从架构设计到底层实现,全面解析Apache Kafka的核心原理
目录
- 一、Kafka架构概览
- [1.1 什么是Kafka](#1.1 什么是Kafka)
- [1.2 核心组件与架构](#1.2 核心组件与架构)
- [1.3 应用场景](#1.3 应用场景)
- 二、核心数据结构与存储机制
- [2.1 Topic、Partition和Offset](#2.1 Topic、Partition和Offset)
- [2.2 日志存储结构](#2.2 日志存储结构)
- [2.3 索引机制](#2.3 索引机制)
- [2.4 消息格式演进](#2.4 消息格式演进)
- 三、高性能设计原理
- [3.1 顺序写入的威力](#3.1 顺序写入的威力)
- [3.2 零拷贝技术](#3.2 零拷贝技术)
- [3.3 PageCache的妙用](#3.3 PageCache的妙用)
- [3.4 批量处理与压缩](#3.4 批量处理与压缩)
- 四、高可用与可靠性保证
- [4.1 副本机制](#4.1 副本机制)
- [4.2 ISR机制深度解析](#4.2 ISR机制深度解析)
- [4.3 Leader选举与Controller](#4.3 Leader选举与Controller)
- [4.4 如何保证消息不丢失](#4.4 如何保证消息不丢失)
- 五、生产者与消费者深度解析
- [5.1 生产者工作原理](#5.1 生产者工作原理)
- [5.2 ACKS机制详解](#5.2 ACKS机制详解)
- [5.3 消费者模型](#5.3 消费者模型)
- [5.4 Rebalance机制](#5.4 Rebalance机制)
- 六、消息语义与性能优化
- [6.1 消息传递语义](#6.1 消息传递语义)
- [6.2 Exactly-Once实现](#6.2 Exactly-Once实现)
- [6.3 性能监控与调优](#6.3 性能监控与调优)
- [6.4 故障排查指南](#6.4 故障排查指南)
一、Kafka架构概览
1.1 什么是Kafka
Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发并于2011年开源。它被设计用于处理大规模实时数据流,具有高吞吐量、低延迟、可扩展和高可用的特性。
Kafka的核心能力包括:
- 消息队列:作为传统消息队列的替代品,支持发布-订阅模式
- 存储系统:可以持久化存储海量数据流,并允许按需回溯
- 流处理:通过Kafka Streams API进行实时流计算
与传统消息队列相比,Kafka的独特之处在于:
- 数据持久化:所有消息都持久化到磁盘,支持消息回溯
- 高吞吐量:单机即可支持百万级TPS
- 水平扩展:通过增加Broker和分区轻松扩容
- 顺序保证:在分区级别保证消息顺序
1.2 核心组件与架构
Kafka的架构由以下核心组件构成:
📥 消费者集群 Consumer Groups 👥 Consumer Group 1 👤 Consumer Group 2 🔧 协调服务 Coordination 🚀 Kafka集群 (3节点) 🖥️ Broker 1 🖥️ Broker 2 🖥️ Broker 3 📤 生产者集群 Producer Cluster 写入消息 写入消息 写入消息 同步复制 同步复制 同步复制 同步复制 消费消息 消费消息 消费消息 消费消息 1. 元数据同步 2. 分区状态 3. 消费者组管理 3. 消费者组管理 3. 消费者组管理 Consumer-3
分配: TopicA-P0, TopicA-P1 Consumer-1
分配: TopicA-P0 Consumer-2
分配: TopicA-P1 ZooKeeper Ensemble
元数据管理
控制器选举
分区分配 TopicA-P0
Follower TopicA-P1
Follower TopicA-P0
Follower TopicA-P1
Leader TopicA-P0
Leader TopicB-P0
Follower Producer 1 Producer 2 Producer N
核心组件详解
1. Producer (生产者)
- 负责向Kafka发布消息
- 可以选择发送到哪个分区(通过key hash或自定义分区器)
- 支持同步和异步发送
2. Broker (代理服务器)
- Kafka集群由多个Broker组成
- 每个Broker是一个独立的服务器进程
- 负责接收、存储和转发消息
- 一个Broker可以管理多个分区
3. Topic (主题)
- 消息的逻辑分类
- 类似于数据库中的表
- 一个Topic可以有多个分区
4. Partition (分区)
- Topic的物理分片
- 每个分区是一个有序的、不可变的消息序列
- 分区是实现并行处理和水平扩展的基础
- 每个分区有唯一的Leader和多个Follower副本
5. Consumer (消费者)
- 从Kafka订阅并消费消息
- 消费者通过Consumer Group实现负载均衡
- 每个消费者维护自己的消费位置(Offset)
6. Consumer Group (消费者组)
- 多个消费者组成的逻辑组
- 一个分区只能被组内一个消费者消费(独占模式)
- 不同组之间互不影响(广播模式)
7. ZooKeeper
- 管理Kafka集群元数据
- 负责Controller选举
- 维护Broker列表、Topic配置等
- 注意:从Kafka 2.8开始,可以使用KRaft模式替代ZooKeeper
1.3 应用场景
Kafka在企业架构中的典型应用场景:
1. 消息解耦
发布订单事件 订阅 订阅 订阅 订阅 订单服务 Kafka 库存服务 支付服务 物流服务 营销服务
2. 日志聚合
- 收集各个服务的日志,统一存储和分析
- 支持ELK (Elasticsearch + Logstash + Kibana) 架构
3. 实时流处理
- 实时推荐系统
- 实时监控告警
- 实时数据分析
4. 事件溯源 (Event Sourcing)
- 存储完整的事件流
- 支持状态回溯和重放
5. 数据管道
- 连接不同的数据系统
- 作为数据湖的入口
二、核心数据结构与存储机制
2.1 Topic、Partition和Offset
Topic的分区设计
Topic是逻辑概念,而Partition是物理实现。一个Topic由一个或多个Partition组成:
消息分配逻辑 Topic: order_events hash分配 hash分配 hash分配 Message
key=user123 Message
key=user456 Message
key=user789 Partition 0
Offset: 0-1000 Partition 1
Offset: 0-1200 Partition 2
Offset: 0-800
为什么需要分区?
- 并行处理:多个消费者可以并行消费不同分区
- 水平扩展:分区可以分布在不同的Broker上
- 顺序保证:同一分区内的消息严格有序
- 负载均衡:消息通过key hash分散到不同分区
Offset的概念
Offset是消息在分区中的唯一标识,是一个单调递增的64位整数:
Partition 0:
Offset: 0 1 2 3 4 5 6 7
┌────┬────┬────┬────┬────┬────┬────┬────┐
Message │ M0 │ M1 │ M2 │ M3 │ M4 │ M5 │ M6 │ M7 │
└────┴────┴────┴────┴────┴────┴────┴────┘
↑ ↑
│ │
Current Offset LEO
(消费者位置) (Log End Offset)关键Offset术语:
- LEO (Log End Offset):分区下一条待写入消息的offset
- HW (High Watermark):已提交消息的最高offset,消费者只能读到HW之前的消息
- Consumer Offset:消费者当前消费到的位置
2.2 日志存储结构
Segment文件组织
Kafka将每个分区的日志分割成多个Segment,每个Segment由三个文件组成:
/kafka-logs/topic-0/
├── 00000000000000000000.log # 消息数据文件
├── 00000000000000000000.index # 偏移量索引文件
├── 00000000000000000000.timeindex # 时间戳索引文件
├── 00000000000000368769.log
├── 00000000000000368769.index
├── 00000000000000368769.timeindex
├── 00000000000000737337.log
├── 00000000000000737337.index
└── 00000000000000737337.timeindexSegment命名规则:
- 文件名是该Segment的第一条消息的offset
- 当.log文件达到阈值(默认1GB)时,滚动创建新的Segment
- 只有最后一个Segment是活跃的(Active Segment),其他都是只读的
Log文件格式
每条消息在.log文件中的存储格式(简化版):
┌────────────────────────────────────────────────────┐
│ Offset (8 bytes) │
├────────────────────────────────────────────────────┤
│ Message Size (4 bytes) │
├────────────────────────────────────────────────────┤
│ CRC32 (4 bytes) - 消息校验码 │
├────────────────────────────────────────────────────┤
│ Magic Byte (1 byte) - 消息格式版本 │
├────────────────────────────────────────────────────┤
│ Attributes (1 byte) - 压缩类型等属性 │
├────────────────────────────────────────────────────┤
│ Timestamp (8 bytes) │
├────────────────────────────────────────────────────┤
│ Key Length (4 bytes) │
├────────────────────────────────────────────────────┤
│ Key (可变长度) │
├────────────────────────────────────────────────────┤
│ Value Length (4 bytes) │
├────────────────────────────────────────────────────┤
│ Value (可变长度) - 实际消息内容 │
└────────────────────────────────────────────────────┘2.3 索引机制
Kafka采用稀疏索引来加速消息查找。
稀疏索引原理
.index文件不为每条消息建立索引,而是每隔若干条消息建立一个索引条目:
.log文件 (实际消息) .index文件 (稀疏索引)
┌──────────────────┐ ┌──────────────────┐
│ Offset: 0 │ │ 0 -> Position 0 │
│ Offset: 1 │ │ │
│ Offset: 2 │ │ │
│ Offset: 3 │ │ │
│ Offset: 4 │ │ 4 -> Position 512│
│ Offset: 5 │ │ │
│ Offset: 6 │ │ │
│ Offset: 7 │ │ │
│ Offset: 8 │ │ 8 -> Position 1024│
└──────────────────┘ └──────────────────┘查找流程(例如查找offset=6的消息):
- 通过文件名确定Segment(二分查找)
- 在.index文件中二分查找,找到 offset=4 -> Position 512
- 从Position 512开始在.log文件中顺序扫描,直到找到offset=6
为什么使用稀疏索引?
- 索引文件小,可以全部加载到内存
- 顺序扫描的成本很低(通常只需扫描几条消息)
- 平衡了空间和查找效率
2.4 消息格式演进
Kafka的消息格式经历了多个版本的演进:
V0 (Kafka 0.10之前)
- 最基础的格式
- 不支持时间戳
V1 (Kafka 0.10.0)
- 增加了时间戳字段
- 支持基于时间的索引和保留策略
V2 (Kafka 0.11.0+,目前主流)
- 支持幂等性和事务
- 增加了Producer ID、Sequence Number等字段
- 改进了压缩效率(批量压缩)
消息批次压缩:
在V2格式中,Kafka在Producer端对一批消息进行整体压缩:
Consumer端 Broker端 Producer端 拉取压缩数据 解压缩 处理消息 直接存储压缩数据 Message Batch Message 1 Message 2 Message 3 压缩 发送到Broker
这种设计的优势:
- Broker不需要解压缩,降低CPU开销
- 批量压缩比单条压缩效率更高
- 减少网络传输和磁盘存储
三、高性能设计原理
Kafka之所以能够实现百万级TPS的高吞吐量,得益于多项精妙的设计。
3.1 顺序写入的威力
顺序I/O vs 随机I/O
磁盘的顺序I/O性能远超随机I/O:
性能对比 (SATA HDD):
┌──────────────┬──────────────┐
│ 顺序写入 │ 600 MB/s │
├──────────────┼──────────────┤
│ 随机写入 │ 100 KB/s │
└──────────────┴──────────────┘
性能差距: 约6000倍Kafka的设计哲学:
传统数据库使用B-Tree等数据结构,导致大量随机I/O。Kafka反其道而行之:
- 消息只追加到日志文件末尾(Append-Only)
- 不支持修改已写入的消息
- 利用操作系统的预读(Read-Ahead)和后写(Write-Behind)机制
Kafka 传统数据库 顺序I/O 写入 600 MB/s 随机I/O 写入 100 KB/s
3.2 零拷贝技术
传统数据传输的问题
传统方式下,从磁盘读取数据并通过网络发送,需要经历4次数据拷贝:
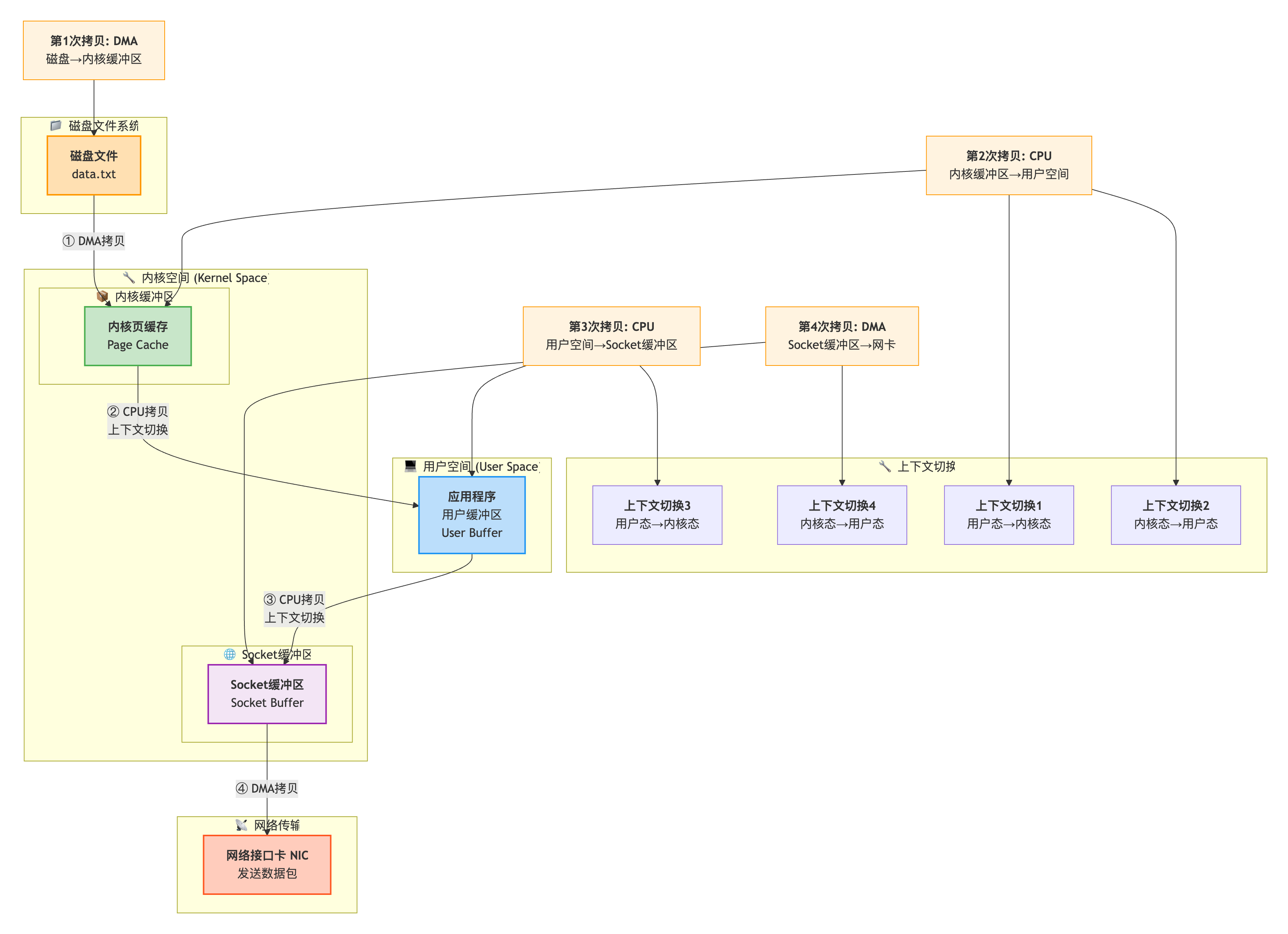
sendfile系统调用
Kafka使用Linux的sendfile()系统调用,实现零拷贝:
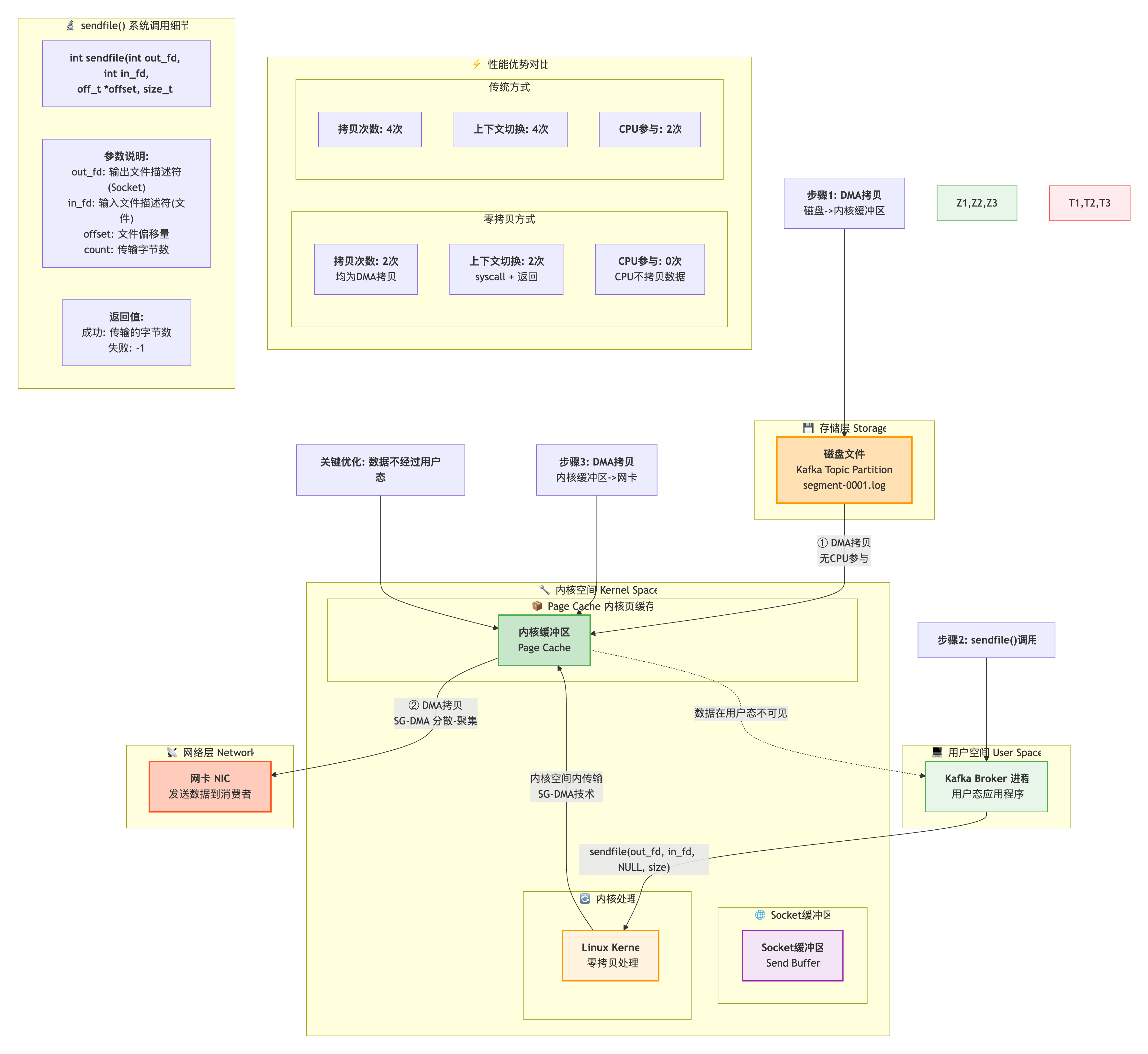
性能提升:
- 减少2次CPU拷贝
- 减少2次上下文切换
- 不占用应用程序内存
- 在大数据量传输时,性能提升明显
3.3 PageCache的妙用
PageCache机制
Kafka不维护自己的缓存,而是完全依赖操作系统的PageCache:
存储层 操作系统 Kafka Broker 应用层 cache miss load 磁盘存储 PageCache
热数据缓存 写入操作 读取操作 生产者 消费者
PageCache的优势:
- 统一管理:操作系统比应用程序更了解内存使用情况
- 自动预读:操作系统会预读后续数据到PageCache
- 进程间共享:多个进程可以共享同一份PageCache
- 进程重启不丢失:PageCache在进程重启后仍然有效
生产-消费模式的最佳场景:
时间轴:
t0: Producer写入消息 → PageCache (内存)
t1: Consumer读取消息 ← PageCache (内存)
如果消费延迟不大,几乎所有读操作都命中PageCache,
实现了"零磁盘读取"的效果。3.4 批量处理与压缩
批量发送机制
Producer不会每条消息单独发送,而是批量打包后发送:
java
// Producer配置
Properties props = new Properties();
props.put("batch.size", 16384); // 批次大小 16KB
props.put("linger.ms", 10); // 等待时间 10ms
props.put("compression.type", "lz4"); // 压缩算法
// 触发发送的条件 (满足任一即发送):
// 1. batch.size 达到 16KB
// 2. linger.ms 等待 10ms 超时
// 3. 手动调用 flush()批量发送的好处:
- 减少网络请求次数(TCP握手开销)
- 提高压缩效率
- 摊薄每条消息的元数据开销
压缩算法对比
Kafka支持多种压缩算法,各有特点:
| 压缩算法 | 压缩率 | CPU开销 | 适用场景 |
|---|---|---|---|
| GZIP | 高 | 高 | 网络带宽受限,CPU充足 |
| Snappy | 中 | 低 | 平衡性能和压缩率 |
| LZ4 | 中 | 极低 | 低延迟要求 (推荐) |
| Zstd | 高 | 中 | Kafka 2.1+新增,综合性能优秀 |
压缩在何处发生?
压缩后发送 存储压缩数据 传输压缩数据 解压缩 Producer Broker Disk Consumer Application
Broker不会解压缩消息,保持压缩状态存储和传输,大大降低了:
- 网络带宽消耗
- 磁盘存储空间
- Broker的CPU开销
四、高可用与可靠性保证
4.1 副本机制
Kafka通过**副本机制(Replication)**来保证数据的高可用性和持久性。
副本角色划分
每个分区都有多个副本,分为:
Topic: order_events, Partition 0 写入 读取 同步 同步 Leader Replica
Broker 1
处理读写请求 Follower Replica
Broker 2
只同步数据 Follower Replica
Broker 3
只同步数据 Producer Consumer
角色说明:
- Leader:处理所有的读写请求,每个分区有且仅有一个Leader
- Follower:只负责从Leader同步数据,不处理客户端请求
- 当Leader宕机时,会从Follower中选举新的Leader
为什么读写都在Leader?
这种设计简化了一致性保证:
- 避免了多写者的并发控制问题
- 消费者读取的数据一定是最新的(从Leader读)
- 副本之间的同步逻辑简单(单向拉取)
副本分配策略
Kafka在创建Topic时,会智能地分配副本到不同Broker:
假设有3个Broker,Topic有3个分区,副本因子=3
Partition 0: Leader=Broker0, Follower=[Broker1, Broker2]
Partition 1: Leader=Broker1, Follower=[Broker2, Broker0]
Partition 2: Leader=Broker2, Follower=[Broker0, Broker1]
目标:
1. Leader均匀分布(负载均衡)
2. 同一分区的副本分散在不同Broker(容错)
3. 同一分区的副本分散在不同机架(机架感知)4.2 ISR机制深度解析
什么是ISR
ISR (In-Sync Replicas) 是指与Leader保持同步的副本集合,是Kafka高可用的核心机制。
非ISR ISR集合 同步快 同步快 同步慢 Follower 3
LEO=50
落后太多 Leader
LEO=100 Follower 1
LEO=100 Follower 2
LEO=99
关键概念:
- LEO (Log End Offset):每个副本的最后一条消息的offset + 1
- HW (High Watermark):ISR中最小的LEO,表示已提交的消息边界
- 只有ISR中的副本才有资格成为新的Leader
ISR的动态维护
ISR不是静态的,Kafka会根据副本的同步情况动态调整:
java
// 判断副本是否应该留在ISR的条件:
replica.lag.time.max.ms = 10000 // 默认10秒
if (currentTime - lastCaughtUpTime > replica.lag.time.max.ms) {
// 副本超过10秒未追上Leader,从ISR中移除
removeFromISR(replica);
}
if (replica.LEO >= leader.HW) {
// 副本追上了Leader,重新加入ISR
addToISR(replica);
}ISR变化示例:
初始状态: ISR = [Leader, Follower1, Follower2]
t1: Follower2网络故障,停止同步
超过10秒后 → ISR = [Leader, Follower1]
t2: Follower2恢复,开始追赶
追上Leader后 → ISR = [Leader, Follower1, Follower2]
t3: Leader宕机
从ISR中选举新Leader → Follower1成为新Leader
ISR = [Follower1(new Leader), Follower2]HW与LEO的更新机制
这是理解Kafka可靠性的关键:
时间线:生产者发送一条消息
t0: Leader收到消息,写入本地日志
Leader.LEO = 101
Leader.HW = 100 (暂不更新)
t1: Follower1拉取消息,写入本地
Follower1.LEO = 101
Leader.HW = 100 (等待所有ISR副本)
t2: Follower2拉取消息,写入本地
Follower2.LEO = 101
Leader.HW = 101 (所有ISR副本都同步了)
→ 消息对消费者可见
关键规则:
- HW = min(所有ISR副本的LEO)
- 消费者只能读到HW之前的消息
- acks=all时,必须等HW更新才返回成功4.3 Leader选举与Controller
Controller的角色
Kafka集群中有一个特殊的Broker被选举为Controller,负责管理整个集群:
Kafka Cluster 选举 分配分区 选举Leader 监控状态 监控状态 Controller
Broker 0
管理者 Broker 1
普通节点 Broker 2
普通节点 ZooKeeper
Controller的职责:
- 监控Broker状态:通过ZooKeeper监听Broker的上下线
- 分区Leader选举:当Leader宕机时,从ISR中选举新Leader
- 分区重新分配:执行分区迁移和副本调整
- Topic管理:创建、删除Topic,修改配置
- 元数据同步:将元数据变更同步到所有Broker
Leader选举流程
当分区的Leader宕机时,Controller负责选举新的Leader:
触发条件: Broker 1 (Leader of Partition 0) 宕机
Step 1: ZooKeeper通知Controller,Broker 1下线
Step 2: Controller查询该Broker上的所有Leader分区
发现 Partition 0 需要重新选举
Step 3: 从ISR中选择新Leader
ISR = [Broker2, Broker3]
选择策略: 优先选择ISR中的第一个存活副本
新Leader = Broker 2
Step 4: Controller更新元数据
- 更新ZooKeeper中的Leader信息
- 向所有Broker发送UpdateMetadata请求
Step 5: 新Leader开始接受读写请求
客户端自动切换到新Leader优化:Preferred Leader选举
Kafka支持**优选Leader(Preferred Leader)**机制:
java
// Topic创建时的初始状态
Partition 0: Replicas=[Broker0, Broker1, Broker2]
PreferredLeader=Broker0 // 第一个副本
// Broker0宕机后
Partition 0: Leader=Broker1 // 临时Leader
// Broker0恢复后,自动触发选举
Partition 0: Leader=Broker0 // 恢复到优选Leader
配置:
auto.leader.rebalance.enable = true这样可以保持集群的负载均衡。
Controller选举
Controller本身也可能宕机,需要重新选举:
Broker 0 (Current Controller) ZooKeeper Broker 1 Broker 2 心跳断开 通知Controller失效 通知Controller失效 尝试创建/controller节点 尝试创建/controller节点 创建成功 (竞争成功) 创建失败 (已存在) 成为新Controller 同步元数据 Broker 0 (Current Controller) ZooKeeper Broker 1 Broker 2
Controller选举采用抢占式:
- 谁先在ZooKeeper中创建
/controller临时节点,谁就是Controller - 其他Broker监听该节点,等待下次选举机会
4.4 如何保证消息不丢失
这是一个综合性问题,需要从三个环节保证:
生产者端保证
java
// 1. ACK机制配置
props.put("acks", "all"); // 等待所有ISR副本确认
// 2. 开启幂等性
props.put("enable.idempotence", true); // 防止网络重试导致重复
// 3. 设置合理的重试次数
props.put("retries", Integer.MAX_VALUE); // 无限重试
// 4. 设置重试间隔
props.put("retry.backoff.ms", 100);
// 5. 设置超时时间
props.put("request.timeout.ms", 30000);
props.put("delivery.timeout.ms", 120000);
// 6. 发送时处理异常
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// 记录失败日志,触发告警
log.error("Failed to send message", exception);
// 可以写入失败队列,后续重试
failedQueue.add(record);
}
});Broker端保证
properties
# 1. 副本因子至少为3
replication.factor = 3
# 2. 最小同步副本数
min.insync.replicas = 2 # 至少2个副本同步成功
# 3. 关闭自动创建Topic(避免误操作)
auto.create.topics.enable = false
# 4. 禁用不完整副本选举
unclean.leader.election.enable = false # 不允许非ISR副本成为Leader
# 5. 合理设置刷盘策略
log.flush.interval.messages = 10000
log.flush.interval.ms = 1000
# 注意:依赖操作系统刷盘即可,过度刷盘影响性能消费者端保证
java
// 1. 关闭自动提交
props.put("enable.auto.commit", false);
// 2. 手动提交offset
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try {
// 处理业务逻辑
processRecord(record);
// 写入数据库
saveToDatabase(record);
} catch (Exception e) {
// 处理失败,不提交offset,下次重新消费
log.error("Process failed, will retry", e);
break;
}
}
// 只有在所有消息处理成功后才提交
consumer.commitSync();
}
// 3. 设置合理的消费超时
props.put("max.poll.interval.ms", 300000); // 5分钟
// 4. 启用消费者组隔离级别(配合事务使用)
props.put("isolation.level", "read_committed");完整的不丢失架构
重要配置总结:
| 层级 | 配置项 | 推荐值 | 说明 |
|---|---|---|---|
| Producer | acks | all | 所有ISR确认 |
| Producer | enable.idempotence | true | 幂等写入 |
| Producer | retries | 高值 | 重试次数 |
| Broker | replication.factor | 3 | 副本数量 |
| Broker | min.insync.replicas | 2 | 最小同步副本 |
| Broker | unclean.leader.election.enable | false | 禁止非ISR选举 |
| Consumer | enable.auto.commit | false | 手动提交 |
| Consumer | isolation.level | read_committed | 事务隔离 |
五、生产者与消费者深度解析
5.1 生产者工作原理
消息发送流程
Producer发送消息的完整流程:
应用程序 拦截器 序列化器 分区器 RecordAccumulator (累加器) Sender线程 Broker send(record) 拦截处理 序列化 计算分区 追加到Batch 等待条件: 1. batch.size达到 2. linger.ms超时 批量发送 网络请求 响应 回调通知 应用程序 拦截器 序列化器 分区器 RecordAccumulator (累加器) Sender线程 Broker
核心组件详解:
- 拦截器(Interceptor)
java
// 自定义拦截器,统计发送量、审计、修改消息等
public class MyInterceptor implements ProducerInterceptor<String, String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 发送前处理,例如添加时间戳
return new ProducerRecord<>(
record.topic(),
record.key(),
record.value() + "|timestamp=" + System.currentTimeMillis()
);
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 响应后处理,例如统计成功率
}
}- 序列化器(Serializer)
java
// 内置序列化器
StringSerializer, ByteArraySerializer, IntegerSerializer
// 自定义序列化器
public class UserSerializer implements Serializer<User> {
@Override
public byte[] serialize(String topic, User data) {
// JSON/Avro/Protobuf等序列化
return JSON.toJSONBytes(data);
}
}- 分区器(Partitioner)
java
// 默认分区策略
if (record.partition() != null) {
// 1. 明确指定分区
return record.partition();
} else if (record.key() != null) {
// 2. 根据key的hash值分配
return hash(record.key()) % numPartitions;
} else {
// 3. 轮询(Sticky Partitioner)
return stickyPartition();
}
// 自定义分区器
public class MyPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 例如:VIP用户发到专属分区
if (isVipUser(key)) {
return 0; // VIP专属分区
}
return hash(key) % (cluster.partitionCountForTopic(topic) - 1) + 1;
}
}- RecordAccumulator(累加器)
这是批量发送的核心:
RecordAccumulator结构:
Topic: order_events
├── Partition 0
│ ├── Batch 1 [M1, M2, M3] - 12KB
│ └── Batch 2 [M4, M5] - 8KB (未满)
├── Partition 1
│ └── Batch 1 [M6, M7, M8, M9] - 16KB (已满)
└── Partition 2
└── Batch 1 [M10] - 2KB (未满)
Sender线程会发送:
- Partition 1的Batch 1 (已满16KB)
- Partition 0的Batch 1 (已满12KB)
- 等待Partition 0 Batch 2和Partition 2 Batch 1达到条件5.2 ACKS机制详解
ACKS参数控制生产者的可靠性级别:
acks=0 (不等待确认)
Producer Leader Follower 1 Follower 2 发送消息 立即返回成功 不等待任何确认 写入本地 同步 同步 Producer Leader Follower 1 Follower 2
特点:
- 最高性能
- 最低可靠性
- 可能丢失消息
- 适用场景:日志收集、指标采集(允许少量丢失)
acks=1 (等待Leader确认)
Producer Leader Follower 1 Follower 2 发送消息 写入本地 返回成功 异步同步 同步 同步 Producer Leader Follower 1 Follower 2
特点:
- 中等性能
- 中等可靠性
- Leader宕机前未同步到Follower会丢失
- 默认配置
acks=all (等待所有ISR确认)
Producer Leader Follower 1 Follower 2 发送消息 写入本地 同步 同步 par 并行同步 确认 确认 所有ISR副本 都确认后 返回成功 Producer Leader Follower 1 Follower 2
特点:
- 最高可靠性
- 最低性能
- 需配合
min.insync.replicas使用 - 适用场景:订单、支付等核心业务
性能对比:
基准测试 (10万条消息,消息大小1KB):
acks=0: 耗时 1.2秒 (83,333 TPS)
acks=1: 耗时 2.5秒 (40,000 TPS)
acks=all: 耗时 4.8秒 (20,833 TPS)
可靠性 vs 性能 是经典的权衡5.3 消费者模型
Consumer Group机制
Consumer Group是Kafka实现负载均衡和广播的关键:
Consumer Group: analytics Consumer Group: order-processor Topic: order_events (4个分区) Consumer 3 Consumer 4 Consumer 5 Consumer 1 Consumer 2 Partition 0 Partition 1 Partition 2 Partition 3
核心规则:
- 组内独占:一个分区只能被组内一个消费者消费
- 组间独立:不同组可以重复消费同一分区
- 自动负载均衡:消费者数量变化时自动Rebalance
- 消费进度隔离:不同组维护各自的offset
消费者数量与分区数的关系:
场景1: 消费者 < 分区 (推荐)
Partition 0 → Consumer 1
Partition 1 → Consumer 1
Partition 2 → Consumer 2
Partition 3 → Consumer 2
充分利用并行性
场景2: 消费者 = 分区 (理想)
Partition 0 → Consumer 1
Partition 1 → Consumer 2
Partition 2 → Consumer 3
Partition 3 → Consumer 4
最佳并行度
场景3: 消费者 > 分区 (浪费)
Partition 0 → Consumer 1
Partition 1 → Consumer 2
Partition 2 → Consumer 3
Partition 3 → Consumer 4
Consumer 5 → 空闲 (浪费资源)分区分配策略
Kafka支持多种分区分配策略:
1. Range策略(默认)
按分区范围分配:
Topic A: 7个分区
Consumer 1: [0, 1, 2, 3] # 7/2=3余1,第一个消费者多分配
Consumer 2: [4, 5, 6]
优点:简单
缺点:可能不均衡(多Topic时更明显)2. RoundRobin策略
轮询分配:
Topic A: 3个分区 [A0, A1, A2]
Topic B: 3个分区 [B0, B1, B2]
Consumer 1: [A0, A2, B1]
Consumer 2: [A1, B0, B2]
优点:均衡
缺点:可能打乱分区的有序性3. Sticky策略(推荐)
粘性分配,尽量保持原有分配:
初始分配:
Consumer 1: [P0, P1]
Consumer 2: [P2, P3]
Consumer 2下线后:
Consumer 1: [P0, P1, P2, P3] # Sticky会保留P0,P1
重新上线Consumer 2:
Consumer 1: [P0, P1] # 保持不变
Consumer 2: [P2, P3] # 重新分配
优点:减少不必要的分区迁移,减少Rebalance影响4. CooperativeSticky策略(Kafka 2.4+)
增量式Rebalance,不需要停止所有消费者:
传统Rebalance (Stop-The-World):
1. 停止所有消费者
2. 重新分配所有分区
3. 恢复所有消费者
CooperativeSticky (增量式):
1. 只停止受影响的消费者
2. 只重新分配变化的分区
3. 其他消费者继续工作
大大减少了Rebalance的停顿时间5.4 Rebalance机制
Rebalance是消费者组重新分配分区的过程,理解它对优化消费性能至关重要。
Rebalance触发条件
Rebalance触发 消费者加入 消费者退出 消费者崩溃 订阅Topic变化 分区数变化 心跳超时
session.timeout.ms 处理超时
max.poll.interval.ms
Rebalance流程
Kafka使用**协调者(Group Coordinator)**管理Rebalance:
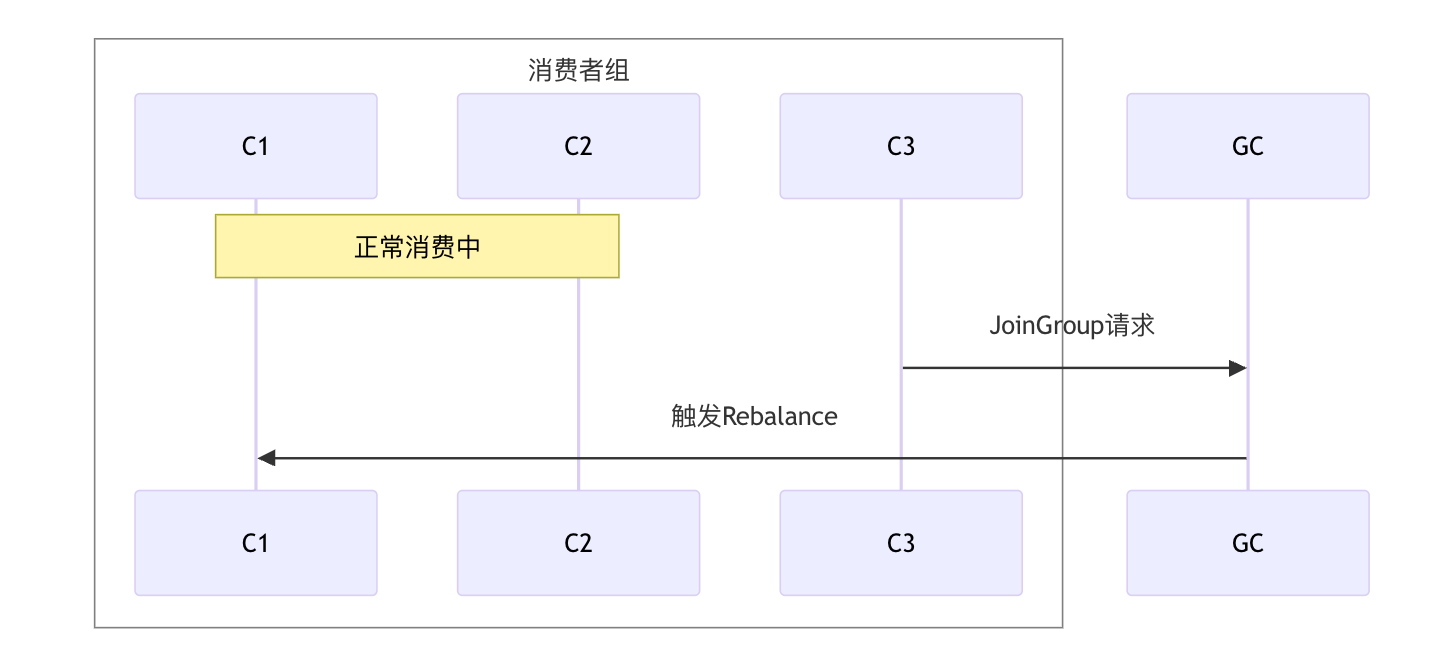
详细步骤:
-
JoinGroup阶段
- 消费者向Coordinator发送JoinGroup请求
- Coordinator收集所有消费者信息
- 选举第一个加入的消费者为Group Leader
-
SyncGroup阶段
- Leader执行分区分配算法
- Leader将分配结果发给Coordinator
- Coordinator将各自的分配结果发给每个消费者
-
Heartbeat维持
- 消费者定期发送心跳给Coordinator
- 超时未收到心跳,触发新的Rebalance
Rebalance的性能影响
Rebalance期间,消费者组会停止消费(Stop-The-World),影响实时性:
Rebalance耗时 =
消费者数量 × session.timeout.ms +
分区分配计算时间 +
offset重新定位时间
示例:
100个消费者,1000个分区
Rebalance可能耗时 10-30秒
期间无法消费消息,产生延迟如何减少不必要的Rebalance
java
// 1. 合理设置心跳和超时
props.put("session.timeout.ms", 30000); // 30秒
props.put("heartbeat.interval.ms", 3000); // 3秒 (建议session的1/3)
// 2. 设置合理的poll间隔
props.put("max.poll.interval.ms", 300000); // 5分钟
props.put("max.poll.records", 100); // 单次拉取100条
// 3. 确保消费逻辑不阻塞
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// ❌ 错误:在poll循环中执行耗时操作
for (ConsumerRecord<String, String> record : records) {
processSlowly(record); // 可能超过max.poll.interval.ms
}
// ✅ 正确:异步处理或控制批次大小
executor.submit(() -> {
for (ConsumerRecord<String, String> record : records) {
processSlowly(record);
}
});
consumer.commitAsync();
}
// 4. 使用Cooperative Sticky策略
props.put("partition.assignment.strategy",
"org.apache.kafka.clients.consumer.CooperativeStickyAssignor");
// 5. 优雅关闭消费者
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
consumer.wakeup(); // 触发WakeupException
}));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 处理消息
}
} catch (WakeupException e) {
// 正常关闭
} finally {
consumer.close(); // 主动离开消费者组,触发Rebalance
}六、消息语义与性能优化
6.1 消息传递语义
Kafka支持三种消息传递语义:
At-Most-Once (最多一次)
消息可能丢失,但不会重复。
java
// 配置
props.put("enable.auto.commit", true);
props.put("acks", "0");
// 流程
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 先自动提交offset,再处理消息
// 如果处理失败,消息丢失
for (ConsumerRecord<String, String> record : records) {
process(record); // 可能失败
}
}
适用场景:日志采集、监控指标(允许丢失)At-Least-Once (至少一次)
消息不会丢失,但可能重复。
java
// 配置
props.put("enable.auto.commit", false);
props.put("acks", "all");
// 流程
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
process(record); // 先处理消息
}
consumer.commitSync(); // 后提交offset
// 如果提交失败(网络故障),下次重新消费
// 导致消息重复处理
}
适用场景:大多数业务场景(配合幂等性)Exactly-Once (精确一次)
消息既不丢失,也不重复。这是最难实现的语义。
6.2 Exactly-Once实现
Kafka从0.11版本开始支持Exactly-Once,通过两个机制实现:
幂等生产者
防止生产者重试导致的重复:
java
// 配置
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
// 原理
每个Producer实例分配一个PID (Producer ID)
每条消息携带Sequence Number
Broker端维护:
Map<PID, Map<Partition, Sequence Number>>
接收消息时检查:
if (msg.sequence == expected + 1) {
// 正常消息,写入
} else if (msg.sequence <= expected) {
// 重复消息,丢弃
} else {
// 乱序消息,拒绝
}幂等性的限制:
- 只能保证单个Producer实例
- 只能保证单个分区
- 重启后PID变化,无法跨会话保证
事务机制
跨分区、跨会话的Exactly-Once:
java
// Producer配置
props.put("enable.idempotence", true);
props.put("transactional.id", "order-producer-1"); // 唯一ID
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
try {
producer.beginTransaction();
// 发送多条消息(可能跨多个分区)
producer.send(new ProducerRecord<>("topic1", "key1", "value1"));
producer.send(new ProducerRecord<>("topic2", "key2", "value2"));
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 回滚事务
producer.abortTransaction();
}Consumer配置:
java
props.put("isolation.level", "read_committed"); // 只读已提交的消息
// 事务性消费-处理-生产
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
producer.beginTransaction();
for (ConsumerRecord<String, String> record : records) {
// 处理消息
String result = process(record);
// 发送到下游Topic
producer.send(new ProducerRecord<>("output-topic", result));
}
// 将消费offset作为事务的一部分提交
producer.sendOffsetsToTransaction(
getCurrentOffsets(consumer),
consumer.groupMetadata()
);
producer.commitTransaction();
}事务原理:
事务日志 (__transaction_state) 数据分区 事务协调者 (Transaction Coordinator) read_committed read_committed 记录事务元数据 Partition 1
写入消息+事务标记 Partition 2
写入消息+事务标记 TC维护事务状态 Producer Consumer
事务流程:
- Producer向TC注册,获取PID
- beginTransaction:TC记录事务开始
- 发送消息到各分区,每个分区记录事务标记
- commitTransaction:TC在事务日志中标记提交
- TC向各分区写入提交标记(Commit Marker)
- Consumer只读取已提交的消息
6.3 性能监控与调优
关键监控指标
生产者指标:
java
// JMX Metrics
kafka.producer:
- record-send-rate // 发送速率 (records/sec)
- record-error-rate // 错误率
- request-latency-avg // 平均延迟 (ms)
- batch-size-avg // 平均批次大小
- compression-rate-avg // 压缩率
- buffer-available-bytes // 可用缓冲区消费者指标:
java
kafka.consumer:
- records-consumed-rate // 消费速率
- fetch-latency-avg // 拉取延迟
- records-lag-max // 最大滞后量 ⚠️ 重要
- commit-latency-avg // 提交延迟Broker指标:
java
kafka.server:
- BytesInPerSec // 入流量
- BytesOutPerSec // 出流量
- MessagesInPerSec // 消息生产速率
- RequestsPerSec // 请求速率
- UnderReplicatedPartitions // 副本未同步分区数 ⚠️ 关键
- IsrShrinksPerSec // ISR收缩频率 ⚠️ 关键
- NetworkProcessorAvgIdlePercent // 网络线程空闲率性能调优指南
1. Broker调优
properties
# 线程配置
num.network.threads = 8 # 网络线程数 = CPU核心数
num.io.threads = 16 # IO线程数 = 网络线程数 × 2
num.replica.fetchers = 4 # 副本拉取线程
# 内存配置
socket.send.buffer.bytes = 102400 # 发送缓冲区 100KB
socket.receive.buffer.bytes = 102400 # 接收缓冲区 100KB
# 日志配置
log.segment.bytes = 1073741824 # 1GB per segment
log.retention.hours = 168 # 保留7天
log.retention.check.interval.ms = 300000 # 5分钟检查一次
# 压缩配置
compression.type = lz4 # Broker端压缩类型(继承或重新压缩)
# 副本配置
replica.lag.time.max.ms = 30000 # ISR剔除阈值 30秒2. Producer调优
java
// 吞吐量优先
props.put("batch.size", 32768); // 32KB
props.put("linger.ms", 50); // 等待50ms凑批次
props.put("compression.type", "lz4"); // LZ4压缩
props.put("buffer.memory", 67108864); // 64MB缓冲区
props.put("acks", "1"); // 平衡可靠性
// 延迟优先
props.put("batch.size", 16384); // 16KB
props.put("linger.ms", 0); // 立即发送
props.put("compression.type", "none"); // 不压缩
props.put("acks", "1");
// 可靠性优先
props.put("acks", "all");
props.put("enable.idempotence", true);
props.put("max.in.flight.requests.per.connection", 1); // 严格有序
props.put("retries", Integer.MAX_VALUE);3. Consumer调优
java
// 吞吐量优先
props.put("fetch.min.bytes", 10240); // 至少10KB才返回
props.put("fetch.max.wait.ms", 500); // 最多等待500ms
props.put("max.poll.records", 500); // 单次拉取500条
props.put("max.partition.fetch.bytes", 1048576); // 单分区最多1MB
// 延迟优先
props.put("fetch.min.bytes", 1); // 有数据就返回
props.put("fetch.max.wait.ms", 100); // 最多等待100ms
props.put("max.poll.records", 100); // 少量多次4. 硬件调优
CPU:
- Broker: 至少8核心
- 高吞吐场景: 16-32核心
内存:
- Broker: 32GB-64GB
- OS PageCache: 分配大量内存给OS
磁盘:
- SSD > HDD(顺序写入差距不大,但随机读快得多)
- RAID 10(性能+冗余)
- 单独磁盘存储日志(避免与系统盘竞争)
网络:
- 万兆网卡 (10 Gbps)
- 专用网络(避免与其他服务竞争)5. JVM调优
bash
# G1 GC配置 (推荐)
-Xms6g -Xmx6g # 堆内存6GB(留足够内存给PageCache)
-XX:+UseG1GC
-XX:MaxGCPauseMillis=20 # 目标停顿时间20ms
-XX:InitiatingHeapOccupancyPercent=35
-XX:G1HeapRegionSize=16M
# GC日志
-Xlog:gc*:file=/var/log/kafka/gc.log:time,tags:filecount=10,filesize=100M6.4 故障排查指南
问题1: Consumer Lag持续增长
症状 :records-lag-max持续上升
排查步骤:
bash
# 1. 查看消费延迟
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--describe --group order-processor
# 输出示例:
# TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
# orders 0 1000 5000 4000 ⚠️
# 2. 检查消费者性能
# - 消费速率 vs 生产速率
# - 单条消息处理时间
# - 是否有频繁Rebalance
# 3. 解决方案
# a. 增加消费者实例(消费者数 < 分区数)
# b. 优化消费逻辑(减少处理时间)
# c. 增大max.poll.records(提高批处理效率)
# d. 异步处理消息问题2: 频繁Rebalance
症状:日志中大量"(Re)joining group"
排查步骤:
java
// 检查是否心跳超时
session.timeout.ms < 处理时间
// 检查是否poll超时
max.poll.interval.ms < 单批消息处理时间
// 解决方案:
// 1. 增大超时配置
props.put("session.timeout.ms", 60000);
props.put("max.poll.interval.ms", 600000);
// 2. 减少单次拉取量
props.put("max.poll.records", 50);
// 3. 异步处理
ExecutorService executor = Executors.newFixedThreadPool(10);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
List<Future<?>> futures = new ArrayList<>();
for (ConsumerRecord<String, String> record : records) {
futures.add(executor.submit(() -> process(record)));
}
// 等待所有任务完成
for (Future<?> future : futures) {
future.get();
}
consumer.commitSync();
}问题3: Under Replicated Partitions
症状 :UnderReplicatedPartitions > 0
原因:
- Follower同步速度跟不上Leader
- 网络问题
- Broker负载过高
- 磁盘IO瓶颈
排查:
bash
# 1. 查看哪些分区副本未同步
kafka-topics.sh --bootstrap-server localhost:9092 \
--describe --under-replicated-partitions
# 2. 检查Broker日志
grep "ISR" /var/log/kafka/server.log
# 3. 检查网络和磁盘IO
iostat -x 1
iftop
# 4. 解决方案
# a. 增加replica.lag.time.max.ms(临时)
# b. 优化网络配置
# c. 升级硬件(磁盘、网络)
# d. 减少Broker负载(迁移分区)问题4: 消息丢失排查
检查清单:
bash
# Producer端
✓ acks = all ?
✓ enable.idempotence = true ?
✓ retries > 0 ?
✓ 异常处理是否完善?
# Broker端
✓ replication.factor >= 3 ?
✓ min.insync.replicas >= 2 ?
✓ unclean.leader.election.enable = false ?
# Consumer端
✓ enable.auto.commit = false ?
✓ 是否先处理后提交?
✓ 异常时是否跳过提交?
# 日志分析
grep "Lost messages" /var/log/app.log
grep "send failed" /var/log/kafka/server.log总结
Kafka作为分布式流处理平台,其核心竞争力在于:
核心优势
-
高吞吐量
- 顺序I/O + 零拷贝 + PageCache
- 批量处理 + 消息压缩
- 分区并行
-
高可用性
- 副本机制 + ISR
- 自动故障转移
- 分布式架构
-
持久化
- 所有消息持久化到磁盘
- 支持消息回溯
- 可配置保留策略
-
可扩展性
- 水平扩展Broker
- 增加分区提升吞吐
- Consumer Group负载均衡
最佳实践总结
| 维度 | 关键配置 | 推荐值 |
|---|---|---|
| 可靠性 | acks | all |
| replication.factor | 3 | |
| min.insync.replicas | 2 | |
| 性能 | compression.type | lz4 |
| batch.size | 16KB-32KB | |
| linger.ms | 10-100ms | |
| 消费 | enable.auto.commit | false |
| max.poll.records | 100-500 | |
| session.timeout.ms | 30s |
技术演进方向
- KRaft模式:移除ZooKeeper依赖(Kafka 3.3+)
- Tiered Storage:冷热数据分离存储
- 更强的Exactly-Once:简化事务API
- 性能优化:Cooperative Rebalance、更高效的序列化
Kafka已成为现代数据架构的基石,掌握其核心原理对构建高性能、高可靠的分布式系统至关重要。
参考资料:
- Apache Kafka官方文档: https://kafka.apache.org/documentation/
- Kafka源代码: https://github.com/apache/kafka
- 《Kafka权威指南》
- 《深入理解Kafka:核心设计与实践原理》