摘要
本周深入研究了多模态文档解析的技术范式与轻量化模型创新。系统梳理了文档解析的三种主流架构:模块化的流水线式(Pipeline)、两阶段式(Layout+VLM)以及端到端式(VLM finetune),并重点分析了轻量级模型MinerU2.5的核心设计。该模型通过"全局布局分析、局部内容识别"的两阶段策略,结合基于Qwen2VL的统一视觉语言模型架构,在参数量仅1.2B的情况下,实现了识别精度与计算效率的有效平衡。
Abstract
This week delved into the technical paradigms of multimodal document parsing and innovations in lightweight models. The three mainstream architectures for document parsing were systematically reviewed: the modular pipeline approach, the two-stage approach (Layout+VLM), and the end-to-end approach (VLM finetune). Particular focus was given to the core design of the lightweight model MinerU2.5. By employing a two-stage strategy of "global layout analysis followed by local content recognition" and leveraging a unified vision-language model architecture based on Qwen2VL, it effectively balances recognition accuracy with computational efficiency despite having only 1.2B parameters.
1、多模态OCR
1.1 文档解析的多模态大模型多种模式
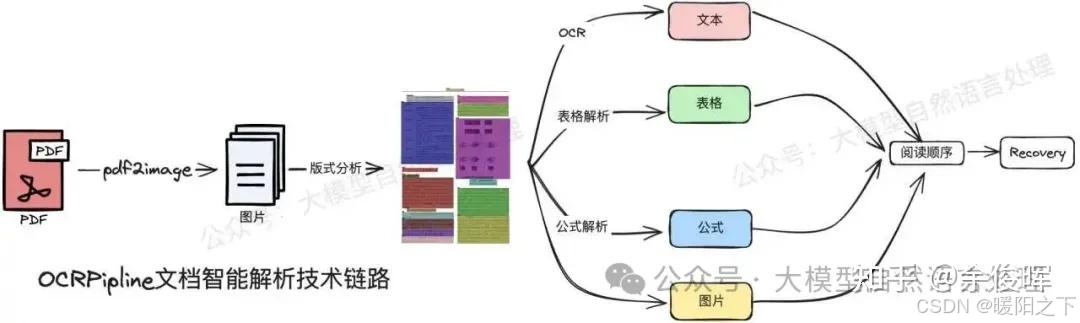
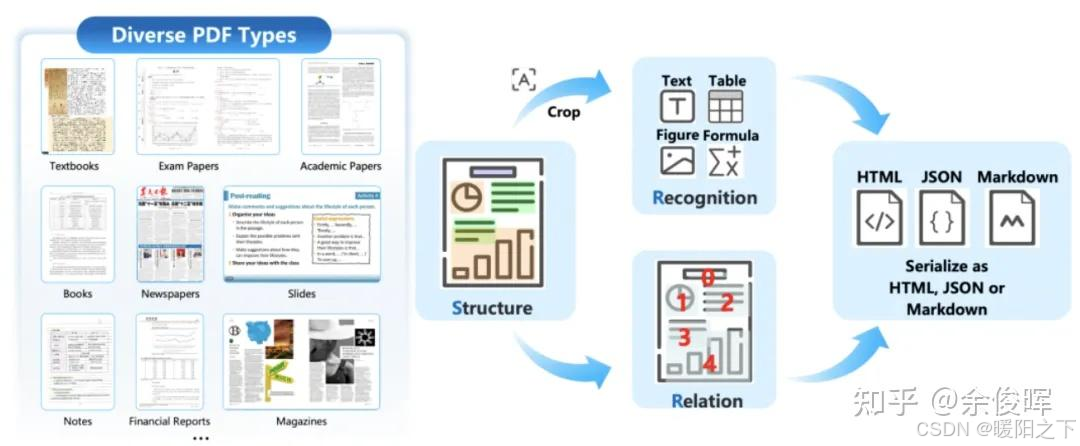
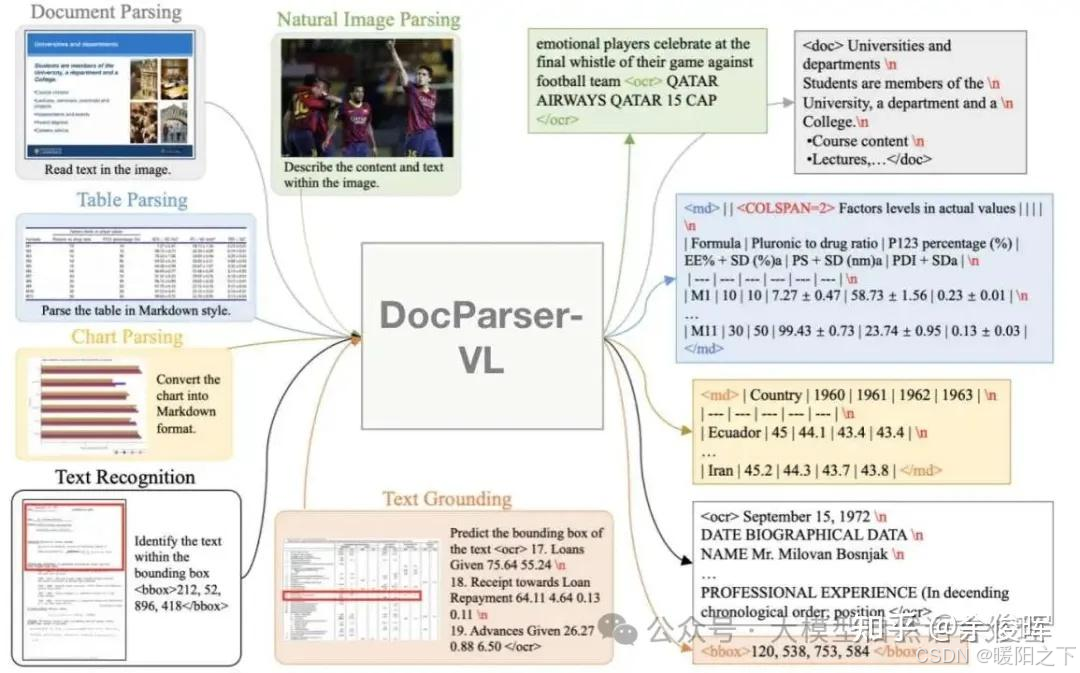
本周学习了解了文档解析的多模态大模型。pipline式、两阶段式和端到端,如下图所示。
pipline:
layout+VLM:
VLM finetune:
1.2 MinerU2.5
MinerU2.5 是专用于文档解析的轻量级(1.2B)视觉语言模型,其核心特点是通过两阶段解析策略平衡识别精度与计算效率:
阶段 I:全局布局(Layout)分析
阶段 II:局部内容识别
相比于上期的PaddleOCR-VL的两阶段,MinerU2.5在两阶段使用的模型都是同一个VLM,通过不同prompt引导目标检测任务、OCR任务。
模型结构上直接使用Qwen2VL的结构。
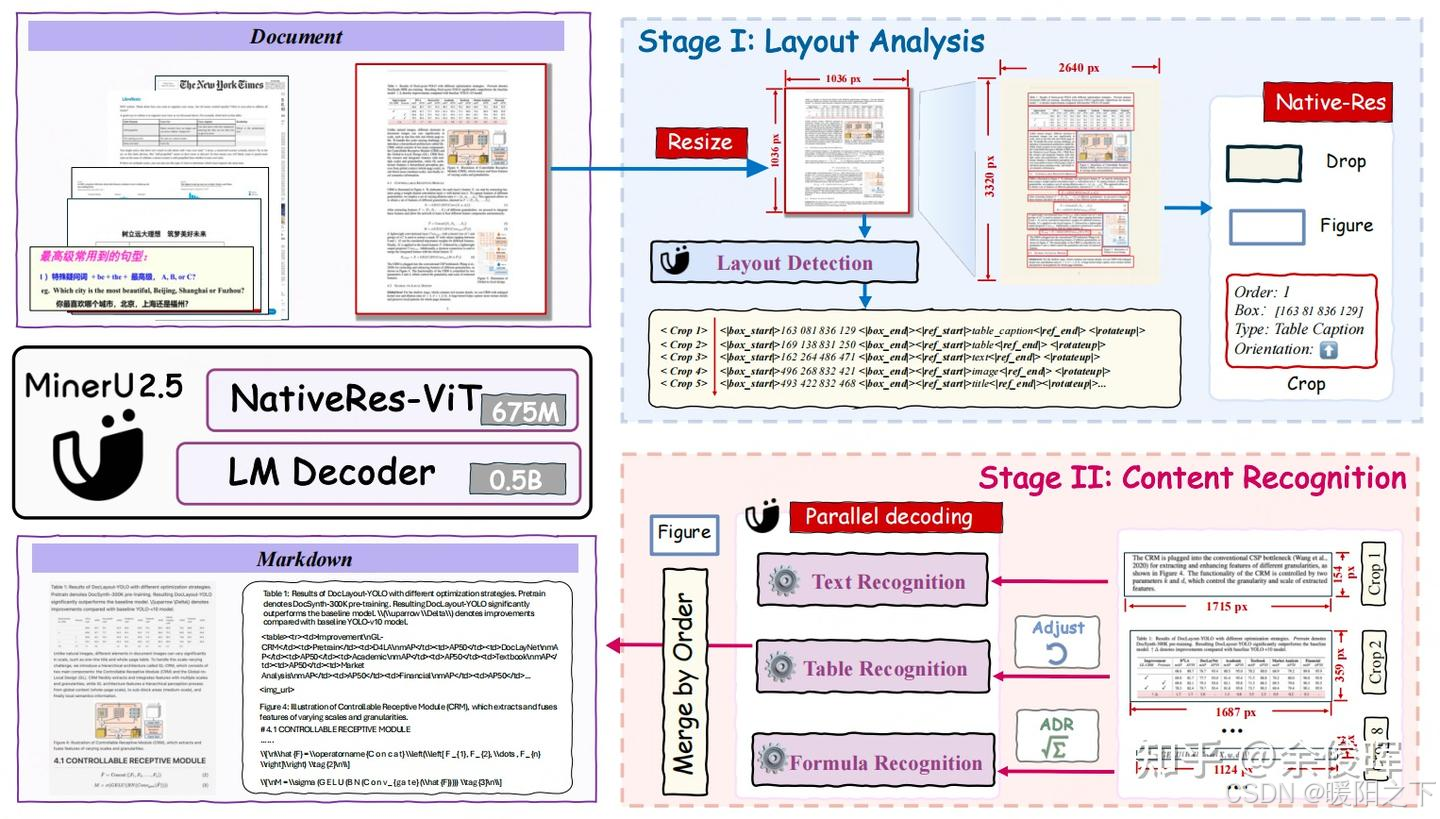
MinerU2.5 的框架,在第一阶段,MinerU2.5 对下采样后的页面执行快速的全局布局分析。在第二阶段,MinerU2.5 利用布局分析结果从原始高分辨率文档中裁剪出关键区域,并在这些原始分辨率的局部区域内进行细粒度的内容识别(例如,文本、表格和公式识别)。
语言解码器:LLM(Qwen2-Instruct-0.5B),M-RoPE 替换了原始的 1D-RoPE
视觉编码器:使用Qwen2-VL视觉编码器(NaViT-675M)进行初始化
patch merge:为了在效率和性能之间取得平衡,该架构在相邻的 2 × 2 视觉 token 上使用 pixel-unshuffe对聚合后的视觉 token 进行预处理,然后再将其输入大型语言模型。
总结
本周通过对比分析三种文档解析范式和剖析一个具体轻量模型,构建了对多模态OCR技术路线的清晰认知。在技术范式层面,理解了从早期模块化流水线(Pipeline)到引入大模型的两阶段(Layout+VLM),再到追求统一建模的端到端(VLM finetune)的演进逻辑,各自在灵活性、精度与复杂性上存在权衡。