前言
上一篇我们介绍了 AI 应用的发展历程以及 Agent 的整体概念,这一篇将针对 ReAct(Reasoning + Acting)模式,并对其设计思想和工程实现进行一次更为系统、偏实战向的讲解。
在讲解 ReAct 之前,有必要先澄清一个经常被混用的问题:Agent 到底是什么?
在早期以及当下大量工程实践中,不同 AI 应用对 Agent 的定义并不一致。很多所谓的 Agent,本质上更接近一个预先定义好的 AI workflow :流程、工具、策略都由应用侧提前固化,用户只是触发执行。例如,一个 WebSearch 场景往往就对应一个「搜索 Agent」,或者通过特定提示词(如 /agent)来唤醒一组固定的搜索工具。
从工程视角看,这类 Agent 更多是能力封装与产品抽象 ,而不是研究语境中强调的「具备自主决策与反馈能力的智能体」。也正因为如此,随着概念被频繁复用,agent 这个词在实际讨论中逐渐变得模糊,单独听到它已很难准确判断其具体能力边界。
如果暂时抛开命名争议,从实现层面抽象来看,一个 Agent 的核心逻辑其实非常简单:一个受控的循环(loop)。在这个循环中,模型不断获取上下文、进行推理、执行动作,并根据结果继续调整行为,直到满足终止条件为止。
在工程实现中,这个过程往往可以被近似理解为:
- 多轮调用 LLM
- 中间可能伴随工具调用
- 有明确的退出条件(如任务完成、步数上限、token 预算)
基于这样的背景,各类 Agent 设计模式(也可以称为范式或框架)逐步出现,而其中最经典、也最具代表性的,便是 ReAct 模式。该模式最早发表于 2022 年,其结构至今仍足以支撑大量中低复杂度的 Agent 场景。
ReAct 模式
核心思想
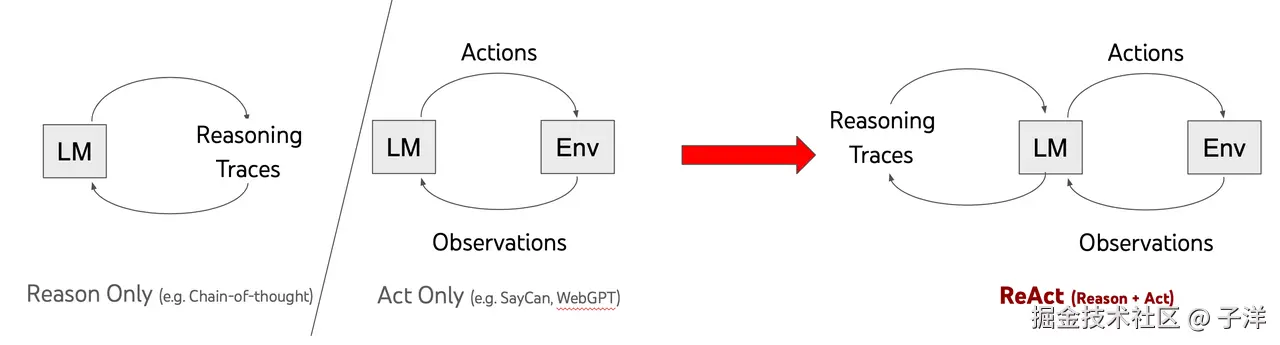
ReAct 的提出,本质上是为了解决一个早期 LLM 应用中的割裂问题:推理与行动往往是分离的。
在 ReAct 出现之前,常见的两类模式分别是:
- Reason-only:模型进行显式推理(如 CoT、Scratchpad),但不与外部环境交互
- Act-heavy / Tool-driven:模型频繁调用工具获取信息,但推理过程并不显式呈现或不与行动交错
需要说明的是,这里的分类来自 ReAct 论文中的抽象对比,而并非对具体系统内部实现的严格学术归类。例如:
- SayCan 内部同样包含推理与可行性评估,并非"无 reasoning"
- WebGPT 也存在内部推理过程,只是推理与行动并未以交错形式呈现给模型
在这种背景下,ReAct(Reasoning + Acting) 的核心思想可以概括为一句话:
在行动中思考,在思考中决定行动。
它尝试将思考 和行动统一到一个连续的闭环中,模拟人类解决问题时的自然过程:
- Thought:分析当前状态与目标
- Action:基于判断调用工具或执行操作
- Observation:观察行动结果
- Thought:根据新信息再次推理
- 重复上述过程,直到问题解决
从形式上看,ReAct 并没有引入复杂的新组件,而是通过 Thought → Action → Observation 的反复交替,显著提升了模型在多步任务、信息不完备任务中的表现稳定性。
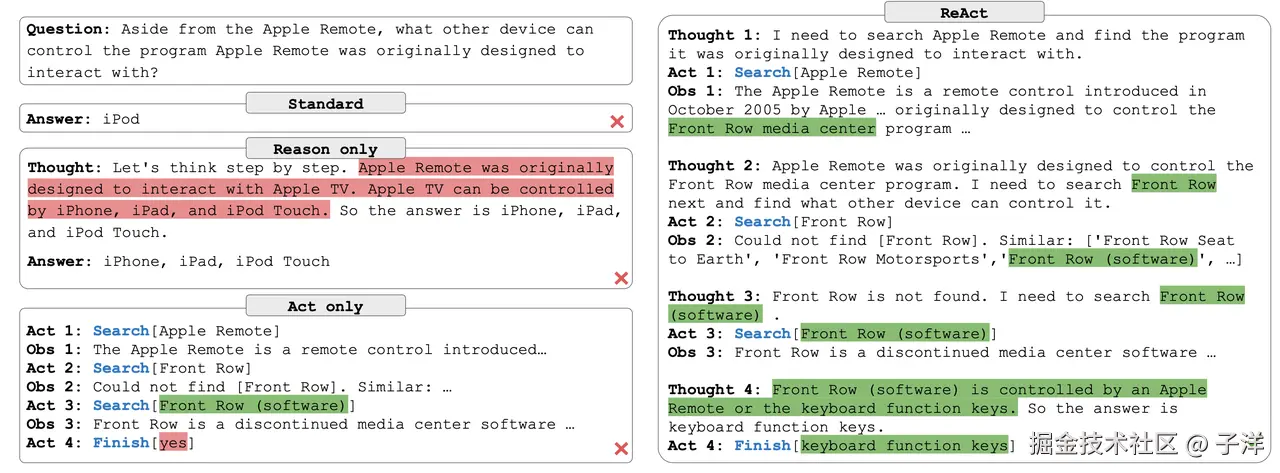
上图是 ReAct 论文中的一个示例,主要对比了 Standard、Reason Only、Act Only 以及 ReAct 四种不同范式在同一问题下的表现差异。Standard 方式直接给出答案,既不显式展开推理,也不与外部环境交互;Reason Only 虽然在回答前进行了逐步推理,但推理过程完全依赖模型自身的知识,一旦前提判断错误,结论便无法被外部信息纠正;Act Only 则能够多轮调用搜索等工具获取信息,但由于缺乏明确的推理指导,行动过程较为盲目,最终仍然得出了错误结果。相比之下,ReAct 通过多轮 Thought → Act → Observation 的交错执行,使模型能够在行动结果的反馈下不断修正推理路径,最终在后续轮次中得到正确答案。
核心实现
从工程角度看,ReAct 的实现并不复杂,其本质就是一个带有终止条件的循环控制结构。可以用下面这段高度简化的伪代码来概括:
JavaScript
// 简化版实现逻辑
for (let i = 0; i < maxLoops; i++) {
// 1. 思考:LLM分析当前情况,决定做什么
const { thought, action, args, final } = await llmThink();
if (final) {
// 任务完成
break;
}
// 2. 行动:调用具体的工具
const result = await callTool(action, args);
// 3. 观察:将结果作为下一次思考的输入
context.push(`观察到:${result}`);
}这段代码已经基本覆盖了 ReAct 的核心机制:
- 循环驱动:模型在多轮中逐步逼近目标
- 模型自决策:由 LLM 决定是否继续、是否调用工具
- 显式终止条件 :通过
final或循环上限避免失控
在真实系统中,通常还会叠加更多安全与成本控制机制,例如:
- 最大循环次数(maxLoops)
- token 或调用预算
- 工具调用白名单
具体实现
下面将结合一份实际可运行的代码示例,展示一个简化但完整的 ReAct Agent 实现。
LLM 调用
这里使用 @ai-sdk 封装多厂商模型调用,示例中支持 OpenAI 与 Azure OpenAI。该部分属于基础设施层,与 ReAct 本身并无强耦合,因此不再展开其原理。具体的介绍和使用方式可以看我之前写的这篇文章 《AI 开发者必备:Vercel AI SDK 轻松搞定多厂商 AI 调用》 。
js
import { generateText } from "ai";
import { createOpenAI } from "@ai-sdk/openai";
import { createAzure } from "@ai-sdk/azure";
/**
* Build a model client from env/config.
* Supported providers: 'openai', 'azure'.
*/
export function getModelClient(options = {}) {
const {
provider = process.env.AI_PROVIDER || "openai",
apiKey = process.env.AI_PROVIDER_API_KEY,
baseURL = process.env.OPENAI_BASE_URL || process.env.AZURE_OPENAI_BASE_URL,
resourceName = process.env.AZURE_OPENAI_RESOURCE_NAME, // for azure
} = options;
if (process.env.AI_MOCK === "1") {
return { client: null, model: null };
}
if (!apiKey) {
throw new Error("Missing API key: set AI_PROVIDER_API_KEY");
}
if (provider === "azure") {
const azure = createAzure({ apiKey, resourceName });
return { client: azure, model: azure("gpt-5") };
}
const openai = createOpenAI({ apiKey, baseURL });
const modelName = process.env.OPENAI_MODEL || "gpt-4o-mini";
return { client: openai, model: openai(modelName) };
}
/**
* Chat-like step with messages array support.
* messages: [{ role: 'system'|'user'|'assistant', content: string }]
*/
export async function llmChat({ messages, schema, options = {} }) {
const { model } = getModelClient(options);
const system = messages.find((m) => m.role === "system")?.content;
const result = await generateText({
model,
system,
messages,
...(schema ? { schema } : {}),
});
return result;
}核心作用只有一个:以 Chat 形式向模型发送上下文,并获得结构化输出。
ReAct 主逻辑
在下面这段代码中,我们完整实现了一个 ReAct Agent 的核心循环逻辑。首先通过 system prompt 对模型的输出形式和行为进行强约束,明确要求其仅以 JSON 格式返回结果 ,且只能包含 thought、action、args、final 四个字段,并分别约定了调用工具与结束任务时的输出规范。与此同时,在 user 消息中显式告知模型当前可用的 tools 列表,并附带每个工具的功能说明与参数定义,使模型能够在循环过程中基于明确的能力边界自主决策是否进行工具调用。
js
import { llmChat } from "../llm/provider.js";
import { callTool, formatToolList } from "../tools/index.js";
const SYSTEM = `You are a ReAct-style agent.
You must reason and act using the following loop:
Thought → Action → Observation
This loop may repeat multiple times.
Output format rules:
- You MUST respond with a single JSON object
- The JSON object MUST contain only the following keys:
- thought (string)
- action (string, optional)
- args (object, optional)
- final (string, optional)
- No additional keys are allowed
- Do NOT use Markdown
- Do NOT include any text outside the JSON object
Behavior rules:
- If you need to call a tool, output "thought", "action", and "args"
- If no further action is required, output "thought" and "final"
- When "final" is present, the response is considered complete and no further steps will be taken
- Do NOT include "action" or "args" when returning "final"
Always follow these rules strictly.`;
export async function runReAct({ task, maxLoops = 6, options = {} } = {}) {
const messages = [
{ role: "system", content: SYSTEM },
{
role: "user",
content: `Task: ${task}\nAvailable tools: ${formatToolList()}`,
},
];
const trace = [];
for (let i = 0; i < maxLoops; i++) {
const { text } = await llmChat({ messages, options });
let parsed;
try {
parsed = JSON.parse(text);
} catch (e) {
// console.warn("Parse failed. Text:", text);
// console.warn("Error:", String(e));
messages.push({ role: "assistant", content: text });
messages.push({
role: "user",
content: `Format error: ${String(e)}.
You previously violated the required JSON format.
This is a strict requirement.
If the response is not valid JSON or contains extra text, it will be discarded.
Retry now.`,
});
continue;
}
trace.push({ step: i + 1, model: parsed });
if (parsed.final) {
console.log("Final result:", parsed.final);
return { final: parsed.final, trace };
}
if (!parsed.action) {
messages.push({ role: "assistant", content: JSON.stringify(parsed) });
messages.push({
role: "user",
content:
"No action provided. Please continue with a tool call or final.",
});
continue;
}
console.log("Action:", parsed.action);
const observation = await callTool(parsed.action, parsed.args || {});
trace[trace.length - 1].observation = observation;
messages.push({ role: "assistant", content: JSON.stringify(parsed) });
messages.push({
role: "user",
content: `Observation: ${JSON.stringify(observation)}. Continue.`,
});
}
return { final: "Max loops reached without final.", trace };
}Tools
Tools 指的是模型在 ReAct 循环中可以调用的具体外部能力接口。通常,一个工具由工具名称、功能描述、参数定义以及对应的 handler 实现 组成。下面示例中实现了两个最基础的文件操作工具:readFileTool 用于读取文件内容,writeFileTool 用于写入文件,两者都完整描述了工具名称、用途、参数 Schema 以及实际执行逻辑。createTool 只是一个用于约定工具输出结构的辅助函数,本身并不涉及核心逻辑,主要用于在非 TS 环境下做基础的参数校验。
这里使用 zod 作为参数校验工具,它可以在 JS / TS 环境中统一使用,通过定义 schema 并在运行时执行 parse 校验,有效缓解模型参数幻觉问题;同时可以直接使用 schema 生成标准的 JSON Schema,作为工具参数说明提供给模型,从而减少手写参数描述的成本。
js
import fs from "fs/promises";
import path from "path";
import { z } from "zod";
import { createTool } from "./types.js";
const readFileSchema = z.object({ file: z.string() });
const writeFileSchema = z.object({ file: z.string(), content: z.string() });
export const readFileTool = createTool({
name: "read_file",
description: "Read a UTF-8 text file from workspace",
schema: readFileSchema,
handler: async ({ file }) => {
const abs = path.resolve(process.cwd(), file);
const data = await fs.readFile(abs, "utf-8");
return { ok: true, content: data };
},
});
export const writeFileTool = createTool({
name: "write_file",
description: "Write a UTF-8 text file to workspace (overwrite)",
schema: writeFileSchema,
handler: async ({ file, content }) => {
const abs = path.resolve(process.cwd(), file);
await fs.mkdir(path.dirname(abs), { recursive: true });
await fs.writeFile(abs, content, "utf-8");
return { ok: true, message: `wrote ${file}` };
},
});实际效果
基于上述 ReAct 实现,我尝试让模型在本地环境中完成多个小游戏的生成与迭代,包括:2048、飞机大战、贪吃蛇、五子棋。从结果来看,整体完成度和可玩性都明显优于我早期纯手写的一些 demo。当然,需要强调的是:ReAct 并不会凭空提升模型能力,它更多是一种能力放大器。
最终效果在很大程度上仍然依赖于底层模型本身的代码生成、规划与理解能力,而 ReAct 负责的,是为这些能力提供一个稳定的执行框架。
2048

飞机大战
贪吃蛇
五子棋
结语
ReAct 并不是最复杂、也不是最"智能"的 Agent 模式,但它结构清晰、实现成本低、工程可控性强,是理解和实践 Agent 系统非常合适的起点。
在后续更复杂的场景中,往往会在 ReAct 之上叠加:规划(Plan & Execute)、反思(Reflection)、记忆与长期状态,但无论如何,ReAct 所确立的 思考---行动---反馈闭环,仍然是多数 Agent 系统绕不开的基础结构。
在下一篇中,我们将展开对 P&E(Plan and Execute)模式 的详细解析,重点介绍其设计理念、执行流程及具体实现方式。
我已将相关代码开源到 GitHub,感兴趣的同学可以下载到本地后执行一下玩玩: github.com/Alessandro-...
相关资料
- GitHub 仓库 : github.com/Alessandro-...
- AI Agent 介绍: short.pangcy.cn/u/139a9efcc...
- ReAct 模式 :www.bohrium.com/paper/read?...