如何用本地模型打造一个懂你业务的 AI 助手?本文手把手教你从零搭建一个生产级 RAG 对话系统



前言
最近 AI 大模型火爆出圈,ChatGPT、Claude 等产品让对话式 AI 成为可能。但企业落地时面临一个核心痛点:通用大模型不懂你的业务数据。
比如你问:"我们公司的请假流程是怎样的?" ------ ChatGPT 只能给你通用回答,而无法基于你公司的员工手册来回答。
RAG(检索增强生成)技术正是为此而生。它让 AI 能够"外挂"知识库,先检索相关文档,再基于检索结果生成答案。
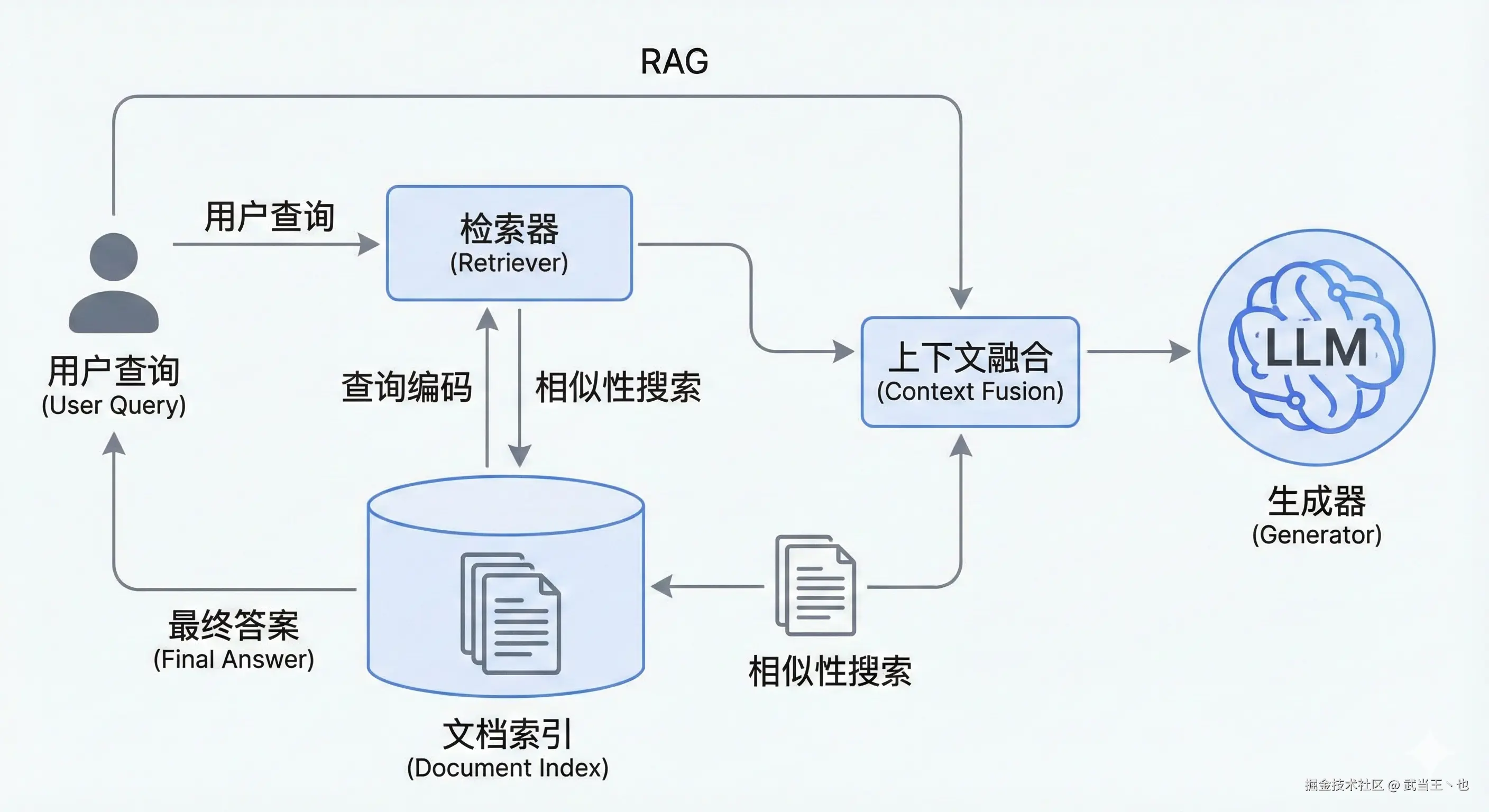
本文将详细介绍如何从零构建一个生产级的 RAG 对话系统 Ace AI,涵盖:
- 使用 Ollama 本地部署 AI 模型
- 使用 Python + FastAPI 编写后端服务
- 使用 ChromaDB 构建向量知识库
- 前端对接实现 AI 对话窗口
- Docker 容器化部署
在线体验地址:wangcaiyuan.com/chat
GitHub 源码:github.com/ace0109/ace... ⭐
一、RAG 技术原理
1.1 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的技术架构:
sql
┌─────────────────────────────────────────────────────────────────┐
│ RAG 工作流程 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 用户问题 │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 向量检索 │ ──────► 从知识库中检索最相关的文档片段 │
│ └─────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 提示词构造 │ ──────► 将检索结果融入 System Prompt │
│ └─────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ LLM 生成 │ ──────► 基于上下文生成答案 │
│ └─────────────┘ │
│ │ │
│ ▼ │
│ 流式返回给用户 │
│ │
└─────────────────────────────────────────────────────────────────┘1.2 核心组件
| 组件 | 作用 | 技术选型 |
|---|---|---|
| LLM | 对话生成 | Ollama (qwen3-coder) |
| Embedding 模型 | 文本向量化 | Ollama (nomic-embed-text) |
| 向量数据库 | 存储和检索文档 | ChromaDB |
| 文本分割器 | 文档切分 | LangChain RecursiveCharacterTextSplitter |
| 后端框架 | API 服务 | FastAPI |
二、项目结构
bash
ace-ai/
├── app/
│ ├── main.py # FastAPI 应用入口
│ ├── services/
│ │ └── rag.py # RAG 服务实现
│ ├── api/routes/
│ │ ├── chat.py # 聊天接口
│ │ └── documents.py # 文档上传
│ └── core/
│ └── auth.py # API Key 认证
├── data/ # 数据存储
├── chroma_db/ # 向量数据库
└── Dockerfile三、Ollama 部署 AI 模型
3.1 安装 Ollama
Ollama 是一个本地运行大模型的工具,支持 macOS、Linux 和 Windows。
macOS / Linux:
bash
curl -fsSL https://ollama.com/install.sh | shWindows: 下载安装包 ollama.com
3.2 拉取所需模型
Ace AI 需要两类模型:
bash
# 1. Chat 模型 - 用于对话生成
ollama pull qwen3-coder:480b-cloud
# 2. Embedding 模型 - 用于文本向量化
ollama pull nomic-embed-text3.3 验证 Ollama 服务
bash
# 检查 Ollama 是否正常运行
curl http://localhost:11434/api/tags
# 测试 Chat 模型
curl http://localhost:11434/api/generate -d '{
"model": "qwen3-coder:480b-cloud",
"prompt": "Hello, how are you?"
}'四、后端服务实现
4.1 RAG 服务核心实现
RAG 服务是整个系统的核心,负责文档向量化、存储和检索。
python
# app/services/rag.py
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
import threading
class RAGService:
def __init__(self):
# 线程锁,保护向量存储操作
self._lock = threading.RLock()
# 初始化 Embedding 模型
self.embeddings = OllamaEmbeddings(
model="nomic-embed-text",
base_url="http://localhost:11434",
)
# 初始化向量数据库
self.vector_store = Chroma(
persist_directory="./chroma_db",
embedding_function=self.embeddings
)
def add_documents(self, texts, metadatas=None, ids=None):
"""将文档存入向量数据库"""
documents = [
Document(page_content=text, metadata=metadatas[i] if metadatas else {})
for i, text in enumerate(texts)
]
with self._lock:
self.vector_store.add_documents(documents, ids=ids)
def query(self, query_text: str, k: int = 3):
"""根据问题检索最相关的 k 个文档片段"""
with self._lock:
return self.vector_store.similarity_search(query_text, k=k)4.2 文档上传处理
当用户上传文档时,需要经过解析、分块、向量化三个步骤:
python
# app/api/routes/documents.py
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 文本分割器配置
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=200, # 块之间重叠字符数
separators=["\n\n", "\n", "。", "!", "?", ".", "!", "?", " ", ""]
)
@router.post("/upload")
async def upload_document(file: UploadFile):
# 1. 解析文件内容 (支持 PDF/TXT/MD)
text = parse_file_content(await file.read(), file.filename)
# 2. 文本分块
chunks = text_splitter.split_text(text)
# 3. 生成唯一 ID 和元数据
base_id = str(uuid.uuid4())
chunk_ids = [f"{base_id}_chunk_{i}" for i in range(len(chunks))]
metadatas = [
{
"source": file.filename,
"upload_time": datetime.now(timezone.utc).isoformat(),
"chunk_index": i,
}
for i in range(len(chunks))
]
# 4. 存入向量数据库
rag_service.add_documents(chunks, metadatas=metadatas, ids=chunk_ids)
return {"message": f"Document uploaded successfully, {len(chunks)} chunks created"}4.3 聊天接口实现
聊天接口支持流式响应(SSE),让用户实时看到 AI 的回答:
python
# app/api/routes/chat.py
@router.post("")
async def chat_with_ollama(messageBody: MessageBody):
# 1. 处理会话 (创建新会话或使用已有会话)
session_id = messageBody.session_id or create_new_session()
# 2. 保存用户消息
chat_store.add_message(session_id, "user", messageBody.message)
# 3. 获取历史消息 (最近 10 条)
history = chat_store.get_messages(session_id)[-10:]
# 4. RAG 检索相关文档
try:
relevant_docs = rag_service.query(messageBody.message, k=3)
context_text = "\n\n".join([doc.page_content for doc in relevant_docs])
except Exception as e:
context_text = "" # 降级:不使用 RAG 上下文
# 5. 构造提示词
system_prompt = "用中文回复。"
if context_text:
system_prompt += f"""
请基于以下【已知信息】回答用户的问题。如果没有已知信息,才按照你的知识回答。
【已知信息】:
{context_text}
"""
# 6. 流式生成响应
async def stream_response():
yield f"data: {{'session_id': '{session_id}'}}\n\n"
async for chunk in llm.astream(messages):
yield f"data: {json.dumps(chunk)}\n\n"
return StreamingResponse(stream_response(), media_type="text/event-stream")4.4 API Key 认证
为了保护 API 安全,实现了基于 API Key 的认证机制:
python
# app/core/auth.py
import hashlib
def verify_api_key(raw_key: str) -> Optional[dict]:
"""验证 API Key"""
key_hash = hashlib.sha256(raw_key.encode()).hexdigest()
cursor.execute(
"SELECT id, role, label FROM api_keys WHERE key_hash = ?",
(key_hash,)
)
return cursor.fetchone()
# API 路由认证依赖
async def require_api_key(request: Request):
api_key = request.headers.get("X-API-Key")
if not api_key:
raise HTTPException(status_code=401, detail="API Key required")
key_record = verify_api_key(api_key)
if not key_record:
raise HTTPException(status_code=403, detail="Invalid API Key")
request.state.api_key_record = key_record
return key_record五、前端对接实现
前端通过 SSE(Server-Sent Events)接收流式响应:
javascript
// 前端调用示例
async function sendMessage(message, sessionId) {
const response = await fetch('http://localhost:8888/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-API-Key': 'your-api-key-here'
},
body: JSON.stringify({ message, session_id: sessionId })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
// 第一个数据包包含 session_id
if (data.session_id) {
sessionId = data.session_id;
continue;
}
// 后续数据包是 AI 的回复内容
if (data.content) {
appendToChat(data.content); // 追加到聊天窗口
}
}
}
}
}六、Docker 部署
6.1 Dockerfile
dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1
WORKDIR /app
# 安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 拷贝代码
COPY app app
# 预创建运行时目录
RUN mkdir -p /app/data /app/chroma_db /app/logs
EXPOSE 8888
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8888"]6.2 构建和运行
bash
# 1. 构建镜像
docker build -t ace-ai:latest .
# 2. 运行容器
docker run -d \
--name ace-ai \
--network host \
-v $(pwd)/data:/app/data \
-v $(pwd)/chroma_db:/app/chroma_db \
-v $(pwd)/logs:/app/logs \
-e TZ=Asia/Shanghai \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--restart unless-stopped \
ace-ai:latest
# 3. 获取超级管理员 API Key
cat data/initial_superadmin_key.txt
# 4. 访问 API 文档
open http://localhost:8888/docs七、效果展示
7.1 上传文档构建知识库
bash
curl -X POST http://localhost:8888/api/documents/upload \
-H "X-API-Key: your-api-key" \
-F "file=@employee_handbook.pdf"7.2 进行对话
bash
curl -X POST http://localhost:8888/api/chat \
-H "Content-Type: application/json" \
-H "X-API-Key: your-api-key" \
-d '{"message": "年假怎么申请?"}'7.3 在线体验
访问 wangcaiyuan.com/chat 即可体验完整的 RAG 对话系统。
八、技术栈
makefile
后端: Python 3.11 + FastAPI
向量库: ChromaDB
LLM: Ollama (qwen3-coder:480b-cloud)
Embedding: Ollama (nomic-embed-text)
容器: Docker主要特性
- SSE 流式响应:实时返回 AI 回复
- API Key 认证:保护接口安全
- 文档解析:支持 PDF、TXT、Markdown
- Docker 部署:一键启动
九、总结
本文介绍了如何快速搭建一个基于 RAG 的 AI 对话系统,核心就是:
- Ollama 本地运行 LLM
- ChromaDB 存储向量知识库
- FastAPI 提供 API 接口
- 前端 通过 SSE 实现流式对话
GitHub 地址 :github.com/ace0109/ace... ⭐
在线体验 :wangcaiyuan.com/chat
有问题欢迎在评论区讨论!
参考链接
本文首发于掘金,转载请注明出处。