评分']).round(3)
scatter = (
Scatter()
.add_xaxis([str(int(i[0])) for i in scatter_data[:100]])
.add_yaxis('', [i[1] for i in scatter_data[:100]], label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title=f'价格与评分关系 (相关系数:{cor})', pos_left='center'),
xaxis_opts=opts.AxisOpts(name='价格(元)', type_='value', splitline_opts=opts.SplitLineOpts(is_show=False),
name_textstyle_opts=opts.TextStyleOpts(font_size=15, font_weight='bold')),
yaxis_opts=opts.AxisOpts(name='评分', type_='value', min_=3.5, max_=5.2,
splitline_opts=opts.SplitLineOpts(is_show=False),
name_textstyle_opts=opts.TextStyleOpts(font_size=15, font_weight='bold')),
toolbox_opts=opts.ToolboxOpts(orient='vertical', pos_left='850px'),
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside'),
visualmap_opts=opts.VisualMapOpts(is_show=True)
)
)
# radar
brand_stats = df.groupby('品牌').agg({
'价格': 'mean',
'评分': 'mean',
'评论数': 'mean',
'产品名称': 'count',
}).reset_index()
# 筛选出 产品名称 列值中最大的5条记录
top_5 = brand_stats.nlargest(5, '产品名称')
category = ['平均价格', '平均评分', '平均评论数', '产品数量']
brand_stats_normalized = brand_stats.copy()
for col in ['价格', '评分', '评论数', '产品名称']:
# 分别获取 这些列中的最大值和最小值
# 归一化数据
max_val = brand_stats[col].max()
min_val = brand_stats[col].min()
if max_val > min_val:
# 如果条件满足,则将该列数据按公式 (x - min) / (max - min) 进行线性变换
brand_stats_normalized[col] = (brand_stats_normalized[col] - min_val) / (max_val - min_val)
# print(brand_stats_normalized[col])
else:
brand_stats_normalized[col] = 0
radar = (
Radar(init_opts=opts.InitOpts(width='900px', height='600px', theme='white'))
# 设置图表schema 包含四个指标:平均价格、平均评分、平均评论数、产品数量
# 每个指标的最大值设为1
.add_schema(
schema=[
opts.RadarIndicatorItem(name='平均价格', max_=1),
opts.RadarIndicatorItem(name='平均评分', max_=1),
opts.RadarIndicatorItem(name='平均评论数', max_=1),
opts.RadarIndicatorItem(name='产品数量', max_=1),
],
splitarea_opt=opts.SplitAreaOpts(is_show=True),
center=['50%', '60%'],
axislabel_opt=opts.LabelOpts(is_show=False),
axistick_opt=opts.AxisTickOpts(is_show=False),
)
)
# print(brand_stats_normalized)
for _, row in brand_stats_normalized.iterrows():
radar.add(
row['品牌'],
[[row['价格'], row['评分'], row['评论数'], row['产品名称']]],
areastyle_opts=opts.AreaStyleOpts(opacity=0.3),
label_opts=opts.LabelOpts(is_show=False),
)
radar.set_global_opts(
title_opts=opts.TitleOpts(title='主要品牌综合表现雷达图', pos_left='center'),
legend_opts=opts.LegendOpts(is_show=True, pos_top='55px'),
toolbox_opts=opts.ToolboxOpts(is_show=True,orient='vertical',pos_left='766px'),
)
# 使用Page布局创建仪表盘
page = Page(layout=Page.SimplePageLayout)
page.add(
pie,
bar,
scatter,
radar
)
# 渲染成HTML文件
page.render('phone_dashboard.html')