1. 主流大语言模型(LLM)核心技术参数的对比表
| 模型 | 结构 | 位置编码 | 激活函数 | layer norm方法 | 补充说明 |
|---|---|---|---|---|---|
| 原生Transformer | Encoder-Decoder | Sinusoidal编码 | ReLU | Post layer norm | 完整Transformer架构,适用于机器翻译等序列转换任务 |
| BERT | Encoder | 绝对位置编码 | GeLU | Post layer norm | 仅用编码器,擅长双向语义理解(文本分类、问答等) |
| LLaMA | Casual decoder | RoPE(旋转位置编码) | SwiGLU | Pre RMS Norm | 解码器+掩码,生成式大模型,RoPE适配长文本,Pre RMS Norm提升训练稳定性 |
| ChatGLM-6B | Prefix decoder | RoPE(旋转位置编码) | GeGLU | Post Deep Norm | 解码器变体,通过前缀调优增强对话能力,Deep Norm适配深层模型 |
| Bloom | Casual decoder | AliBi(相对位置编码) | GeLU | Pre Layer Norm | 解码器+掩码,AliBi支持任意长度输入,Pre Layer Norm提升训练稳定性 |
2. 输入嵌入(Input Embedding)的实现与结构
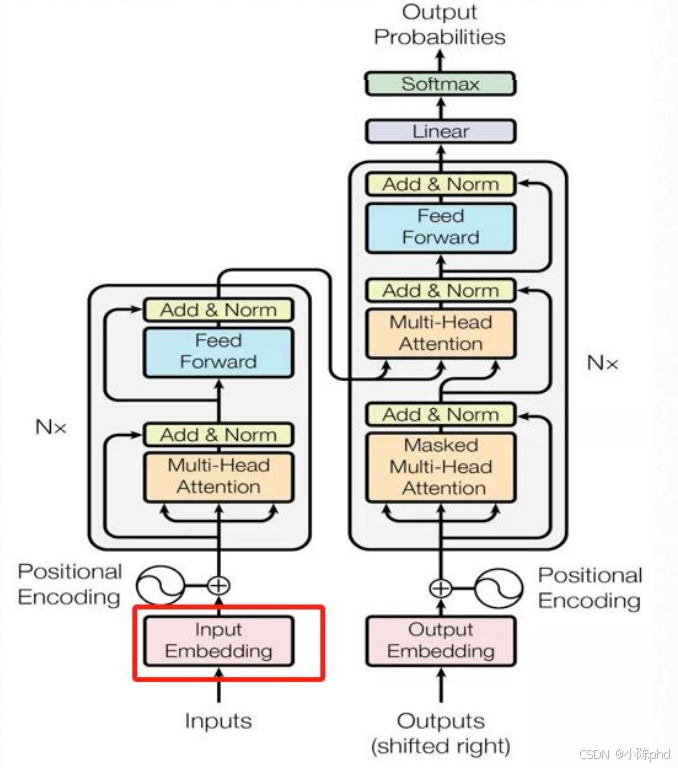
2.1 模块结构描述
Input Embedding是Transformer处理文本的首个核心模块,核心作用是将离散的单词索引(如"苹果"对应索引100)转换为连续的、固定维度的稠密向量(词向量),为后续的注意力计算、特征提取提供可数值化的输入。
其核心结构设计要点:
- 核心组件 :基于查表法实现的嵌入层(Embedding Layer),本质是一个形状为
[vocab_size, d_model]的可训练参数矩阵; - 缩放操作 :将嵌入层输出的词向量乘以
√d_model,目的是平衡词向量与后续位置编码的数值量级,避免某一部分特征主导计算; - 输入输出 :
- 输入:单词的索引序列(shape:
[batch_size, seq_len]); - 输出:维度统一的词向量序列(shape:
[batch_size, seq_len, d_model])。
- 输入:单词的索引序列(shape:
2.2 完整代码实现(PyTorch)
python
import math
import torch
import torch.nn as nn
class InputEmbedding(nn.Module):
"""
Transformer输入嵌入模块
:param vocab_size: 词汇表总大小(所有唯一单词的数量)
:param d_model: 词向量的维度(Transformer的特征维度,通常设为512/1024)
"""
def __init__(self, vocab_size: int, d_model: int):
super().__init__()
# 1. 定义嵌入层:将单词索引映射为d_model维向量
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model) # 核心嵌入层
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播:将单词索引转换为缩放后的词向量
:param x: 输入的单词索引序列,shape=[batch_size, seq_len]
:return: 缩放后的词向量,shape=[batch_size, seq_len, d_model]
"""
# 2. 嵌入层查表得到词向量 + 缩放(√d_model)
embed_output = self.embedding(x) * math.sqrt(self.d_model)
return embed_output
# ------------------- 测试示例 -------------------
if __name__ == "__main__":
# 超参数设置(符合Transformer原始论文)
VOCAB_SIZE = 10000 # 假设词汇表有10000个单词
D_MODEL = 512 # 词向量维度设为512
BATCH_SIZE = 2 # 批次大小
SEQ_LEN = 10 # 句子长度(每个句子包含10个单词)
# 1. 初始化嵌入模块
input_embedding = InputEmbedding(VOCAB_SIZE, D_MODEL)
# 2. 构造测试输入:随机生成单词索引(范围0~9999)
test_input = torch.randint(0, VOCAB_SIZE, (BATCH_SIZE, SEQ_LEN))
print("输入形状(batch_size, seq_len):", test_input.shape) # torch.Size([2, 10])
# 3. 前向传播得到词向量
embed_output = input_embedding(test_input)
print("输出形状(batch_size, seq_len, d_model):", embed_output.shape) # torch.Size([2, 10, 512])2.3 关键细节说明
-
nn.Embedding的本质 :
nn.Embedding(vocab_size, d_model)会初始化一个可训练的矩阵,每行对应一个单词的词向量,训练过程中模型会自动优化这些向量,让语义相似的单词向量更接近。 -
缩放操作的必要性 :
乘以
√d_model是为了让词向量的方差接近1(与自注意力中QK^T的缩放逻辑一致),避免后续与位置编码相加后数值量级失衡,保证模型训练稳定。 -
与位置编码的衔接 :
实际使用中,Input Embedding的输出会与"位置编码(Positional Encoding)"的输出相加,得到最终的输入向量(既包含单词语义,又包含位置信息),再送入编码器。
-
Input Embedding的核心是通过可训练的嵌入层完成"单词索引→词向量"的转换,是Transformer处理文本的基础;
-
代码实现的核心是
nn.Embedding层 + 缩放操作,保证输出向量的数值量级适配后续计算; -
该模块的输出会结合位置编码,为Transformer提供"语义+位置"的完整输入特征。
3 .位置编码(Positional Encoding)的实现与作用
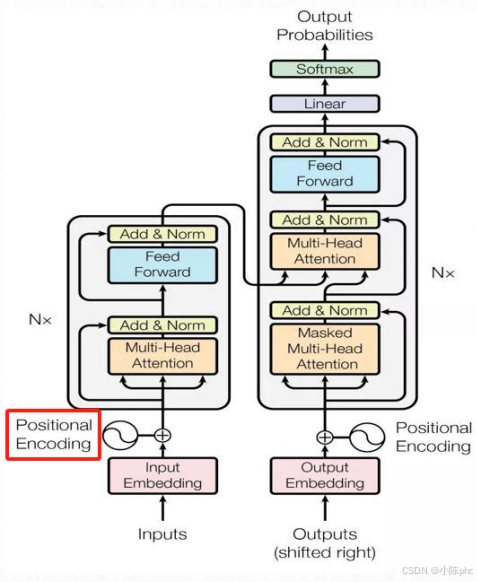
3.1 位置编码的核心作用
Transformer的注意力机制本身不具备"感知文本顺序"的能力(比如"我吃苹果"和"苹果吃我",纯注意力无法区分顺序)。位置编码的核心作用是:
给每个位置的词向量添加位置信息,让模型能识别单词在句子中的顺序,理解文本的时序关系。
3.2 位置编码的数学原理(Sinusoidal编码)
Transformer原生采用正弦/余弦位置编码 ,对应图中的公式:
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel) \begin{align*} PE_{(pos, 2i)} &= \sin\left(pos / 10000^{2i/d_{\text{model}}}\right) \\ PE_{(pos, 2i+1)} &= \cos\left(pos / 10000^{2i/d_{\text{model}}}\right) \end{align*} PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel)=cos(pos/100002i/dmodel)
pos:单词在句子中的位置(如第1个词、第2个词);i:词向量的维度索引(如512维向量的第0维、第1维);d_model:词向量的维度(如512)。- 逻辑:通过正弦/余弦函数生成位置向量,既保证不同位置的向量唯一,又能体现位置间的相对关系(如位置
pos+k与pos的编码关系固定)。
3.3 位置编码的代码实现(PyTorch)
以下是图中PositionalEncoding类的完整实现及解析:
python
import math
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, dim: int, dropout: float, max_len=5000):
"""
:param dim: 词向量维度(需为偶数,因为要分sin/cos)
:param dropout: dropout比例
:param max_len: 最大句子长度(预先生成对应长度的位置编码)
"""
super().__init__()
# 检查维度是否为偶数
if dim % 2 != 0:
raise ValueError("不能使用sin/cos位置编码,应该使用偶数维度")
# 1. 初始化位置编码矩阵pe(shape: [max_len, dim])
pe = torch.zeros(max_len, dim)
# 2. 构造位置索引pos(shape: [max_len, 1])
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 3. 计算公式中的分母项:10000^(2i/d_model)
div_term = torch.exp(torch.arange(0, dim, 2).float() * (-math.log(10000.0) / dim))
# 4. 偶数维度用sin,奇数维度用cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 5. 注册为缓存(不参与训练,仅作为常量使用)
self.register_buffer('pe', pe)
self.dropout = nn.Dropout(p=dropout)
self.dim = dim
def forward(self, emb, step=None):
"""
:param emb: Input Embedding的输出(词向量,shape: [batch_size, seq_len, dim])
:param step: 可选,指定取第step个位置的编码(用于生成式任务)
:return: 融合位置信息的词向量(shape: [batch_size, seq_len, dim])
"""
# 缩放词向量(与Input Embedding的缩放逻辑一致)
emb = emb * math.sqrt(self.dim)
# 拼接词向量与位置编码
if step is None:
emb = emb + self.pe[:emb.size(1)] # 取前seq_len个位置的编码
else:
emb = emb + self.pe[step] # 取指定step位置的编码
# 添加dropout防止过拟合
return self.dropout(emb)3.4 关键细节解析
- 为什么用sin/cos函数?
正弦/余弦的周期性让模型能更好地学习"相对位置"(比如位置pos和pos+5的编码关系固定),适配长文本场景。 register_buffer的作用?
位置编码是固定常量 ,不参与模型训练,用register_buffer将其存到缓存中,避免重复计算,节省内存。- 与Input Embedding的配合
位置编码的输出会与Input Embedding的词向量相加,最终得到"语义信息+位置信息"的输入特征,这是Transformer理解文本顺序的核心前提。
4 自注意力(Self-Attention)的实现与作用
图中为多头注意力,自注意力为其子模块。
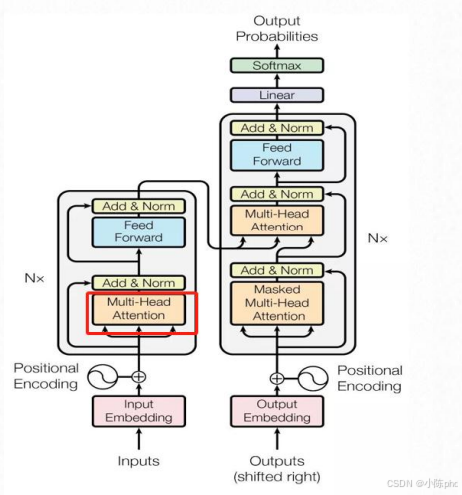
4.1 自注意力的核心作用
自注意力(Self-Attention)是Transformer的核心组件 ,作用是让模型在处理文本时,动态关注句子中不同位置的单词(比如理解"他喜欢苹果"时,让"他"和"苹果"建立关联),从而捕捉单词间的语义依赖关系。
4.2 自注意力的数学原理
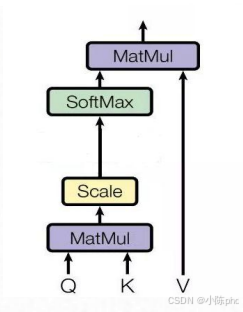
图中右上角的公式是自注意力的核心计算逻辑:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk QKT)V
- QQQ(Query):查询矩阵,代表当前单词"要找什么";
- KKK(Key):键矩阵,代表其他单词"提供什么信息";
- VVV(Value):值矩阵,代表其他单词"具体的信息内容";
- dkd_kdk:KKK的维度,dk\sqrt{d_k}dk 是缩放因子(避免QKTQK^TQKT数值过大导致softmax梯度消失)。
4.3 自注意力的代码实现(PyTorch)
以下是图中self_attention函数的完整解析:
python
import math
import torch
import torch.nn.functional as F
def self_attention(q, k, v, d_k, mask=None, dropout=None):
"""
:param q: 查询矩阵Q,shape: [batch_size, n_heads, seq_len, d_k]
:param k: 键矩阵K,shape: [batch_size, n_heads, seq_len, d_k]
:param v: 值矩阵V,shape: [batch_size, n_heads, seq_len, d_k]
:param d_k: K的维度
:param mask: 掩码(用于遮挡不需要关注的位置,如生成式任务中的"未来词")
:param dropout: dropout层(防止过拟合)
:return: 自注意力的输出,shape: [batch_size, n_heads, seq_len, d_k]
"""
# 1. 计算Q与K的相似度得分:Q*K^T / √d_k
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# 2. 应用掩码(若有):将需要遮挡的位置得分设为极小值(-1e9)
if mask is not None:
mask = mask.unsqueeze(1) # 扩展维度以匹配scores的形状
scores = scores.masked_fill(mask == 0, -1e9) # 掩码位置填充-1e9
# 3. 对得分做softmax,转换为注意力权重(总和为1)
scores = F.softmax(scores, dim=-1)
# 4. 应用dropout(若有)
if dropout is not None:
scores = dropout(scores)
# 5. 注意力权重与V相乘,得到最终输出
output = torch.matmul(scores, v)
return output4.4 代码执行流程解析
- 计算相似度得分 :
通过torch.matmul(q, k.transpose(-2, -1))计算Q与K的点积(代表单词间的关联程度),再除以dk\sqrt{d_k}dk 缩放,避免数值过大。 - 应用掩码 :
若传入mask(如生成式任务中,遮挡"未来还未生成的词"),将掩码位置的得分设为−1e9-1e9−1e9------softmax后这些位置的权重会趋近于0,模型不会关注这些位置。 - 生成注意力权重 :
对得分做softmax,将得分转换为"0~1"的权重(权重越高,代表该位置的单词越重要)。 - 计算输出 :
注意力权重与V相乘,得到融合了"关键信息"的输出(即模型关注的单词信息会被放大)。
4.5 与"多头注意力(Multi-Head Attention)"的关系
图中红色框标注的"Multi-Head Attention"是自注意力的扩展:
- 原理:将Q、K、V拆分为多个"头"(如8个),每个头独立计算自注意力,再将结果拼接------让模型同时从多个角度关注单词间的关联(比如一个头关注语法,一个头关注语义)。
- 本质:图中的
self_attention是"单头注意力",而"多头注意力"是多个单头注意力的并行计算+拼接。
5 多头注意力(Multi-Head Attention)的实现与作用
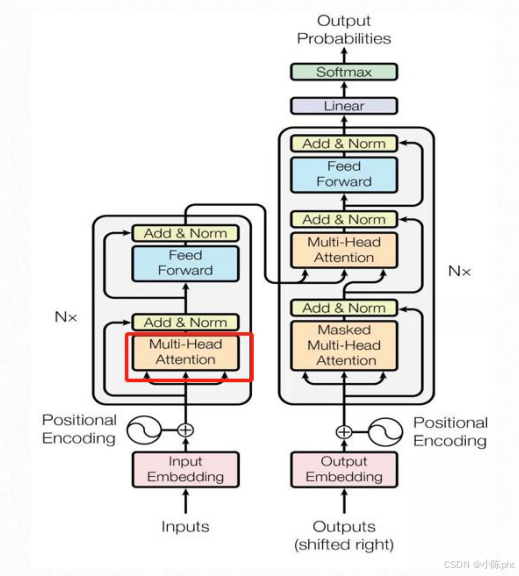
5.1 多头注意力的核心作用
多头注意力是自注意力的扩展升级,核心是让模型同时从多个不同的角度捕捉单词间的语义关联(比如一个"头"关注语法结构,一个"头"关注语义逻辑),相比单头自注意力,能更全面地理解文本的复杂关系。
5.2 多头注意力的实现逻辑
多头注意力的核心流程是:
- 拆分Q/K/V:将输入的Q、K、V通过线性层映射后,拆分为多个"头"(如8个);
- 单头注意力并行计算:每个头独立执行自注意力计算;
- 拼接输出:将所有头的输出拼接,再通过线性层得到最终结果。
5.3 多头注意力的代码实现(PyTorch)
以下是图中MultiHeadAttention类的完整解析(需结合前文的self_attention函数):
python
import torch
import torch.nn as nn
# 需引入前文定义的self_attention函数
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout=0.1):
"""
:param heads: 注意力头的数量(如8)
:param d_model: 模型的特征维度(需被heads整除)
:param dropout: dropout比例
"""
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads # 每个头的特征维度
self.h = heads # 注意力头数量
# 定义Q/K/V对应的线性层(将输入映射到d_model维度)
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model) # 最终输出的线性层
def forward(self, q, k, v, mask=None):
"""
:param q: 查询矩阵Q,shape: [batch_size, seq_len, d_model]
:param k: 键矩阵K,shape: [batch_size, seq_len, d_model]
:param v: 值矩阵V,shape: [batch_size, seq_len, d_model]
:param mask: 掩码(同自注意力)
:return: 多头注意力的输出,shape: [batch_size, seq_len, d_model]
"""
bs = q.size(0) # 获取批次大小
# 1. 线性映射 + 拆分注意力头
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# 2. 调整维度顺序:[batch_size, 头数, 序列长度, 每个头的维度]
k = k.transpose(1, 2)
q = q.transpose(1, 2)
v = v.transpose(1, 2)
# 3. 每个头独立计算自注意力
scores = self_attention(q, k, v, self.d_k, mask, self.dropout)
# 4. 拼接所有头的输出:恢复维度顺序 + 合并头
concat = scores.transpose(1, 2).contiguous() # 调整维度为[bs, seq_len, h, d_k]
concat = concat.view(bs, -1, self.d_model) # 合并为[bs, seq_len, d_model]
# 5. 最终线性层输出
output = self.out(concat)
return output5.4 代码执行流程解析
- 线性映射与拆头 :
通过q_linear/k_linear/v_linear将输入映射到d_model维度,再用view拆分为heads个独立的头(每个头维度为d_k)。 - 维度调整 :
用transpose将"头数"维度提前,保证每个头的自注意力计算独立。 - 单头注意力并行计算 :
调用前文的self_attention函数,每个头并行执行自注意力。 - 拼接与输出 :
将所有头的输出拼接,再通过out线性层整合为最终的d_model维度输出。
5.5 多头注意力的优势
相比单头自注意力,多头注意力的核心优势是**"多视角语义捕捉"**:
- 比如处理句子"猫追老鼠"时,一个头可能关注"猫"和"追"的动作关联,另一个头关注"追"和"老鼠"的对象关联,最终拼接的结果能更全面地表达句子的语义。
6. Add & Norm(残差连接+层归一化)的实现与作用
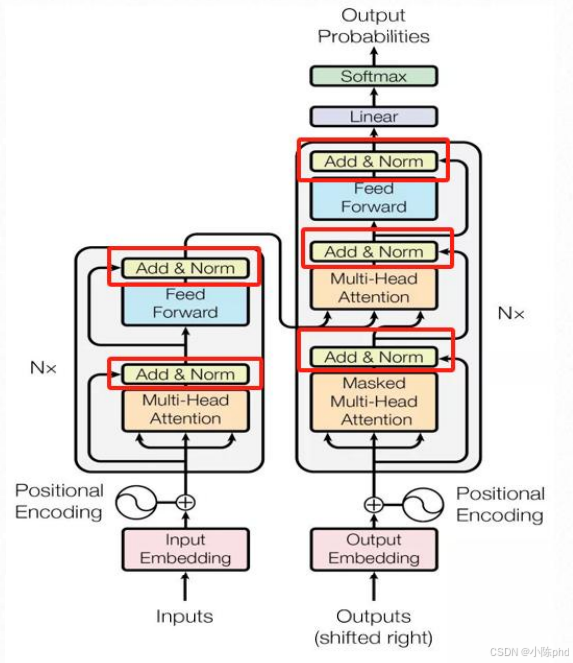
6.1 Add & Norm的核心作用
Add & Norm是Transformer中稳定训练、加速收敛的关键模块,由"残差连接(Add)"和"层归一化(Norm)"两部分组成:
- 残差连接:解决深层模型的梯度消失问题,让模型能训练更深的层数;
- 层归一化:对每一层的输出做归一化(均值为0、方差为1),避免数值波动过大,稳定训练过程。
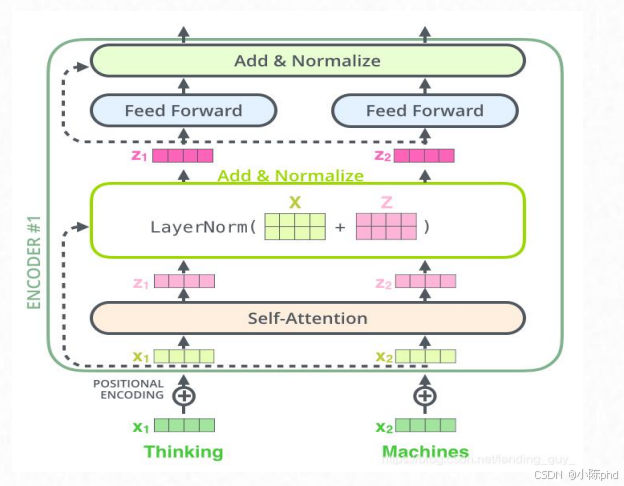
6.2 层归一化(LayerNorm)的原理与实现
层归一化的核心是对每个样本的特征维度 做归一化,公式为:
Z~j=γj⋅Zj−μjσj2+ϵ+βj\tilde{Z}_j = \gamma_j \cdot \frac{Z_j - \mu_j}{\sqrt{\sigma_j^2 + \epsilon}} + \beta_jZ~j=γj⋅σj2+ϵ Zj−μj+βj
- μj\mu_jμj:特征的均值,σj2\sigma_j^2σj2:特征的方差;
- γ、β\gamma、\betaγ、β:可训练的缩放/偏移参数(让模型自主调整归一化的幅度);
- ϵ\epsilonϵ:防止分母为0的小常数。
代码实现(图中LayerNorm类):
python
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
def __init__(self, x_size, eps=1e-6):
"""
:param x_size: 特征维度大小
:param eps: 防止分母为0的小常数
"""
super().__init__()
# 可训练的缩放参数(初始为1)
self.ones_tensor = nn.Parameter(torch.ones(x_size))
# 可训练的偏移参数(初始为0)
self.zeros_tensor = nn.Parameter(torch.zeros(x_size))
self.eps = eps
def forward(self, x):
# 计算均值(按特征维度)
mean = x.mean(-1, keepdim=True)
# 计算标准差
std = x.std(-1, keepdim=True)
# 层归一化计算:(x-均值)/标准差 * 缩放 + 偏移
return self.ones_tensor * (x - mean) / (std + self.eps) + self.zeros_tensor6.3 残差连接+层归一化(SublayerConnection)的实现
图中的SublayerConnection类实现了"残差连接+层归一化"的组合逻辑,对应Transformer架构中的"Add & Norm"环节:
代码实现(图中SublayerConnection类):
python
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
"""
:param size: 特征维度大小(与d_model一致)
:param dropout: dropout比例
"""
super().__init__()
# 层归一化模块
self.layer_norm = LayerNorm(size)
# Dropout层(防止过拟合)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, sublayer):
"""
:param x: 模块的输入(残差连接的"原始输入")
:param sublayer: 当前子模块(如多头注意力、前馈网络)
:return: 残差连接+层归一化后的输出
"""
# 逻辑:层归一化(原始输入 + 子模块输出) → 再做Dropout
return self.dropout(self.layer_norm(x + sublayer(x)))6.4 代码执行流程解析
- 残差连接 :
将"原始输入x"与"子模块(如多头注意力)的输出sublayer(x)"相加,保留原始信息,避免梯度消失。 - 层归一化 :
对残差连接的结果做层归一化,稳定数值分布。 - Dropout :
对归一化后的结果做Dropout,防止模型过拟合。
6.5 Add & Norm在Transformer中的位置
从左侧架构图可见,Transformer的编码器/解码器中,每个子模块(多头注意力、前馈网络)之后都会接一个Add & Norm:
- 例如:多头注意力的输出 → 残差连接(+原始输入)→ 层归一化 → 送入前馈网络。
Add & Norm是Transformer的"训练稳定器",由残差连接和层归一化组成:
- 残差连接解决深层梯度消失问题;
- 层归一化稳定数值分布;
- 代码实现中,
LayerNorm负责归一化计算,SublayerConnection负责将"残差连接+层归一化+Dropout"组合为一个可复用的模块,是Transformer能训练深层结构的关键保障。
7 Feed Forward(前馈网络)的实现与作用
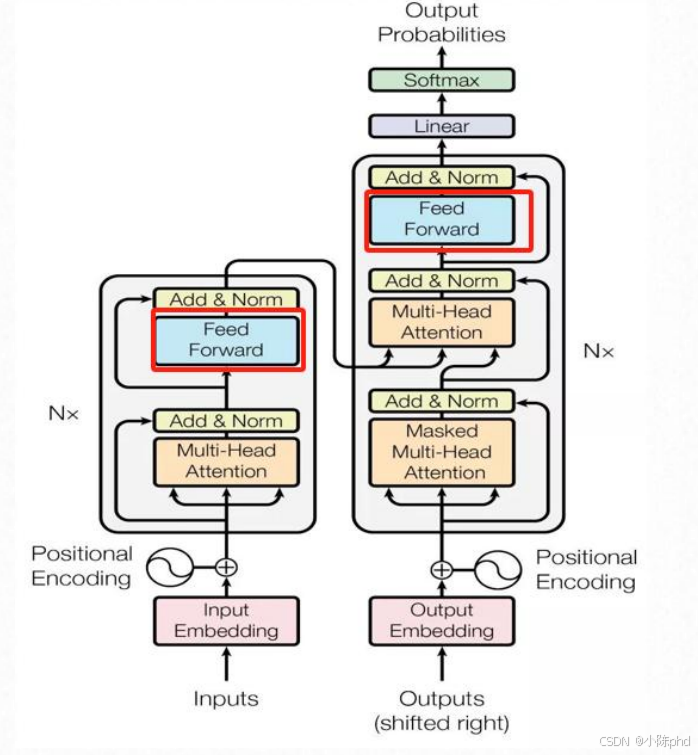
7.1 Feed Forward的核心作用
Feed Forward(也称为FFN,前馈神经网络)是Transformer中增强特征表达能力的模块,在多头注意力之后对特征做非线性变换,进一步提取更复杂的语义信息。
7.2 Feed Forward的结构设计
Transformer中的Feed Forward是两层线性网络+激活函数 的结构,通常会将中间层的维度放大(比如原始论文中d_ff=2048,是d_model=512的4倍),目的是增加模型的表达能力。
7.3 Feed Forward的代码实现(PyTorch)
以下是图中FeedForward类的完整解析:
python
import torch
import torch.nn as nn
class FeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout=0.1):
"""
:param d_model: 输入/输出的特征维度(与Transformer的d_model一致)
:param d_ff: 中间隐藏层的维度(通常是d_model的4倍)
:param dropout: dropout比例
"""
super().__init__()
# 第一层线性层:d_model → d_ff
self.w_1 = nn.Linear(d_model, d_ff)
# 第二层线性层:d_ff → d_model
self.w_2 = nn.Linear(d_ff, d_model)
# 层归一化(稳定训练)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
# Dropout层(防止过拟合)
self.dropout_1 = nn.Dropout(dropout)
# ReLU激活函数(引入非线性)
self.relu = nn.ReLU()
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x):
"""
:param x: 输入特征,shape: [batch_size, seq_len, d_model]
:return: 输出特征,shape: [batch_size, seq_len, d_model]
"""
# 1. 层归一化 → 第一层线性变换 → ReLU激活 → Dropout
inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))
# 2. 第二层线性变换 → Dropout
output = self.dropout_2(self.w_2(inter))
# 3. 残差连接(原始输入 + 输出)
return output + x7.4 代码执行流程解析
- 层归一化 :先对输入
x做层归一化,稳定数值分布; - 第一层线性变换+激活 :通过
w_1将特征维度从d_model放大到d_ff,再用ReLU引入非线性,之后做Dropout; - 第二层线性变换 :通过
w_2将特征维度从d_ff缩回到d_model,再做Dropout; - 残差连接 :将输出与原始输入
x相加,保留原始信息,避免梯度消失。
7.5 Feed Forward在Transformer中的位置
从左侧架构图可见,Transformer的编码器/解码器中,每个多头注意力模块之后都会接一个Feed Forward:
- 流程:多头注意力输出 → Add & Norm → Feed Forward → Add & Norm。
Feed Forward是Transformer中增强特征表达的模块,核心是"两层线性变换+ReLU激活+残差连接"的结构:
- 中间层放大维度(
d_ff),提升模型的非线性表达能力; - 残差连接和层归一化保证训练稳定;
- 它与多头注意力配合,让模型既能捕捉单词间的关联(注意力),又能提炼更复杂的语义特征(前馈网络)。
8 Encoder(编码器)的实现与作用
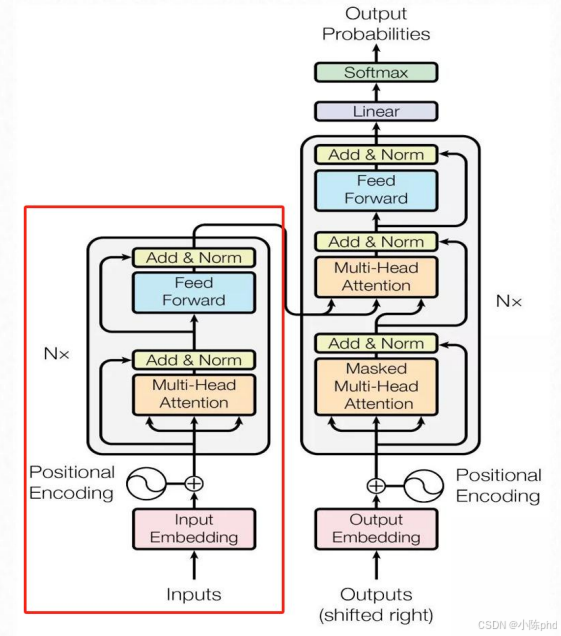
8.1 Encoder的核心作用
Encoder(编码器)是Transformer的"语义提取模块",负责将输入文本(如待翻译的句子)编码为包含全局语义信息的特征向量,为后续的解码器提供输入。
8.2 Encoder的结构设计
Encoder由N个相同的EncoderLayer(编码器层)堆叠而成(原始论文中N=6),每个EncoderLayer包含两个核心子模块:
- 多头注意力(Multi-Head Attention);
- 前馈网络(Feed Forward);
每个子模块后都搭配"Add & Norm"(残差连接+层归一化)。
8.3 核心辅助函数:clone_module_to_modulist
图中clone_module_to_modulist函数用于复制多个相同的模块(如将1个EncoderLayer复制为6个),是构建多层Encoder的基础:
python
import copy
import torch.nn as nn
def clone_module_to_modulist(module, module_num):
"""
:param module: 待复制的模块(如EncoderLayer)
:param module_num: 复制的数量
:return: 包含module_num个相同模块的ModuleList
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(module_num)])8.4 EncoderLayer(编码器层)的实现
EncoderLayer是Encoder的基本单元,包含"多头注意力+前馈网络"的完整流程:
python
class EncoderLayer(nn.Module):
def __init__(self, size, attn, feed_forward, dropout=0.1):
"""
:param size: 特征维度(与d_model一致)
:param attn: 多头注意力模块
:param feed_forward: 前馈网络模块
:param dropout: dropout比例
"""
super().__init__()
self.attn = attn
self.feed_forward = feed_forward
# 复制2个SublayerConnection(分别对应注意力、前馈网络的Add & Norm)
self.sublayer_connection_list = clone_module_to_modulist(
SublayerConnection(size, dropout), 2
)
self.size = size
def forward(self, x, mask):
"""
:param x: 输入特征
:param mask: 掩码(遮挡无效位置,如填充词)
:return: 编码器层的输出
"""
# 第一步:多头注意力 + Add & Norm
x = self.sublayer_connection_list[0](
x, lambda x: self.attn(x, x, x, mask) # 自注意力:Q=K=V=x
)
# 第二步:前馈网络 + Add & Norm
return self.sublayer_connection_list[1](x, self.feed_forward)8.5 Encoder(编码器)的实现
Encoder通过堆叠N个EncoderLayer,实现深层语义编码:
python
class Encoder(nn.Module):
def __init__(self, n, encoder_layer):
"""
:param n: EncoderLayer的堆叠层数
:param encoder_layer: 单个EncoderLayer模块
"""
super().__init__()
# 复制n个EncoderLayer
self.encoder_layer_list = clone_module_to_modulist(encoder_layer, n)
def forward(self, x, src_mask):
"""
:param x: 输入文本的预处理特征(Input Embedding + 位置编码)
:param src_mask: 输入文本的掩码
:return: 编码器的最终输出(全局语义特征)
"""
# 依次经过每个EncoderLayer
for encoder_layer in self.encoder_layer_list:
x = encoder_layer(x, src_mask)
return x8.6 代码执行流程解析
- EncoderLayer的前向传播 :
输入x先经过"多头自注意力+Add & Norm",再经过"前馈网络+Add & Norm",输出提炼后的特征。 - Encoder的前向传播 :
输入特征依次经过N个EncoderLayer,每一层都逐步增强语义表达,最终输出包含全局信息的编码结果。
8.7 Encoder在Transformer中的位置
从左侧架构图可见,Encoder是Transformer的左侧模块:
- 输入:经过Input Embedding + 位置编码的文本特征;
- 输出:全局语义编码向量,送入Decoder(解码器)做后续生成。
Encoder是Transformer的"语义编码器",核心是多层EncoderLayer的堆叠:
- 每个EncoderLayer包含"多头自注意力+前馈网络+Add & Norm",实现语义的逐步提炼;
clone_module_to_modulist辅助函数实现模块的批量复制,是构建深层网络的关键;- 最终输出的全局语义向量,是解码器生成目标文本的基础。
9 Decoder(解码器)的实现与作用
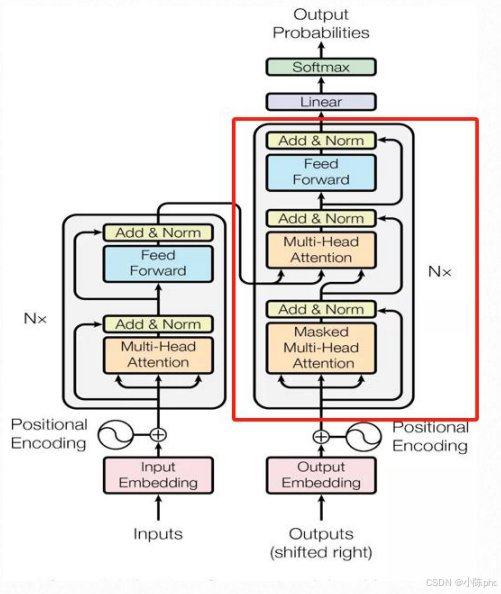
9.1 Decoder的核心作用
Decoder(解码器)是Transformer的"生成模块",负责基于Encoder输出的全局语义特征,逐步生成目标文本(如翻译后的句子、对话回复等)。
9.2 Decoder的结构设计
Decoder由N个相同的DecoderLayer(解码器层)堆叠而成(原始论文中N=6),每个DecoderLayer包含3个核心子模块:
- Masked Multi-Head Attention(掩码多头注意力,防止"偷看未来词");
- Multi-Head Attention(交叉注意力,关注Encoder的语义特征);
- Feed Forward(前馈网络);
每个子模块后都搭配"Add & Norm"(残差连接+层归一化)。
9.3 DecoderLayer(解码器层)的实现
DecoderLayer是Decoder的基本单元,包含"掩码注意力+交叉注意力+前馈网络"的完整流程:
python
import torch.nn as nn
# 需引入前文的SublayerConnection、clone_module_to_modulist
class DecoderLayer(nn.Module):
def __init__(self, d_model, attn, feed_forward, sublayer_num, dropout=0.1):
"""
:param d_model: 特征维度
:param attn: 多头注意力模块
:param feed_forward: 前馈网络模块
:param sublayer_num: 子模块数量(通常为3)
:param dropout: dropout比例
"""
super().__init__()
self.self_attn = attn # 掩码自注意力
self.feed_forward = feed_forward
# 复制sublayer_num个SublayerConnection(对应3个子模块)
self.sublayer_connection_list = clone_module_to_modulist(
SublayerConnection(d_model, dropout), sublayer_num
)
self.d_model = d_model
def forward(self, x, lr_memory, src_mask, trg_mask):
"""
:param x: 解码器的输入(已生成的部分文本特征)
:param lr_memory: Encoder的输出(全局语义特征)
:param src_mask: 输入文本的掩码
:param trg_mask: 目标文本的掩码(遮挡未来词)
:return: 解码器层的输出
"""
# 1. 掩码多头自注意力 + Add & Norm(防止偷看未来词)
x = self.sublayer_connection_list[0](
x, lambda x: self.self_attn(x, x, x, trg_mask)
)
# 2. 交叉注意力 + Add & Norm(关注Encoder的语义特征)
x = self.sublayer_connection_list[1](
x, lambda x: self.self_attn(x, lr_memory, lr_memory, src_mask)
)
# 3. 前馈网络 + Add & Norm
return self.sublayer_connection_list[2](x, self.feed_forward)9.4 Decoder(解码器)的实现
Decoder通过堆叠N个DecoderLayer,实现目标文本的逐步生成:
python
class Decoder(nn.Module):
def __init__(self, n_layers, decoder_layer):
"""
:param n_layers: DecoderLayer的堆叠层数
:param decoder_layer: 单个DecoderLayer模块
"""
super().__init__()
# 复制n_layers个DecoderLayer
self.decoder_layer_list = clone_module_to_modulist(decoder_layer, n_layers)
def forward(self, x, memory, src_mask, trg_mask):
"""
:param x: 目标文本的预处理特征(Output Embedding + 位置编码)
:param memory: Encoder的输出(全局语义特征)
:param src_mask: 输入文本的掩码
:param trg_mask: 目标文本的掩码
:return: 解码器的最终输出
"""
# 依次经过每个DecoderLayer
for decoder_layer in self.decoder_layer_list:
x = decoder_layer(x, memory, src_mask, trg_mask)
return x9.5 代码执行流程解析
- 掩码自注意力 :
对解码器输入x做自注意力,但通过trg_mask遮挡"未来还未生成的词",保证生成顺序的合理性。 - 交叉注意力 :
以解码器当前特征为Q,Encoder输出的memory为K/V,让解码器关注输入文本的全局语义。 - 前馈网络 :
对交叉注意力的输出做非线性变换,提炼生成特征。 - Decoder的前向传播 :
输入特征依次经过N个DecoderLayer,逐步生成目标文本的特征表示。
9.6 Decoder在Transformer中的位置
从左侧架构图可见,Decoder是Transformer的右侧模块:
- 输入:经过Output Embedding + 位置编码的目标文本特征(已生成部分)、Encoder输出的
memory; - 输出:目标文本的特征表示,送入后续的Linear+Softmax生成最终的单词概率。
Decoder是Transformer的"文本生成器",核心是多层DecoderLayer的堆叠:
- 每个DecoderLayer通过"掩码自注意力(保证顺序)+交叉注意力(关联输入语义)+前馈网络(提炼特征)",实现目标文本的逐步生成;
- 依赖Encoder输出的
memory,保证生成内容与输入文本的语义一致性; - 最终输出的特征经过Linear+Softmax,得到每个位置的单词概率,完成文本生成。
10 WordProbGenerator(词概率生成器)的实现与作用
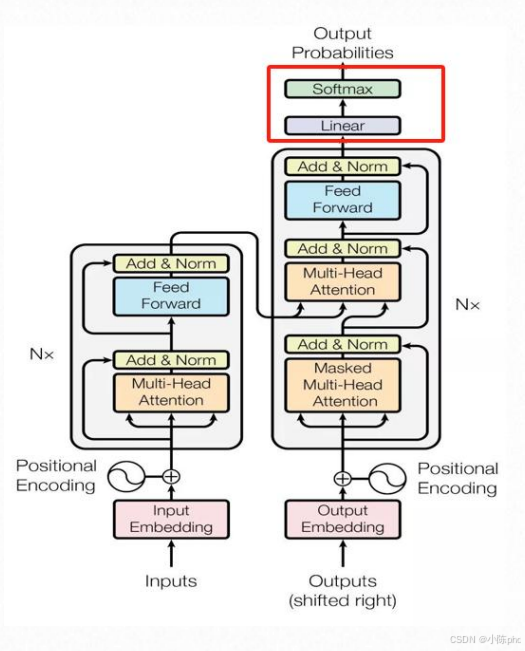
10.1 WordProbGenerator的核心作用
WordProbGenerator是Transformer的最终输出模块 ,负责将Decoder输出的特征向量转换为词汇表中每个单词的概率,完成文本生成的最后一步。
10.2 WordProbGenerator的结构设计
该模块由线性层(Linear)+ Softmax函数组成:
- 线性层:将Decoder输出的
d_model维特征映射到"词汇表大小"的维度; - Softmax函数:将映射后的结果转换为"0~1"的概率分布(每个位置对应一个单词的概率)。
10.3 WordProbGenerator的代码实现(PyTorch)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class WordProbGenerator(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
"""
:param d_model: Decoder输出的特征维度
:param vocab_size: 词汇表的总单词数
"""
super().__init__()
# 线性层:将d_model维特征映射到vocab_size维
self.linear = nn.Linear(d_model, vocab_size)
def forward(self, x):
"""
:param x: Decoder的输出特征,shape: [batch_size, seq_len, d_model]
:return: 每个位置的单词对数概率,shape: [batch_size, seq_len, vocab_size]
"""
# 1. 线性层映射:d_model → vocab_size
linear_out = self.linear(x)
# 2. Softmax转换为概率分布(用log_softmax便于后续计算损失)
return F.log_softmax(linear_out, dim=-1)10.4 代码执行流程解析
- 线性层映射 :
接收Decoder输出的[batch_size, seq_len, d_model]特征,通过nn.Linear(d_model, vocab_size)将每个位置的特征映射为"词汇表大小"的向量(每个元素对应一个单词的得分)。 - Softmax概率转换 :
对映射后的向量做log_softmax(在dim=-1维度,即词汇表维度),将得分转换为"对数概率"(既保证概率总和为1,又便于计算交叉熵损失)。
10.5 WordProbGenerator在Transformer中的位置
从架构图可见,WordProbGenerator是Transformer的最顶层模块:
- 输入:Decoder输出的特征向量;
- 输出:每个位置的单词概率分布,用于选择概率最高的单词作为生成结果。
WordProbGenerator是Transformer的"输出终端",核心是线性层+Softmax的组合:
- 线性层负责"特征→词汇表维度"的映射;
- Softmax负责将得分转换为概率分布;
- 最终输出的概率分布,是Transformer生成文本的直接依据(通常选择概率最高的单词作为当前位置的输出)。
11 Transformer完整模型的实现与工作流程
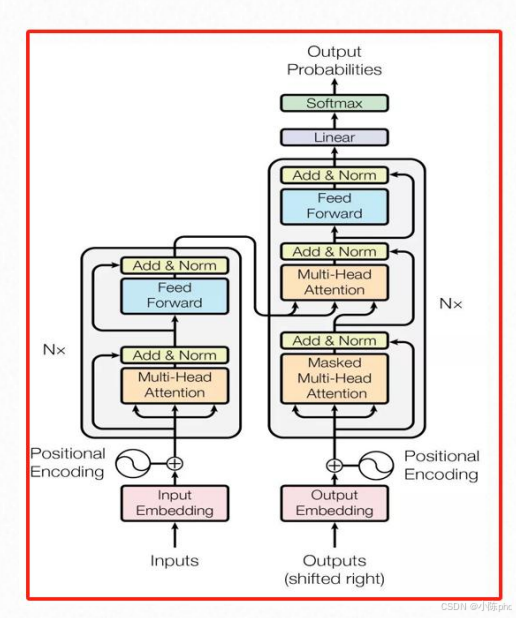
11.1 Transformer完整模型的核心作用
Transformer完整模型是端到端的序列转换模型(如机器翻译、文本生成),通过"编码器+解码器+输出层"的组合,实现从输入文本到目标文本的转换。
11.2 Transformer完整模型的结构设计
完整模型由3个核心部分组成:
- Encoder(编码器):处理输入文本,输出全局语义特征;
- Decoder(解码器):基于编码器特征和已生成的目标文本,生成新的文本特征;
- 输出线性层:将解码器输出映射为词汇表概率分布。
11.3 Transformer完整模型的代码实现(PyTorch)
python
import torch.nn as nn
# 需引入前文的Encoder、Decoder
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
"""
:param src_vocab: 输入文本的词汇表大小
:param trg_vocab: 目标文本的词汇表大小
:param d_model: 模型特征维度
:param N: 编码器/解码器的堆叠层数
:param heads: 多头注意力的头数
:param dropout: dropout比例
"""
super().__init__()
# 初始化编码器
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
# 初始化解码器
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
# 输出线性层:将解码器特征映射到目标词汇表维度
self.out = nn.Linear(d_model, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
"""
:param src: 输入文本的索引序列,shape: [batch_size, src_seq_len]
:param trg: 目标文本的索引序列(已生成部分),shape: [batch_size, trg_seq_len]
:param src_mask: 输入文本的掩码
:param trg_mask: 目标文本的掩码
:return: 目标文本的概率分布,shape: [batch_size, trg_seq_len, trg_vocab]
"""
# 1. 编码器处理输入文本,得到全局语义特征
e_outputs = self.encoder(src, src_mask)
# 2. 解码器基于编码器特征和目标文本,生成新特征
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
# 3. 线性层映射为词汇表概率分布
output = self.out(d_output)
return output11.4 完整模型的工作流程解析
以"机器翻译"任务为例,流程如下:
- 输入预处理 :
输入文本(如英文句子)转换为索引序列src,目标文本(如中文句子)转换为索引序列trg,并生成对应的掩码src_mask(遮挡填充词)、trg_mask(遮挡未来词)。 - 编码器编码 :
src经过Input Embedding + 位置编码后,送入Encoder得到全局语义特征e_outputs。 - 解码器生成 :
trg经过Output Embedding + 位置编码后,结合e_outputs送入Decoder,生成当前位置的文本特征d_output。 - 输出概率分布 :
d_output经过线性层out,转换为目标词汇表的概率分布,选择概率最高的单词作为当前位置的输出。 - 迭代生成 :
将新生成的单词加入trg,重复步骤2-4,直到生成结束符(如<EOS>)。
11.5 Transformer完整模型的意义
Transformer是现代大语言模型的基础架构(如BERT、GPT均基于Transformer的子结构),其核心优势是:
- 并行计算:相比RNN的串行计算,注意力机制支持并行处理文本,训练/推理效率更高;
- 长距离依赖:自注意力能直接捕捉文本中长距离的单词关联,更适合处理长文本;
- 可扩展性:通过堆叠层数、增加头数等方式,可灵活扩展模型能力。
Transformer完整模型是端到端的序列转换框架,核心是"编码器-解码器"结构:
- 编码器负责提取输入文本的全局语义;
- 解码器负责基于语义特征生成目标文本;
- 输出层将特征映射为词汇表概率,完成文本生成;
它的出现彻底改变了自然语言处理的技术路线,是当前大模型的核心基础。