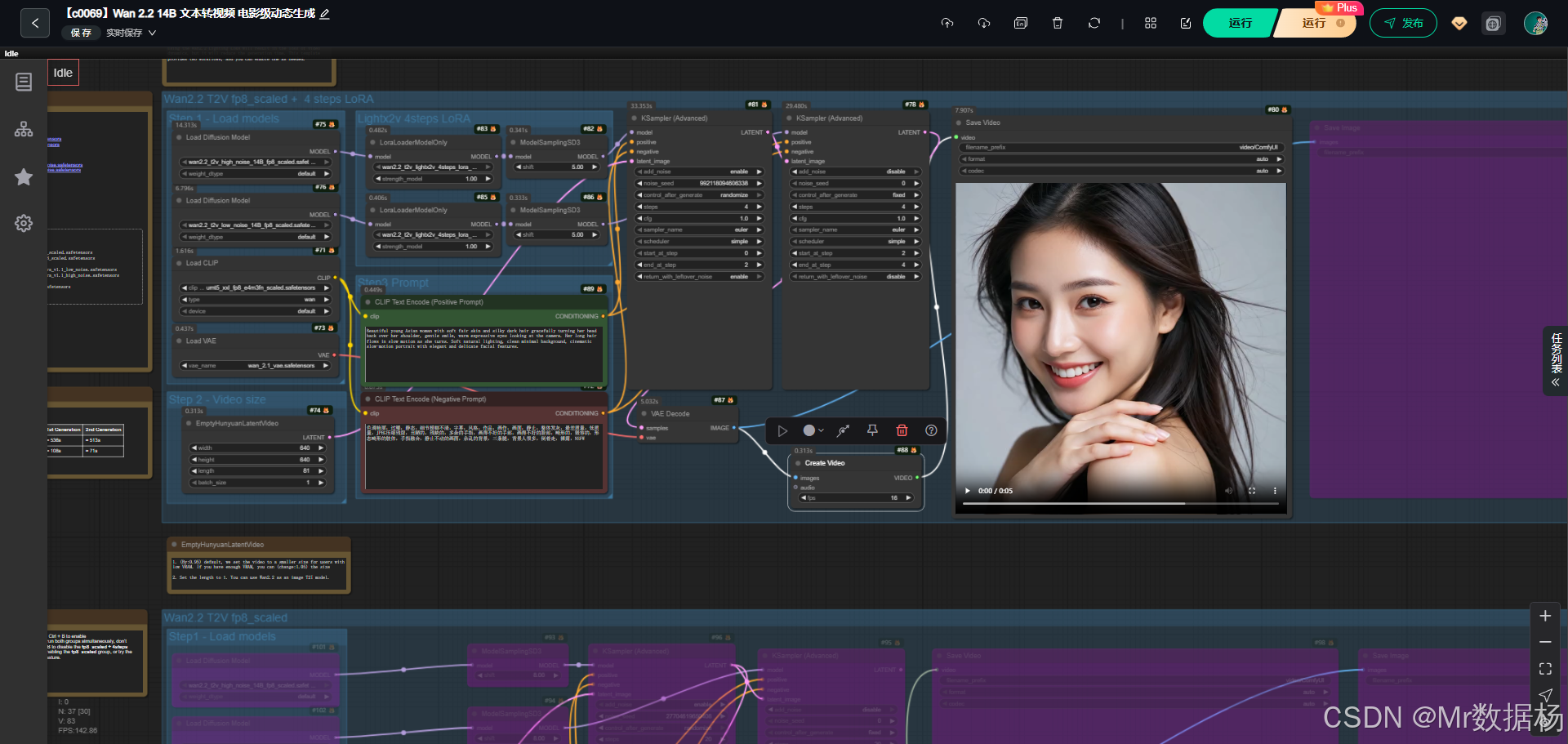
今天展示的案例是一个基于 Wan2.2 Text-to-Video 的 ComfyUI 工作流。该流程结合低噪与高噪的双 UNet 模型以及轻量化的 LoRA 适配器,完成从文本提示到视频输出的完整链路。
通过 CLIP 文本编码器解析正向与反向提示词,结合 VAE 进行潜空间解码,最终在 KSampler 的驱动下输出动态视频。整体流程兼顾了画面清晰度与生成效率,读者能直观理解 Wan2.2 在视频生成中的实际应用。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode(Positive / Negative) 文本语义驱动的核心入口](#CLIPTextEncode(Positive / Negative) 文本语义驱动的核心入口)
- [UNETLoader + ModelSamplingSD3 视频扩散生成的解算核心](#UNETLoader + ModelSamplingSD3 视频扩散生成的解算核心)
- [KSamplerAdvanced 基于 Prompt 的逐帧扩散采样器](#KSamplerAdvanced 基于 Prompt 的逐帧扩散采样器)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该工作流以 Wan2.2 系列模型为核心,分为两套主路径:一条是直接使用 fp8_scaled 模型完成视频生成,另一条是结合四步 LoRA 的轻量版本来提升生成速度。整个链路由模型加载、潜空间初始化、文本提示解析、采样生成、解码成像及视频合成构成。其优势在于既能生成高质量的动态图像,又能通过 LoRA 方案在有限算力环境下快速迭代结果。
核心模型
核心模型由 Wan2.2 的高噪与低噪扩散模型、Wan2.1 VAE、UMT5 XXL 文本编码器及 LoRA 模块组成。高噪模型负责保证视频的动态细节,低噪模型则提升画面的稳定性,而 LoRA 模块用于在更短的步数中实现视频生成,从而兼顾效率与质量。
| 模型名称 | 说明 |
|---|---|
| wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors | 高噪扩散模型,侧重视频动态细节 |
| wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors | 低噪扩散模型,保证画面稳定与细腻 |
| wan_2.1_vae.safetensors | 负责潜空间的编码与解码,实现图像还原 |
| umt5_xxl_fp8_e4m3fn_scaled.safetensors | 大型文本编码器,用于解析正负向提示词 |
| wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors | 高噪版本 LoRA,适合快速生成动态视频 |
| wan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensors | 低噪版本 LoRA,保证效率同时保持画质 |
Node节点
Node 节点的设计涵盖了从模型加载到视频输出的全链路。UNet 与 LoRA Loader 节点构成生成主干,CLIPTextEncode 节点用于提示词解析,KSamplerAdvanced 节点控制采样策略,VAEDecode 节点完成图像还原,CreateVideo 与 SaveVideo 节点则实现多帧合成与输出。通过节点的模块化组合,用户可以灵活选择使用高噪或低噪模型,以及是否开启 LoRA 快速模式。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载高噪与低噪扩散模型,作为生成主干 |
| LoraLoaderModelOnly | 加载轻量化 LoRA 模块,用于快速生成 |
| CLIPLoader / CLIPTextEncode | 文本提示解析,输出正向与反向条件 |
| EmptyHunyuanLatentVideo | 初始化潜空间,设定视频分辨率与帧长 |
| KSamplerAdvanced | 负责采样与扩散过程,决定生成速度与质量 |
| VAEDecode | 将潜变量解码为图像帧 |
| CreateVideo | 将多张图像合成为视频 |
| SaveVideo / SaveImage | 保存输出结果,支持视频与静态帧 |
工作流程
该工作流在设计上通过分阶段的串联实现了从文本输入到视频输出的全过程。首先加载 Wan2.2 的高噪与低噪模型,以及 LoRA、VAE 和 CLIP 编码器,为生成过程奠定基础。随后通过 EmptyHunyuanLatentVideo 初始化潜空间并设定分辨率与帧长,确保视频生成在可控范围内进行。正向与反向提示词由 CLIPTextEncode 节点解析,经过 KSamplerAdvanced 控制扩散与采样过程后生成潜变量,再由 VAE 解码成单帧图像。多张图像在 CreateVideo 节点中合成为视频,最终通过 SaveVideo 输出结果。同时,SaveImage 节点可以将关键帧单独保存,方便检查与二次创作。整个流程形成了清晰的链路,既保证了生成质量,也为灵活性和效率提供了支持。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 引入 Wan2.2 高噪/低噪 UNet 模型、LoRA、VAE 与 CLIP 编码器 | UNETLoader, LoraLoaderModelOnly, VAELoader, CLIPLoader |
| 2 | 潜空间初始化 | 设定视频尺寸与帧数,生成初始潜变量 | EmptyHunyuanLatentVideo |
| 3 | 文本提示解析 | 解析正向与反向提示词,提供条件约束 | CLIPTextEncode (Positive/Negative) |
| 4 | 采样生成 | 控制扩散与采样过程,生成潜变量序列 | KSamplerAdvanced, ModelSamplingSD3 |
| 5 | 解码成像 | 将潜变量解码为图像帧 | VAEDecode |
| 6 | 视频合成 | 将多帧图像组合为视频 | CreateVideo |
| 7 | 输出结果 | 保存视频文件与关键图像 | SaveVideo, SaveImage |
大模型应用
CLIPTextEncode(Positive / Negative) 文本语义驱动的核心入口
在整个 Wan2.2 T2V 工作流中,CLIPTextEncode 是负责"理解文本"的大模型节点,它将用户输入的文字 Prompt 转换为高维语义向量,作为生成视频画面的主要指导力量。
正向 Prompt 决定画面的主体、风格、情绪、光影与动作描述,而负向 Prompt 用来限制不期望出现的特征,约束模型避免生成过曝、模糊、畸形等质量缺陷。
由于视频生成过程极度依赖语义条件,因此 Prompt 在此节点中的作用尤为关键,几乎决定了最终成片的叙事逻辑、视觉质量与镜头气质。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode(Positive) | Beautiful young European woman with honey blonde hair... (完整原文已保留) | 将用户的正向描述编码为语义特征,是画面构成与角色意象的主要来源。 |
| CLIPTextEncode(Negative) | 色调艳丽,过曝,静态... 等大量质量限制词 (完整原文已保留) | 用来抑制低质量、畸形、不希望出现的画面特征,确保生成结果更干净、更自然。 |
UNETLoader + ModelSamplingSD3 视频扩散生成的解算核心
UNETLoader 负责加载 Wan2.2 的多版本扩散模型(高噪声 / 低噪声),而 ModelSamplingSD3 则控制模型在采样时的动态特性,两者共同构成视频生成的计算主体。
由于 Wan2.2 是专为视频训练的 T2V 模型,Prompt 语义会在扩散过程中持续影响每一帧潜空间的演化,而不同的噪声模型(高噪 / 低噪)也会导致 Prompt 在画面中体现的力度差异。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| UNETLoader | 无 Prompt | 承担扩散模型的所有计算,用于将语义条件转化为逐帧视频内容。 |
| ModelSamplingSD3 | 无 Prompt | 设定采样方式,使 Prompt 影响视频结构、动态与镜头表现。 |
KSamplerAdvanced 基于 Prompt 的逐帧扩散采样器
此节点根据 Prompt 语义、负向约束和扩散模型输出的特征,对视频潜空间进行多轮迭代计算。每一轮采样都重新应用 Prompt 语义,因此 Prompt 的叙事性、动作描述、光影描写都会直接反馈到视频动态中。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| KSamplerAdvanced | 由 Positive Prompt + Negative Prompt 输入 | 在扩散过程中持续施加文本语义,使视频的风格、主体、动作保持统一并符合 Prompt 设定。 |
使用方法
整个工作流通过三大步骤实现从文本到视频的自动化生成:首先加载 Wan2.2 T2V 的多模型结构(包含高噪声与低噪声版本,也可叠加 4Steps LoRA 加速推理),然后由 EmptyHunyuanLatentVideo 创建一个空白视频潜空间作为基础帧序列。接着用户输入的文本 Prompt 会被 CLIPTextEncode 转换成语义向量,正向 Prompt 用于定义视频中的人物、动作、镜头与光影,负向 Prompt 则限制低质量内容的出现。
在采样阶段,KSamplerAdvanced 结合 UNET 模型和采样器,将文本语义逐帧写入潜空间,生成具有动态效果的高质量画面;之后 VAE 将潜空间解码为视频帧,再统一组装为最终的视频文件。用户只需要修改 Prompt 或调整视频尺寸即可自动生成不同主题、不同风格的完整视频画面。
| 注意点 | 说明 |
|---|---|
| Prompt 决定视频风格与镜头表现 | 动作、光影、人物特征应尽量在正向 Prompt 里描述清晰 |
| 负向 Prompt 必须填写 | 可大幅减少畸形、模糊、过曝、背景紊乱等问题 |
| 视频尺寸越大越吃显存 | 640×640 是推荐的中等规格 |
| 4Steps LoRA 会牺牲动态 | 优点是速度快,可用于快速预览 |
| 高噪 / 低噪模型生成风格不同 | 高噪更有动态张力,低噪更稳定清晰 |
| KSampler 的步数直接影响画质 | 步数越高越细腻,但生成时间更长 |
| VAE 解码影响最终色彩与细节 | 建议保持默认的 wan_2.1_vae |
应用场景
该工作流适用于多种视频生成与创作场景。在影视和广告领域,可以快速生成风格统一的短视频素材,满足品牌宣传与视觉创意需求。在教育和培训中,能够生成场景化的教学视频,增强知识传递的直观性。在个人创作方面,既能实现艺术风格的视频表达,也能用于动画人物的动态生成。结合高噪与低噪模型的双路径设计,使其既能在高性能显卡环境下输出高质量视频,也能通过 LoRA 方案在有限算力条件下实现快速生成,从而覆盖了专业与大众创作者的使用需求。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 影视广告 | 生成短视频与广告素材 | 广告公司、影视制作人 | 品牌宣传片、广告动画 | 快速产出高质量视频,降低制作成本 |
| 教学培训 | 构建教学场景视频 | 教育机构、教师 | 课程演示、知识动画 | 提升教学直观性与学习兴趣 |
| 个人创作 | 动态艺术与角色动画 | 独立创作者、设计师 | 艺术风格短片、人物动态演示 | 增强创意表达与个性化输出 |
| 游戏开发 | 场景与角色视频生成 | 游戏美术、开发团队 | NPC 动态演示、游戏过场 | 缩短视频素材制作周期 |
| 内容运营 | 社交媒体短视频生产 | 自媒体人、运营人员 | 平台短视频内容 | 提升内容更新效率与视觉吸引力 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用