pytorch 卷积神经网络
文章目录
- [pytorch 卷积神经网络](#pytorch 卷积神经网络)
-
- 前言
- [1. 卷积神经网络(CNN)基础概念](#1. 卷积神经网络(CNN)基础概念)
-
- [1.1 图像的基本原理](#1.1 图像的基本原理)
- [1.2 为什么使用卷积神经网络?](#1.2 为什么使用卷积神经网络?)
-
- [1. 传统神经网络的局限:死记硬背位置](#1. 传统神经网络的局限:死记硬背位置)
- [2. 什么是"平移不变性"?](#2. 什么是“平移不变性”?)
- [3. CNN如何解决该问题?](#3. CNN如何解决该问题?)
- [1.3 核心组件:卷积层](#1.3 核心组件:卷积层)
- [2. 卷积神经网络的架构](#2. 卷积神经网络的架构)
-
- [2.1 输入层](#2.1 输入层)
- [2.2 卷积层:特征提取的核心](#2.2 卷积层:特征提取的核心)
-
- [1. 卷积的本质:特定位置的线性组合](#1. 卷积的本质:特定位置的线性组合)
- [2. 为什么需要多卷积核?](#2. 为什么需要多卷积核?)
- [3. 多通道卷积的计算逻辑](#3. 多通道卷积的计算逻辑)
-
- [A. 多通道单卷积核](#A. 多通道单卷积核)
- [B. 多通道多卷积核](#B. 多通道多卷积核)
- [4. 深度卷积:通往抽象特征之路](#4. 深度卷积:通往抽象特征之路)
- [2.3 激活函数:赋予网络非线性灵魂](#2.3 激活函数:赋予网络非线性灵魂)
- [2.4 池化层:降维与抗扰动](#2.4 池化层:降维与抗扰动)
-
- [1. 最大池化](#1. 最大池化)
- [2. 平均池化](#2. 平均池化)
- [2.5 全连接层与输出层:逻辑决策的终点](#2.5 全连接层与输出层:逻辑决策的终点)
- [3. 经典CNN论文和架构](#3. 经典CNN论文和架构)
- [4. pytorch代码案例详细讲解](#4. pytorch代码案例详细讲解)
-
- [4.1 完整代码案例](#4.1 完整代码案例)
- [4.2 详细代码讲解](#4.2 详细代码讲解)
-
- [1. 数据加载和预处理](#1. 数据加载和预处理)
- [2. 模型定义](#2. 模型定义)
- [3. 损失函数和优化器](#3. 损失函数和优化器)
- [4. 训练循环](#4. 训练循环)
- [5. 测试集评估模型效果](#5. 测试集评估模型效果)
- 总结
前言
卷积神经网络(CNN)是深度学习在计算机视觉领域的灵魂,它模仿人类视觉系统,通过卷积层、池化层等核心组件,实现了对图像特征从局部线条到整体语义的层次化提炼。
与传统神经网络相比,其独特的"局部感知"和"参数共享"机制赋予了模型强大的平移不变性,使其能够高效地处理复杂的图像数据。
1. 卷积神经网络(CNN)基础概念
1.1 图像的基本原理
在了解卷积神经网络前,先来看看图像的原理:
图像在计算机中是一堆按顺序排列的数字,数值为0到255。0表示最暗,255表示最亮。 如下图:
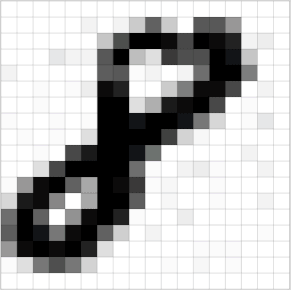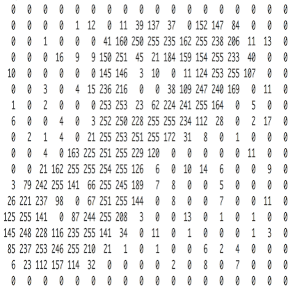
上图是只有黑白颜色的灰度图,而更普遍的图片表达方式是RGB颜色模型,即红、绿、蓝三原色的色光以不同的比例相加,以产生多种多样的色光。
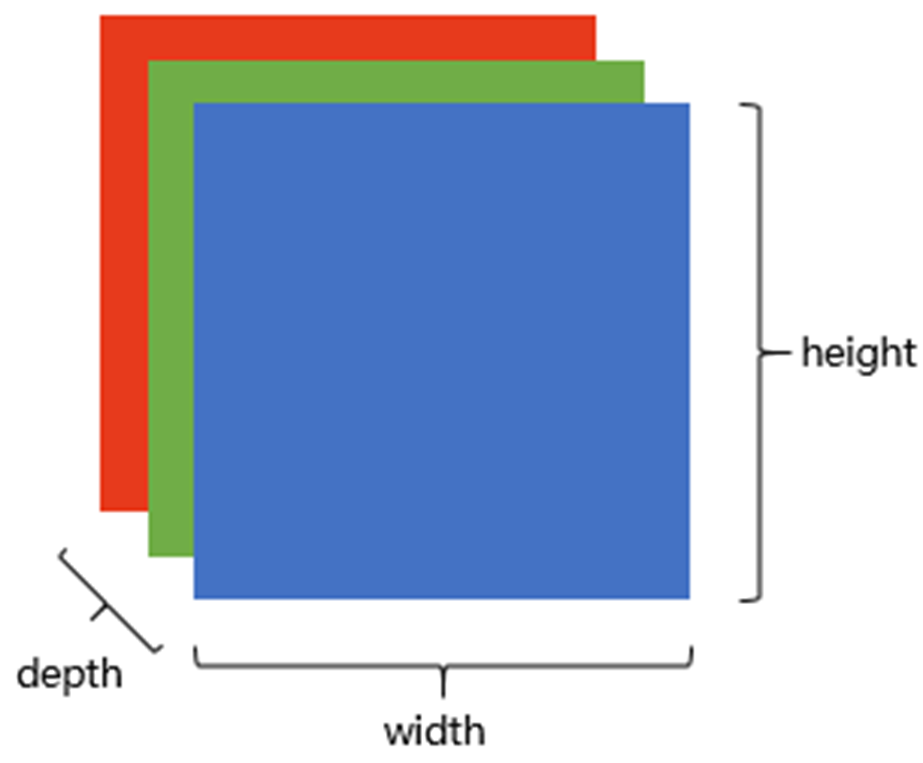
RGB颜色模型中,单个矩阵就扩展成了有序排列的三个矩阵,也可以用三维张量去理解。
其中的每一个矩阵又叫这个图片的一个channel(通道),宽, 高, 深来描述。
CNN 处理图像,先懂图像数据:
- 灰度图:黑白照片,每个像素是 0~255 的数(0黑,255白),矩阵形式:二维数组 高度 H, 宽度 W。
- 彩色图 (RGB) :三层叠加(红R、绿G、蓝B 通道),三维张量 H, W, 3。
- 每个通道独立,但组合成颜色。比如像素 (255,0,0) 是纯红。
数学表示:图像 I 是张量 I ∈ ℝ^{H × W × C},C=1 (灰度) 或 3 (RGB)。
1.2 为什么使用卷积神经网络?
在处理图像时,卷积神经网络(CNN)比你之前学习的普通神经网络(全连接网络)更强大。
核心原因在于"平移不变性"。
1. 传统神经网络的局限:死记硬背位置
在传统神经网络中,每个神经元都与输入像素"一对一"绑定。
- 位置敏感 :如果模型学习了圆圈在图片左上角 的样子,当你把圆圈移动到右下角时,原本负责左上角的神经元接收不到信号,而负责右下角的神经元此前从未见过这个圆圈。
- 缺乏灵活性 :计算机看到的只是一堆杂乱的像素数值,它无法理解"形状"这个概念,只记得"坐标 ( 1 , 1 ) (1,1) (1,1) 的像素是红色的"。
2. 什么是"平移不变性"?
平移不变性(Translation Invariance)是指:不管物体出现在图像的哪个角落,模型都能认出它。
- 直观理解:就像人类看猫,猫在照片左边、右边或是中间,我们一眼都能认出是猫。
- 传统网络的问题:它要求猫必须出现在训练时的精确坐标上,稍微挪动一点,它就认不出来了。
3. CNN如何解决该问题?
卷积神经网络通过**"卷积操作"**实现了平移不变性:
- 局部感知(Local Perception):卷积核像一个"移动扫描仪",它不看整张图,只看一小块区域(局部特征)。
- 权重共享(Weight Sharing):这个扫描仪在整张图片上从左往右、从上往下滚动扫过。
- 特征捕捉:由于是用同一个扫描仪(卷积核)扫过整张图,只要圆圈出现在任何位置,扫描仪滑过它时都会产生强烈的反应。

1.3 核心组件:卷积层
**卷积是 CNN 的灵魂:用小"过滤器"(卷积核 K)在图像上滑动,计算局部"相似度",生成新图(特征图)。**这个也是卷积神经网络可以学习到图片的局部特征的原因。所以多用于图像处理。
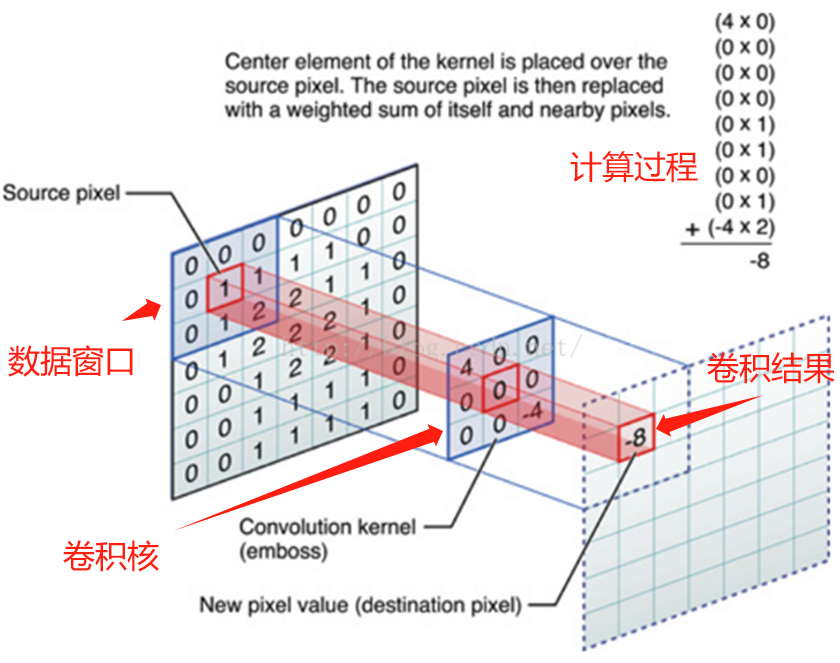
卷积操作的本质是一种数学运算,它通过卷积核在输入数据上的滑动,对局部区域的像素进行加权求和,从而生成新的特征图 。为了更直观地理解这个过程,我们来看下面这张示意图:
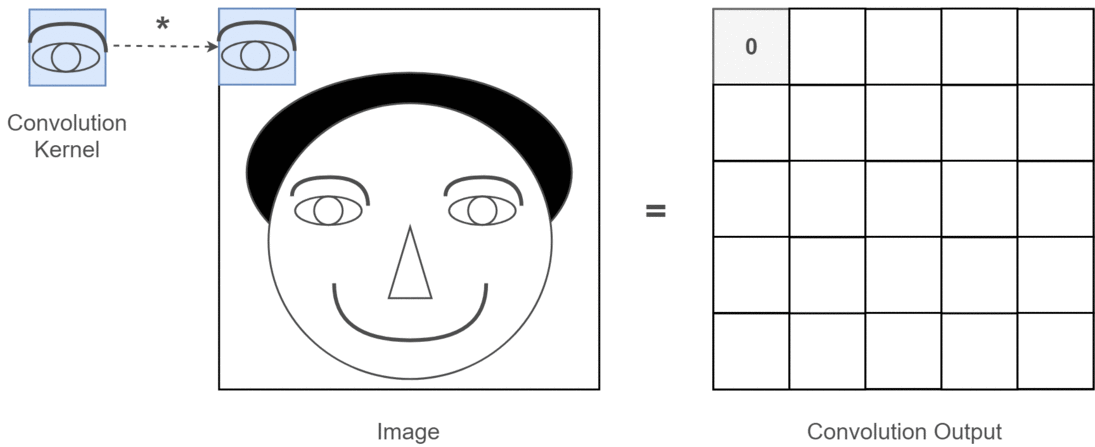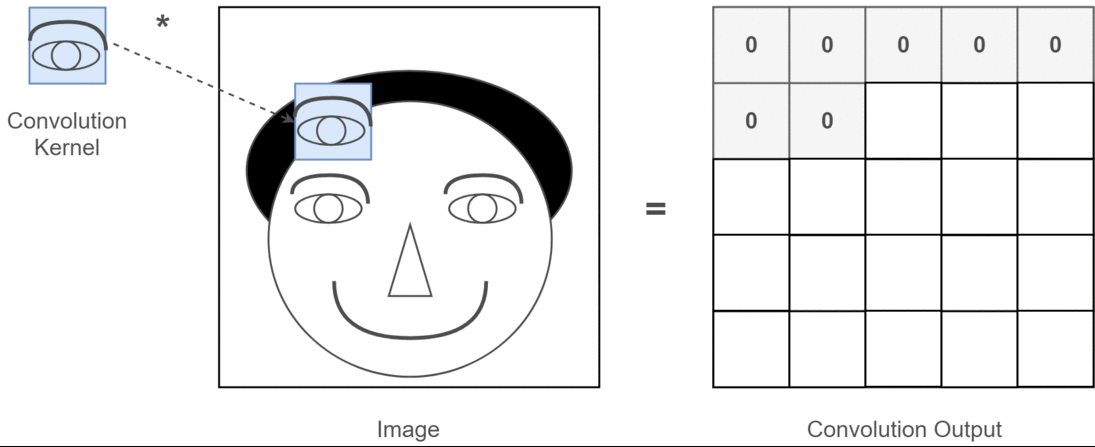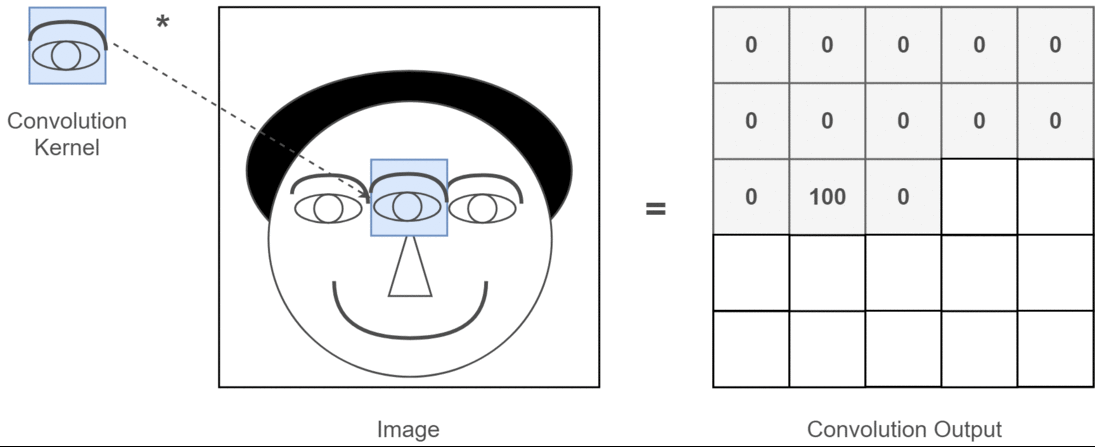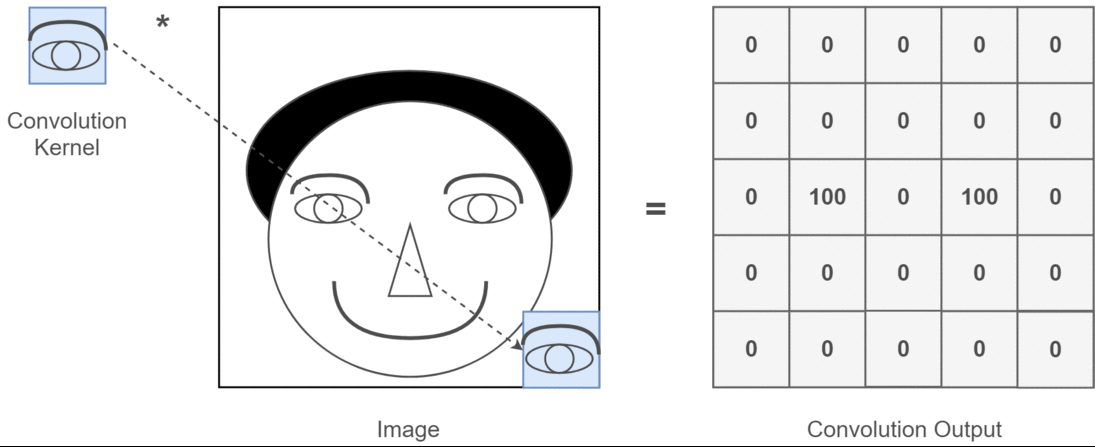
这张图中蓝色的框就是指一个数据窗口,红色框为卷积核(滤波器),最后得到的绿色方形就是卷积的结果(数据窗口中的数据与卷积核逐个元素相乘再求和)。
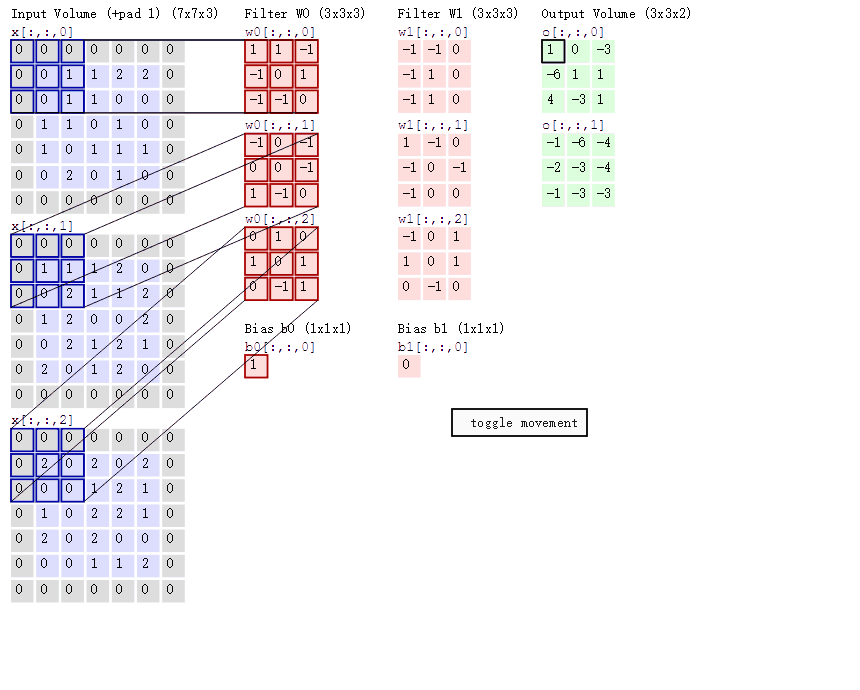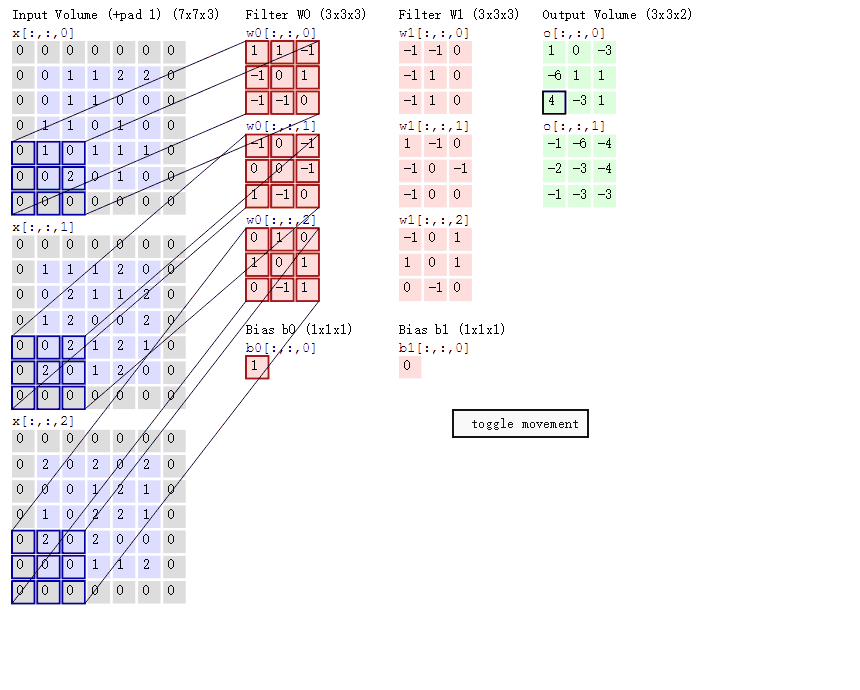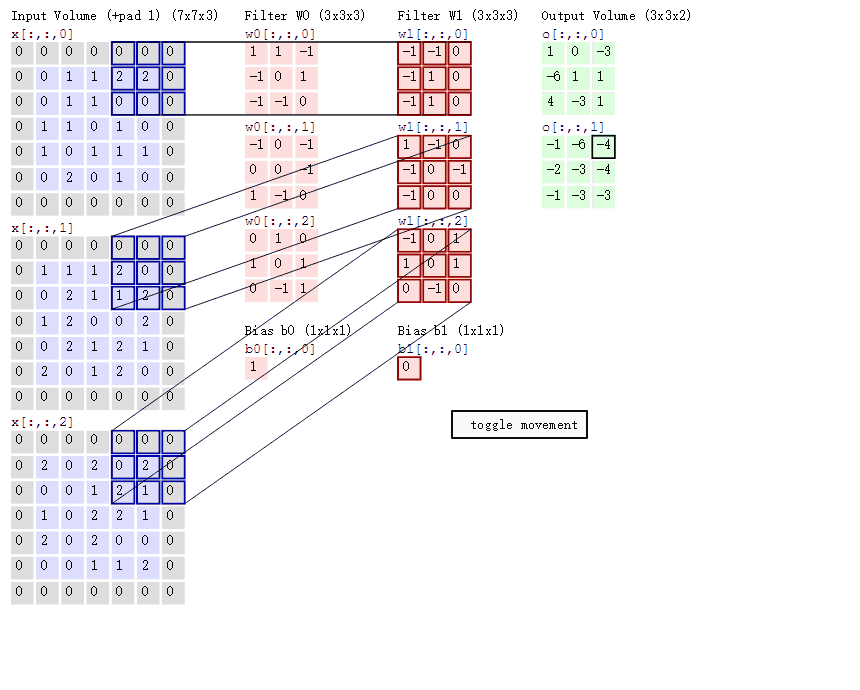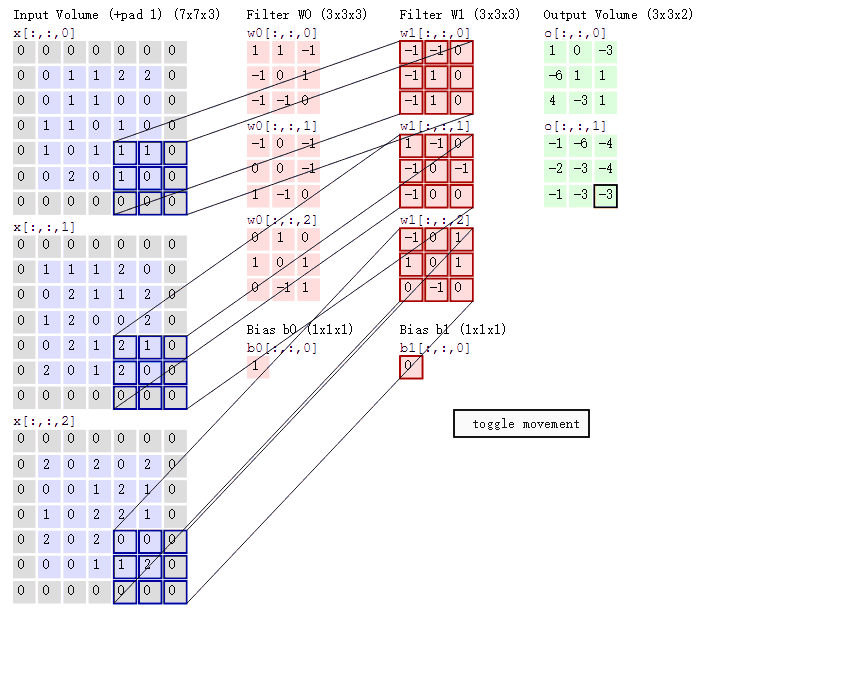
一张图了解卷积计算过程:
要精确控制卷积的过程,我们需要调整以下三个专业参数:
a. 步长 (Stride)
- 定义:指卷积核每次滑动的格数。
- 影响:步长越大,提取的特征图(Feature Map)尺寸就越小,扫描得也就越"粗糙";步长越小,特征提取越细腻,但计算量更大。
b. 填充 (Zero-Padding)
- 定义:在原始图像的外围补上一圈或多圈 0。
- 目的 :
- 尺寸对齐:确保图像边缘的信息也能被卷积核中心扫描到,防止输出图像迅速缩小。
- 整除需求:调整图像总长度,使其能被步长整除,方便卷积核刚好滑到末尾位置。
- 专业意义:**数据填充的主要目的是确保卷积核能够覆盖输入图像的边缘区域,同时保持输出特征图的大小。**这对于在CNN中保留空间信息和有效处理图像边缘信息非常重要。
c. 卷积核个数 (Number of Filters)
- 定义:每一层使用的卷积核数量。
- 影响 :它决定了输出结果的厚度(Depth/Channels)。
- 专业意义:每个卷积核负责提取一种特征(比如一个提边缘,一个提颜色)。如果你有 64 个卷积核,输出就会有 64 个通道,代表提取了 64 种不同的特征信息。
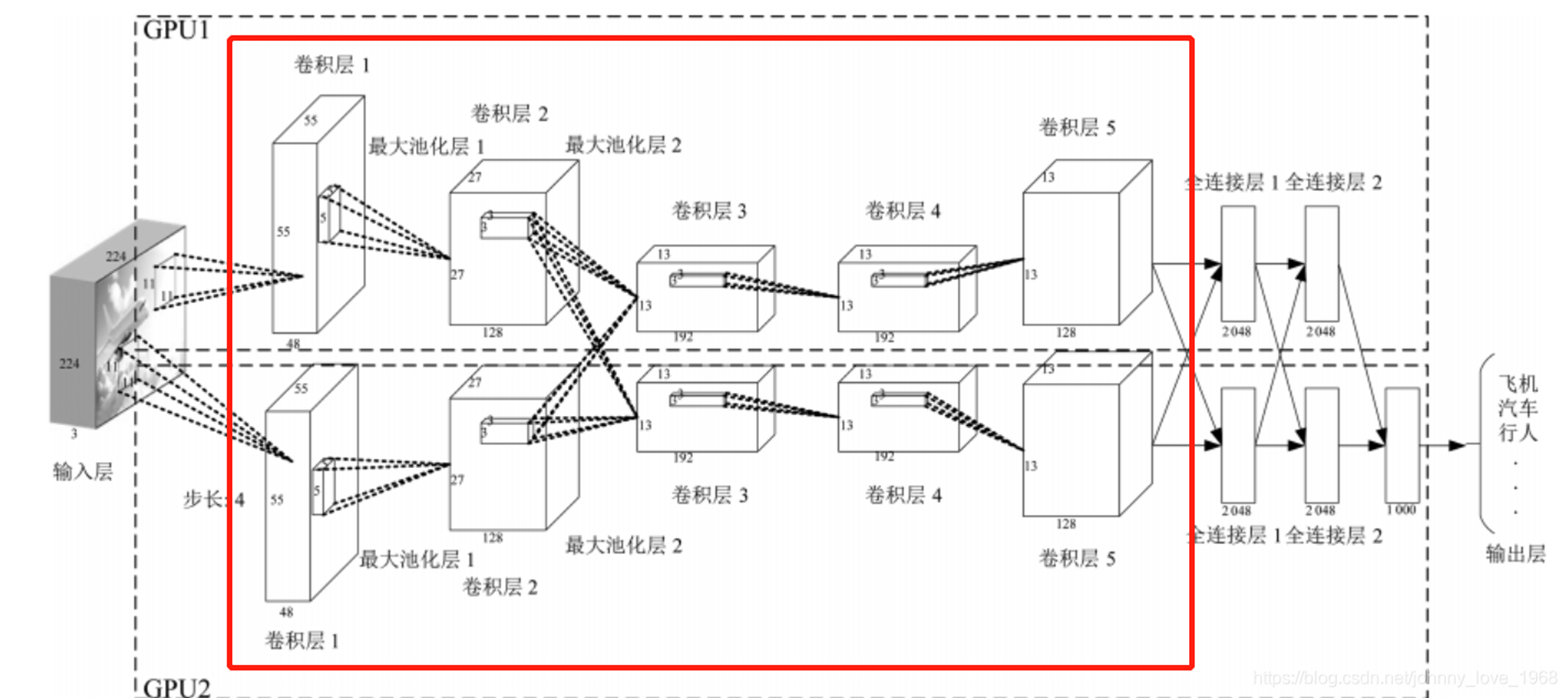
2. 卷积神经网络的架构
一个层次化特征提取的过程:
输入图像 → \rightarrow → 提炼细节(卷积) → \rightarrow → 简化数据(池化) → \rightarrow → 由点及面(堆叠) → \rightarrow → 逻辑决策(全连接)。
下面总览CNN的架构概念:
-
输入层 (Input Layer):数字化世界
-
核心逻辑:将肉眼看到的彩色图像转化为计算机能理解的数字矩阵。
-
专业细节 :彩色图像由 RGB 三个通道组成。比如一张 224 × 224 224 \times 224 224×224 的照片,在输入层就是一个形状为 ( 3 , 224 , 224 ) (3, 224, 224) (3,224,224) 的三维张量。
-
-
卷积和激活 (Convolution & Activation):寻找线条
-
卷积作用:通过卷积核在图像上滑动,提取局部特征(如边缘、纹理)。
-
激活意义 :应用 ReLU 等激活函数引入非线性,使网络能学习比直线更复杂的特征模式。
-
数学直觉:卷积负责"提取信号",激活函数负责"过滤并增强信号"。
-
-
池化层 (Pooling Layer):抓住重点
-
核心逻辑:在保留关键信息的前提下,缩小特征图的大小。
-
常见方式:
- 最大池化 (Max Pooling):选取窗口内最强的那个信号,舍弃其余,这能有效提取最重要的特征。
- 平均池化 (Average Pooling):计算窗口内的平均值。
-
核心目的 :减少后续计算量,并提高模型的"平移不变性"(即物体稍微挪动位置,池化后的结果依然相似)。
-
-
多层堆叠 (Multi-layer Stacking):从局部到整体
-
核心逻辑:CNN 通常通过多个卷积和池化层的交替堆叠来工作。
-
特征演变:
- 浅层:识别简单的线条和颜色点。
- 深层:将线条组合成复杂的模式,如眼睛、轮子或人脸。
-
深度力量:层数越深,网络能理解的语义信息就越高级。
-
-
全连接和输出 (Fully Connected & Output):最后决断
-
核心逻辑:将前面层提取到的三维特征图"展平"成一维向量,交给全连接层进行综合判断。
-
最终结果:根据任务不同,输出可以是图像属于某个类别的概率(分类),或者是坐标数值(回归)。
-
2.1 输入层
输入层是 CNN 的"入口大门",负责接收原始数据(如图像),并预处理成适合网络的格式。它不进行计算,只转换数据,确保后续层能高效处理。
图像数据是多维数组(张量),CNN 天然适合处理,因为它保留空间结构(不像全连接网络扁平化一切)。
- 图像表示:多维数组表示 。彩色图像通常表示为
[高度, 宽度, 通道数](如 RGB 的通道数为 3)。例如 224x224 RGB 图:形状 224, 224, 3。- 为什么通道?每个通道独立捕捉颜色信息,组合成彩色。
预处理操作:
- 去均值(Mean Subtraction):将像素值减去数据集均值,使数据分布在原点附近,加速模型收敛。
- 归一化(Normalization) :将像素值缩放到特定区间(如 0 , 1 0, 1 0,1),消除不同特征间的尺度差异。
2.2 卷积层:特征提取的核心
卷积层是 CNN 的"引擎",用小"过滤器"(卷积核)扫描图像,提取局部特征(如边缘、纹理)。它高效因为参数共享和局部连接。
操作本质 :卷积核在输入数据上滑动,对局部区域进行加权求和 。例如, 3 × 3 3 \times 3 3×3 的卷积核与对应的 3 × 3 3 \times 3 3×3 区域元素相乘求和,得到特征图的一个值。
核心参数:
- 卷积核大小 :小核(如 3 × 3 3 \times 3 3×3)擅长捕捉局部细节;大核(如 11 × 11 11 \times 11 11×11)则用于快速提取全局显著特征。
- 步长 (Stride):决定滑动的格数。步长越大,特征图尺寸越小,计算量随之降低。
- 填充 (Padding):在边缘补 0,防止边缘信息丢失并控制输出尺寸。
- 通道数:输出通道数决定了特征图的数量,每个通道代表一种不同的特征探测。
如图所示:
单核卷积上面已经讲了很多,至于计算公式就不必多说,这里后面主要讲解以下多核和深度卷积。
1. 卷积的本质:特定位置的线性组合
卷积计算在本质上与全连接层相同,都是神经元之间的线性组合。不同之处在于,卷积只选择输入矩阵中特定位置的神经元进行运算。
- 计算过程 :卷积核(Kernel/Filter)在输入数据上依次扫描并进行内积运算(对应元素相乘再求和)。
- 特征图 (Feature Map):扫描完成后得到的结果矩阵称为特征图。
- 输入维度:通常由宽(Width)、高(High)和通道(Channel)三个维度表示。
2. 为什么需要多卷积核?
单个卷积核只能识别某一类特定的特征(如锐利度、边缘等)。对于复杂数据,仅凭一类特征不足以进行有效辨识。
- 探测多样性:通过多个不同的卷积核,模型可以提取到多种特征属性(如不同的锐利度表现),这有利于后续的分类或检测任务。
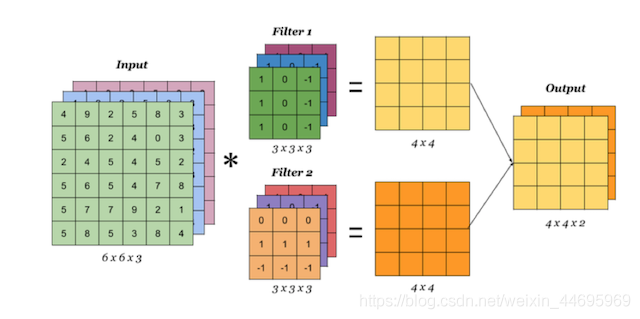
- 维度对应 :卷积核的个数直接决定了输出特征图的通道数 。例如,使用 2 个卷积核会得到形状为 h , w , 2 h, w, 2 h,w,2 的结果。

3. 多通道卷积的计算逻辑
这是最容易产生误解的地方:输入通道数必须与卷积核的通道数匹配。
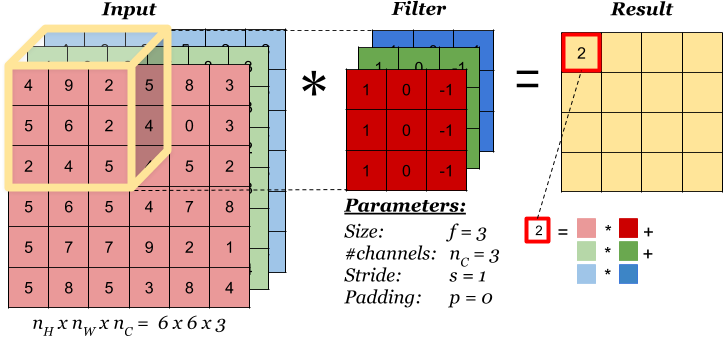
A. 多通道单卷积核
如果输入是 RGB 三通道(形状为 n , n , 3 n, n, 3 n,n,3),那么一个 卷积核也必须包含三个通道(形状为 w , w , 3 w, w, 3 w,w,3)。
- 计算方式 :卷积核的每一个通道分别与输入对应的通道进行卷积,将三个通道的结果相加 ,最后加上偏置(Bias),得到一个单通道的特征图。
B. 多通道多卷积核
使用 k k k 个卷积核处理三通道输入:
- 匹配规则:每个卷积核仍必须是三通道的。
- 输出结果 : k k k 个卷积核分别按照上述"相加再加偏置"的逻辑运算,最终输出 k k k 个特征图,总形状为 h , w , k h, w, k h,w,k。
4. 深度卷积:通往抽象特征之路
深度卷积是指将卷积操作进行多次叠加(卷积后再卷积)。
- 横向提取:通过多个卷积核提取同层次的不同特征。
- 纵向叠加:通过层层叠加,提取不同层次的特征。
- 特征演变 :
- 浅层:能看到物体的轮廓(如汽车轮廓)。
- 深层:提取到的是人眼难以分辨的、更高级且抽象的特征。
- 价值:这些抽象特征能显著提高模型在下游任务(如分类)中的最终精度。
- 简言之:就是在池化之前多次卷积和激活函数一起才做。
2.3 激活函数:赋予网络非线性灵魂
如果没有激活函数,再深的网络也只是线性组合。
- ReLU ( m a x ( 0 , x ) max(0, x) max(0,x)) :最常用,计算简单且能缓解梯度消失,但需注意防止神经元"死亡"。
- Sigmoid :输出在 ( 0 , 1 ) (0, 1) (0,1) 区间,常用于二分类输出层,但在深层网络中易导致梯度消失。
- Tanh :输出在 ( − 1 , 1 ) (-1, 1) (−1,1),收敛速度优于 Sigmoid,但在深层网络中同样存在饱和区梯度消失问题。
2.4 池化层:降维与抗扰动
池化层主要负责压缩信息,增强模型对物体位置轻微变化的鲁棒性。
- 最大池化 (Max Pooling):选取窗口内的最大值。它能保留最显著特征,并对图像位移具有鲁棒性。
- 平均池化 (Average Pooling):计算窗口平均值。能起到平滑效果,但可能丢失细节。
- 核心价值 :减少参数数量和计算量,并有效防止过拟合。
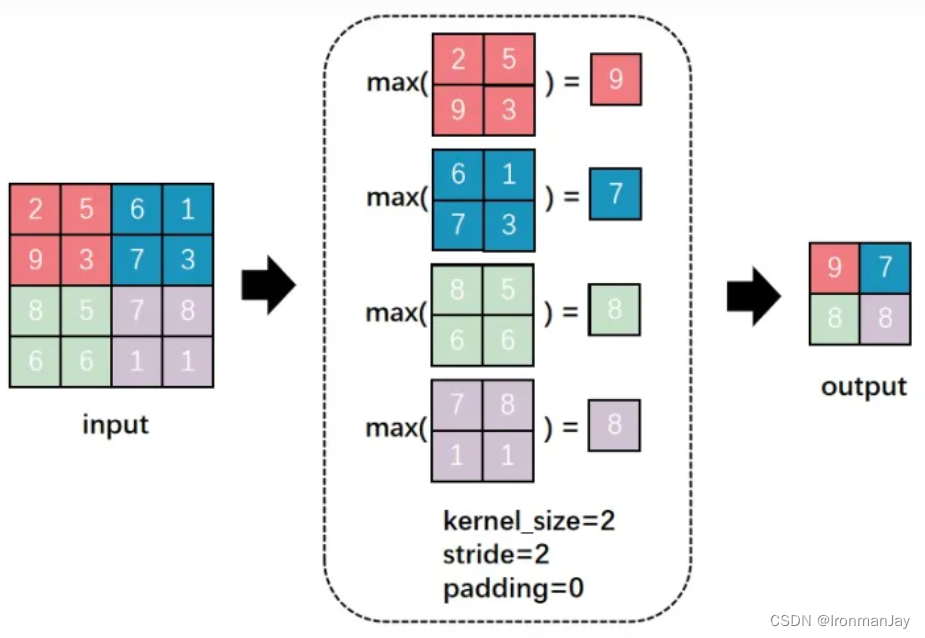
1. 最大池化
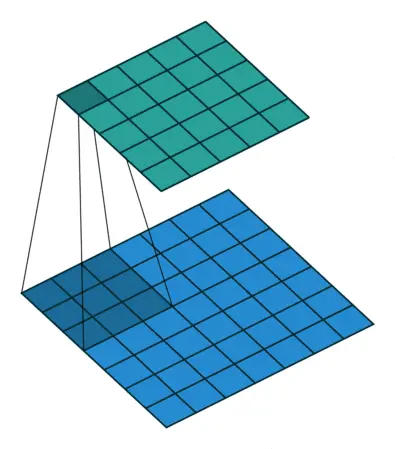
操作逻辑 :将特征图划分为固定大小的窗口(如 2 × 2 2 \times 2 2×2),仅提取该区域内的最大数值作为输出。
核心优势:
- 保留显著特征:由于只选取最大值,它能有效捕捉图像中最突出的边缘或纹理信号。
- 平移鲁棒性:即使物体在图像中发生了轻微的位移,只要它产生的最强信号仍在池化窗口内,输出结果就不会改变。
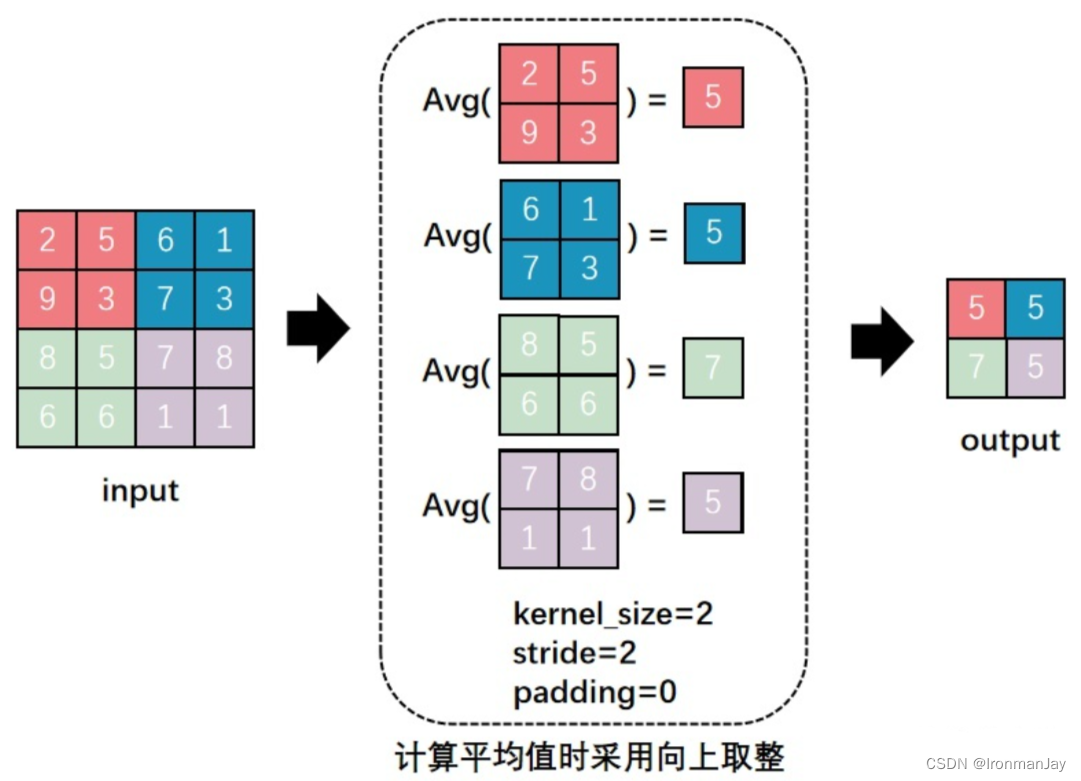
2. 平均池化
平均池化提供了一种更平滑的信息压缩方式。
- 操作逻辑 :计算池化窗口内所有元素的算术平均值作为输出。
- 数学示例 :在 2 × 2 2 \times 2 2×2 窗口中,若四个元素分别为 1, 2, 4, 5,则输出值为 ( 1 + 2 + 4 + 5 ) / 4 = 3 (1+2+4+5)/4 = 3 (1+2+4+5)/4=3。
- 核心优势 :
- 平滑去噪:通过平均化处理,可以减少图像中的随机噪声影响。
- 关注整体:相比于只看最强点,它更倾向于保留区域内的整体背景信息,适用于对细节要求不高但注重全局特征的任务。
- 缺点:相比最大池化,它容易模糊图像细节,因为强信号会被周围的弱信号稀释。
2.5 全连接层与输出层:逻辑决策的终点
这是流水线的最后阶段,将特征转化为最终结论。
- 全连接层 (FC):将三维特征图"展平"为一维向量,整合所有局部特征形成全局表示。
- 输出层 :
- 分类任务 :通常配合 Softmax 函数,将输出转化为各个类别的预测概率(总和为 1)。
- 回归任务:直接输出一个连续值(如房价),通常不使用激活函数。
3. 经典CNN论文和架构
| 网络名称 | 诞生年份 | 主要贡献与创新点 | 原始论文链接 |
|---|---|---|---|
| LeNet-5 | 1998 | 第一个成功的卷积神经网络应用;引入了卷积、池化和全连接层的组合。 | LeNet-5 Paper |
| AlexNet | 2012 | 击败传统计算机视觉模型的转折点;首次大规模使用 ReLU 激活函数、Dropout 和 GPU 并行计算。 | AlexNet Paper |
| VGGNet | 2014 | 提出"块(Block)"的概念;通过堆叠多个 3 × 3 3 \times 3 3×3 小卷积核代替大卷积核,增加深度且减少参数。 | VGG Paper |
| NiN | 2013 | 引入 1 × 1 1 \times 1 1×1 卷积和全局平均池化(GAP),有效减少参数量并抑制过拟合。 | NiN Paper |
| GoogLeNet | 2014 | 提出 Inception 模块,通过多路径并行卷积并行提取不同尺度的特征,显著降低模型复杂度。 | GoogLeNet Paper |
| ResNet | 2015 | 引入残差学习(Residual Learning)和跳跃连接,成功解决了深层网络中的梯度消失问题。 | ResNet Paper |
| DenseNet | 2017 | 采用稠密连接(Dense Block),每一层都与前面所有层相连,增强特征传播并减少参数量。 | DenseNet Paper |
4. pytorch代码案例详细讲解
这里代码使用PyTorch框架实现了一个简单的卷积神经网络(CNN)模型,用于在CIFAR-10数据集上进行图像分类任务。CIFAR-10是一个经典的基准数据集,包含60,000张32x32像素的彩色图像,分成10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车),其中50,000张用于训练,10,000张用于测试。
代码的主要流程包括:
- 设备配置:检查是否可用GPU加速训练。
- 数据加载与预处理:下载并加载CIFAR-10数据集,进行标准化处理。
- 模型定义:构建一个简单的CNN架构,包括卷积层、池化层和全连接层。
- 损失函数与优化器:使用交叉熵损失和Adam优化器。
- 训练循环:运行5个epoch,计算并打印每个epoch的平均损失。
- 测试评估:在测试集上计算准确率。
4.1 完整代码案例
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 设备配置(可选:用 GPU 加速)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到 [-1, 1]
])
# 下载/加载数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
# 模型定义
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 输入3通道,输出32,3x3核
self.pool = nn.MaxPool2d(2, 2) # 2x2 最大池化
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 512) # 展平后全连接(输入图像32x32,经过两次池化8x8)
self.fc2 = nn.Linear(512, 10) # 输出10类
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x))) # 卷积+ReLU+池化
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8) # 展平
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleCNN().to(device) # 模型移到设备
# 损失函数 + 优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
num_epochs = 5
for epoch in range(num_epochs):
model.train() # 训练模式
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移到设备
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
print(f'Epoch {epoch+1}/{num_epochs}, Average Loss: {avg_loss:.4f}')
# 测试
model.eval() # 评估模式(关闭 dropout 等)
correct = 0
total = 0
with torch.no_grad(): # 无梯度计算
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) # 获取最大概率类
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Test Accuracy: {accuracy:.2f}%')4.2 详细代码讲解
1. 数据加载和预处理
python
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到 [-1, 1]
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)作用:
- 定义数据变换(转换为张量并标准化均值/标准差到-1,1范围);
- 加载训练/测试集(如果不存在则下载);
- 创建DataLoader用于批量加载数据(batch_size=64,训练时shuffle打乱顺序)。
为什么:
- 标准化帮助模型收敛更快(数据分布更均匀)。
- DataLoader高效处理大数据集,支持多线程(num_workers=2)。
- CIFAR-10图像是3通道RGB,32x32大小。
pytorch语法:
-
transforms.ToTensor(): 将图片像素值从 0 , 255 0, 255 0,255 压缩到 0 , 1 0, 1 0,1。 -
transforms.Normalize: 通过均值和标准差将数据调整到 − 1 , 1 -1, 1 −1,1。这能使数据分布在原点附近,有助于模型更快收敛。 -
DataLoader: 将 50,000 张训练图切分成大小为 64 的"批次(Batch)",提高计算效率。- 在深度学习中,DataLoader 的角色就像是工厂里的"物料传送带"。
- 如果你有 50,000 张图片,直接把它们一次性全部塞进电脑的内存和显卡(GPU)里,电脑会因为"吃不下"而直接崩溃(内存溢出)。为了解决这个问题,我们需要 Batch(批次) 训练。
2. 模型定义
python
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) # 输入3通道,输出32,3x3核
self.pool = nn.MaxPool2d(2, 2) # 2x2 最大池化
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.fc1 = nn.Linear(64 * 8 * 8, 512) # 展平后全连接(输入图像32x32,经过两次池化8x8)
self.fc2 = nn.Linear(512, 10) # 输出10类
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x))) # 卷积+ReLU+池化
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8) # 展平
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = SimpleCNN().to(device) # 模型移到设备SimpleCNN 类采用了典型的"卷积-激活-池化"结构。
- 输入层 : 接收 32 × 32 32 \times 32 32×32 的 RGB 彩色图像(3 通道)。
- 卷积层 (Conv2d) :
conv1: 使用 32 个卷积核提取基础特征(如边缘)。conv2: 进一步提取 64 个更复杂的抽象特征。
- 激活函数 (ReLU): 在卷积后立即应用,引入非线性,使网络能学习复杂模式。
- 最大池化 (MaxPool2d) : 采用 2 × 2 2 \times 2 2×2 窗口将特征图宽高减半。经过两次池化,原始 32 × 32 32 \times 32 32×32 图像变为 8 × 8 8 \times 8 8×8,大大减少了参数量。
- 全连接层 (Linear) :
x.view(-1, 64 * 8 * 8): 将三维的特征图"展平"成一维向量。- 最后输出 10 个数值,代表图片属于 10 个类别的得分。
3. 损失函数和优化器
python
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)作用:定义交叉熵损失(适合多类分类);Adam优化器(自适应学习率,lr=0.001)。
4. 训练循环
python
num_epochs = 5
for epoch in range(num_epochs):
model.train() # 训练模式
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移到设备
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
print(f'Epoch {epoch+1}/{num_epochs}, Average Loss: {avg_loss:.4f}')设备配置 : 优先使用 GPU (cuda),能大幅缩短训练时间。
损失函数 (CrossEntropyLoss): 专门用于多分类任务,它会自动在内部计算 Softmax 概率。
优化器 (Adam): 比传统的 SGD 更智能,能自动调整每个参数的学习率。
训练循环:
- 前向传播: 模型对图片进行预测。
- 计算损失: 对比预测值与真实标签。
- 反向传播 (
backward): 计算每个参数对误差的"贡献度(梯度)"。 - 更新参数 (
step): 优化器微调权重,降低下次预测的误差。
5. 测试集评估模型效果
python
model.eval() # 评估模式(关闭 dropout 等)
correct = 0
total = 0
with torch.no_grad(): # 无梯度计算
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) # 获取最大概率类
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Test Accuracy: {accuracy:.2f}%')作用:model.eval()切换到评估模式;无梯度(节省内存);遍历测试集,预测类别,计算正确率。
总结
核心机制:通过卷积提取特征、激活函数引入非线性以及池化层降维,CNN 实现了对图像信息的高效压缩与深度解析。
实战闭环:借由 PyTorch 框架,我们完成了从数据预处理到模型训练与评估的完整流程,深刻体会了批次训练(DataLoader)对计算效率的提升作用。