今天带大家演示一套基于 Qwen2-VL 的 ComfyUI 图像反推描述词工作流。整个流程围绕"上传图像、调用大模型解析、输出精细文本描述"展开,让读者能直观看到如何把图片内容转成可直接使用的描述词。工作流结构简单但高效,核心由图像加载、视觉语言模型推理、文本展示三部分组成,能够在一次推理中生成连贯、细致的图像描述,非常适合做提示词反推、图像分析、内容理解等任务。
文章目录
工作流介绍
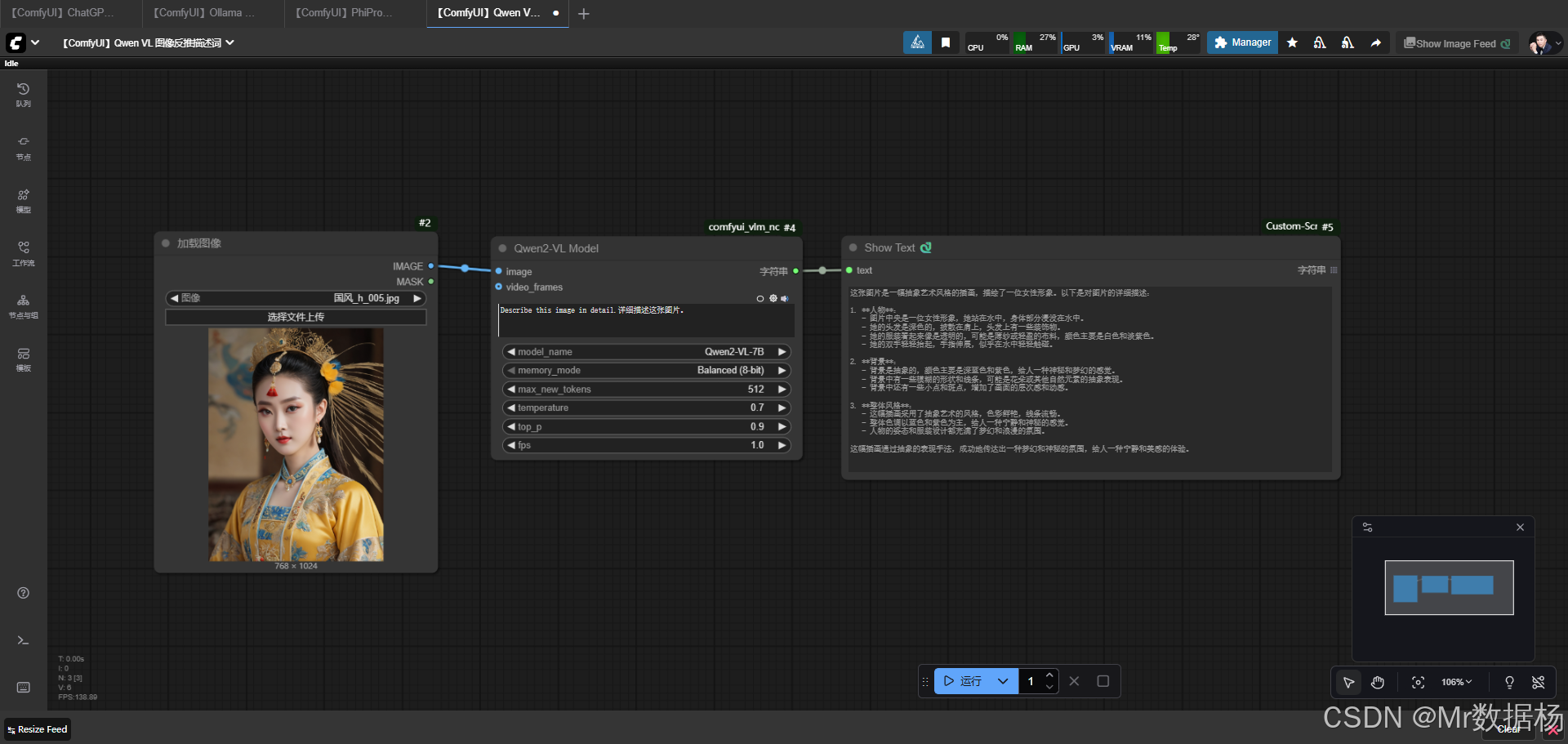
这套工作流通过 LoadImage 节点载入图片,再交由 Qwen2VLNode 执行反推描述,最后使用 ShowText 节点输出可阅读内容。它围绕一张输入图像展开分析,从主体、背景到风格信息逐层提取,并通过大模型的语言能力将视觉信息转成自然语言。核心模型负责内容理解与文本生成,节点之间连接清晰,各自承担图像输入、模型推理、结果呈现的职责,使整体流程流畅稳定。
核心模型
这套工作流依托 Qwen2-VL-7B 模型完成视觉内容解析。模型具备强大的图像理解能力,能够识别人物、环境、颜色和抽象信息,并以自然语言输出结构完整的描述文本。通过 Balanced 8-bit 推理模式,模型保持了性能与显存占用之间的平衡,使流程易于在日常设备上运行。模型的温度、top_p 和生成长度在节点内均可调整,以便控制描述的细致度和风格,从而让结果更贴近真实图像内容。
| 模型名称 | 存储需求 | 内存使用 | 推理速度 | 精度表现 | 功能描述 | 应用场景 | 模型特性/硬件要求 |
|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 中等 | 占用约6~8GB | 较快 | 精度适中 | 轻量化多模态模型,支持图像到文本生成 | 教育、科研实验、小型应用 | 适合单卡消费级显卡运行 |
| Qwen2-VL-7B | 较大 | 占用约14~20GB | 中等 | 精度较高 | 更大规模参数,语义解析更细致 | 创作、科研、内容标注 | 推荐高显存显卡(24GB以上) |
| Qwen2-VL-72B | 极大 | 占用100GB以上 | 较慢 | 精度最佳 | 超大规模模型,适合专业级应用 | 企业级部署、科研机构 | 需A100/H100级别GPU集群 |
| Qwen2-VL-2B-AWQ | 中等 | 占用约4~6GB | 较快 | 精度略降 | 2B模型的AWQ量化版,压缩后推理更快 | 移动端推理、轻量部署 | 消费级GPU即可 |
| Qwen2-VL-2B-GPTQ-Int4 | 小 | 占用约3~4GB | 很快 | 精度有所下降 | 2B模型的Int4量化版,存储需求低 | 低成本部署 | 低显存显卡即可运行 |
| Qwen2-VL-2B-GPTQ-Int8 | 中等 | 占用约5~6GB | 快 | 精度接近原版 | 2B模型的Int8量化版,兼顾速度与精度 | 教育训练、开发测试 | 消费级显卡友好 |
| Qwen2-VL-7B-AWQ | 较大 | 占用约8~12GB | 中等 | 精度略降 | 7B模型的AWQ量化版,显存需求降低 | 创意生成、中等规模项目 | 适配中高端显卡 |
| Qwen2-VL-7B-GPTQ-Int4 | 中等 | 占用约6~8GB | 较快 | 精度有所下降 | 7B模型的Int4量化版,优化存储与速度 | 研发与测试 | 单卡20GB显卡即可 |
| Qwen2-VL-7B-GPTQ-Int8 | 较大 | 占用约10~12GB | 中等 | 精度接近原版 | 7B模型的Int8量化版,性能均衡 | 模型研究与应用验证 | 高显存显卡更佳 |
| Qwen2-VL-72B-AWQ | 极大 | 占用50~70GB | 较快(对比原版) | 精度略降 | 72B模型的AWQ量化版,降低硬件门槛 | 高性能计算、企业部署 | 多GPU环境推荐 |
| Qwen2-VL-72B-GPTQ-Int4 | 大 | 占用30~40GB | 相对较快 | 精度有所下降 | 72B模型的Int4量化版,降低部署门槛 | 企业大规模场景 | 需多卡高性能GPU |
| Qwen2-VL-72B-GPTQ-Int8 | 极大 | 占用60~80GB | 中等 | 精度接近原版 | 72B模型的Int8量化版,兼顾精度与存储优化 | 专业研究、跨模态大任务 | 高端GPU服务器 |
Node节点
工作流包含三个关键节点,它们共同完成从图像输入到文本输出的完整过程。LoadImage 负责读取图片并将其转换成可供后续处理的格式。Qwen2VLNode 是整个流程的核心,它接收图像并执行视觉语言推理,将视觉内容转成文字。ShowText 节点则把生成的描述在界面中直观呈现,便于复制、阅读或做二次利用。三个节点配合紧密,使整个流程从加载、推理到输出保持简洁高效。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载外部图像作为模型输入 |
| Qwen2VLNode | 对输入图像进行视觉理解并生成描述文本 |
| ShowText | 展示模型输出的文本内容 |
工作流程
整个工作流程按照"输入图像、模型解析、文本展示"三个阶段顺序推进。流程从图像加载开始,确保输入内容稳定可靠,然后交由视觉语言模型执行深度解析,把画面中的主体元素、动作、颜色和氛围完整抽取出来。最终由文本展示节点统一输出,形成可直接使用的描述内容。各阶段既独立又连贯,使整个反推过程清晰易控。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 图像输入 | 载入本地或上传的图像,为模型解析做好准备 | LoadImage |
| 2 | 内容解析 | 对图像内容进行识别、理解并生成自然语言描述 | Qwen2VLNode |
| 3 | 文本输出 | 将生成的描述在界面中展示,便于查看和复用 | ShowText |
大模型应用
图像内容解析节点概述
Qwen2VLNode 在整个工作流中承担图像理解和文本生成的核心任务。它接收加载后的图像,根据内部设定的 Prompt 指令,对画面内容进行拆解和语言化表达。该节点的工作目标是把视觉细节还原成清晰的自然语言描述,包括人物特征、场景氛围、色彩风格等,让图像的隐含信息以文字的形式呈现。通过固定的 Prompt,它能够稳定地产生连续、完整的说明文本,是整个反推流程的关键执行者。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| Qwen2VLNode | Describe this image in detail.详细描述这张图片。 | Prompt 的目标是要求模型对图像进行全面细致的说明,从主体到背景都需明确表达。它为图像反推提供了清晰的指令,使输出内容完整、有结构,并确保生成的描述符合视觉理解任务的需求。 |
使用方法
使用这套工作流的方式非常直接。首先载入你想解析的图片,随后无需额外配置即可启动流程。图像会自动进入大模型节点,由其执行内容解析并生成文字。最后,输出的文本会在界面中完整呈现,便于复制、编辑或用于下游任务。整个过程无需手动调整节点逻辑,只需准备图像即可开始使用,是一套适合日常内容处理和提示词反推的简洁工具。
应用场景
这套工作流适用于所有需要从图像中反推文本描述的场景。它能把视觉信息快速转换成语言表达,帮助创作者提取画面要素、分析风格、生成提示词,或用于图像理解类任务。无论是做 AI 绘画提示优化、创作灵感整理,还是分析图像内容,都能给出清晰可用的文字结果。对需要理解画面结构、需要在工作中大量处理视觉内容的人来说,这套流程能显著提升效率。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 图像反推描述 | 将图像内容转成自然语言提示词或说明文本 | 绘画创作者、提示词工程师、内容生产者 | 主体、场景、风格、氛围等细节描述 | 获取结构清晰、逻辑完整的图像文字解释 |
| 图像理解辅助 | 提供视觉内容分析,帮助快速掌握画面要点 | 数据标注员、研究人员、运营编辑 | 模型生成的可读性文本 | 快速抓取核心信息,提高内容处理效率 |
| 灵感采集 | 从图像中提取创作线索和风格关键词 | 插画师、写作者、视觉创作者 | 结构化的画面理解结果 | 促进创意拓展,强化视觉与语言间的联想 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用