T-RAG:从LLM实战中汲取的经验
马苏马利·法特希基亚(Masoomali Fatehkia)、季·金·卢卡斯(Ji Kim Lucas)、桑杰·乔瓦拉(Sanjay Chawla)
卡塔尔计算研究所 哈马德·本·哈利法大学 多哈
电子邮箱:{mfatehkia, jlucas, schawla}@hbku.edu.qa(@hbku.edu.qa)
摘要
大型语言模型(LLM)展现出卓越的语言能力,推动人们尝试将其整合到多个领域的应用中。一个重要的应用场景是基于企业私有文档的问答系统,该场景的核心考量包括:数据安全性(要求应用可本地部署)、有限的计算资源,以及对系统准确响应查询的可靠性需求。检索增强生成(RAG)已成为构建基于LLM应用的主流框架。尽管搭建基础RAG系统相对简单,但要使其具备稳健性和可靠性,需要大量定制化工作以及对应用领域的深入了解。本文分享了我们在构建和部署基于LLM的组织私有文档问答应用过程中的经验。该应用结合了RAG技术与微调后的开源LLM,同时提出了一种名为Tree-RAG(T-RAG)的系统------它采用树结构表示组织内部的实体层级关系,在响应用户关于组织层级内实体的查询时,生成文本描述以增强上下文信息。包括"大海捞针测试"在内的评估结果表明,这种组合方案的性能优于单纯的RAG或微调实现。最后,我们总结了在构建实际应用场景下LLM系统的关键经验教训。
1 引言
大型语言模型(LLM)是自然语言处理(NLP)领域的最新进展,在语言处理方面展现出广泛的能力Zhao et al.(2023)。自OpenAI推出的ChatGPT向公众开放测试并迅速走红后¹,LLM受到了广泛关注。这推动了LLM在各类应用中的探索,从创意写作Gómez-Rodríguez and Williams(2023)、编程Liventsev et al.(2023),到对事实准确性要求更高的法律Louis et al.(2023)和医疗He et al.(2023)领域。
LLM的一个重要应用方向是基于组织专有文档(如治理/政策手册)的问答。这类文档是日常运营和决策的常用参考依据,因此用户经常需要查阅文档或咨询组织内专家以获取相关信息。因此,构建一个能够基于组织文档响应多样化用户查询的应用,有望显著提升工作效率。
在这类场景中部署LLM应用需要考虑多个因素:首先是数据安全风险------由于文档的机密性,无法通过API使用专有LLM模型(避免数据泄露风险)²,因此必须采用可本地部署的开源模型;其次是计算资源有限,且基于可用文档生成的训练数据集规模通常较小;最后,系统必须能够可靠、准确地响应用户查询。因此,在这类场景中部署稳健的LLM应用并非易事,需要做出诸多设计决策并进行定制化开发。
应用场景
本文的应用场景是基于某组织治理手册的问答系统。该类文档的核心特征包括:(1)描述组织的治理原则、各治理机构的职责;(2)详细说明组织下属所有实体的完整层级结构及其分类。基于该文档的LLM问答应用需要能够回答各类问题,例如描述不同治理机构及其职责、列出组织内实体及其所属类别等。以下是基于联合国(UN)相关文档的典型查询示例:
-
Giga³计划如何让联合国儿童基金会(UNICEF)和国际电信联盟(ITU)的相关方参与其战略?
-
人力资源管理(HR Management)下属有哪些实体示例?
-
2023年Giga计划的三大目标受众类别是什么?
本文分享了我们为某大型非营利组织构建和部署基于私有治理手册的LLM问答应用的经验,主要贡献如下:
-
提供了一个面向组织终端用户、基于LLM的治理文档问答应用的真实案例研究;
-
设计了一种结合检索增强生成(RAG)与微调开源LLM的响应生成方案,其中LLM在基于组织文档生成的指令数据集上进行训练;
-
提出了一种新颖的基于树结构的上下文组件(Tree-RAG,T-RAG),该组件采用树结构表示组织内实体的层级信息,在响应用户关于组织层级实体的查询时,生成文本描述以增强上下文;
-
提出了一种新的评估指标(Correct-Verbose),用于评估生成响应的质量------该指标既考量响应的准确性,也统计响应中包含的与问题无关但事实正确的额外信息;此外,通过"大海捞针测试"评估了T-RAG的检索能力。
论文其余部分结构如下:第2节回顾相关工作;第3节定义关键术语;第4节概述LLM应用中的检索增强生成(RAG)技术并详细介绍T-RAG;第5节说明系统实现细节;第6节展示评估结果;第7节总结论文并指出未来工作方向。
¹https://www.nytimes.com/2022/12/05/technology/chatgpt-ai-twitter.html
²https://mashable.com/article/samsung-chatgpt-leak-details
³Giga是联合国儿童基金会(UNICEF)与国际电信联盟(ITU)联合发起的倡议,旨在实现全球所有学校联网。ITU即国际电信联盟(International Telecommunication Union)。
2 相关工作
2.1 大型语言模型
大型语言模型(LLM)在自然语言处理领域展现出卓越能力Zhao et al.(2023)。近年来,各类LLM层出不穷,例如OpenAI的GPT系列(如GPT-4OpenAI et al.(2023))和开源模型(如Meta的Llama-2Touvron et al.(2023))。LLM基于Transformer架构Vaswani et al.(2017),大型模型的参数规模可达数千亿。它们在海量训练数据上进行预训练,数据来源包括书籍、网络爬虫页面和社交媒体对话Zhao et al.(2023)。其强大的语言能力使LLM适用于问答等下游应用,但在处理训练语料之外的领域特定或高度专业的查询时,LLM仍存在局限性Kandpal et al.(2023)。尽管LLM可以针对金融Huang et al.(2023)或地理语言映射Huang et al.(2022)等特定领域进行预训练,但这需要大规模训练数据集和高昂的计算资源。目前已有多种基于LLM构建领域特定应用的方法,下文将对相关方法进行综述。
2.2 微调
微调是一种将领域知识融入LLM参数记忆的方法------通过在领域特定标注数据集(如问答应用的问答数据集)上训练,更新模型权重Min et al.(2017)。微调既能保留LLM的语言能力,又能融入新任务的知识,并适配LLM的写作风格和语气Gao et al.(2024)。微调需要高质量的训练数据集,但数据集规模远小于预训练所需数据Gao et al.(2024)。全参数微调(更新模型所有参数)Howard and Ruder(2018)的计算成本极高,而仅更新模型参数的一个小子集即可实现相当的性能Houlsby et al.(2019)。近年来,参数高效微调(PEFT)方法的兴起显著降低了微调所需的内存占用和计算资源Xu et al.(2023), Lialin et al.(2023),使其成为资源有限组织的可行选择。
2.3 检索增强生成(RAG)
检索增强生成(RAG)是一种无需训练LLM即可构建LLM应用的主流方法。当面对训练数据之外的领域特定问题时,LLM可能生成不准确信息(即"幻觉")Zhang et al.(2023)。RAG通过从外部数据源检索信息,并将其作为上下文传递给LLM以生成响应,从而解决这一问题Lewis et al.(2020)。通过让模型访问外部信息源,RAG显著提升了生成响应的事实准确性和相关性Ram et al.(2023)。尽管RAG也可用于预训练阶段Guu et al.(2020a), Guu et al.(2020b),但由于其实用性和易用性,更多被应用于推理阶段Gao et al.(2024)。然而,RAG对检索文档的构成高度敏感Cuconasu et al.(2024),因此需要大量定制化工作以构建有效的检索流水线。RAG还可与微调等其他方法结合使用Balaguer et al.(2024)。
2.4 知识图谱
RAG应用通常依赖检索器根据用户查询获取相关文档,但也存在其他获取相关上下文的方法,例如基于知识图谱生成上下文Agrawal et al.(2023a)。知识图谱以三元组形式(实体对(图中的节点)及其关系(图中的边))表示现实世界的符号知识。可基于用户查询中提到的实体从知识图谱中提取相关信息,并以三元组原始格式Baek et al.(2023)或文本陈述形式Wu et al.(2023)作为上下文提供给LLM。领域特定知识图谱已被应用于医疗Xia et al.(2022)、金融Baldazzi et al.(2023)和教育Agrawal et al.(2023b)等领域的问答应用。另一种方法(GraphRAG)基于源文档构建LLM衍生的知识图谱,用于检索和响应生成Edge et al.(2024)。尽管知识图谱能够捕捉实体对之间的多种关系,但无法有效表示组织架构等层级信息------这类信息更适合用树结构表示。
2.5 LLM的应用
LLM的应用已扩展到多个领域:教育领域的试题生成Drori et al.(2023)、招聘与职位推荐Fang et al.(2023)、新闻推荐Xiao et al.(2022)、各类医疗应用He et al.(2023)、医疗问答Guo et al.(2022)、患者健康记录查询Hamidi and Roberts(2023)、心理健康辅助工具Lai et al.(2023)、法律问答Louis et al.(2023)以及IT支持系统Yang et al.(2023)等。
3 关键术语
以下是部分LLM相关关键术语的简要释义:
-
提示词(Prompt):输入给LLM的文本,用于引导模型行为和生成输出。根据任务不同,提示词可包含指令、上下文、问题和示例等多个元素。
-
系统提示词(System Prompt):位于提示词开头的文本指令,不同模型可能通过特殊标签(如<<SYS>>)标识。系统提示词包含模型需遵循的指令,并设定模型的工作场景。附录A.2提供了本文使用的系统提示词示例。
-
上下文(Context):添加到提示词中的额外文本,帮助LLM回答问题。例如,对于问题"2022年国际足联世界杯在哪里举办?",上下文可以是维基百科中相关段落的内容。
-
上下文学习(In-context Learning):LLM无需微调,仅通过在上下文中提供示例即可完成新任务的能力。例如,要进行情感分析,可向LLM提供两个句子及其情感标签,再输入第三个句子,模型即可预测其情感。这也被称为少样本学习(few-shot learning)。
-
上下文窗口/长度(Context Window/Length):LLM可接收的最大输入令牌数(Llama-2的上下文窗口为4096个令牌)。更长的上下文窗口允许模型一次性处理更多信息,有助于理解长文本。
-
幻觉(Hallucination):LLM生成看似合理但与上下文、用户输入或现实知识不符的虚假信息Zhang et al.(2023)。例如,当被要求列出联合国难民署(UNHCR)创新服务部门(Innovation Service)下属实体时(图2),模型可能错误地提及"设计服务部(Design Services)",而该实体在组织中并不存在。
4 检索增强生成(RAG)
检索增强生成(RAG)通过为LLM提供外部信息源,提升其在领域特定任务上的性能。尽管RAG存在多种变体,本文在算法1中概述了典型的RAG应用流程。该流程通常包括两个阶段:应用启动时执行一次的索引阶段(Index Process),以及每次响应输入查询时执行的查询阶段(Query Process)Barnett et al.(2024)。
索引阶段的步骤如下:将输入文档D分割为离散的文本块{c₁, c₂, ..., cₙ}(步骤2和3);使用编码器模型将文本块cᵢ转换为嵌入向量dᵢ=encoder(cᵢ)(步骤4);将嵌入向量存储到向量数据库中(步骤5)。该数据库后续用于为用户查询检索相关文本块。
查询阶段在响应用户查询时执行:对于给定查询q,使用编码器模型生成查询的嵌入向量v=encoder(q);搜索数据库以找到与查询嵌入向量v最相似的前k个文本块嵌入向量{d₁, d₂, ..., dₖ}(相似度计算和文本块筛选可采用多种算法);将从数据库中检索到的前k个文本块{c₁, c₂, ..., cₖ}与查询一起输入提示词模板;将完整的提示词输入LLM,模型基于提供的信息生成输出,并返回给用户。
表1:LLM应用算法。左侧为典型RAG应用的算法,右侧为本文系统(T-RAG)的算法。蓝色高亮部分为本文系统与典型RAG的差异。T-RAG的索引阶段与RAG类似,故未展示。
算法1 典型RAG系统的高层概述
索引阶段
1: 加载嵌入模型 → embeddings
2: 加载文档 → doc = load("file_name")
3: 文档分块 → c = chunker.chunk(doc)
4: 生成文本块嵌入 → ce = embeddings.embed(c)
5: 构建向量数据库 → db = index(ce)
查询阶段
1: 初始化系统提示词 → sys_prompt = "你是一个AI...."
2: 加载LLM模型 → model = load("llm_model")
3: 循环:
4: 获取用户查询 → q = get.user_query()
5: 生成查询嵌入 → qe = embeddings.embed(q)
6: 检索相关文本块 → chunks = db.search(qe)
7: 合并文本块为上下文 → context = merge(chunks)
8: 构建提示词 → prompt = create_prompt(sys_prompt, q, context)
9: 生成响应 → answer = model.generate(prompt)
10: 结束循环
算法2 本文系统(T-RAG)
查询阶段
1: 初始化系统提示词 → sys_prompt = "你是一个AI...."
2: 加载微调LLM模型 → model = load("finetuned_llm")
3: 构建实体树 → tree = build_tree("entities_file")
4: 循环:
5: 获取用户查询 → q = get.user_query()
6: 生成查询嵌入 → qe = embeddings.embed(q)
7: 检索相关文本块 → chunks = db.search(qe)
8: 解析查询中的实体 → entities = parse_entities(q)
9: 如果实体不为空:
10: 从实体树检索实体信息 → entities_info = tree.search(entities)
11: 合并实体信息与文本块为上下文 → context = merge(entities_info, chunks)
12: 否则:
13: 仅使用文本块作为上下文 → context = merge(chunks)
14: 构建提示词 → prompt = create_prompt(sys_prompt, q, context)
15: 生成响应 → answer = model.generate(prompt)
16: 结束循环
4.1 T-RAG
本文系统(Tree-RAG,T-RAG)的整体工作流程如图1所示,算法2概述了其核心步骤。与典型RAG应用相比,T-RAG的查询阶段有两处关键改进:一是未使用预训练LLM,而是采用微调后的LLM生成响应(微调过程基于组织文档生成的问答指令数据集,详见后续章节);二是除向量数据库外,引入了实体树用于上下文检索。
实体树存储组织内实体及其层级位置信息:树中的每个节点代表一个实体,父节点表示该实体所属的上级类别。例如,在图2所示的联合国难民署(UNHCR)组织架构中,"难民署创新服务部(UNHCR Innovation Service)"是"副高级专员(Deputy High Commissioner)"下属的实体。
在检索阶段,T-RAG利用实体树进一步增强向量数据库检索到的上下文,具体流程如下:解析器模块从用户查询中提取与组织实体名称匹配的关键词;如果找到匹配项,从实体树中提取每个匹配实体的信息,并转换为描述该实体及其在组织层级中位置的文本陈述;将该文本陈述与向量数据库检索到的文档文本块合并,形成最终上下文。这使得模型在响应用户关于组织实体的查询时,能够获取实体及其层级关系的相关信息。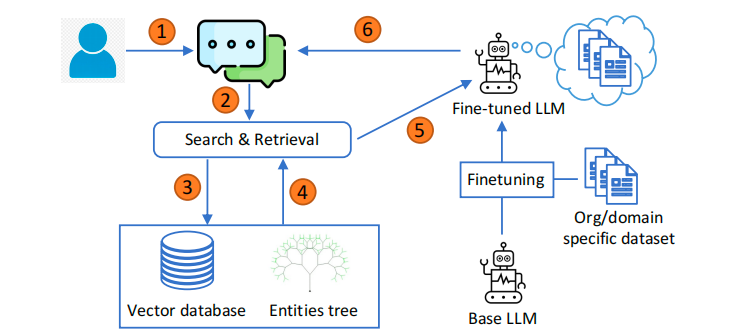
5 方法
本节及后续章节将详细说明系统实现和评估过程。由于无法分享组织私有文档的具体细节,本文将使用公开可得的联合国(UN)组织文档作为示例进行说明。
5.1 指令数据集构建
微调LLM需要领域特定的训练数据集,本节将介绍基于组织文档生成指令数据集的流程。
第一步:将原始PDF文档转换为文本格式以进行后续处理(使用LangChain库⁴)。除文本外,文档还包含多个表格和一个展示所有实体的组织架构图------由领域专家手动将表格和组织架构图转换为文本描述。
第二步:基于文档的章节标题进行分块,将每个章节分割为独立的文本块。通过多轮迭代为每个文本块生成(问题,答案)对,具体流程如下:
-
第一轮迭代:向Llama-2模型输入文本块,要求生成多种类型的问题(如判断题、总结题、简答题等)及对应答案,记录模型生成的问题、答案和相关文本块;
-
第二轮迭代:向模型输入文本块和对话示例,要求生成用户与AI助手的对话;
-
第三轮迭代:向模型输入文本块和领域专家基于文档手动设计的问题示例,要求生成问题及答案。
提示词示例详见附录A.1。
最后,汇总多轮迭代生成的问答对,通过人工检查进行质量控制,并去除重复问题。最终数据集包含1614个问答对,随机分为90%的训练集和10%的验证集。
5.2 LLM微调
由于LLM参数规模庞大,全参数微调的计算成本极高。参数高效微调(PEFT)是一类高效微调LLM的技术,其中QLoRADettmers et al.(2023)结合了4位量化(4-bit Quantization)和低秩适配(LoRA)Hu et al.(2021)两种技术,是一种高效的LLM微调方法。LoRA的核心假设是:LLM的模型权重具有低内在秩,可通过低秩矩阵近似表示,从而显著减少微调过程中需要更新的参数数量。
LoRA的数学表达如下:h = W₀x + BAx,其中h是模型输出,x是输入,W₀∈ℝ^(d×n)是预训练模型权重,B∈ℝ^(d×r)和A∈ℝ^(r×n)是低秩矩阵(秩r远小于min(n,d))。微调过程中,预训练权重W₀保持冻结,仅更新低秩矩阵A和B。因此,需要更新的参数数量为d×r + r×n,远小于预训练模型的总参数数量d×n。本文在微调Llama-2 7B模型时,设置秩r=64,最终可训练参数约为3350万,仅为模型总参数的1/200左右。
QLoRA通过权重量化进一步节省内存------将预训练模型权重W₀转换为4位精度表示。本文使用Hugging Face的"peft"⁵库,基于QLoRA在问答指令数据集上微调基础LLM模型,微调过程使用4台配备24GB内存的Quadro RTX 6000 GPU。
⁵https://huggingface.co/docs/peft/index
5.3 实体树构建
组织文档包含展示组织层级和部门划分的组织架构图,其中列出了所有实体及其所属类别和子类别。为了响应关于这些实体及其层级位置的查询,需要将该信息转换为LLM可访问和使用的格式。本节将介绍如何表示该信息,并在用户查询时检索相关信息以增强输入给LLM的上下文。
组织层级和所有实体以树结构编码:树中的每个节点代表一个实体,父节点代表该实体的直接上级类别。图2展示了联合国难民署(UNHCR)⁶组织架构的一个片段------布达佩斯全球服务中心(Global Service Center in Budapest)是副高级专员(Deputy High Commissioner)下属实体,而副高级专员又隶属于高级专员执行办公室(High Commissioner Executive Office)。通过这种树结构,可以编码每个实体在组织中的完整层级路径,以及其下属的其他实体。在检索阶段,可从树中提取该信息并转换为文本陈述,与向量数据库检索到的文档文本块合并作为上下文(见图2),帮助LLM生成更准确的响应。
⁶https://reporting.unhcr.org/unhcr-headquarters-organizational-structure
为了确保上下文仅包含与实体相关的关键信息,需要先检测用户查询中是否提及组织实体:如果查询未提及任何实体,则跳过树检索,仅使用文档文本块作为上下文;如果提及实体,则需要准确识别这些与组织相关的命名实体。本文使用spaCy⁷库提取用户查询中的命名实体,但spaCy的默认命名实体识别(NER)算法无法满足自定义场景需求------例如,对于图2中的用户查询,spaCy可能仅将"布达佩斯(Budapest)"识别为地点实体,而忽略"布达佩斯全球服务中心(Global Service Center in Budapest)"是联合国难民署(UNHCR)的组织实体这一关键信息。因此,本文对spaCy进行了定制化改造:定义新的实体类别,并通过字符串匹配规则识别组织实体。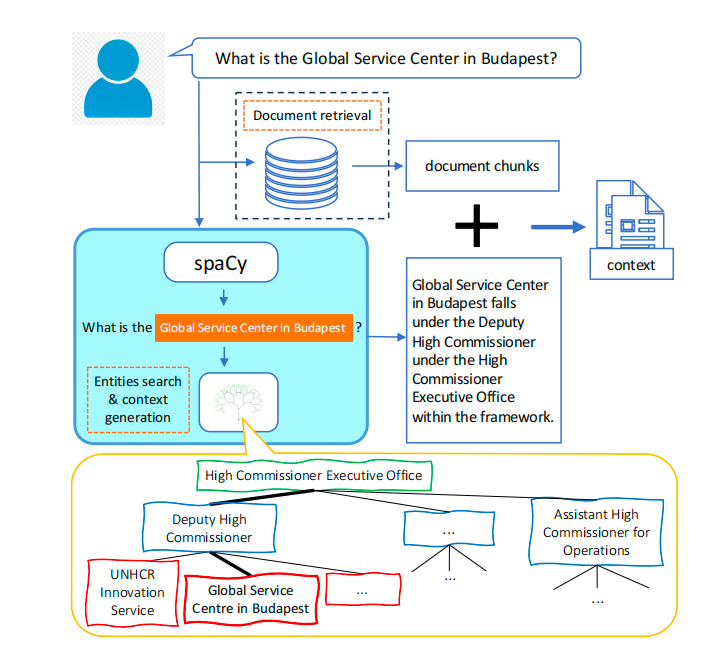
上下文生成的整体流程总结如下(图2):
-
对于用户输入查询,首先从向量数据库检索相关信息文本块(RAG的标准流程);
-
解析用户查询中的实体名称;
-
如果未检测到实体,则跳过树检索,上下文仅包含文档文本块;
-
如果检测到一个或多个实体(如示例中的"布达佩斯全球服务中心"),则从实体树中提取相关信息并转换为文本形式,与文档文本块合并作为最终上下文。
5.4 实现配置
5.4.1 响应生成的LLM模型
由于应用需要本地部署,本文选择开源的Llama-2模型Touvron et al.(2023)------该模型性能优异且支持本地部署。Llama-2模型提供多种参数规模(7B至70B),本文选择较小的Llama-2 7B聊天模型⁸,原因是:大型LLM的微调和运行需要大量计算资源,而小型模型更适合资源有限的中小企业或GPU获取受限的地区Nellis and Cherney(2023)。
⁸https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
5.4.2 系统实现方案
本文测试了三种系统实现方案,具体如下表2所示:
表2:不同系统实现方案概述
|-----------------|-----------|---------------|
| 名称 | 模型 | 上下文来源 |
| RAG | 基础Llama-2 | 文档文本块 |
| 微调模型(Finetuned) | 微调Llama-2 | 无 |
| T-RAG | 微调Llama-2 | 问答文本块 + 实体树信息 |
-
RAG:使用基础Llama-2模型,上下文为原始文档的10个文本块;
-
微调模型(Finetuned):使用在组织文档指令数据集上微调的Llama-2模型,无额外上下文;
-
T-RAG:结合RAG检索和微调模型生成响应,上下文来源包括两部分:(1)从指令数据集筛选的3对问答文本块(仅保留直接问答,过滤对话、填空题等类型);(2)实体树信息(基于用户查询中提及的实体,从实体树中提取的层级信息)。
技术选型细节:
-
向量数据库:Chroma DB⁹(用于存储文档文本块以进行上下文检索);
-
文档选择算法:最大边际相关性(MMR)------基于与查询的相似度和文档多样性选择文本块;
-
嵌入模型:Instructor¹⁰(适用于多领域的文本嵌入模型Su et al.(2023));
-
推理配置:贪心解码(温度参数=0),重复惩罚系数=1.1。
¹⁰原文中嵌入模型为"Instructor",保留原名(中文可译为"指令嵌入模型")
6 结果
6.1 性能评估
LLM输出评估通常采用自动评估或人工评估Chang et al.(2023):自动评估依赖更强大的LLM(如GPT-4Liu et al.(2023))或专门用于评估的裁判LLMWang et al.(2023),研究表明LLM评估结果与人工评估结果在多种任务上具有一致性Chiang and Lee(2023);自动评估扩展性强且成本较低,但对于面向终端用户的系统,真实用户反馈至关重要。
本文采用人工评估验证系统性能:组织终端用户对系统进行三轮测试,生成三组测试问题。第一组问题由熟悉文档的组织领域专家设计,用于系统初始测试;第二组和第三组问题由其他终端用户在后续测试中生成。
由领域专家对生成响应进行评分,评分标准如下:
-
正确(C):响应准确回答问题,且事实无误;
-
正确-冗余(CV):响应准确回答问题,但包含与问题无关但事实正确的额外信息。
LLM应用的核心目标是提供准确、简洁的答案。由于LLM可能从上下文中提取无关信息,"正确-冗余(CV)"指标用于量化系统生成冗余答案的频率。评估结果如表3所示,"All"行(粗体)为三组问题的汇总结果,"T"列为正确响应总数(T=C+CV),最后一列为正确响应百分比。
表3:评估结果。每个系统在三轮用户测试生成的三组问题上进行测试,"All"为汇总结果。N为每组问题的数量,响应被手动评为"正确(C)"或"正确-冗余(CV)"(即回答正确但包含无关的正确信息)。"T"为正确响应总数(T=C+CV),最后一列为正确响应百分比。RAG和微调模型的性能相近,T-RAG整体性能更优,但更倾向于生成冗余答案。
|-----------------|-----|----|-------|-----------|--------|-------|
| 名称 | 问题集 | N | C(正确) | CV(正确-冗余) | T(总正确) | 百分比 |
| RAG | 集1 | 17 | 9 | 0 | 9 | 52.9% |
| RAG | 集2 | 11 | 7 | 0 | 7 | 63.6% |
| RAG | 集3 | 9 | 4 | 1 | 5 | 55.6% |
| RAG | 所有 | 37 | 20 | 1 | 21 | 56.8% |
| 微调模型(Finetuned) | 集1 | 17 | 11 | 1 | 12 | 70.6% |
| 微调模型(Finetuned) | 集2 | 11 | 3 | 0 | 3 | 27.3% |
| 微调模型(Finetuned) | 集3 | 9 | 5 | 0 | 5 | 55.6% |
| 微调模型(Finetuned) | 所有 | 37 | 19 | 1 | 20 | 54.1% |
| T-RAG | 集1 | 17 | 9 | 4 | 13 | 76.5% |
| T-RAG | 集2 | 11 | 6 | 2 | 8 | 72.7% |
| T-RAG | 集3 | 9 | 6 | 0 | 6 | 66.7% |
| T-RAG | 所有 | 37 | 21 | 6 | 27 | 73.0% |
在37个问题中,RAG和微调模型的性能相近(分别正确回答21个和20个问题),而T-RAG的整体性能更优(正确回答27个问题)。但T-RAG更倾向于生成冗余答案:6个响应被评为"正确-冗余(CV)",而其他两种方案仅各有1个。
6.2 实体树检索模块的评估
为了评估T-RAG中实体树组件生成的上下文对性能的提升作用,设计了两组与实体相关的测试问题:
-
简单问题集(simple):直接询问组织实体的相关信息;
-
复杂问题集(complex):要求列出某类别下的部分或全部实体,或询问两个不同类别下的实体(复合问题)。
以联合国难民署(UNHCR)组织架构为例:
-
简单问题:"副高级专员(Deputy High Commissioner)在组织框架中的位置是什么?"
-
复杂问题:"列出副高级专员(Deputy High Commissioner)和对外关系部(External Relations)下属的部分实体。"
测试了包含/不包含实体树上下文的不同实现方案,结果如表4所示:实体树上下文显著提升了简单问题和复杂问题的回答准确率------对于微调模型,加入实体树上下文后,两组问题的正确响应数量几乎翻倍。性能提升的原因主要有两点:一是实体树上下文减少了模型的"幻觉"(即生成不存在的实体或类别);二是实体树上下文补充了微调模型的参数记忆,使其能够更准确地回答实体相关问题(如列出某类别下的实体)------LLM在记忆冷门实体的长尾知识时往往存在困难Kandpal et al.(2023)。
表4:实体相关问题的实体树上下文评估结果。对比包含/不包含实体树上下文的不同实现方案,以评估实体树的性能提升。括号内为正确响应百分比。实体树上下文显著提升了RAG和微调模型的性能。
|--------------------------------|-----------|-----------|
| 名称 | 简单问题(17个) | 复杂问题(22个) |
| RAG | 10(58.5%) | 11(50%) |
| 微调模型(Finetuned) | 8(47.1%) | 8(36.4%) |
| 微调模型+实体树(Finetuned + tree) | 17(100%) | 17(77.3%) |
| 无实体树的T-RAG(T-RAG without tree) | 16(94.1%) | 10(45.5%) |
| T-RAG | 17(100%) | 15(68.2%) |
对于T-RAG,移除实体树上下文后性能仍有一定下降,但下降幅度小于微调模型:无实体树的T-RAG在简单问题上的正确率为94.1%(16/17),这是因为其上下文包含了指令数据集的问答文本块;而在复杂问题上,实体树上下文的提升效果更为显著------包含实体树时正确率为68.2%(15/22),不包含时仅为45.5%(10/22)。
6.2.1 基于联合国难民署(UNHCR)组织架构的评估
使用联合国难民署(UNHCR)的组织架构进一步测试实体树上下文的效果:设计13个简单问题和13个复杂问题,询问UNHCR组织层级中的各类实体。对比两种RAG系统的性能:(1)上下文为UNHCR组织层级的文本描述块;(2)上下文为实体树生成的文本陈述。结果显示,实体树上下文显著提升了准确率:
-
简单问题:文本块RAG的正确率为46.2%(6/13),实体树RAG的正确率为92.3%(12/13);
-
复杂问题:文本块RAG的正确率为46.2%(6/13),实体树RAG的正确率为61.5%(8/13)。
6.2.2 定性评估
分析模型生成的响应发现,实体树上下文可减少以下两类错误:
-
幻觉错误:主要出现在无上下文的微调模型中,表现为生成不存在的实体;
-
错位错误:响应中提及的实体属于组织,但被错误归类到其他类别下。
表5展示了一个错位错误的示例:问题询问"副高级专员(Deputy High Commissioner)和对外关系部(External Relations)下属的实体",但响应中错误地将"高级专员执行办公室(High Commissioner Executive Office)"下属的实体(红色粗体标注)列为副高级专员的下属实体。
表5:错位错误示例。基于UNHCR实体的RAG系统(无实体树上下文)生成的问题和响应。红色粗体标注的实体实际隶属于高级专员执行办公室,但被错误列为副高级专员的下属实体。
|----|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 问题 | 列出副高级专员(Deputy High Commissioner)和对外关系部(External Relations)下属的部分实体? |
| 响应 | 根据提供的上下文,副高级专员下属实体包括:<br>1. 副高级专员(Deputy High Commissioner)<br>2. 监察长办公室(Inspector General Office)<br>3. 政策制定与评估办公室(Policy Development & Evaluation Office)<br><br>对外关系部下属实体包括:<br>1. 治理与合作(Governance & Partnership)<br>2. 机构间协调(Inter-agency Coordination)<br>3. 战略沟通(Strategic Communications)<br>4. 私营部门筹款服务(Private Sector Fund Raising Service)<br>5. 沟通与公共信息(Communications & Public Information) |
6.2.3 大海捞针测试(Needle in a Haystack Test)
为了评估上下文位置对模型性能的影响,进行了"大海捞针测试"gkamradt(2023):将相关上下文(T-RAG的实体树上下文或RAG的文档文本块上下文)放置在由k个无关上下文块组成的"干扰项"中,测试模型在不同位置和干扰项数量下的性能。测试基于39个实体相关问题,结果如表6所示。
总体而言,相关上下文位于上下文两端时,模型性能更优;值得注意的是,当相关文档文本块位于10个无关块中间时(k=10),RAG的性能显著下降(正确率仅33.3%),而T-RAG在相同条件下仍保持较高性能(正确率64.1%)。这表明,无论相关信息的位置和上下文规模如何,模型从实体树上下文中提取正确答案的能力更强。
表6:大海捞针测试结果。将实体树上下文(T-RAG)或包含相关信息的文档文本块(RAG)放置在由k个无关文档组成的上下文中,测试39个实体相关问题的性能。相关信息位于上下文两端时,模型性能通常更优;当相关文档文本块位于大量无关文档中间时(k=10),RAG性能显著下降,而T-RAG仍保持较好性能。
|---------|-----------|-----------|-----------|-----------|
| 位置 | T-RAG | | RAG | |
| | k=2 | k=10 | k=2 | k=10 |
| 顶部(Top) | 29(74.4%) | 27(69.2%) | 30(76.9%) | 22(56.4%) |
| 中间(Mid) | 27(69.2%) | 25(64.1%) | 26(66.7%) | 13(33.3%) |
| 底部(End) | 32(82.1%) | 28(71.8%) | 25(64.1%) | 18(46.2%) |
6.3 微调模型的过拟合测试
微调通过更新模型权重使LLM学习新任务,但可能导致模型过拟合(即忘记预训练阶段学到的知识)。为了测试过拟合风险,在大规模多任务语言理解(MMLU)基准测试Hendrycks et al.(2021)上对比了微调模型和基础模型的性能------MMLU包含多个学科(如STEM、人文科学、社会科学等)的多项选择题,用于评估LLM的语言理解能力和知识储备。
图3显示了基础模型和微调模型的整体及各学科准确率:微调模型的整体准确率为43%,基础模型为45.3%,两者性能相近;微调模型在人文科学上的得分略高,在STEM领域得分较低。这表明本文的微调未导致严重过拟合,但仍需谨慎对待微调------它可能影响LLM的通用语言能力。
7 经验教训
构建适用于实际应用的稳健LLM系统需要诸多考量和定制化工作,基于本文的实践经验,总结以下关键教训:
-
基础RAG系统的搭建相对简单,但要实现稳健性并非易事------需要领域专业知识(例如,本文借助领域专家设计示例问题,用于生成微调的指令数据集),并对系统各组件进行优化设计;
-
微调模型对问题表述较为敏感。例如,当向微调模型询问"提供所有......的完整列表"(a comprehensive list of all the...)与"提供所有......的列表"(a list of all the...)时,前者可能生成包含虚假名称的"幻觉"响应,而后者可得到正确答案。这可能是因为问题表述与训练数据中的表述存在差异;
-
微调模型可将信息融入模型参数,从而节省LLM有限的上下文窗口空间,为聊天应用的对话历史等其他信息预留更多空间。这可能是一种比扩展LLM上下文窗口Zhang et al.(2024)或适配大上下文窗口的RAGXu et al.(2024)更简洁的替代方案;
-
在系统开发的多个阶段引入终端用户测试,可获取有价值的反馈,指导开发过程中的决策;
-
树结构是表示组织实体等层级信息的理想形式,评估结果表明,实体树上下文能显著提升系统响应实体相关问题的稳健性。
7.1 RAG与微调的对比
本文的应用结合了RAG和微调两种方法,两者各有优劣,具体对比如下:
-
计算资源:微调初期需要更多计算资源进行模型训练,而小型应用的RAG计算需求主要集中在检索技术,相对较低;
-
风格适配:与RAG相比,微调更易使模型的写作风格和语气适配组织文档;
-
通用能力风险:微调需谨慎,更新模型参数可能降低LLM的整体语言能力,因此需要通过过拟合测试等方式验证;
-
优化需求:微调需要构建高质量训练数据集和调优超参数,而RAG也需要大量优化工作(例如文档分块方式、嵌入模型选择、检索算法设计等,见表1中的RAG算法步骤);
-
知识更新:LLM应用需要随着底层文档的变化更新知识库------RAG可通过更新检索数据库轻松实现,更适合动态、频繁更新的场景;而微调模型的更新需要重新构建训练数据集并重新训练,更适合底层文档变化不频繁的场景(如本文的应用);
-
鲁棒性:微调模型在面对陌生输入时仍易产生"幻觉",而RAG通过将响应锚定在上下文上,可显著减少"幻觉"Zhang et al.(2023)。但RAG的检索流水线存在诸多局限性,对嘈杂或不完整的上下文敏感,可能导致"幻觉"和不完整答案Barnett et al.(2024)。
减少LLM的"幻觉"仍是一个开放的研究问题,未来的技术进展将使系统更稳健Ye et al.(2023)。基于本文经验,结合RAG和微调的混合方法在实际应用中具有广阔前景,值得进一步探索。
7.2 未来工作
该组织对本文系统给予了积极反馈,并希望将其扩展到更广泛的文档语料库。未来的另一项工作是将系统扩展为基于聊天的应用,这需要解决问答应用之外的额外问题(如有效处理对话历史)。
参考文献
(注:参考文献列表按原文格式保留,作者、年份、标题、期刊/会议等信息均未改动,仅将英文期刊/会议名称译为中文以符合中文学术论文习惯,格式保持一致)
Agrawal et al.(2023a) Garima Agrawal, Tharindu Kumarage, Zeyad Alghami, and Huan Liu. 2023a. 知识图谱能否减少LLM的幻觉?一项综述(Can Knowledge Graphs Reduce Hallucinations in LLMs? : A Survey). https://doi.org/10.48550/arXiv.2311.07914 arXiv:2311.07914 cs.
Agrawal et al.(2023b) Garima Agrawal, Kuntal Pal, Yuli Deng, Huan Liu, and Chitta Baral. 2023b. AISecKG:网络安全教育的知识图谱数据集(AISecKG: Knowledge Graph Dataset for Cybersecurity Education). 见《AAAI 2023春季研讨会:机器学习与知识工程结合的挑战论文集》(Proceedings of the AAAI 2023 Spring Symposium on Challenges Requiring the Combination of Machine Learning and Knowledge Engineering (AAAI-MAKE 2023))(CEUR Workshop Proceedings, Vol. 3433), Andreas Martin, Hans-Georg Fill, Aurona Gerber, Knut Hinkelmann, Doug Lenat, Reinhard Stolle, and Frank van Harmelen(编). CEUR, 旧金山机场凯悦酒店. https://ceur-ws.org/Vol-3433/#paper6 ISSN: 1613-0073.
Baek et al.(2023) Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023. 零样本知识图谱问答的知识增强语言模型提示词方法(Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering). 见《第一届自然语言推理与结构化解释研讨会论文集》(Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE)), Bhavana Dalvi Mishra, Greg Durrett, Peter Jansen, Danilo Neves Ribeiro, and Jason Wei(编). 计算语言学协会, 加拿大多伦多, 78-106. https://doi.org/10.18653/v1/2023.nlrse-1.7
Balaguer et al.(2024) Angels Balaguer, Vinamra Benara, Renato Luiz de Freitas Cunha, Roberto de M. Estevão Filho, Todd Hendry, Daniel Holstein, Jennifer Marsman, Nick Mecklenburg, Sara Malvar, Leonardo O. Nunes, Rafael Padilha, Morris Sharp, Bruno Silva, Swati Sharma, Vijay Aski, and Ranveer Chandra. 2024. RAG与微调:流水线、权衡与农业领域案例研究(RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture). https://doi.org/10.48550/arXiv.2401.08406 arXiv:2401.08406 cs.
Baldazzi et al.(2023) Teodoro Baldazzi, Luigi Bellomarini, Stefano Ceri, Andrea Colombo, Andrea Gentili, and Emanuel Sallinger. 2023. 基于本体推理的大型企业语言模型微调(Fine-Tuning Large Enterprise Language Models via Ontological Reasoning). 见《规则与推理:第七届国际联合会议论文集》(Rules and Reasoning: 7th International Joint Conference, RuleML+RR 2023, Oslo, Norway, September 18--20, 2023, Proceedings). 施普林格出版社, 德国柏林、海德堡, 86-94. https://doi.org/10.1007/978-3-031-45072-3_6
Barnett et al.(2024) Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. 2024. 检索增强生成系统工程中的七个失败点(Seven Failure Points When Engineering a Retrieval Augmented Generation System). http: //arxiv.org/abs/2401.05856 arXiv:2401.05856 cs.
Chang et al.(2023) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2023. 大型语言模型评估综述(A Survey on Evaluation of Large Language Models). https://doi.org/10.48550/arXiv.2307.03109 arXiv:2307.03109 cs.
Chiang and Lee(2023) Cheng-Han Chiang and Hung-yi Lee. 2023. 大型语言模型能否替代人工评估?(Can Large Language Models Be an Alternative to Human Evaluations?). 见《第61届计算语言学协会年会论文集(第一卷:长论文)》(Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki(编). 计算语言学协会, 加拿大多伦多, 15607-15631. https://doi.org/10.18653/v1/2023. acl-long.870
Cuconasu et al.(2024) Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. 噪声的力量:重新定义RAG系统的检索(The Power of Noise: Redefining Retrieval for RAG Systems). https://doi.org/10.48550/arXiv.2401.14887 arXiv:2401.14887 cs.
Dettmers et al.(2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA:量化LLM的高效微调(QLoRA: Efficient Finetuning of Quantized LLMs). https://doi.org/10.48550/arXiv.2305.14314 arXiv:2305.14314 cs.
Drori et al.(2023) Iddo Drori, Sarah J. Zhang, Reece Shuttleworth, Sarah Zhang, Keith Tyser, Zad Chin, Pedro Lantigua, Saisamrit Surbehera, Gregory Hunter, Derek Austin, Leonard Tang, Yann Hicke, Sage Simhon, Sathwik Karnik, Darnell Granberry, and Madeleine Udell. 2023. 从人工天数到机器秒数:自动生成和解答机器学习期末考试题(From Human Days to Machine Seconds: Automatically Answering and Generating Machine Learning Final Exams). 见《第29届ACM SIGKDD知识发现与数据挖掘会议论文集》(Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '23)). ACM协会, 美国纽约, 3947-3955. https://doi.org/10.1145/3580305.3599827
Edge et al.(2024) Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. 从局部到全局:面向查询的摘要生成的Graph RAG方法(From Local to Global: A Graph RAG Approach to Query-Focused Summarization). https://doi.org/10.48550/arXiv.2404.16130 arXiv:2404.16130 cs.
Fang et al.(2023) Chuyu Fang, Chuan Qin, Qi Zhang, Kaichun Yao, Jingshuai Zhang, Hengshu Zhu, Fuzhen Zhuang, and Hui Xiong. 2023. RecruitPro:基于技能感知提示学习的预训练语言模型在智能招聘中的应用(RecruitPro: A Pretrained Language Model with Skill-Aware Prompt Learning for Intelligent Recruitment). 见《第29届ACM SIGKDD知识发现与数据挖掘会议论文集》(Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '23)). ACM协会, 美国纽约, 3991-4002. https: //doi.org/10.1145/3580305.3599894
Gao et al.(2024) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2024. 大型语言模型的检索增强生成综述(Retrieval-Augmented Generation for Large Language Models: A Survey). https://doi.org/10.48550/arXiv.2312.10997 arXiv:2312.10997 cs.
gkamradt(2023) gkamradt. 2023. LLM测试:大海捞针------LLM压力测试(LLMTest Needle In A Haystack - Pressure Testing LLMs). https://github. com/gkamradt/LLMTest_NeedleInAHaystack.
Guo et al.(2022) Quan Guo, Shuai Cao, and Zhang Yi. 2022. 基于大型语言模型和知识图谱的医疗问答系统(A medical question answering system using large language models and knowledge graphs). 《国际智能系统期刊》(International Journal of Intelligent Systems)37, 11 (2022), 8548-8564. https://doi.org/10.1002/int.22955 _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1002/int.22955.
Guu et al.(2020a) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020a. 检索增强语言模型预训练(Retrieval Augmented Language Model Pre-Training). 见《第37届国际机器学习会议论文集》(Proceedings of the 37th International Conference on Machine Learning). PMLR, 3929-3938. https://proceedings.mlr.press/v119/guu20a.html ISSN: 2640-3498.
Guu et al.(2020b) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020b. REALM:检索增强语言模型预训练(REALM: retrieval-augmented language model pre-training). 见《第37届国际机器学习会议论文集》(Proceedings of the 37th International Conference on Machine Learning (ICML'20, Vol. 119)). JMLR.org, 3929-3938.
Gómez-Rodríguez and Williams(2023) Carlos Gómez-Rodríguez and Paul Williams. 2023. 模型联盟:大型语言模型在创意写作上的综合评估(A Confederacy of Models: a Comprehensive Evaluation of LLMs on Creative Writing). 见《计算语言学协会发现:EMNLP 2023》(Findings of the Association for Computational Linguistics: EMNLP 2023), Houda Bouamor, Juan Pino, and Kalika Bali(编). 计算语言学协会, 新加坡, 14504-14528. https://doi.org/10.18653/v1/2023.findings-emnlp.966
Hamidi and Roberts(2023) Alaleh Hamidi and Kirk Roberts. 2023. AI聊天机器人在患者特定电子健康记录问题上的评估(Evaluation of AI Chatbots for Patient-Specific EHR Questions). https://doi.org/10.48550/arXiv.2306.02549 arXiv:2306.02549 cs.
He et al.(2023) Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, and Erik Cambria. 2023. 医疗领域大型语言模型综述:数据、技术、应用与问责制和伦理(A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics). https://doi.org/10.48550/arXiv.2310.05694 arXiv:2310.05694 cs.
Hendrycks et al.(2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. 大规模多任务语言理解评估(Measuring Massive Multitask Language Understanding). https://doi.org/10. 48550/arXiv.2009.03300 arXiv:2009.03300 cs.
Houlsby et al.(2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. 自然语言处理的参数高效迁移学习(Parameter-Efficient Transfer Learning for NLP). 见《第36届国际机器学习会议论文集》(Proceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97)), Kamalika Chaudhuri and Ruslan Salakhutdinov(编). PMLR, 2790-2799. https:// proceedings.mlr.press/v97/houlsby19a.html
Howard and Ruder(2018) Jeremy Howard and Sebastian Ruder. 2018. 文本分类的通用语言模型微调(Universal Language Model Fine-tuning for Text Classification). 见《第56届计算语言学协会年会论文集(第一卷:长论文)》(Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)), Iryna Gurevych and Yusuke Miyao(编). 计算语言学协会, 澳大利亚墨尔本, 328-339. https://doi.org/10.18653/v1/P18-1031
Hu et al.(2021) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA:大型语言模型的低秩适配(LoRA: Low-Rank Adaptation of Large Language Models). https://doi.org/10. 48550/arXiv.2106.09685 arXiv:2106.09685 cs.
Huang et al.(2023) Allen H. Huang, Hui Wang, and Yi Yang. 2023. FinBERT:从金融文本中提取信息的大型语言模型(FinBERT: A Large Language Model for Extracting Information from Financial Text*). 《当代会计研究》(Contemporary Accounting Research)40, 2 (2023), 806-841. https://doi. org/10.1111/1911-3846.12832 _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/1911-3846.12832.
Huang et al.(2022) Jizhou Huang, Haifeng Wang, Yibo Sun, Yunsheng Shi, Zhengjie Huang, An Zhuo, and Shikun Feng. 2022. ERNIE-GeoL:地理-语言预训练模型及其在百度地图中的应用(ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps). 见《第28届ACM SIGKDD知识发现与数据挖掘会议论文集》(Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '22)). ACM协会, 美国纽约, 3029-3039. https://doi.org/10.1145/ 3534678.3539021
Kandpal et al.(2023) Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2023. 大型语言模型在长尾知识学习上的困境(Large language models struggle to learn long-tail knowledge). 见《第40届国际机器学习会议论文集》(Proceedings of the 40th International Conference on Machine Learning (ICML'23, Vol. 202)). JMLR.org, 美国夏威夷檀香山, 15696-15707.
Lai et al.(2023) Tin Lai, Yukun Shi, Zicong Du, Jiajie Wu, Ken Fu, Yichao Dou, and Ziqi Wang. 2023. Psy-LLM:基于AI大型语言模型的全球心理健康服务规模化(Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models). https: //doi.org/10.48550/arXiv.2307.11991 arXiv:2307.11991 cs.
Lewis et al.(2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. 知识密集型自然语言处理任务的检索增强生成(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks). 见《神经信息处理系统进展》(Advances in Neural Information Processing Systems, Vol. 33). Curran Associates, Inc., 9459-9474. https://proceedings.neurips.cc/paper_files/ paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
Lialin et al.(2023) Vladislav Lialin, Vijeta Deshpande, and Anna Rumshisky. 2023. 以小见大:参数高效微调指南(Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning). https://doi.org/10.48550/arXiv.2303.15647
Liu et al.(2023) Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval:基于GPT-4的自然语言生成评估,更贴合人工判断(G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment). https://doi.org/10.48550/arXiv.2303. 16634 arXiv:2303.16634 cs.
Liventsev et al.(2023) Vadim Liventsev, Anastasiia Grishina, Aki Härmä, and Leon Moonen. 2023. 基于大型语言模型的全自主编程(Fully Autonomous Programming with Large Language Models). 见《遗传与进化计算会议论文集》(Proceedings of the Genetic and Evolutionary Computation Conference (GECCO '23)). ACM协会, 美国纽约, 1146-1155. https: //doi.org/10.1145/3583131.3590481
Louis et al.(2023) Antoine Louis, Gijs van Dijck, and Gerasimos Spanakis. 2023. 可解释的长文本法律问答:检索增强大型语言模型(Interpretable Long-Form Legal Question Answering with Retrieval-Augmented Large Language Models). https://doi.org/10.48550/ arXiv.2309.17050 arXiv:2309.17050 cs.
Min et al.(2017) Sewon Min, Minjoon Seo, and Hannaneh Hajishirzi. 2017. 基于大规模细粒度监督数据迁移学习的问答系统(Question Answering through Transfer Learning from Large Fine-grained Supervision Data). 见《第55届计算语言学协会年会论文集(第二卷:短论文)》(Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)), Regina Barzilay and Min-Yen Kan(编). 计算语言学协会, 加拿大温哥华, 510-517. https://doi.org/10.18653/v1/P17-2081
Nellis and Cherney(2023) Stephen Nellis and Max A. Cherney. 2023. 美国限制英伟达和AMD向部分中东国家出口AI芯片(US curbs AI chip exports from Nvidia and AMD to some Middle East countries). 路透社(Reuters)(2023年8月). https://www.reuters.com/technology/ us-restricts-exports-some-nvidia-chips-middle-east-countries-filing-2023-08-30/
OpenAI et al.(2023) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mo Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux