目录
引言
之前小马的文章《如何5分钟快速搭建智能问答系统》介绍过基于RAG实现的问答系统。然而,基于RAG的原理实现就有很多种,比如当语料有QA问答对和长文本时如何实现多路召回,当召回的语料长度过大时如何用模型进行重排再给到回答总结大模型等等,这些都是实际场景中需要精雕细琢的技术细节。今天我们就来简单感受下模型重排。

RAG的核心工作流程
检索(Retrieval)
AI系统首先根据用户提出的问题,从其连接的数据源(企业内部数据库、文档库或外部知识库)中查找相关的文档或信息片段。这个过程类似于人类使用搜索引擎寻找答案。
生成答案(Grounded Generation)
在获取相关资料后,AI系统会基于这些信息生成最终的回答,并且通常会注明参考来源,从而提升信息的可信度。
传统检索方式的局限性------向量搜索的优缺点
工作原理
- 向量检索主要依赖"语义理解",而非简单的关键词匹配
- 将用户问题和所有待检索文档转换为数学模型中的"向量"表示
- 通过计算向量间的余弦相似度或欧几里得距离来评估相关性
面临挑战
- 信息压缩损失:固定长度的向量可能导致重要细节丢失
- 单阶段局限:初步检索可能包含不相关或宽泛内容
- 长上下文窗口问题:
- LLM的处理能力有限,过多文档会降低性能和准确率
- 信息稀释效应:关键内容被淹没在大量文本中
- "中间文档难题":位于文档中间的重要信息容易被忽略
解决方案:重排序(Reranking)机制的引入
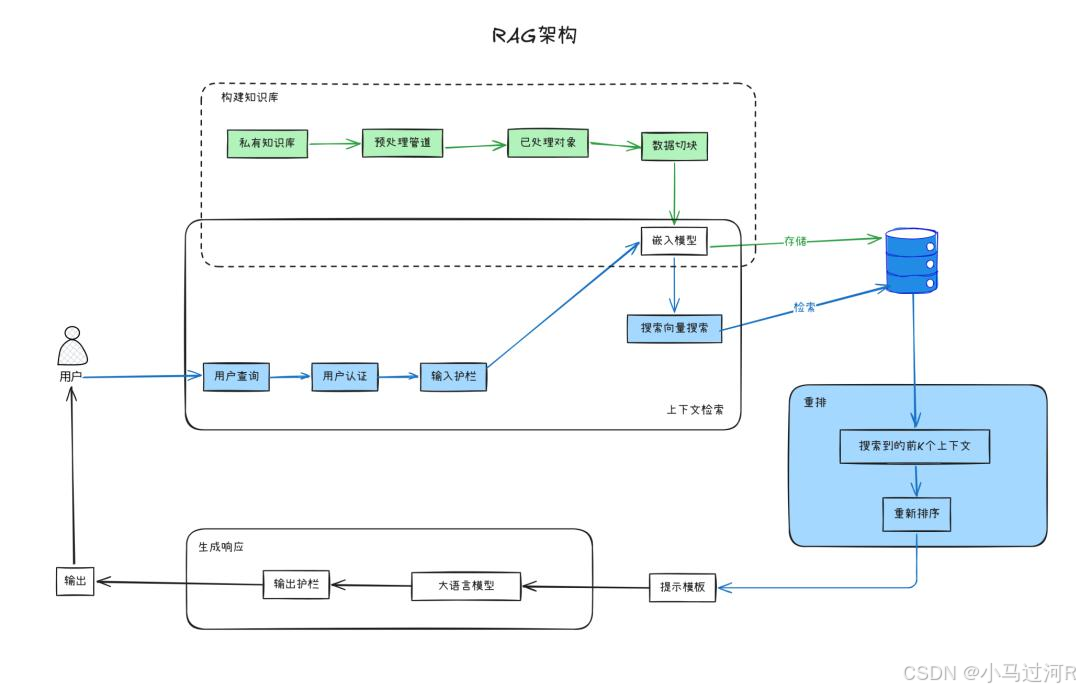
工作流程
- 初步检索:使用快速检索技术获取相关文档
- 二次排序:对初步结果进行重新评估和排序,提升最相关文档的优先级
- 选择性输入:将重排后的最相关文档输入LLM,减少无关信息干扰
实践示例:两阶段检索模式
第一阶段:向量搜索
- 使用ChromaDB向量数据库进行快速检索
- 基于余弦相似度获取初步排名
python
#在向量数据库中通过余弦相似度做一阶段检索:
# 用户查询
query_text = "大语言模型的工作原理和技术特点"
query_embedding = get_embedding(query_text)
print(f"用户问题:{query_text}")
# 从 ChromaDB 搜索最相似的 5 条结果
results = collection.query(
query_embeddings=[query_embedding],
n_results=5,
include=["documents", "distances"]
)
retrieved_docs = results["documents"][0] # 获取返回的文档列表
distances = results["distances"][0] # 获取相似度距离
print("ChromaDB 搜索结果(未重排):")
for i, (doc, distance) in enumerate(zip(retrieved_docs, distances), 1):
similarity = 1 - distance # 将距离转换为相似度
print(f"{i}. 相似度: {similarity:.4f} - {doc}")测试查询:"大语言模型的工作原理和技术特点"
结果示例:
ChromaDB 搜索结果(未重排):
1.相似度: 0.7058 - 大语言模型的涌现能力使其在没有专门训练的情况下也能完成复杂任务,如推理和编程
2.相似度: 0.7017 - 大语言模型的参数规模从数十亿到数万亿不等,参数量越大通常性能越强
3.相似度: 0.6908 - 大语言模型通过自监督学习从海量文本中学习语言规律和知识,形成强大的语义理解能力
4.相似度: 0.6731 - 大语言模型(LLM)是基于Transformer架构的深度学习模型,能够理解和生成人类语言
5.相似度: 0.5491 - ChatGPT是OpenAI开发的大语言模型,通过强化学习和人类反馈训练,具有优秀的对话能力
第二阶段:重排序
- 使用Cohere的Reranker模型进行精细排序
- 基于语义匹配度重新调整文档优先级
python
# 使用 Cohere Reranker 进行重排序
response = co.rerank(query=query_text, documents=retrieved_docs, model="rerank-v3.5")
reranked_results = []
reranked_scores = []
for item in response.results:
original_doc = retrieved_docs[item.index] # 使用索引获取原始文档
reranked_results.append(original_doc)
reranked_scores.append(item.relevance_score)
print("\n🎯 经过 Reranker 重新排序的最终结果:")
for i, (doc, score) in enumerate(zip(reranked_results, reranked_scores), 1):
print(f"{i}. 相似度: {score:.4f} - {doc}")测试查询:"大语言模型的工作原理和技术特点"
经过 Reranker 重新排序的最终结果:
1.相似度: 0.7699 - 大语言模型(LLM)是基于Transformer架构的深度学习模型,能够理解和生成人类语言
2.相似度:0.6999 - 大语言模型通过自监督学习从海量文本中学习语言规律和知识,形成强大的语义理解能力
3.相似度: 0.5974 - 大语言模型的涌现能力使其在没有专门训练的情况下也能完成复杂任务,如推理和编程
4.相似度: 0.4884 - 大语言模型的参数规模从数十亿到数万亿不等,参数量越大通常性能越强
5.相似度: 0.4183 - ChatGPT是OpenAI开发的大语言模型,通过强化学习和人类反馈训练,具有优秀的对话能力
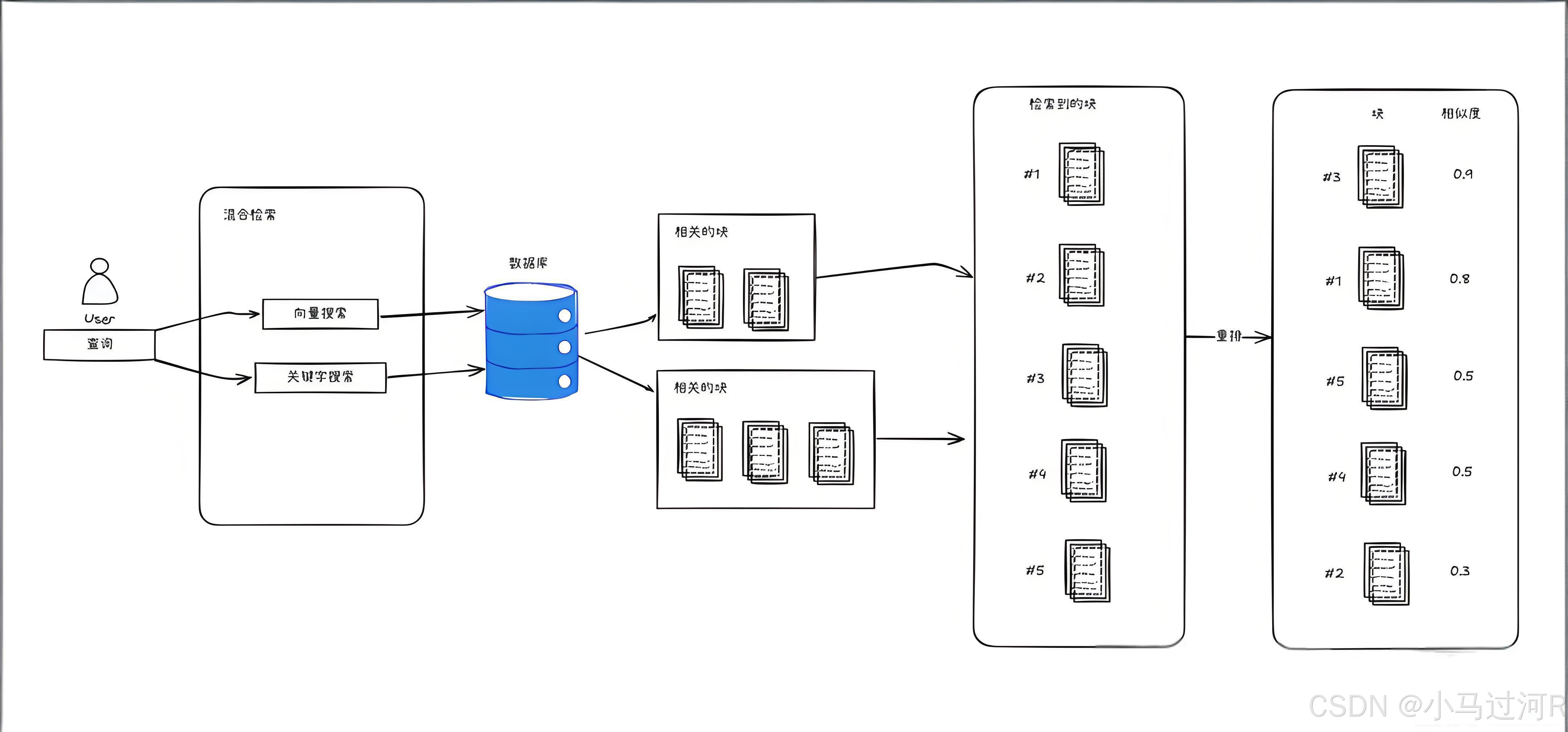
重排序在高精度领域的重要性
适用场景
- 专业性要求高:法律、金融、医疗等领域需要高度可靠的参考资料
- 混合检索优化:结合多种检索技术时的结果归一化和优先级调整
- 减少AI幻觉风险:避免AI因检索不准确而生成错误信息
核心价值
- 精准度提升:确保最相关的内容位于搜索结果前列
- 减少无关干扰:优化进入LLM的文档数量和质量
- 资源优化:在有限的计算和提示空间内最大化信息价值
总结
重排序通过对初步检索结果进行语义层面的二次评估和排序,成为提升检索质量和最终答案可靠性的关键技术。它弥补了快速检索的准确性局限,特别是在高精度、专业化的应用场景中表现突出,尽管带来了更高的计算成本,但其对回答质量的改善使其成为优化RAG系统的重要工具。