视觉-语言-动作模型已成为强大的通用机器人操作策略,这得益于大规模多模态预训练。然而,在分布外的部署场景中,这些模型往往无法可靠地实现泛化,因为在这些场景中,观测噪声、传感器误差或执行扰动等不可避免的干扰现象十分普遍。虽然近期基于强化学习的后训练为适配预训练的VLA模型提供了一种实用方法,但现有方法主要强调奖励最大化,却忽视了应对环境不确定性的鲁棒性。
RobustVLA是一种轻量级的在线RL后训练方法,旨在明确增强VLA模型的韧性。通过系统的鲁棒性分析,这里确定了两个关键的正则化项:雅可比矩阵正则化,用于减轻模型对观测噪声的敏感性;平滑性正则化,用于在动作扰动下稳定策略。在多种机器人环境中的广泛实验表明,RobustVLA在鲁棒性和可靠性方面显著优于先前的先进方法。研究结果凸显了基于原则性鲁棒性感知的RL后训练的重要性,这是提高VLA模型可靠性和鲁棒性的关键一步。
论文链接:https://arxiv.org/abs/2511.01331
论文名称:RobustVLA: Robustness-Aware Reinforcement Post-Training for Vision-Language-Action Models
当下的痛点
- 视觉-语言-动作模型借助大规模多模态预训练,在机器人操作任务中展现出强大通用性,但在分布外场景中泛化能力受限。
- 分布外场景的核心挑战来自环境扰动,主要分为两类:观测扰动(传感器噪声、图像偏移、旋转、遮挡等)和动作扰动(执行器误差、高斯噪声等)。
- 现有强化学习后训练方法聚焦奖励最大化,未明确约束模型对扰动的敏感性,导致模型在真实环境中易因微小扰动出现性能大幅下降。
RobustVLA的设计逻辑
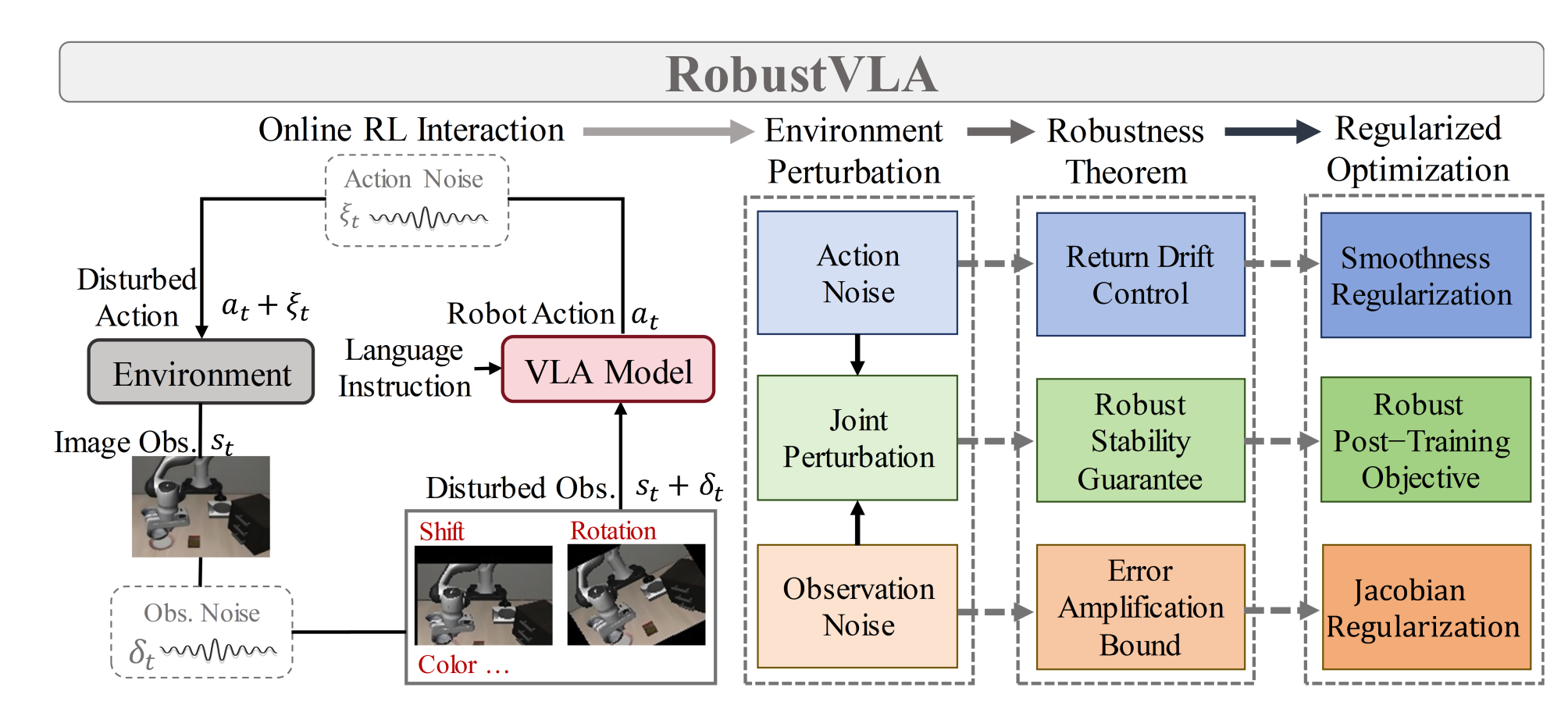
鉴于在线强化学习交互过程中存在环境不确定性,这里考虑了观测噪声(传感器/摄像头故障)和动作噪声(高斯执行误差)及其联合效应。此外,基于这三个方面开展了鲁棒性理论分析,确立了误差放大界限、回报漂移控制以及鲁棒稳定性保证。最后,我们推导出了正则化优化目标,包括模型雅可比矩阵正则化和动作平滑正则化,以及鲁棒强化学习后训练目标。

1)双正则化策略
- 雅可比正则化:针对观测扰动,通过惩罚模型对数动作概率关于观测输入的梯度范数,降低模型对观测噪声的敏感性。优化目标为:
R J a c ( θ ) = E ( s , a ) ∼ D min { ∥ ∇ s log π θ ( a ∣ s ) ∥ 2 2 , G m a x } \mathcal{R}{Jac}(\theta)=\mathbb{E}{(s,a)\sim \mathcal{D}}\left\\min\\left\\{\\big\\\|\\nabla_{s}\\log \\pi_{\\theta}(a\|s)\\big\\\|_{2}\^{2},\\, G_{max}\\right\\}\\right RJac(θ)=E(s,a)∼Dmin{ ∇slogπθ(a∣s) 22,Gmax}
- 光滑正则化:针对动作扰动,惩罚连续模型更新间的平均动作偏差,抑制模型漂移,稳定长时序决策。优化目标为:
R S m o o t h ( θ ) = E s ∼ D ∥ μ θ ( s ) − μ θ − ( s ) ∥ 2 2 \mathcal{R}{Smooth}(\theta)=\mathbb{E}{s \sim \mathcal{D}}\left\\left\\\| \\mu_{\\theta}(s)-\\mu_{\\theta\^{-}}(s)\\right\\\| _{2}\^{2}\\right RSmooth(θ)=Es∼D∥μθ(s)−μθ−(s)∥22
整体优化目标
- 融合PPO的优势优化、雅可比正则化和光滑正则化,形成鲁棒后训练目标:
L R o b u s t V L A ( θ ) = L P P O ( θ ) + α R J a c ( θ ) + β R S m o o t h ( θ ) \mathcal{L}{RobustVLA}(\theta)=\mathcal{L}{PPO}(\theta)+\alpha \mathcal{R}{Jac}(\theta)+\beta \mathcal{R}{Smooth}(\theta) LRobustVLA(θ)=LPPO(θ)+αRJac(θ)+βRSmooth(θ)
- 其中α和β为超参数,分别控制两种正则化的强度。
自适应噪声调度
- 基于模型的平滑成功率动态调整注入的观测/动作噪声强度:成功率高于阈值则提升噪声,低于阈值则降低噪声。
- 该机制避免训练初期因强扰动导致模型不稳定,同时逐步提升模型的抗扰动能力。
理论支撑:鲁棒性边界分析
观测扰动的误差放大边界(定理1)
- 当观测存在扰动 s ~ t = s t + δ s t \tilde{s}{t}=s{t}+\delta_{s}^{t} s~t=st+δst( ∥ δ s t ∥ ≤ ϵ s \left\|\delta_{s}^{t}\right\| ≤\epsilon_{s} ∥δst∥≤ϵs)时,鲁棒性差距满足:
J ( π ∗ ) − J ( π ) ≤ O ( H L r L f H ) ⋅ ( ϵ o f f l i n e + λ ϵ s ) J(\pi^{*})-J(\pi) \leq \mathcal{O}\left(H L_{r} L_{f}^{H}\right) \cdot\left(\epsilon_{offline }+\lambda \epsilon_{s}\right) J(π∗)−J(π)≤O(HLrLfH)⋅(ϵoffline+λϵs)
- 核心洞察:模型的雅可比敏感性λ直接影响误差放大效果,通过雅可比正则化缩小λ可有效约束性能损失。
动作扰动的回报漂移边界(定理2)
- 当动作存在高斯扰动 a t = π t ( s t ) + ξ t a_{t}=\pi_{t}(s_{t})+\xi_{t} at=πt(st)+ξt( ξ t ∼ N ( 0 , σ 2 I d ) \xi_{t} \sim N(0, \sigma^{2} I_{d}) ξt∼N(0,σ2Id))时,鲁棒性差距满足:
J ( π ∗ ) − J ( π ) ≤ O ( H L r L f H ) ⋅ ( ϵ o f f l i n e + ∑ t = 1 H δ t + σ d ) J(\pi ^{*})-J(\pi )\leq \mathcal {O}(H L_{r}L_{f}^{H})\cdot \left( \epsilon _{offline }+\sum _{t=1}^{H}\delta _{t}+\sigma \sqrt {d}\right) J(π∗)−J(π)≤O(HLrLfH)⋅(ϵoffline+t=1∑Hδt+σd )
- 核心洞察:回报漂移由模型累积漂移 ∑ t = 1 H δ t \sum_{t=1}^{H}\delta_{t} ∑t=1Hδt和动作噪声 σ d \sigma\sqrt{d} σd 共同驱动,光滑正则化可限制 δ t \delta_{t} δt以稳定性能。
联合扰动的鲁棒稳定性边界(定理3)
- 当观测和动作扰动同时存在时,鲁棒性差距满足:
J ( π ∗ ) − J ( π ) ≤ O ( H 2 L r L f H ) ⋅ ( ϵ o f f l i n e + ∑ t = 1 H δ t + λ ϵ s + σ d ) J\left(\pi^{*}\right)-J(\pi) \leq \mathcal{O}\left(H^{2} L_{r} L_{f}^{H}\right) \cdot\left(\epsilon_{offline }+\sum_{t=1}^{H} \delta_{t}+\lambda \epsilon_{s}+\sigma \sqrt{d}\right) J(π∗)−J(π)≤O(H2LrLfH)⋅(ϵoffline+t=1∑Hδt+λϵs+σd )
- 核心洞察:双扰动下误差会通过反馈循环放大,需同时施加两种正则化才能约束复合误差累积。
实验对比分析
基准实验设置
- 这里基于LIBERO平台构建鲁棒测试基准,包含5种观测扰动和3种动作扰动。
- 对比基线包括离线模仿学习、离线强化学习、在线强化学习三类共8种主流方法,RobustVLA分为无课程学习和有课程学习两个版本。
核心实验结果
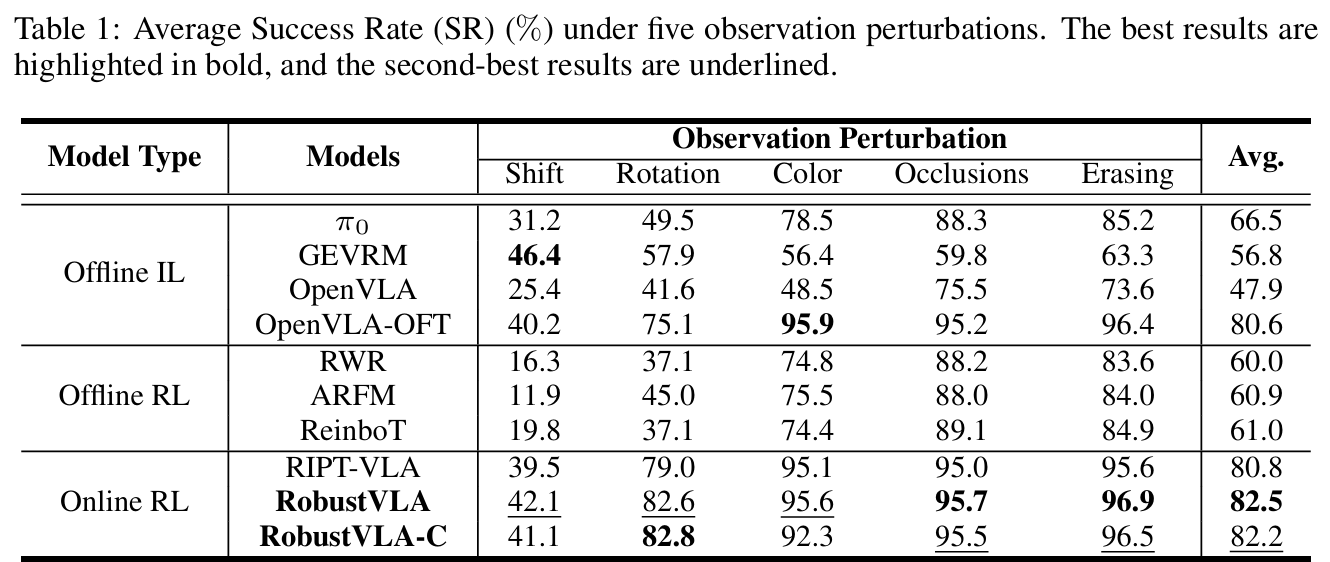
- 观测扰动场景:RobustVLA和RobustVLA-C平均成功率分别达82.2%和82.5%,显著优于OpenVLA-OFT的80.6%和RIPT-VLA的80.8%,验证雅可比正则化的有效性(table1)。
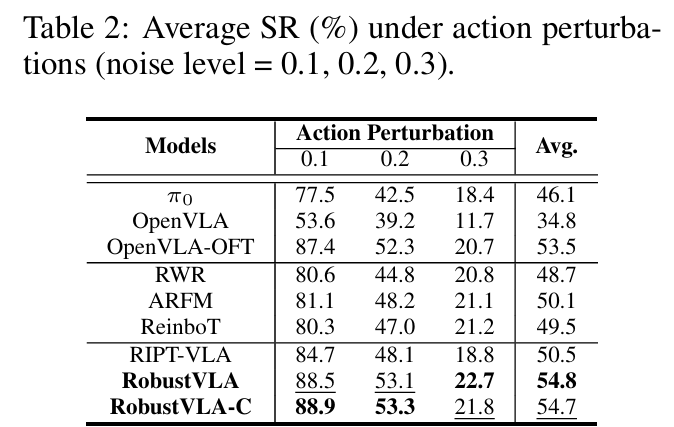
- 动作扰动场景:两者平均成功率均约54.7%,超过OpenVLA-OFT的53.5%和ARFM的50.1%,证明光滑正则化对动作噪声的抵抗能力(table2)。
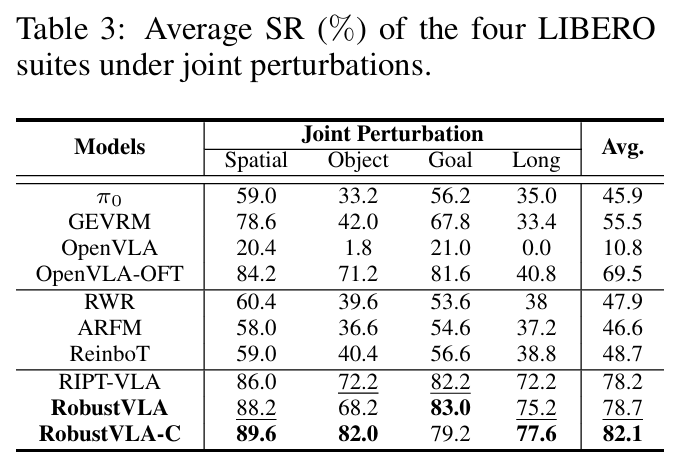
- 联合扰动场景:RobustVLA-C以82.1%的平均成功率大幅领先,在线强化学习方法整体优于离线方法,凸显自主交互+双正则化的协同作用(table3)。
迁移学习与消融实验
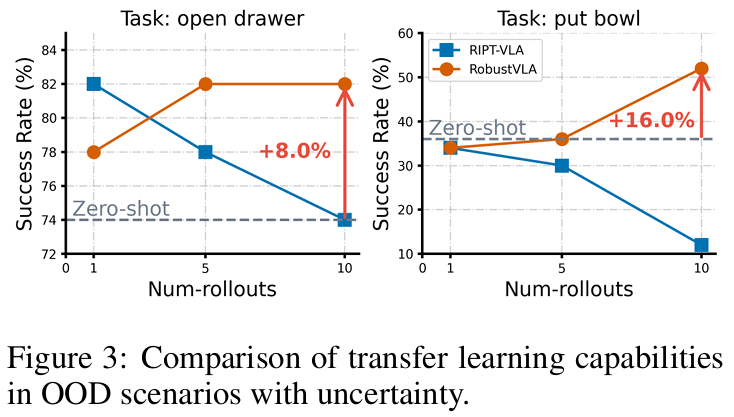
- 迁移学习:在"开抽屉""放碗"等任务中,RobustVLA相较于零样本迁移分别提升8.0%和16.0%,展现更强的分布外适应能力(figure3)。
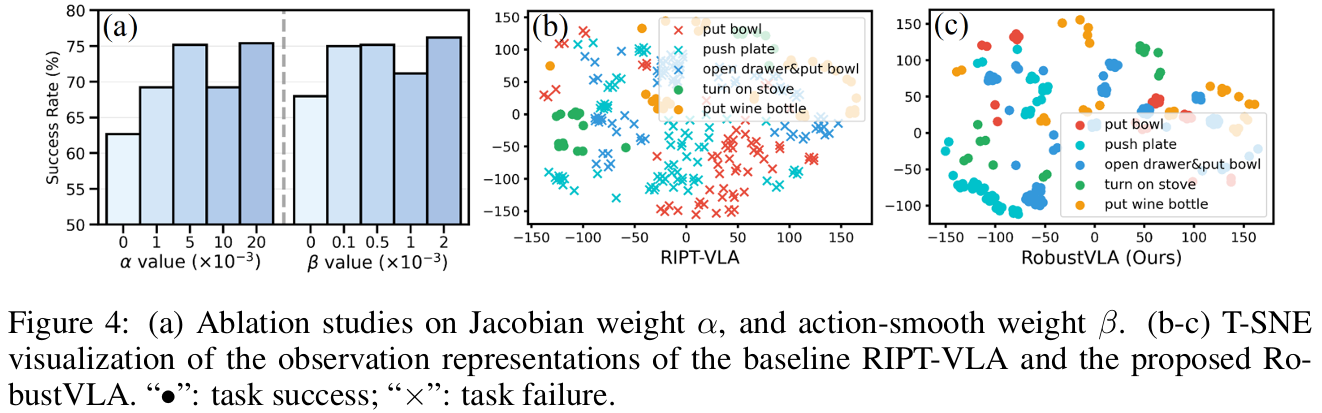
- 消融实验:移除雅可比正则化或光滑正则化均会导致性能下降,证明双正则化是鲁棒性提升的关键;T-SNE可视化显示,RobustVLA的观测表征在扰动下更稳定(figure4)。
参考
1RobustVLA: Robustness-Aware Reinforcement Post-Training for Vision-Language-Action Models
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?