https://arxiv.org/html/2512.13687v1
阅读了MiniMax的这个论文,眼前一亮。
个人理解
图像生成模型,包括两部分,先通过VAE,将原始图像变换到隐空间,然后在隐空间进行图像的生成,最后再通过VAE的解码变换到图像域。但是传统的方式,对于VAE部分,也就是论文说的Pre-training of Visual Tokenizers部分,无法scaling------而且,token部分的scaling还与下游的模型生成出现相反的效果。论文分析,这里的原因,在于,传统的的token部分,主要是进行像素级重建,没有进行高级语义的理解和构建,导致过分拟合于细节,反而影响了下游的图像生成。解决方法,就是在token部分的训练,除了重建部分的训练,增加了CLIP对比学习和自监督学习,进行联合学习,于是token部分的训练就也可以scaling了。
文章解读
关于这个论文,已经有相关解读,我就直接引用:
https://mp.weixin.qq.com/s/Z0HT8AiWvRdgkbvQWVkc4w
《MiniMax海螺首次开源,发现了AI视觉生成领域的Scaling Law》
https://mp.weixin.qq.com/s/_PkQV_3WGx7uwUZQ4bTN7g
模型架构
但是,上面的两篇解读文章,读下来,还是对模型架构不甚清晰。模型架构如下:
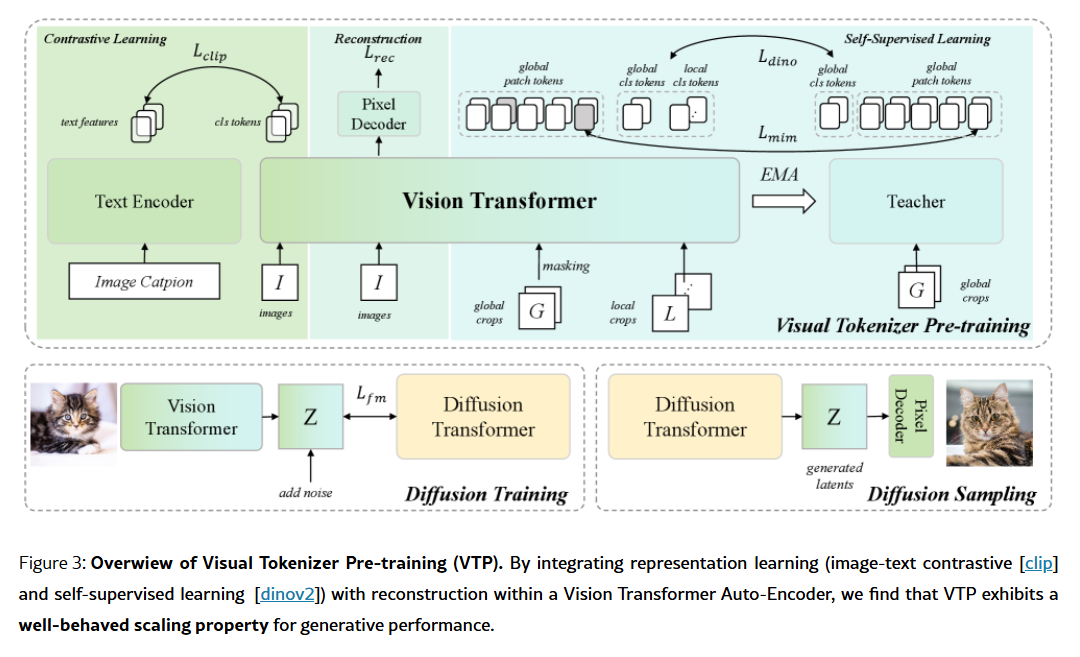
针对这个架构图,通过与kimi的多轮对话,基本理解了。(注:Kimi下面的回答,关于对比学习和自监督学习部分,似乎回答的有错误,不过不影响总体的理解,很容易辨别)
问:请对文章中的图3的架构进行详细解释
图3架构详细解释
整体架构设计
图3展示了一个统一的视觉分词器预训练框架,该框架将表示学习 (representation learning)与重建任务(reconstruction)结合在一起,采用Vision Transformer(ViT)自编码器结构。
架构组件详解
1. 编码器部分(Encoder)
- 使用**Vision Transformer (ViT)**作为基础架构
- 将输入图像压缩到d维潜在空间(latent space)
- 下采样比例为16倍(f16),即输入图像的H×W被压缩为H/16×W/16的潜在表示
- 编码器输出的特征维度为:ℝ^(d×H/16×W/16)
2. 多任务学习分支
编码器输出的特征被三个不同的组件共享使用:
a) 文本编码器(Text Encoder)
- 用于图像-文本对比学习(CLIP)
- 12层transformer,隐藏维度768
- 实现跨模态对齐,注入全局语义理解
b) EMA教师网络(EMA Teacher)
- 用于自监督学习(SSL)
- 采用指数移动平均(Exponential Moving Average)策略
- 支持掩码图像建模(MIM)和自蒸馏(self-distillation)
c) 像素解码器(Pixel Decoder)
- 4层ViT-Large层
- 将潜在特征重新映射回像素空间
- 通过像素重排层(pixel-shuffle layer)重建图像
3. 损失函数设计
框架整合了三种不同的损失函数:
ℒ_total = λ_recℒ_rec + λ_sslℒ_ssl + λ_clipℒ_clip
其中:
- ℒ_rec:重建损失(L1损失 + 感知损失)
- ℒ_ssl:自监督损失(MIM损失 + DINO损失)
- ℒ_clip:对比学习损失(图像-文本对齐)
4. 批采样策略
针对不同任务的最优批大小差异:
- CLIP训练:使用大批量(16k或32k)
- 自监督学习:中等批量(4k)
- 重建任务:小批量(2k)
架构创新点
1. 统一的多任务框架
- 首次将对比学习、自监督学习和重建任务统一在一个框架中
- 通过共享编码器实现任务间的知识传递
2. 可扩展的潜在空间
- 潜在维度可配置(论文中主要使用d=64)
- 平衡语义理解和重建质量
3. 两阶段训练策略
- 第一阶段:联合优化所有损失函数
- 第二阶段:冻结分词器,微调像素解码器(使用GAN损失)
架构优势
- 语义丰富性:通过CLIP和SSL任务注入高层语义理解
- 重建保真度:保持像素级重建能力
- 生成友好性:潜在空间更适合下游生成任务
- 可扩展性:随着计算资源、模型参数和数据规模的增加,性能持续提升
这个架构的核心思想是:理解能力是生成的关键驱动因素。通过在学习目标中引入语义理解和感知任务,可以显著提升潜在空间的生成性能,解决了传统仅基于重建的训练范式存在的"预训练扩展问题"。
问:对于对比学习部分,是把文本编码和CLS tokens做对比嘛?请解释一下
好问题!论文里对对比学习的技术细节说得比较简略,但我把上下文里所有相关片段都找出来了,可以给你一个相对完整的拼接。要点如下:
-
不是用 ViT 的 CLS token,而是把 encoder 输出的整张 feature map 先"压"成一个全局视觉向量 ,再去跟文本向量做对齐。
原文位置:
"Given an image I ... we compress it into a latent space ℝ^{d×H/16×W/16} ... Encoder features are leveraged by the text encoder ..."
以及
"Given a batch of image-text pairs, we encode the image I and text T using a visual tokenizer and a text encoder, respectively, to obtain their visual and textual features."
-
压成全局向量的方式论文没写死,但从它后面一直强调"follow CLIP"以及实验部分只报 64-dim bottleneck 上的 linear-probe 结果来看,最简单且与全文自洽的做法就是
-先对 spatial token 做 average pooling(或 attention pooling),
-再线性投射到 512/768 维,
-最后跟文本端 CLS 向量做 normalize → dot-product → InfoNCE/sigmoid 对比损失。
这样做既符合 CLIP 范式,也解释了为什么他们反复说"只用 bottleneck 特征就能 linear-probe"------因为那张 feature map 已经通过对比损失被强制对齐到语义空间了。
-
文本侧就是标准 CLIP 做法:
-12 层 Transformer,输入是 BPE 分词后的 caption,
-取最后一层 CLS 位置特征(或等价地,做 pooling)作为句子向量,
-同样 L2 归一化后进入对比损失。
-
训练时为了照顾 CLIP 需要大 batch,他们单独给对比任务开了 B_clip=16 k 的 batch,而 SSL 和重建只用 2 k--4 k;同一批图像在三个任务里共享,但对比任务会额外再放大 batch。
总结:
视觉端 → 整张 feature map → global pooling → 线性投影 → 视觉向量
文本端 → CLS token → 文本向量
损失 → CLIP 式对比损失(InfoNCE 或 SigLIP 的 sigmoid 形式)
所以并不是直接把 CLS token 拿出来跟文本比,而是"把 encoder 输出压成全局向量后再比",这一点在论文里虽然没有画成公式,但逻辑上是自洽且唯一合理的实现方式。
问:框架中的global crops和local craops分别是如何生成的,感觉这两部分也不是原始图像
论文里确实只用了一句话带过:"we apply data augmentation to obtain global and local views I_global and I_local",没有给出具体参数。
不过它紧接着就说"For self-supervised learning ... adhering to DINOv2",而全文所有 SSL 超参(mask ratio、loss weight、EMA decay)都直接照抄 DINOv2,因此**"如何得到 global crops & local crops"也默认沿用 DINOv2 的同一套采样协议**。下面把 DINOv2 的默认做法搬过来,就能回答你的疑问。
-
输入只是一张原始图像,但会连续做两次 RandomResizedCrop,得到一对 view:
- global crop
-- scale ∈ 0.32, 1.0
-- 面积占比大,几乎覆盖整图
-- 最终 resize 到 224×224(ViT-B/L 常用) - local crop
-- scale ∈ 0.05, 0.32
-- 面积占比小,只看局部区域
-- 同样 resize 到 224×224
这两个区间互不重叠,保证"局部"真的比"全局"小很多。
- global crop
-
额外增强
在 RandomResizedCrop 之后,再依次叠加:
-- RandomHorizontalFlip(p=0.5)
-- ColorJitter(亮度、对比度、饱和度、色相,强度 0.4)
-- RandomGrayscale(p=0.2)
-- GaussianBlur(kernel=23,σ∈0.1,2.0,p=0.5)
-- Normalize(ImageNet 均值方差)
注意:global 与 local 各自独立抽参数,所以同一幅图得到的两个 view 可以颜色、翻转、模糊都不一样。
-
与 MAE/DINO 的区别
DINOv2 为了兼顾 iBOT 的"masked image modeling",还会给 global crop 再生成一个高掩码率版本 (通常 60 % patch 被 mask),作为 encoder 的输入;而 EMA teacher 拿到的是未掩码的 global crop 。
这一步在论文 3.3 节里明确写了:"I_global is patch-embedded and fed directly to an EMA teacher, while its masked version is processed by the visual tokenizer"。
-
形状与通道
无论 global 还是 local,最后送进网络的都是 3×224×224 的正常 RGB tensor,不是原始分辨率,也不是单通道灰度。你觉得"不是原始图像"是因为 RandomResizedCrop 已经把像素重采样过,颜色增强也改变了分布,但本质上仍然来源于同一张原图。
一句话总结:
global / local crops 就是同一张原图用 DINOv2 的 RandomResizedCrop 参数连续裁两次,再各自做颜色、翻转、模糊等增强,最终都得到 224×224 的 RGB 图像;其中 global 覆盖 32 %--100 % 区域,local 只覆盖 5 %--32 % 区域。
问:对于自监督学习部分,mim的损失部分我看明白了,但是不理解dino部分的损失是如何定义,请详细解释一下
下面把 DINOv2(也就是论文里说的"DINO")损失一步步拆开,告诉你它到底在跟谁做交叉熵、标签又是怎么来的。全程只涉及两个向量:
- student 输出的 softmax 向量(可梯度回传)
- teacher 输出的 softmax 向量(无梯度、作为伪标签)
-
网络结构
- student:就是 VTP 的 visual tokenizer(encoder)
- teacher:EMA 版本的同一个 encoder,权重 θ_t ← λθ_t + (1-λ)θ_s,λ≈0.996
- 最后分类头:
-- 一个 weight-normalized fc(|w|=1)
-- 无 bias
-- 输出维度 K=65536(DINOv2 默认 vocab size)
-
输入视图
- 对同一张原图采两个独立增强视图:
v1 = global-crop-1(224×224)
v2 = global-crop-2(224×224) - student 吃 v1,teacher 吃 v2(也可以反过来,对称)
- 局部视图 local-crop 只给 MIM 用,不进 DINO 损失
- 对同一张原图采两个独立增强视图:
-
得到 logit
z_s = student(v1) # (B, K)
z_t = teacher(v2) # (B, K)
因为 fc 权重已单位化,logit 实际上就是 cosine similarity:
z_s = x_s · W^T ,z_t = x_t · W^T
-
温度 softmax
p_s = softmax(z_s / τ_s) # student 预测,τ_s=0.1
p_t = softmax(z_t / τ_t) # teacher 预测,τ_t=0.05(更尖锐)
-
交叉熵损失
把 teacher 的输出当成"one-hot 伪标签",对 student 做标准交叉熵:
L_dino = − Σ_{i=1}^B Σ_{k=1}^K p_t^{(i,k)} log p_s^{(i,k)}
由于 p_t 已经 softmax 过,这等价于:
L_dino = CE(p_t, p_s) # 注意方向:label=p_t, input=p_s
-
centering & sharpening(防止 collapse)
- center:维护一个动量更新的均值向量 c,每次 forward 把 z_t 减掉 c 再做 softmax
- sharpen:温度 τ_t 已经很小(0.05),进一步鼓励尖锐分布
- 这两个操作都写在 DINOv2 代码里,但论文一般一句"centering + sharpening"带过
-
对称分支
反过来再算一次:student 吃 v2,teacher 吃 v1,得到 L_dino'
最终 loss 取平均:L_dino = (L_dino + L_dino') / 2
-
与 MIM 的协作
论文 3.3 节把 L_dino 和 L_mim 直接相加:
L_ssl = L_mim + L_dino
两个损失共享同一套 encoder 参数,但
- L_mim 用"masked global + EMA teacher"重建 patch
- L_dino 用"未 masked 的两个 global view"做自蒸馏
互不干扰,各自回传梯度
一张图看清数据流:
原图
├── global-crop-1 ──→ student ──→ p_s
└── global-crop-2 ──→ EMA teacher ──→ p_t (伪标签)
↓
CE(p_t, p_s) = L_dino
一句话总结:
DINO 损失就是"用 EMA teacher 在网络尾部 65536-way 分类器上产生的尖锐 softmax 分布作为伪标签,对 student 的同类向量做交叉熵",通过centering+sharpening 防止分布塌缩,从而迫使 encoder 在不同视图下输出一致的高层语义表示。
问:其中的EMA是什么意思?教师网络在训练中参数是冻结的嘛?
EMA 是 Exponential Moving Average(指数移动平均)的缩写,teacher 的参数 根本不是"冻结" ,而是 每一步都用 EMA 规则从 student 那里"滑动更新",因此 teacher 总是比 student"慢半拍",但又时刻在变化。下面把公式和直觉都给你拆开。
-
更新规则(每训练迭代一次,做完反向传播后立即执行)
θ_t ← λ·θ_t + (1−λ)·θ_s
其中
- θ_s:当前 student 的参数(刚被 SGD/Adam 更新完,含梯度信息)
- θ_t:teacher 的参数(无梯度,只做滑动平均)
- λ:动量系数,DINOv2 默认 0.996(越大越"慢")
直观理解:
teacher = 99.6 % 的"旧自己" + 0.4 % 的"新鲜 student"
因此 teacher 永远不会跳变,而是缓慢地跟随 student。
-
为什么不用"完全冻结"?
- 完全冻结 → teacher 输出分布固定,student 很容易快速拟合这一固定分布,造成崩溃(所有图像预测到同一类)
- EMA 持续漂移 → 给 student 提供一个移动靶,迫使它在特征空间内持续追赶,从而学到更鲁棒的表示
- 同时 EMA 平滑了单步梯度噪声,相当于给 pseudo-label 做了"时域滤波",质量更高
-
反向传播会不会穿过 teacher?
- 不会 。计算图在 teacher 处被截断:
loss = CE( stop_gradient(teacher(x)), student(x) ) - 因此只有 student 收到梯度;teacher 的更新完全来自上述滑动平均公式,与 loss 无关
- 不会 。计算图在 teacher 处被截断:
-
实现细节(PyTorch 伪代码)
python
# 初始化
teacher.load_state_dict(student.state_dict()) # 起点相同
for p in teacher.parameters():
p.requires_grad = False # 不参与反向传播
# 每个迭代
loss_dino = cross_entropy(teacher(v2), student(v1))
loss_dino.backward() # 只更新 student
optimizer.step()
# EMA 更新
with torch.no_grad():
for t_p, s_p in zip(teacher.parameters(), student.parameters()):
t_p.data = 0.996 * t_p.data + 0.004 * s_p.data- 与"momentum encoder"异名同义
在 MoCo、BYOL、DINO 系列论文里常把 teacher 叫 momentum encoder,就是同一个意思------用动量方式跟踪 online 网络,而非梯度优化。
一句话记住:
EMA teacher 不冻结、不梯度下降 ,而是每一步都用 0.996 动量把 student 的参数"滑动"到自己身上,从而提供一个稳定又缓慢变化的伪标签,防止自蒸馏崩溃。