引言:学习的本质是创造
在人工智能的发展历程中,我们见证了模型从理解 到生成的进化。自编码器(Autoencoder)教会了我们如何压缩和重建,变分自编码器(VAE)则让我们看到了生成的可能。但这一切,都还停留在"模仿"的层面。
今天,我们要探索一种全新的范式------生成对抗网络(GAN)。如果说VAE是"学习后创造",那么GAN就是"创造中学习"。
一、博弈的艺术:对抗中的进化
1.1 基本思想
想象一场永不停止的艺术对决:
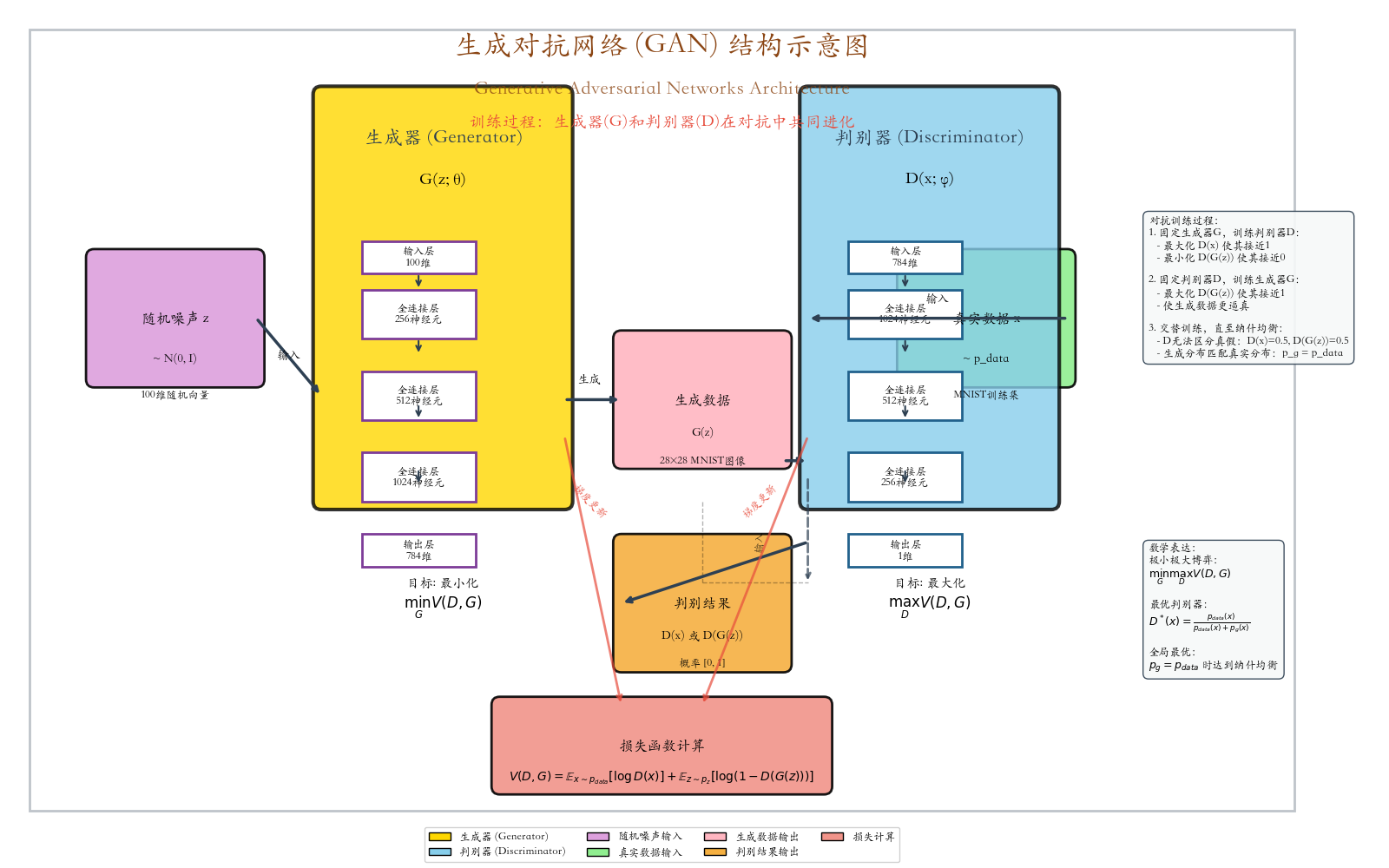
伪造者(Generator) :一位技艺高超的伪造者,试图制造足以以假乱真的名画仿作。
鉴赏家(Discriminator):一位经验丰富的艺术鉴赏家,专门鉴别画作的真伪。
这场博弈的关键在于:
- 伪造者不断改进技术,让仿作越来越逼真
- 鉴赏家不断提升眼力,能识破更精致的仿作
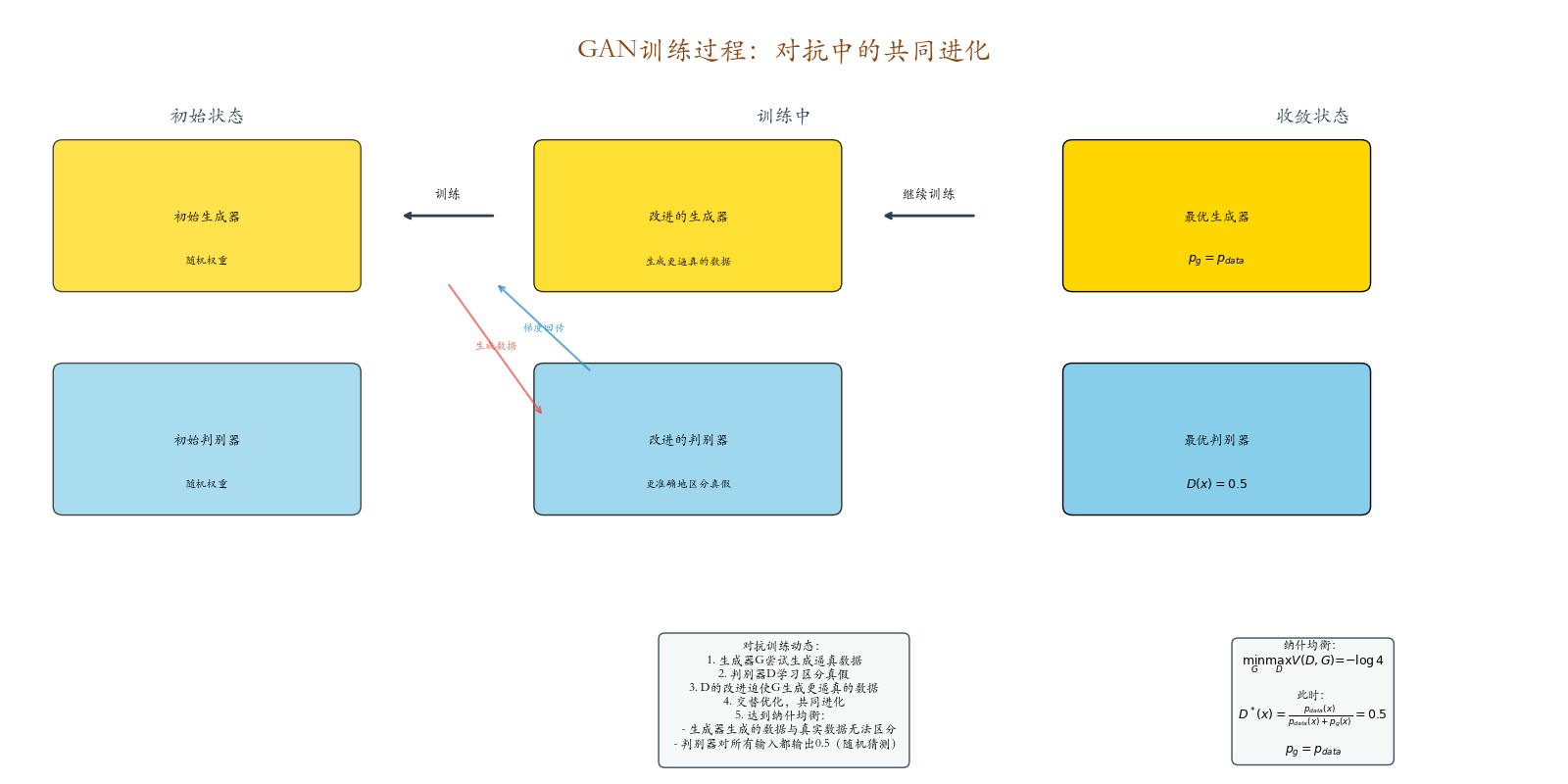
- 双方在对抗中共同进化 ,最终难分伯仲
1.2 数学表达
这个博弈过程可以用极小极大博弈 来描述:
minGmaxDV(D,G)=Ex∼pdata(x)logD(x)+Ez∼pz(z)log(1−D(G(z))) \min_G \max_D V(D, G) = \mathbb{E}{x \sim p{\text{data}}(x)}\\log D(x) + \mathbb{E}_{z \sim p_z(z)}\\log(1 - D(G(z))) GminDmaxV(D,G)=Ex∼pdata(x)logD(x)+Ez∼pz(z)log(1−D(G(z)))
-
minG\min_GminG :最小化关于生成器GGG
-
maxD\max_DmaxD :最大化关于判别器DDD
-
E\mathbb{E}E:期望(平均值)
-
xxx:真实数据样本
- 示例:一张猫的图片,一个手写数字
- 从真实数据分布pdata(x)p_{\text{data}}(x)pdata(x)采样得到
-
zzz:随机噪声
- 示例:100维随机数
- 从简单分布pz(z)p_z(z)pz(z)采样(通常为标准正态分布N(0,1)\mathcal{N}(0,1)N(0,1))
-
G(z)G(z)G(z) :生成器:用噪声zzz生成假数据
- 输入:噪声zzz
- 输出:假数据G(z)G(z)G(z)
- 目标:生成逼真的数据
-
D(x)D(x)D(x):判别器:对生成数据的判断
- 输入:数据xxx(真或假)
- 输出:概率值0,10,10,1
- 解释:xxx是真实数据的概率
- 示例:D(x)=0.9D(x)=0.9D(x)=0.9表示90%可能是真数据
1.3 博弈关系与训练过程
公式拆解与博弈目标
第一项 :Ex∼pdata(x)logD(x)\mathbb{E}{x \sim p{\text{data}}(x)}\\log D(x)Ex∼pdata(x)logD(x)
- 让判别器正确识别真实数据
- 目标:最大化此项,使D(x)→1D(x) \rightarrow 1D(x)→1
第二项 :Ez∼pz(z)log(1−D(G(z)))\mathbb{E}_{z \sim p_z(z)}\\log(1 - D(G(z)))Ez∼pz(z)log(1−D(G(z)))
- 让判别器正确识别生成数据
- 判别器目标:最大化此项,使D(G(z))→0D(G(z)) \rightarrow 0D(G(z))→0
- 生成器目标:最小化此项,使D(G(z))→1D(G(z)) \rightarrow 1D(G(z))→1
博弈关系:
- 判别器:maxDV(D,G)\max_D V(D, G)maxDV(D,G),准确区分真假
- 生成器:minGV(D,G)\min_G V(D, G)minGV(D,G),让生成数据以假乱真
训练过程
交替训练:
-
训练判别器(固定生成器):
- 优化目标:最大化V(D,G)V(D, G)V(D,G)
- 目标:D(x)→1D(x) \rightarrow 1D(x)→1,D(G(z))→0D(G(z)) \rightarrow 0D(G(z))→0
-
训练生成器(固定判别器):
- 优化目标:最小化V(D,G)V(D, G)V(D,G)
- 目标:D(G(z))→1D(G(z)) \rightarrow 1D(G(z))→1
最终平衡:
- 判别器无法区分:D(x)=0.5D(x) = 0.5D(x)=0.5,D(G(z))=0.5D(G(z)) = 0.5D(G(z))=0.5
- 生成分布匹配真实分布:pg=pdatap_g = p_{\text{data}}pg=pdata
核心总结
| 损失项 | 含义 | 判别器目标 | 生成器目标 |
|---|---|---|---|
| logD(x)\log D(x)logD(x) | 真实数据判为真 | 最大化 | 无影响 |
| log(1−D(G(z)))\log(1-D(G(z)))log(1−D(G(z))) | 生成数据判为假 | 最大化 | 最小化 |
对抗本质:
- 判别器:努力区分真假
- 生成器:努力以假乱真
- 动态博弈,共同进步
二、代码实现:MNIST手写数字生成
python
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import os
import datetime
matplotlib.rcParams['axes.unicode_minus'] = False
# Note: Font family changed to English-compatible font
matplotlib.rcParams['font.family'] = 'DejaVu Sans'
# Create directory for saving results
current_time = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
save_dir = f'gan_results_{current_time}'
os.makedirs(save_dir, exist_ok=True)
print(f"Save directory: {save_dir}")
# Set random seed
torch.manual_seed(42)
np.random.seed(42)
# Device configuration
device = torch.device("mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Data preprocessing
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # Normalize to [-1, 1]
])
# Load MNIST dataset
train_dataset = torchvision.datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Generator definition
class Generator(nn.Module):
"""Generator: Generate images from noise"""
def __init__(self, noise_dim=100, img_channels=1, feature_size=64):
super(Generator, self).__init__()
self.noise_dim = noise_dim
# Fully connected layers
self.fc = nn.Sequential(
nn.Linear(noise_dim, 256),
nn.BatchNorm1d(256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(True),
nn.Linear(1024, 28 * 28 * img_channels),
nn.Tanh() # Output range [-1, 1]
)
def forward(self, z):
"""Forward pass: noise → image"""
x = self.fc(z)
x = x.view(-1, 1, 28, 28) # Reshape to image shape
return x
# Discriminator definition
class Discriminator(nn.Module):
"""Discriminator: Distinguish real and generated images"""
def __init__(self, img_channels=1):
super(Discriminator, self).__init__()
# Fully connected layers
self.model = nn.Sequential(
nn.Linear(28 * 28 * img_channels, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid() # Output probability [0, 1]
)
def forward(self, img):
"""Forward pass: image → real probability"""
img_flat = img.view(img.size(0), -1) # Flatten
validity = self.model(img_flat)
return validity
# Initialize models
noise_dim = 100
generator = Generator(noise_dim=noise_dim).to(device)
discriminator = Discriminator().to(device)
# Loss function and optimizer
criterion = nn.BCELoss() # Binary Cross Entropy Loss
lr = 0.0002
beta1 = 0.5
# Optimizers
g_optimizer = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))
# Training function
def train_gan(generator, discriminator, train_loader, num_epochs=50, save_images_every=5, device='cuda'):
"""Train GAN and save generated results for each epoch"""
# Record losses
g_losses = []
d_losses = []
# Save generated images for each epoch
all_generated_images = []
epoch_list = []
# Fixed noise for visualization (show 5 images per epoch)
fixed_noise = torch.randn(5, noise_dim).to(device)
for epoch in range(num_epochs):
epoch_g_loss = 0.0
epoch_d_loss = 0.0
for i, (real_imgs, _) in enumerate(train_loader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
# Real and fake labels
real_labels = torch.ones(batch_size, 1).to(device) # Real images label = 1
fake_labels = torch.zeros(batch_size, 1).to(device) # Fake images label = 0
# ========== Train Discriminator ==========
d_optimizer.zero_grad()
# Real images loss
real_validity = discriminator(real_imgs)
d_real_loss = criterion(real_validity, real_labels)
# Generate fake images
noise = torch.randn(batch_size, noise_dim).to(device)
fake_imgs = generator(noise)
# Fake images loss
fake_validity = discriminator(fake_imgs.detach())
d_fake_loss = criterion(fake_validity, fake_labels)
# Total discriminator loss
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# ========== Train Generator ==========
g_optimizer.zero_grad()
# Regenerate fake images
fake_imgs = generator(noise)
# Generator wants discriminator to think fake images are real
validity = discriminator(fake_imgs)
g_loss = criterion(validity, real_labels) # Make fake images classified as real
g_loss.backward()
g_optimizer.step()
# Record losses
epoch_g_loss += g_loss.item()
epoch_d_loss += d_loss.item()
# Calculate average epoch loss
avg_g_loss = epoch_g_loss / len(train_loader)
avg_d_loss = epoch_d_loss / len(train_loader)
g_losses.append(avg_g_loss)
d_losses.append(avg_d_loss)
print(f'Epoch [{epoch + 1:3d}/{num_epochs}] '
f'D Loss: {avg_d_loss:.4f} | G Loss: {avg_g_loss:.4f}')
# Save generated results every save_images_every epochs
if (epoch + 1) % save_images_every == 0 or epoch == 0 or epoch == num_epochs - 1:
with torch.no_grad():
generator.eval()
images = generator(fixed_noise)
images = images.cpu().numpy()
images = (images + 1) / 2 # Denormalize
images = np.clip(images, 0, 1)
all_generated_images.append(images)
epoch_list.append(epoch + 1)
generator.train()
# Save single epoch generated images
save_single_epoch_images(images, epoch + 1, save_dir)
return g_losses, d_losses, all_generated_images, epoch_list
def save_single_epoch_images(images, epoch, save_dir):
"""Save generated images for a single epoch"""
fig, axes = plt.subplots(1, 5, figsize=(12, 3))
for i in range(5):
axes[i].imshow(images[i, 0], cmap='gray', vmin=0, vmax=1)
axes[i].axis('off')
axes[i].set_title(f'Image {i + 1}')
plt.suptitle(f'Epoch {epoch} Generated Results', fontsize=16, y=0.95)
plt.tight_layout()
plt.savefig(f'{save_dir}/epoch_{epoch:03d}_generated.png', dpi=150, bbox_inches='tight')
plt.close()
print(f" Saved Epoch {epoch} generated images to {save_dir}/epoch_{epoch:03d}_generated.png")
# Train GAN
print("Starting GAN training...")
print(f"Training for {50} epochs, saving results every 5 epochs...")
num_epochs = 50
g_losses, d_losses, all_generated_images, epoch_list = train_gan(
generator, discriminator, train_loader, num_epochs, save_images_every=5, device=device
)
# Visualize generated results for all epochs
def visualize_all_epochs(all_generated_images, epoch_list, num_images=5, save_dir='.'):
"""Plot generated results for all epochs in one large figure and save"""
num_epochs = len(epoch_list)
# Create large figure
fig, axes = plt.subplots(num_epochs, num_images, figsize=(15, 3 * num_epochs))
# Adjust axes dimension if only one row
if num_epochs == 1:
axes = axes.reshape(1, -1)
for epoch_idx in range(num_epochs):
images = all_generated_images[epoch_idx] # Shape: (5, 1, 28, 28)
for img_idx in range(num_images):
ax = axes[epoch_idx, img_idx]
img = images[img_idx, 0] # Get single image
ax.imshow(img, cmap='gray', vmin=0, vmax=1)
ax.axis('off')
# Add epoch label in first column
if img_idx == 0:
ax.set_ylabel(f'Epoch {epoch_list[epoch_idx]}',
rotation=0, ha='right', va='center', fontsize=12, fontweight='bold')
# Add training progress above ylabel
if epoch_idx == 0:
ax.text(-0.5, 1.1, f"Training Progress: {epoch_list[epoch_idx]}/{max(epoch_list)}",
transform=ax.transAxes, fontsize=14, fontweight='bold', color='red')
else:
# Add training progress in first row
if epoch_idx == 0 and img_idx == 2:
ax.text(0, 1.1, f"GAN Training Process",
transform=ax.transAxes, ha='center', fontsize=16, fontweight='bold', color='blue')
plt.suptitle(f'GAN Training Process - Generated Image Evolution from Epoch 1 to Epoch {max(epoch_list)}', fontsize=18, y=0.98)
plt.tight_layout()
# Save image
save_path = f'{save_dir}/all_epochs_comparison.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"Saved all epochs comparison to: {save_path}")
plt.show()
# Visualize interpolation process
def visualize_generation_process(generator, noise_dim, device, num_steps=10, save_dir='.'):
"""Visualize generation process (interpolation) from noise to image and save"""
generator.eval()
with torch.no_grad():
# Two different noise vectors
noise_a = torch.randn(1, noise_dim).to(device)
noise_b = torch.randn(1, noise_dim).to(device)
# Linear interpolation
alphas = torch.linspace(0, 1, num_steps).view(-1, 1).to(device)
interpolated_noise = noise_a + alphas * (noise_b - noise_a)
# Generate images
generated_images = generator(interpolated_noise)
generated_images = generated_images.cpu().numpy()
generated_images = (generated_images + 1) / 2
generated_images = np.clip(generated_images, 0, 1)
# Plot interpolation process
fig, axes = plt.subplots(1, num_steps, figsize=(15, 3))
for i in range(num_steps):
axes[i].imshow(generated_images[i, 0], cmap='gray')
axes[i].set_title(f'α={alphas[i].item():.2f}', fontsize=10)
axes[i].axis('off')
plt.suptitle('Latent Space Interpolation Generation Process', fontsize=16, y=0.98)
plt.tight_layout()
# Save image
save_path = f'{save_dir}/latent_space_interpolation.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"Saved interpolation plot to: {save_path}")
plt.show()
# Compare real and generated images
def compare_real_fake(real_images, generator, noise_dim, device, num_images=10, save_dir='.'):
"""Compare real and generated images and save"""
generator.eval()
with torch.no_grad():
# Generate fake images
noise = torch.randn(num_images, noise_dim).to(device)
fake_images = generator(noise)
fake_images = fake_images.cpu().numpy()
fake_images = (fake_images + 1) / 2
# Get real images
real_images = real_images[:num_images].cpu().numpy()
real_images = (real_images + 1) / 2
# Plot comparison
fig, axes = plt.subplots(2, num_images, figsize=(15, 4))
for i in range(num_images):
# Real images
axes[0, i].imshow(real_images[i, 0], cmap='gray')
if i == 0:
axes[0, i].set_ylabel('Real Images', fontsize=12)
axes[0, i].axis('off')
# Generated images
axes[1, i].imshow(fake_images[i, 0], cmap='gray')
if i == 0:
axes[1, i].set_ylabel(f'Generated Images\n(Epoch {max(epoch_list)})', fontsize=12)
axes[1, i].axis('off')
plt.suptitle('Real Images vs Generated Images Comparison', fontsize=16, y=0.98)
plt.tight_layout()
# Save image
save_path = f'{save_dir}/real_vs_fake_comparison.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"Saved real vs fake comparison to: {save_path}")
plt.show()
# Save loss curves
def save_loss_curves(g_losses, d_losses, save_dir='.'):
"""Save training loss curves"""
plt.figure(figsize=(10, 6))
epochs = range(1, len(g_losses) + 1)
plt.plot(epochs, g_losses, 'b-', label='Generator Loss', linewidth=2)
plt.plot(epochs, d_losses, 'r-', label='Discriminator Loss', linewidth=2)
plt.plot(epochs, [0.5] * len(epochs), 'k--', label='Ideal Balance Point', linewidth=1, alpha=0.5)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('GAN Training Loss Curves')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
# Save image
save_path = f'{save_dir}/loss_curves.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"Saved loss curves to: {save_path}")
plt.close()
# Evaluate generation quality
def evaluate_generation_quality(generator, discriminator, noise_dim, device, num_samples=1000, save_dir='.'):
"""Evaluate quality of generated images and save results"""
generator.eval()
discriminator.eval()
with torch.no_grad():
# Generate many samples
noise = torch.randn(num_samples, noise_dim).to(device)
fake_images = generator(noise)
# Calculate discriminator's "real" score for generated images
validity_scores = discriminator(fake_images)
avg_score = validity_scores.mean().item()
# Calculate diversity: average difference between different images
fake_images_flat = fake_images.view(num_samples, -1)
# Randomly select sample pairs to compute differences
num_pairs = 1000
indices_a = torch.randint(0, num_samples, (num_pairs,))
indices_b = torch.randint(0, num_samples, (num_pairs,))
diversity = 0
for i in range(num_pairs):
img_a = fake_images_flat[indices_a[i]]
img_b = fake_images_flat[indices_b[i]]
diversity += torch.norm(img_a - img_b, p=2).item()
diversity /= num_pairs
# Save evaluation results
with open(f'{save_dir}/evaluation_results.txt', 'w') as f:
f.write(f"GAN Training Evaluation Results\n")
f.write(f"================================\n")
f.write(f"Training completed epoch: {max(epoch_list)}\n")
f.write(f"Evaluation time: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"Average 'real' score: {avg_score:.4f} (0=fake, 1=real)\n")
f.write(f"Image diversity: {diversity:.4f} (higher value = better diversity)\n")
f.write(f"Discriminator judgment on generated images: {'Real' if avg_score > 0.5 else 'Fake'} (threshold=0.5)\n")
f.write(f"Final generator loss: {g_losses[-1]:.4f}\n")
f.write(f"Final discriminator loss: {d_losses[-1]:.4f}\n")
print(f"Generation quality evaluation after training:")
print(f"Average 'real' score: {avg_score:.4f} (0=fake, 1=real)")
print(f"Image diversity: {diversity:.4f} (higher value = better diversity)")
print(f"Discriminator judgment on generated images: {'Real' if avg_score > 0.5 else 'Fake'} (threshold=0.5)")
return avg_score, diversity
# Save model parameters
def save_models(generator, discriminator, save_dir='.'):
"""Save generator and discriminator models"""
torch.save(generator.state_dict(), f'{save_dir}/generator_final.pth')
torch.save(discriminator.state_dict(), f'{save_dir}/discriminator_final.pth')
print(f"Saved model parameters to: {save_dir}/")
# Execute visualization and saving
print(f"\nSaving training results to directory: {save_dir}")
# Show generated results for all epochs
print(f"1. Displaying generated image evolution during training...")
print(f"Showing epochs: {epoch_list}")
visualize_all_epochs(all_generated_images, epoch_list, num_images=5, save_dir=save_dir)
# Save loss curves
print(f"\n2. Saving loss curves...")
save_loss_curves(g_losses, d_losses, save_dir=save_dir)
# Visualize interpolation process
print(f"\n3. Visualizing latent space interpolation...")
visualize_generation_process(generator, noise_dim, device, num_steps=10, save_dir=save_dir)
# Get a batch of real images for comparison
real_images_batch, _ = next(iter(train_loader))
print(f"\n4. Comparing real and generated images...")
print(f"Final model after training (Epoch {max(epoch_list)})")
compare_real_fake(real_images_batch, generator, noise_dim, device, num_images=10, save_dir=save_dir)
# Evaluate generation quality
print(f"\n5. Evaluating generation quality...")
avg_score, diversity = evaluate_generation_quality(generator, discriminator, noise_dim, device, num_samples=1000,
save_dir=save_dir)
# Save models
print(f"\n6. Saving model parameters...")
save_models(generator, discriminator, save_dir=save_dir)
# Simple training summary
print(f"\n7. Training Summary:")
print(f"✓ Trained for {max(epoch_list)} epochs")
print(f"✓ Saved results every {epoch_list[1] - epoch_list[0] if len(epoch_list) > 1 else 1} epochs")
print(f"✓ Saved {len(epoch_list)} time points")
print(f"✓ Final generator loss: {g_losses[-1]:.4f}")
print(f"✓ Final discriminator loss: {d_losses[-1]:.4f}")
print(f"✓ All results saved to directory: {save_dir}/")
print(f"✓ Evaluation results saved to: {save_dir}/evaluation_results.txt")
print(f"✓ Model parameters saved to: {save_dir}/generator_final.pth and {save_dir}/discriminator_final.pth")
# Create and save training configuration information
def save_config_info(save_dir, num_epochs, batch_size, noise_dim, lr):
"""Save training configuration information"""
with open(f'{save_dir}/training_config.txt', 'w') as f:
f.write("GAN Training Configuration\n")
f.write("==========================\n")
f.write(f"Training time: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"Training device: {device}\n")
f.write(f"Total epochs: {num_epochs}\n")
f.write(f"Batch size: {batch_size}\n")
f.write(f"Noise dimension: {noise_dim}\n")
f.write(f"Learning rate: {lr}\n")
f.write(f"Optimizer: Adam (beta1={beta1})\n")
f.write(f"Loss function: BCELoss\n")
f.write(f"Model architecture: Generator(FC), Discriminator(FC)\n")
print(f"\n8. Saving training configuration...")
save_config_info(save_dir, num_epochs, batch_size, noise_dim, lr)
print(f"✓ Training configuration saved to: {save_dir}/training_config.txt")
# Create example grid
print(f"\n9. Creating example grid...")
# Generate some example images to show generation quality
def create_example_grid(generator, noise_dim, device, save_dir, n_examples=25):
"""Create a grid of example images"""
generator.eval()
with torch.no_grad():
# Generate 25 random samples
noise = torch.randn(n_examples, noise_dim).to(device)
generated_images = generator(noise)
generated_images = generated_images.cpu().numpy()
generated_images = (generated_images + 1) / 2
# Create 5x5 grid
fig, axes = plt.subplots(5, 5, figsize=(10, 10))
axes = axes.flatten()
for i in range(n_examples):
ax = axes[i]
ax.imshow(generated_images[i, 0], cmap='gray')
ax.axis('off')
plt.suptitle('Generated Examples (5x5 Grid)', fontsize=20, y=0.95)
plt.tight_layout()
save_path = f'{save_dir}/examples_grid.png'
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"✓ Example grid saved to: {save_path}")
plt.show()
create_example_grid(generator, noise_dim, device, save_dir, n_examples=25)
print(f"\n✅ All training results saved to directory: {save_dir}/")
print(f" Includes: generated images for each epoch, comparison plots, loss curves, model parameters, and configuration information")



三、GAN的核心原理
GAN的核心是最小化两个分布之间的Jensen-Shannon散度:
DJS(pdata∥pg)=12DKL(pdata∥pdata+pg2)+12DKL(pg∥pdata+pg2) D_{JS}(p_{\text{data}} \parallel p_g) = \frac{1}{2} D_{KL}\left(p_{\text{data}} \parallel \frac{p_{\text{data}} + p_g}{2}\right) + \frac{1}{2} D_{KL}\left(p_g \parallel \frac{p_{\text{data}} + p_g}{2}\right) DJS(pdata∥pg)=21DKL(pdata∥2pdata+pg)+21DKL(pg∥2pdata+pg)
其中:
- pdatap_{\text{data}}pdata:真实数据分布
- pgp_gpg:生成器分布
最优判别器 :
D∗(x)=pdata(x)pdata(x)+pg(x) D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)} D∗(x)=pdata(x)+pg(x)pdata(x)
最优生成器 :当且仅当pg=pdatap_g = p_{\text{data}}pg=pdata时,DJS(pdata∥pg)=0D_{JS}(p_{\text{data}} \parallel p_g) = 0DJS(pdata∥pg)=0
四、GAN的变体与改进
4.1 DCGAN:深度卷积GAN
数学原理
DCGAN(Deep Convolutional GAN)是GAN架构的重要改进,将全连接层替换为卷积/转置卷积层,特别适用于图像生成任务。
核心改进:
- 用转置卷积(Transposed Convolution)替代全连接层进行上采样
- 使用批量归一化(Batch Normalization)稳定训练
- 移除池化层,使用步幅卷积进行下采样
- 激活函数选择:生成器用ReLU,判别器用LeakyReLU
数学公式 :
转置卷积的前向传播可以用矩阵乘法表示:
Y=CTX Y = C^T X Y=CTX
其中CCC是卷积核对应的稀疏矩阵,XXX是输入,YYY是输出。
4.2 WGAN:Wasserstein GAN
数学原理
WGAN通过使用Wasserstein距离(也称为推土机距离)替代JS散度,解决了GAN训练不稳定的问题。
Wasserstein距离定义 :
W(Pr,Pg)=infγ∈Π(Pr,Pg)E(x,y)∼γ∥x−y∥ W(P_r, P_g) = \inf_{\gamma \in \Pi(P_r, P_g)} \mathbb{E}_{(x,y) \sim \gamma} \\\|x - y\\\| W(Pr,Pg)=γ∈Π(Pr,Pg)infE(x,y)∼γ∥x−y∥
其中:
- PrP_rPr:真实数据分布
- PgP_gPg:生成器分布
- Π(Pr,Pg)\Pi(P_r, P_g)Π(Pr,Pg):所有可能的联合分布γ\gammaγ的集合
- E(x,y)∼γ∥x−y∥\mathbb{E}_{(x,y) \sim \gamma}\\\|x - y\\\|E(x,y)∼γ∥x−y∥:在联合分布γ\gammaγ下xxx和yyy之间的期望距离
Kantorovich-Rubinstein对偶定理 :
Wasserstein距离的对偶形式为:
W(Pr,Pg)=sup∥f∥L≤1Ex∼Prf(x)−Ex∼Pgf(x) W(P_r, P_g) = \sup_{\|f\|L \leq 1} \mathbb{E}{x \sim P_r}f(x) - \mathbb{E}_{x \sim P_g}f(x) W(Pr,Pg)=∥f∥L≤1supEx∼Prf(x)−Ex∼Pgf(x)
其中fff是1-Lipschitz函数。
WGAN的目标函数 :
minGmaxD∈1-LipschitzEx∼PrD(x)−Ez∼p(z)D(G(z)) \min_G \max_{D \in 1\text{-Lipschitz}} \mathbb{E}{x \sim P_r}D(x) - \mathbb{E}{z \sim p(z)}D(G(z)) GminD∈1-LipschitzmaxEx∼PrD(x)−Ez∼p(z)D(G(z))
权重裁剪 :为保证判别器是1-Lipschitz函数,WGAN对参数进行裁剪:
w←clip(w,−c,c) w \leftarrow \text{clip}(w, -c, c) w←clip(w,−c,c)
WGAN-GP :WGAN with Gradient Penalty,通过梯度惩罚项替代权重裁剪:
L=Ex~∼PgD(x\~)−Ex∼PrD(x)+λEx^∼Px^(∥∇x\^D(x\^)∥2−1)2 L = \mathbb{E}{\tilde{x} \sim P_g}D(\\tilde{x}) - \mathbb{E}{x \sim P_r}D(x) + \lambda \mathbb{E}{\hat{x} \sim P{\hat{x}}}(\\\|\\nabla_{\\hat{x}} D(\\hat{x})\\\|_2 - 1)\^2 L=Ex~∼PgD(x\~)−Ex∼PrD(x)+λEx^∼Px^(∥∇x\^D(x\^)∥2−1)2
其中x^=ϵx+(1−ϵ)x~\hat{x} = \epsilon x + (1 - \epsilon) \tilde{x}x^=ϵx+(1−ϵ)x~,ϵ∼U0,1\epsilon \sim U0,1ϵ∼U0,1。
4.3 CGAN:条件GAN
数学原理
条件GAN(Conditional GAN)在生成器和判别器中都加入条件信息yyy,实现有条件的生成。
目标函数 :
minGmaxDV(D,G)=Ex∼pdata(x)logD(x∣y)+Ez∼pz(z)log(1−D(G(z∣y))) \min_G \max_D V(D, G) = \mathbb{E}{x \sim p{\text{data}}(x)} \\log D(x\|y) + \mathbb{E}_{z \sim p_z(z)} \\log (1 - D(G(z\|y))) GminDmaxV(D,G)=Ex∼pdata(x)logD(x∣y)+Ez∼pz(z)log(1−D(G(z∣y)))
其中yyy是条件标签,可以是类别标签、文本描述或其他辅助信息。
改进:
- 在生成器输入中拼接条件信息
- 在判别器输入中拼接条件信息
- 可以实现特定类别的图像生成