业务痛点:某财险公司年车险理赔额超80亿元,欺诈案件占比约8%(行业平均5-10%),年损失超6.4亿元。现有欺诈检测依赖人工审核(单案耗时2-3天),存在:
- 漏检率高:人工审核后仍有30%欺诈案件未被识别
- 成本高:专职审核团队50人,年人力成本超1200万元
- 标准不一:不同审核员对"理赔合理性"判断差异大(如"单方事故无现场照片"的风险权重不一致)
算法团队:
- 语言:Python 3.9、Scala 2.13(Spark开发)
- 数据处理:Spark 3.4(分布式ETL)、Pandas 1.5(本地特征探索)
- 特征存储:Feast 0.34(统一管理在线/离线特征)
- 模型训练:Scikit-learn 1.2(随机森林)、XGBoost 2.0(备选)
- 实验跟踪:MLflow 2.8(记录参数/指标/模型)、Weights & Biases(可视化)
- 版本控制:Git(算法仓库:git@github.com:insurer/claims-fraud-algorithm.git)
业务团队:
- 语言:Java 17(Spring Boot)、Go 1.20(高性能API)
- 服务框架:FastAPI 0.104(Python轻量级API)、gRPC(跨语言通信)
- 服务治理:Kong 3.4(API网关)、Consul 1.16(服务发现)
- 监控:Prometheus 2.47(指标采集)、Grafana 10.2(可视化)
- 版本控制:Git(业务仓库:git@github.com:insurer/claims-fraud-business.git)
数据准备与特征变化
(1)原数据结构(多源异构数据)
原始数据来自5个系统,存储在数据湖(HDFS)中,包含结构化(SQL表)、半结构化(JSON日志)、非结构化(事故照片元数据)数据。
① 理赔核心系统(claims_core,Hive表)

② 车辆管理系统(vehicle_info,MySQL表)

③ 投保人数据库(policyholders,PostgreSQL表)

④ 第三方数据(third_party,MongoDB集合)
json
// 维修厂资质
{ "repair_shop_id": "RP045", "license_status": "有效", "fraud_history": 0, "avg_claim_amount": 7800 }
// 交警事故库
{ "accident_id": "ACC789", "claim_id": "CLM001", "is_false_report": 0, "weather": "晴" }⑤ 反欺诈黑名单库(fraud_blacklist,HBase表)

(2)数据清洗与特征工程(算法团队负责)
缺失值处理:
- has_witness(是否有证人):空值用"0"(无证人)填充(占80%);
- last_maintenance_date(上次保养日期):空值用"事故前6个月"默认日期(基于车型平均保养周期)
异常值处理:
- claim_amount(理赔金额):超过同车型历史95%分位数(如家用轿车>5万)视为异常,用"车型-损失类型"中位数替换
- report_delay_hours(报案延迟小时数=report_time-accident_time):>72小时视为无效,标记为"高风险"并人工复核
特征提取(核心业务逻辑,从原始字段到特征字段)
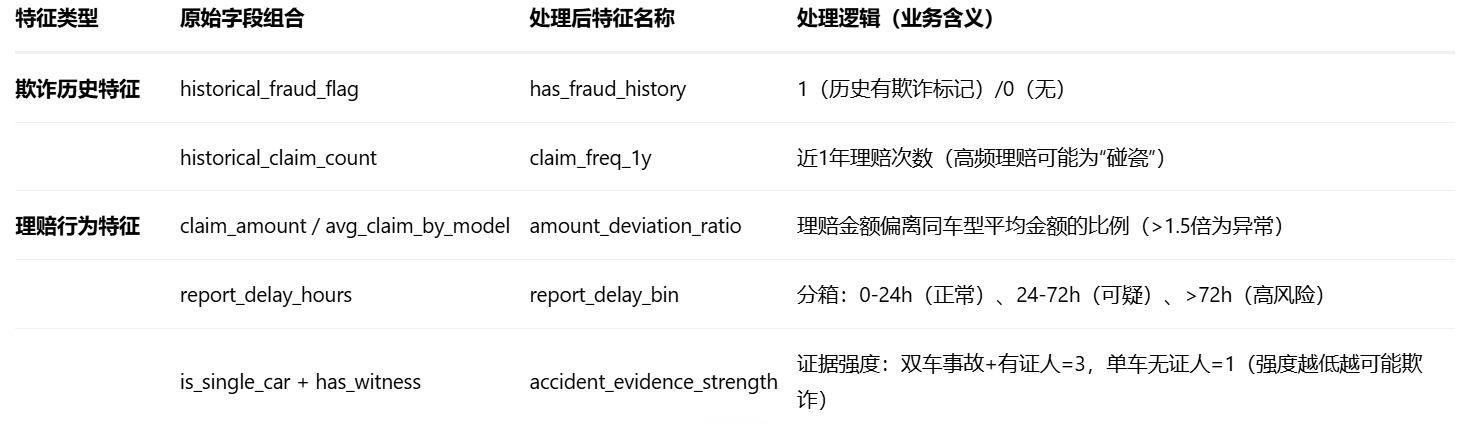
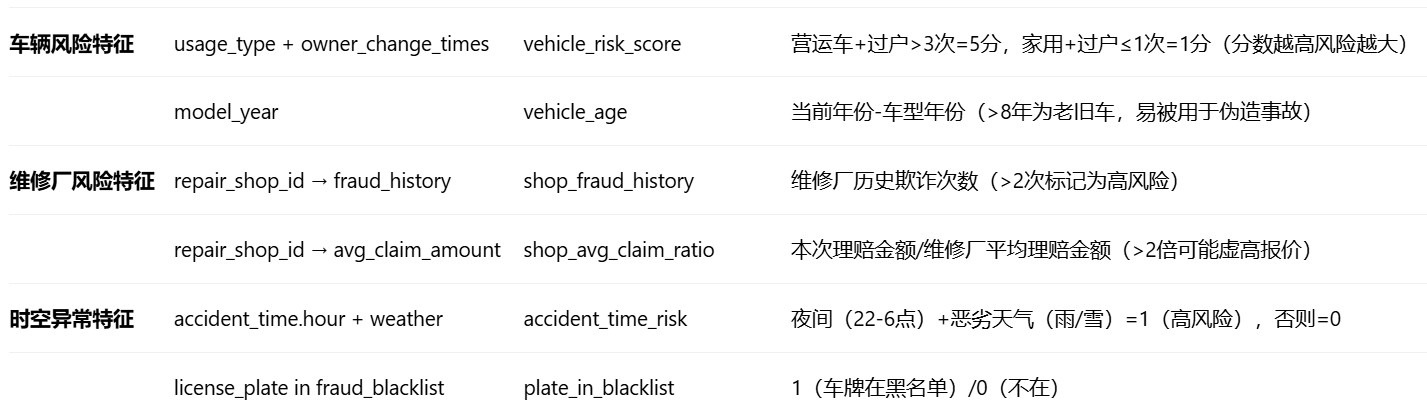
特征编码与标准化
- 类别特征:usage_type(车辆使用性质)、loss_type(损失类型)用Target Encoding(基于欺诈率编码,避免One-Hot维度爆炸)
- 连续特征:amount_deviation_ratio、claim_freq_1y用RobustScaler(抗异常值)
- 特征选择:用随机森林内置特征重要性(或SHAP值)筛选Top20特征(剔除重要性<0.01的特征)
特殊变化对比表(原数据->处理后特征)
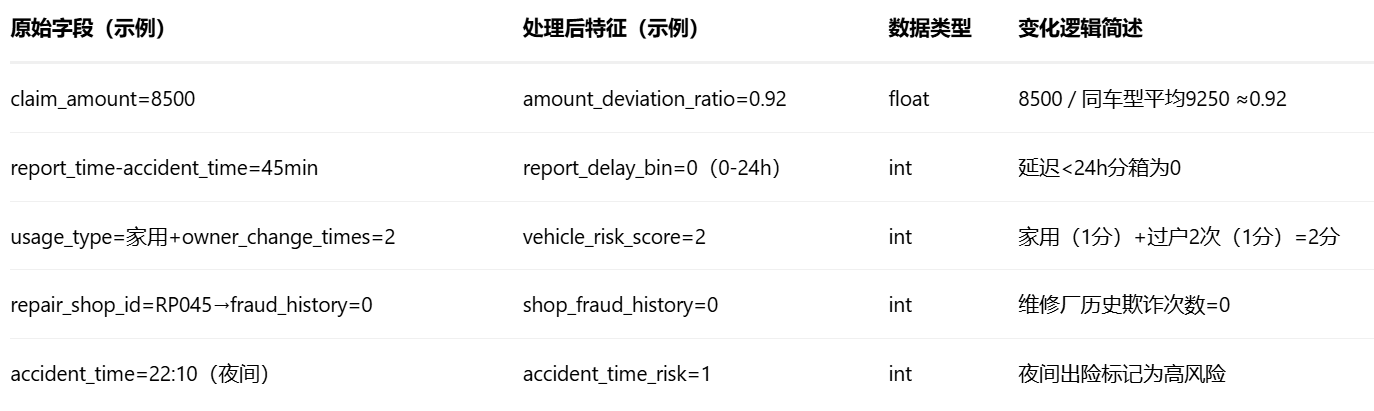
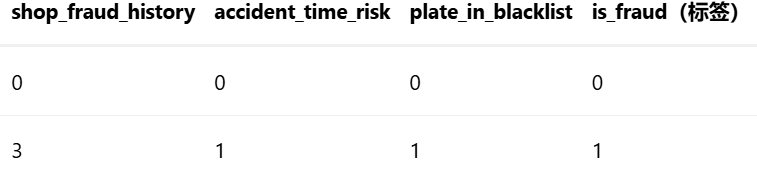
(3)处理后特征矩阵示例(算法团队输出)

代码结构
算法团队仓库(claims-fraud-algorithm)
text
claims-fraud-algorithm/
├── data_processing/ # 数据预处理(Spark/Scala)
│ ├── src/main/scala/com/insurer/
│ │ ├── DataCleaning.scala # 缺失值/异常值处理
│ │ └── FeatureEngineering.scala # 特征提取(含Target Encoding)
│ └── build.sbt # Scala依赖(Spark)
├── model_training/ # 模型训练(Python)
│ ├── train_random_forest.py # 随机森林训练(含交叉验证)
│ ├── evaluate_model.py # 评估指标(AUC/KS/混淆矩阵)
│ ├── feature_importance.py # SHAP特征重要性分析
│ └── requirements.txt # Python依赖
├── feature_store/ # 特征存储(Feast配置)
│ ├── feature_repo/
│ │ ├── features.py # 特征定义(实体:claim_id)
│ │ └── feature_store.yaml # Feast配置(在线/离线存储)
│ └── deploy_feature_store.sh # 部署脚本(到K8s)
├── mlflow_tracking/ # MLflow实验跟踪
│ ├── run_experiment.py # 启动实验并记录参数/指标
│ └── mlflow_server_config.yaml # MLflow服务配置
└── README.md # 算法文档(特征字典/模型参数)
python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.metrics import roc_auc_score, confusion_matrix
import shap
import mlflow
import joblib
from src.utils.logger import setup_logger # 自定义日志工具
logger = setup_logger(__name__)
def load_processed_features(feature_path:str)->tuple:
"""加载算法团队处理后的特征矩阵(含标签)"""
df = pd.read_parquet(feature_path) # 特征矩阵
X = df.drop(columns=["claim_id","is_fraud"])
y = df["is_fraud"] # 标签:1=欺诈,0=正常
return X, y
def train_random_forest(X:pd.DataFrame,y:pd.Series,params:dict) -> RandomForestClassifier:
"""
训练随机森林模型(带类别权重平衡)
Args:
X: 特征矩阵
y: 标签
params: 模型参数(n_estimators, max_depth等)
Returns:
训练好的随机森林模型
"""
model = RandomForestClassifier(
n_estimators=params["n_entimators"],# 树数量(默认100,调参后200)
max_depth=params["max_depth"], # 树最大深度(防过拟合,调参后10)
min_samples_split=params["min_samples_split"],# 分裂最小样本数(5)
class_weight="balanced",# 自动平衡类别权重(欺诈样本少则权重高)
random_state=42,
n_jobs=-1 #并行训练(-1用所有CPU核心)
)
# 5折分层交叉验证(保持欺诈/正常样本比例)
"""
n_splits=5:将数据分成5份,进行5折交叉验证
shuffle=True:拆分前先打乱数据顺序,防止原始数据顺序影响结果
random_state=42:设置随机种子,确保结果可复现
"""
cv = StratifiedKFold(n_splits=5,shuffle=True,random_state=42)
cv_scores = cross_val_score(model,X,y,cv=cv,scoring="roc_auc")# 将数据集分成5份,依次使用4份训练,1份测试 使用AUC-ROC作为评估指标
logger.info(f"交叉验证AUC: {cv_scores.mean():.4f} ± {cv_scores.std():.4f}")
# 训练最终模型
model.fit(X,y)
# 记录实验
with mlflow.start_run(run_name="random_forest_fraud_detection"):
mlflow.log_params(params)
mlflow.log_metric("cv_auc_mean", cv_scores.mean())
mlflow.log_metric("cv_auc_std", cv_scores.std())
mlflow.sklearn.log_model(model, "random_forest_model")
logger.info(f"模型训练完成,交叉验证AUC={cv_scores.mean():.4f}")
return model
def evaluate_model(model: RandomForestClassifier, X_test: pd.DataFrame, y_test: pd.Series)-> dict:
"""评估模型性能(AUC/KS/混淆矩阵)"""
y_pred_proba = model.predict_proba(X_test)[:, 1] # 欺诈概率
y_pred = model.predict(X_test) # 预测类别(阈值=0.5)
# 核心指标
auc = roc_auc_score(y_test,y_pred_proba)
ks = calculate_ks(y_test, y_pred_proba) # 自定义KS值计算(见下方)
cm = confusion_matrix(y_test, y_pred)
tn, fp, fn, tp = cm.ravel()
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
metrics = {
"AUC-ROC": auc, "KS": ks, "Precision": precision, "Recall": recall,
"ConfusionMatrix": {"TN": int(tn), "FP": int(fp), "FN": int(fn), "TP": int(tp)}
}
logger.info(f"模型评估结果: {metrics}")
return metrics
def calculate_ks(y_true:pd.Series,y_pred_proba:np.ndarray)->float:
"""计算KS值(区分欺诈/正常样本的能力)"""
df = pd.DataFrame({"y_true":y_true,"y_pred_proba":y_pred_proba})
df = df.sort_value("y_pred_proba",ascending=False).reset_index(drup=True)
df["cum_good"] = (1 - df["y_true"]).cumsum() / (1 - df["y_true"]).sum() # 累计正常样本占比
df["cum_bad"] = df["y_true"].cumsum() / df["y_true"].sum() # 累计欺诈样本占比
df["ks"] = df["cum_bad"] - df["cum_good"] # KS曲线差值
return df["ks"].max() # KS值为最大差值
def analyze_feature_importance(model: RandomForestClassifier, X: pd.DataFrame)-> None:
"""用SHAP分析特征重要性(算法团队输出给业务团队解释用)"""
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values[1],X,plot_type="bar") # 欺诈类(label=1)的特征重要性
logger.info("SHAP特征重要性分析完成,图表保存至mlruns/shap_summary.png")
if __name__ == "__main__":
# 加载特征矩阵
X,y = load_processed_features("data/processed/fraud_features.parquet")
# 划分训练集/测试集(分层抽样)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42, stratify=y)
# 模型参数(经网格搜索调优)
"""
n_estimators,表示随机森林中决策树的数量,值越大,模型越稳定,泛化能力越好。但计算时间也会增加,200是一个平衡值
max_depth,每个决策树的最大深度,控制树的复杂度。太深,容易过拟合;太浅,容易欠拟合
min_samples_split,节点分裂所需的最小样本树,如果一个节点的样本树小于5,就不再分裂,防止模型对噪声数据过度学习
实际会有多种组合,例如:
{
'n_estimators': [100, 200, 300],
'max_depth': [5, 10, 15],
'min_samples_split': [2, 5, 10]
}
"""
params = {"n_estimators": 200, "max_depth": 10, "min_samples_split": 5}
# 训练模型
model = train_random_forest(X_train,y_train,params)
# 评估模型
metrics = evaluate_model(model,X_test,y_test)
# 保存模型(供业务团队调用)
joblib.dump(model,"model/random_forest_fraud_model.pkl")
# 特征重要性分析
analyze_feature_importance(model,X_test)模型文件:model/random_forest_fraud_model.pkl(训练好的随机森林模型)
特征服务:Feast特征存储配置(feature_store/feature_repo/)、特征字典(FEATURE_DICTIONARY.md)
实验报告:MLflow记录的模型参数(n_estimators=200, max_depth=10)、评估指标(AUC=0.93, KS=0.68, Precision=0.89, Recall=0.91)、SHAP特征重要性图表
dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY feature_store/feature_repo ./feature_repo
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt # 含feast==0.34
EXPOSE 6566 # Feast gRPC端口
CMD ["feast", "serve", "--port", "6566"] # 启动特征服务业务团队仓库(claims-fraud-business)
text
claims-fraud-business/
├── api_gateway/ # API网关(Kong配置)
│ ├── kong.yml # 路由规则(转发至欺诈检测服务)
│ └── plugins/ # 认证/限流插件
├── fraud_detection_service/ # 欺诈检测微服务(FastAPI)
│ ├── main.py # 服务入口(加载模型/特征客户端)
│ ├── predictor.py # 调用算法团队的模型和特征服务
│ ├── schemas.py # 请求/响应模型(Pydantic)
│ └── requirements.txt # Python依赖(含grpcio)
├── monitoring/ # 监控配置
│ ├── prometheus_rules.yml # 告警规则(如AUC<0.9触发告警)
│ └── grafana_dashboards/ # 可视化面板(API延迟/QPS)
├── deployment/ # 部署配置(K8s)
│ ├── fraud-detection-deployment.yaml # Deployment配置(副本数3)
│ └── service.yaml # Service配置(ClusterIP)
└── README.md # 业务文档(API调用示例)
python
import grpc
import joblib
import pandas as pd
from concurrent import futures
from feast import FeatureStore # 调用算法团队的特征服务
from src.schemas import ClaimRequest,FraudPredictionResponse # Pydantic模型(请求/响应)
from src.utils.logger import setup_logger
logger = setup_logger(__name__)
class FraudPredictor:
def __init__(self,model_path:str,feature_store_config:str):
"""初始化预测器:加载算法团队的模型和特征服务客户端"""
self.model = joblib.load(model_path) #加载随机森林模型
self.feature_store = FeatureStore(repo_path=feature_store_config) # 连接Feast特征存储
logger.info("欺诈预测器初始化完成:模型加载成功,特征服务连接成功")
def get_online_features(self, claim_id: str) -> pd.DataFrame:
"""调用算法团队的特征服务,获取实时特征(在线特征)"""
# 定义特征视图(与算法团队的Feast配置一致)
feature_refs = [
"has_fraud_history", "claim_freq_1y", "amount_deviation_ratio",
"report_delay_bin", "vehicle_risk_score", "shop_fraud_history"
]
# 从Feast获取实时特征(实体:claim_id)
feature_vector = self.feature_store.get_online_features(
entity_rows=[{"claim_id": claim_id}],
features=feature_refs
).to_dict()
return pd.DataFrame(feature_vector)
def predict(self, claim_request: ClaimRequest) -> FraudPredictionResponse:
"""核心预测逻辑:融合请求参数与特征服务数据,调用模型预测"""
try:
# 1. 从请求中获取claim_id(业务系统传入的唯一标识)
claim_id = claim_request.claim_id
# 2. 调用特征服务获取实时特征(算法团队维护)
online_features = self.get_online_features(claim_id)
if online_features.empty:
raise ValueError(f"特征服务未找到claim_id={claim_id}的特征")
# 3. 融合请求参数中的非特征字段(如accident_time_risk需实时计算)
# (注:部分特征需业务系统实时计算,如夜间出险标记)
accident_hour = pd.to_datetime(claim_request.accident_time).hour
accident_time_risk = 1 if (22 <= accident_hour or accident_hour < 6) else 0
# 4. 构造模型输入特征向量(与算法团队训练时一致)
feature_vector = online_features.copy()
feature_vector["accident_time_risk"] = accident_time_risk # 补充实时特征
feature_vector = feature_vector[self.model.feature_names_in_] # 按模型训练时的特征顺序排列
# 5. 调用随机森林模型预测欺诈概率
fraud_prob = self.model.predict_proba(feature_vector)[0][1] # 欺诈类概率(label=1)
risk_level = "高风险" if fraud_prob > 0.7 else "中风险" if fraud_prob > 0.4 else "低风险"
# 6. 构造响应(含解释性信息,基于算法团队的SHAP结果)
response = FraudPredictionResponse(
claim_id=claim_id,
fraud_probability=round(fraud_prob, 4),
risk_level=risk_level,
key_factors=[ # 基于算法团队的SHAP特征重要性(示例)
{"factor": "历史欺诈标记", "impact": "正向影响", "shap_value": 0.32},
{"factor": "理赔金额偏离度", "impact": "正向影响", "shap_value": 0.28},
{"factor": "维修厂欺诈历史", "impact": "正向影响", "shap_value": 0.25}
],
timestamp=pd.Timestamp.now().isoformat()
)
logger.info(f"预测完成:claim_id={claim_id}, 欺诈概率={fraud_prob:.4f}")
return response
except Exception as e:
logger.error(f"预测失败:claim_id={claim_request.claim_id}, 错误={str(e)}", exc_info=True)
raise
dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY fraud_detection_service/ ./
COPY model/random_forest_fraud_model.pkl ./model/
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt # 含fastapi, uvicorn, feast
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "4"] # 4个工作进程
yml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: fraud-detection-service
spec:
replicas: 3 # 3副本负载均衡
selector:
matchLabels:
app: fraud-detection
template:
metadata:
labels:
app: fraud-detection
spec:
containers:
- name: fraud-detection
image: insurer/fraud-detection-service:v1.0 # 业务团队镜像
ports:
- containerPort: 8000
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "1"
memory: "2Gi"
livenessProbe: # 健康检查
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: fraud-detection-service
spec:
selector:
app: fraud-detection
ports:
- port: 80
targetPort: 8000
type: ClusterIP应用
①、实时欺诈检测(理赔申请提交时触发)
理赔审核系统调用业务团队的API网关(https://api.insurer.com/fraud/predict),传入理赔申请信息(claim_id、accident_time、claim_amount等)
bash
curl -X POST https://api.insurer.com/fraud/predict \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <TOKEN>" \ # 认证令牌
-d '{
"claim_id": "CLM003",
"accident_time": "2023-07-15T23:30:00", # 夜间出险(实时特征)
"claim_amount": 15000,
"policy_id": "POL789",
"vehicle_id": "VH202"
}'②、分级处置决策
API返回欺诈概率(如0.82)和风险等级(高风险),理赔系统按规则决策:
- 自动拒赔:欺诈概率>0.7(高风险),触发自动拒赔并标记欺诈嫌疑
- 人工复核:0.4<欺诈概率≤0.7(中风险),分配至资深审核员重点核查(如维修厂资质、事故照片真实性)
- 自动通过:欺诈概率≤0.4(低风险),进入正常赔付流程
③、监控与迭代
实时监控:Prometheus采集API响应时间、QPS、错误率,Grafana展示;监控模型预测分布(PSI指标),若PSI>0.25(特征分布漂移)触发告警
模型迭代:算法团队每月用新数据增量训练,每季度全量重训;若AUC连续2周<0.9,自动触发重训流程(Airflow调度)
业务反馈闭环:风控团队每周分析误判案例(如"真实欺诈但被误判为正常"),反馈至算法团队优化特征(如增加"报案人与被保险人关系"特征)