搜索的各种方法
1.暴力查找
速度慢。
2.二叉搜索
查找快,但是需要提前进行排序,而且由于他的底层是数组,数据的插入删除代价很大(需要挪动数据)。
3.搜索树->二叉搜索树(O(N))->平衡树(AVL树,红黑树)(O(logN))
->多叉平衡树(B树系列)
二叉搜索树的查找效率较高,但是存在部分极端情况,会导致查找效率较低。
4.哈希
容器分为序列式容器和关联式容器
序列式容器:vector/list......
关联式容器:map/set......
map/set的使用
set的底层时一个key的搜索树
map的底层则是一个key-value的搜索树
set的使用
使用set需要包含头文件**#include<set>**

eg.
cpp
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(2);
s.insert(5);
s.insert(8);
s.insert(8);
s.insert(8);
s.insert(4);
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}结果如下:

可以看出尽管插入时是乱序,在迭代器输出时仍是顺序
因为set的底层是二叉搜索树,迭代器默认遍历的顺序是中序
插入时存在重复数据时,set也会进行自动去重,因为它的底层是二叉搜索树
删除
cpp
//删除最小值
s.erase(s.begin());
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
//删除特定值
s.erase(4);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
由于set本身的特性,它的开头就是最小值
但是就算用erase删除一个不存在的值也不会报错
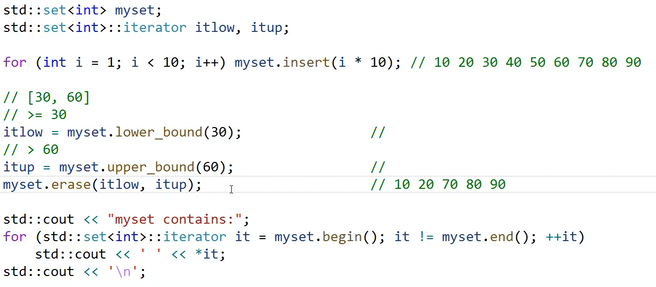
边界
边界有lower_bound和upper_bound
lower_bound返回小于等于参数的值的迭代器
upper_bound返回大于等于参数的值的迭代器
想在搜索树中寻找一定数值的区间时,可以使用该函数
multiset
multiset是一种允许数值冗余的set
本质上是一种二叉搜索树的变形
当已经存在的数值再次插入该二叉搜索树时,通常按照比他大处理(向右边插入)
但是实际上相等的值不管是向左插入还是向右插入,都没有关系,因为旋转后,插入右边的相同值也可能旋转到左边
multiset与set的区别
1.插入时允许相等的值插入
2.find查找x时,多个x在树中,返回中序的第一个x
在multiset中使用erase(x)则会删除所有的x值
map的使用
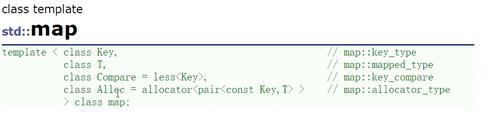
map使用pair来存储key和value,pair里的两个成员分别是first和second
pair的底层大概如下:

map的五种插入方法
eg.
cpp
map<string, string> dict;
pair<string, string> kv1("left", "左边");//有名对象
dict.insert(kv1);
dict.insert(pair<string, string>("right", "右边"));//匿名对象
dict.insert(make_pair("Left", "左边"));
dict.insert({ "Right", "右边" });
map<string, string> kv3 = { { "left", "左边" }, { "right", "右边" } };流插入,流提取
由于pair没有重载流插入和流提取,因此使用时需要注意
eg.
cpp
auto it = dict.begin();
while (it != dict.end())
{
cout << (*it).first << ":" << (*it).second << endl;
cout << it->first << ":" << it->second << endl;
++it;
}
cout << endl;
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;第二种遍历方法需要注意
一定要用(const type& e: dict)
因为dict内的值是结构体,要type e : dict消耗过大
operator


insert函数插入成功,则返回key所在的迭代器(刚刚插入的key所在的迭代器)(正常插入)
insert函数插入失败,则返回已经存在的相等的值所在的迭代器(查找)
无论insert成功或失败,都会返回一个与key相等值所在的迭代器
此时再对该迭代器的second解引用,则能够获得key的value
因此,operator 的功能其实是,先进行插入,如果插入失败了,则是一个查找的功能
eg.
cpp
int main()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
// 插入+修改
dict["left"] = "左边";
// 修改
dict["left"] = "左边,剩余";
// key不存在-》插入 <"insert", "">
dict["insert"];
// key存在-》查找
dict["left"];
return 0;
}因此在使用operator 时需要注意,因为如果operator 一个不存在的值,则会将该值直接插入进去
计数方法

2.使用operator 计数

map与multimap的区别
map的key相同,不管value是否相同,都不会再继续插入,也不会对已经插入的key的value进行修改
multimap不同,可以插入key相同,value不同的pair,也可以插入key和value均相同的pair
multimap的find也与multiset类似,返回中序遍历的第一个
但是multimap是不存在operator 的