文章目录
- 前言
- 计算机网络和因特网
-
- 什么是因特网
- 网络边缘
-
- 接入网
-
- 家庭接入:DSL、电缆、FTTH
- 企业(和家庭)接人:以太网和WiFi
- [广域无线接人: 4G 和 LTE(书中是3G但目前普遍是4G)](#广域无线接人: 4G 和 LTE(书中是3G但目前普遍是4G))
- 物理媒体(仅作介绍,可自行查阅资料)
- 网络核心
- 分组交换网中的时延、丢包和吞吐量
- 协议层次及其服务模型
-
- 分层的体系结构
-
- 协议分层(5层因特网协议栈)
- [OSI 摸型](#OSI 摸型)
- 封装
- 面对攻击的网络(不做介绍)
- 计算机网络和因特网的历史(不做介绍)
- 参考目录
前言
阅读本文前请注意最后编辑时间,文章内容可能与目前最新的技术发展情况相去甚远。欢迎各位评论与私信,指出错误或是进行交流等。
本文是关于《计算机网络:自顶向下方法(第七版)》第一章的学习分享,内容书写顺序也是按照书中的顺序。本文并不会提及书中的所有内容,主要写重点的知识,以及自己感兴趣的内容。会对原文中的内容进行一定的精简,或者加上个人的理解。
计算机网络和因特网
什么是因特网
因特网构成描述
因特网是一个世界范围的计算机网络,即它是一个互联了遍及全世界数十亿计算设备的网络。 计算设备多数是传统的桌面PC、 Linux工作站以及所谓的服务器, 然而,越来越多的非传统的因特网"物品"(如便携机、 智能手机、平板电脑、电视、游戏机、温度调节装置、家用安
全系统、家用电器、手表、 眼镜、汽车、运输控制系统等)正在与因特网相连。 用因特网术语来说,所有这些设备都称为主机 (host) 或端系统 (end system) 。
端系统通过通信链路 (communication link) 和分组交换机 (packet switch) 连接到一起。 通信链路,它们由不同类型的物理媒体组成。 这
些物理媒体包括同轴电缆、铜线、光纤和无线电频谱。 不同的链路能够以不同的速率传输数据,链路的传输速率 (transmission rate) 以比特/秒 (bills, 或 bps) 度量。
当一台端系统要向另一台端系统发送数据时,发送端系统将数据分段,并为每段加上首部字节。 由此形成的信息包用计算机网络的术语来说称为分组 (packet)。
分组交换机从它的一条入通信链路接收到达的分组,并从它的一条出通信链路转发该分组。 在当今的因特网中,两种最著名的类型是路由器 (router) 和链路层交换机 (link-layer swtch) 。
端系统通过因特网服务提供商 (Internet Service Provider, ISP) 接入因特网,包括如本地电缆或电话公司那样的住宅区ISP、 公司 ISP、 大学 ISP, 在机场、旅馆、 咖啡店和其他公共场所提供WiFi 接入的 ISP, 以及为智能手机和其他设备提供移动接入的蜂窝数据ISP。 每个 ISP 自身就是一个由多台分组交换机和多段通信链路组成的网络。 各ISP为端系统提供了各种不同类型的网络接入,包括如线缆调制解调器或DSL那样的住宅宽带接入、高速局域网接入和移动无线接人。 ISP也为内容提供者提供因特网接入服务,将 Web站点和视频服务器直接连入因特网。 因特网就是将端系统彼此互联,因此为端系统提供接入的lSP 也必须互联。
个人理解 Internet Service Provider, ISP 从字面意思上看是因特网服务提供者,书本中翻译为提供商,但从后面的举例中来看有些接入ISP并不是商业性的。本地电缆或电话公司那样的住宅区ISP(在国内可以理解为移动/联通等电话公司,提供了因特网接入服务),但像公司ISP/大学ISP/在机场、旅馆、 咖啡店和其他公共场所提供WiFi 接入的 ISP/这些接入点 可能是免费提供的。我们的端系统与这些接入点相连(例如使用网线连接我们的设备 或者 通过WiFi连接 可以获得因特网服务,这些接入点 他们一般情况下也是先接入了类似于联通等因特网提供商)。以及为智能手机和其他设备提供移动接入的蜂窝数据ISP(例如手机通过电话卡使用蜂窝移动数据流量进行上网)
通过所提供的服务描述因特网
除了从构成因特网的部件来认识因特网。 我们也能从一个完全不同的角度,即从为应用程序提供服务的基础设施的角度来描述因特网。 除了诸如电子邮件和Web 冲浪等传统应用外,因特网应用还包括移动智能手机和平板电脑应用程序,其中包括即时讯息、与实时道路流量信息的映射、来自云的音乐流、电影和电视流、在线社交网络、视频会议、多人游戏以及基于位置的推荐系统。 因为这些应用程序涉及多个相互
交换数据的端系统,故它们被称为分布式应用程序 (distributed application) 。 重要的是,因特网应用程序运行在端系统上,即它们并不运行在网络核心中的分组交换机中。 尽管分组交换机能够加速端系统之间的数据交换,但它们并不在意作为数据的源或宿的应用程序。
运行在不同端系统上的软件将需要互相发送数据。 此时我们碰到一个核心问题, 运行在一个端系统上的应用程序怎样才能指令因特网向运行在另一个端系统上的软件发送数据呢?与因特网相连的端系统提供了一个套接字接口 (socket interface) , 该接口规定了运行在一个端系统上的程序请求因特网基础设施向运行在另一个端系统上的特定目的地程序交付数据的方式。 因特网套接字接口是一套发送程序必须遵循的规则集合,因此因特网能够将数据交付给目的地。
此时,我们做一个简单的类比。 假定Alice使用邮政服务向 Bob发一封信。当然, Alice 不能只是写了这封信(相关数据)然后把该信丢出窗外。 相反,邮政服务要求 Alice 将信放入一个信封中;在信封的中间写上 Bob 的全名、地址和邮政编码;封上信封;在信封的右上角贴上邮票;最后将该信封丢进一个邮局的邮政服务信箱中。 因此,该邮政服务有自己的"邮政服务接口"或一套规则,这是Alice必须遵循的,这样邮政服务才能将她的信件交付给Bob。 同理,因特网也有一个发送数据的程序必须遵循的套接字接口,使因特网向接收数据的程序交付数据。当然,邮政服务向顾客提供了多种服务,如特快专递、挂号、普通服务等。 同样,因特网向应用程序提供了多种服务。 当你研发一种因特网应用程序时,也必须为你的应用程序选择其中的一种因特网服务。
什么是网络协议
网络协议 :定义了在两个或多个通信实体之间交换的报文的格式和顺序,以及报文发送或接收一条报文或其他事件所采取的动作。
网络边缘
与因特网相连的计算机和其他设备称为端系统。 因为它们位于因特网的边缘, 故而被称为端系统。 因特网的端系统包括了桌面计算机(例如,桌面PC、 Mac 和Linux设备)、 服务器(例如, Web和电子邮件服务器)和移动计算机 (例如,便携机、智能手机和平板电脑)。 此外,越来越多的非传统物品正被作为端系统与因特网相连
端系统也称为主机 (host) , 因为它们容纳(即运行)应用程序,如 Web浏览器程序、 Web 服务器程序、电子邮件客户程序或电子邮件服务器程序等。 主机有时又被进一步划分为两类:客户(client) 和服务器 (server) 。 客户通常是桌面 PC、移动 PC 和智能手机等,而服务器通
常是更为强大的机器,用于存储和发布 Web页面、流视频、中继电子邮件等。
接入网
接入网,是指将端系统物理连接到其边缘路由器(edgerouter)的网络。边缘路由器是端系统到任何其他远程端系统的路径上的第一台路由器。
家庭接入:DSL、电缆、FTTH
注:这里没有给出DSL、电缆、FTTH的图片,大家可以自行上网搜索,可能在现实生活中见过这些线。
数字用户线(Digital Subscriber Line, DSL)。住户从提供本地电话接入的本地电话公司处获得DSL因特网接入。因此,当使用DSL时,用户的本地电话公司是它的lSP。每个用户的DSL调制解调器使用现有的电话线(即双绞铜线)与位于电话公司的本地中心局 (CO) 中的数字用户线接入复用器 (DSLAM) 交换数据。家庭的 DSL调制解调器得到数字数据后将其转换为高频音(模拟信号),以通过电话线传输给本地中心局;来自家庭的模拟信号在DSLAM处被转换回数字形式。如下图所示
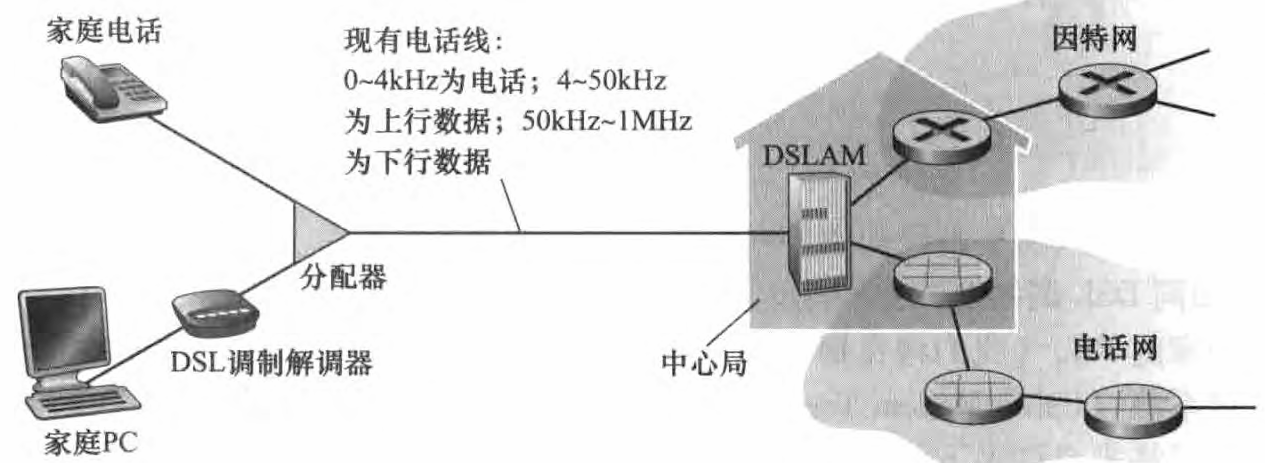
这种方法使单根DSL线路看起来就像有3 根单独的线路一样, 因此一个电话呼叫和一个因特网连接能够同时共享DSL链路。在用户一
侧,一个分配器把到达家庭的数据信号和电话信号分隔开,并将数据信号转发给DSL调制解调器。 在电话公司一侧,在本地中心局中, DSLAM把数据和电话信号分隔开,并将数据送往因特网。 数百甚至上千个家庭与同一个DSLAM相连 。
DSL 利用电话公司现有的本地电话基础设施,而电缆因特网接入利用了有线电视公司现有的有线电视基础设施。 住宅从提供有线电视的公司获得了电缆因特网接入。如下图所示,光缆将电缆头端连接到地区枢纽(光缆与光缆节点相连),光缆节点后使用传统的同轴电缆到达各家各户。 每个地区枢纽(光缆节点)通常支持500-5000个家庭。 因为在这个系统中应用了光纤和同轴电缆,所以它经常被称为混合光纤同轴 (Hybrid Fiber Coax , HFC) 系统。
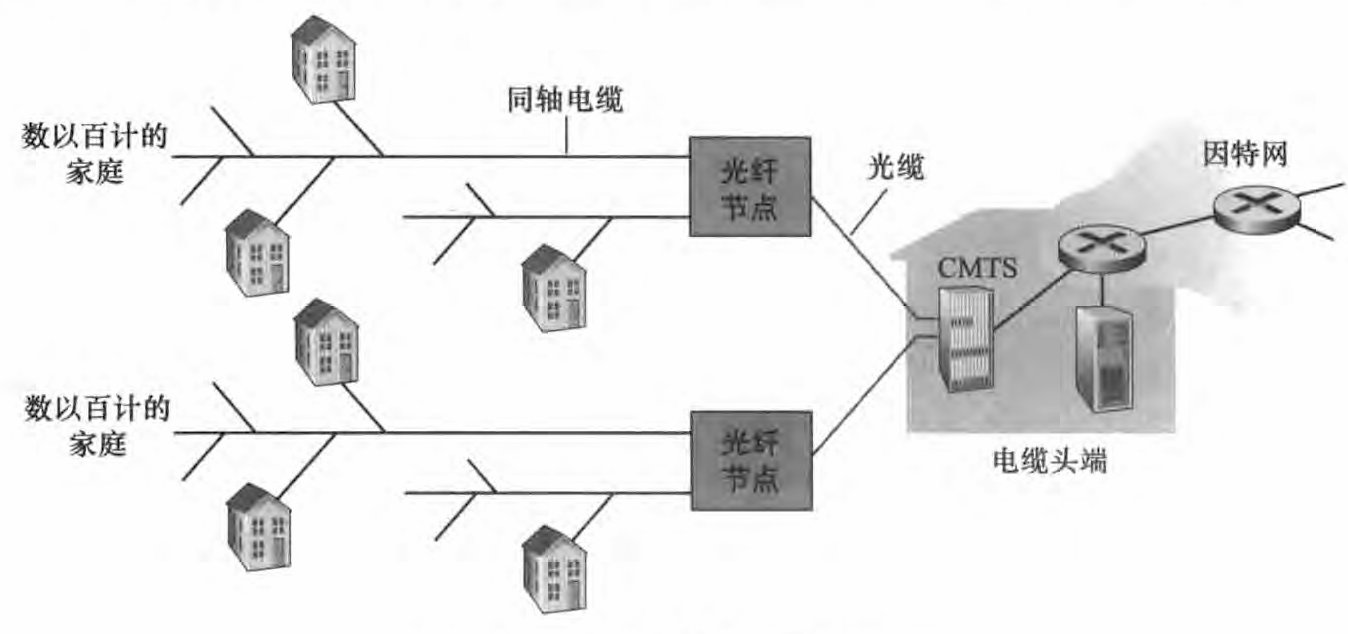
电缆因特网接入需要特殊的调制解调器,这种调制解调器称为电缆调制解调器。 电缆调制解调器端接系统 (Cable Modem Termination System, CMTS) 与 DSL 网络的 DSLAM 具有类似的功能,即将来自许多家庭中的电缆调制解调器发送的模拟信号转换回数字形式。
电缆因特网接入的一个重要特征是共享广播媒体。 特别是,由电缆头端发送的每个分组经每段链路到每个家庭;每个家庭发送的每个分组经上行信道向电缆头端传输。 因此,如果几个用户同时经下行信道下载一个视频文件,每个用户接收视频文件的实际速率将大大低于电缆总计的下行速率。 而另一方面,如果仅有很少的活跃用户在进行Web 冲浪,则每个用户都可以以全部的下行速率接收Web 网页,因为用户们很少在完全相同的时刻请求网页。
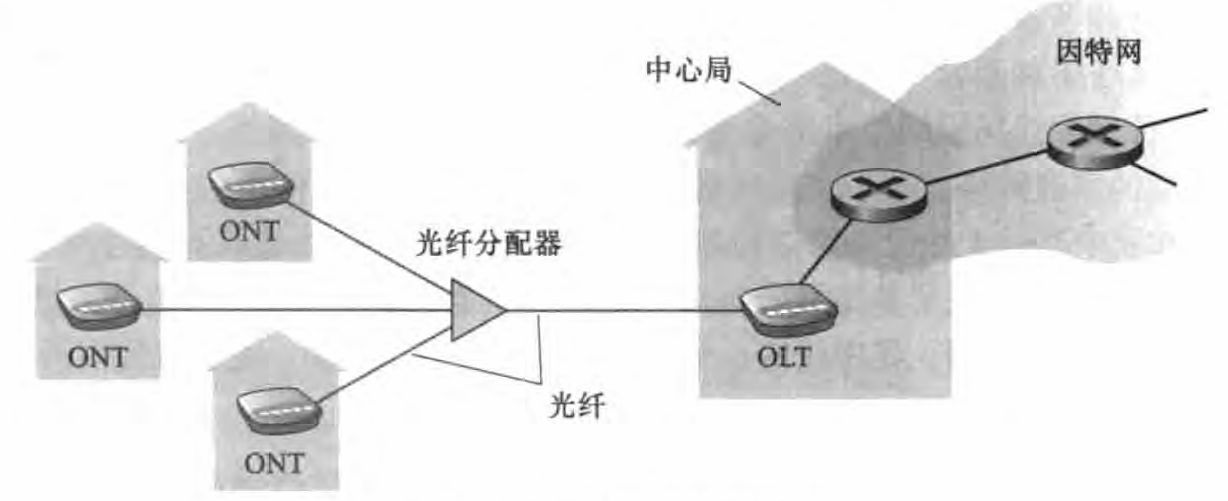
光纤到户 (FiberTo The Home , FTTH) 是目前更为常见的一种因特网接入方式。最简单的光纤分布网络称为直接光纤,从本地中心局到每户设置一根光纤。 更为一般的是,从中心局出来的每根光纤实际上由许多家庭共享,直到相对接近这些家庭的位置,该光纤才分成每户一根光纤。
每个家庭具有一个光纤网络端接器 (Optical Network Terminator, ONT) , 它由专门的光纤连接到邻近的分配器 (splitter) 。 该分配器把一些家庭(通常少千100 个)集结到一根共享的光纤,该光纤再连接到本地电话和公司的中心局中的光纤线路端接器 (Optical Line Terminator , 0 LT) 。 该 OLT 提供了光信号和电信号之间的转换,经过本地电话公司路由器与因特网相连。 在家庭中,用户将一台家庭路由器(通常是
无线路由器)与ONT相连,并经过这台家庭路由器接入因特网。 如下图所示
个人理解:FTTH是我们目前生活中常见的因特网接入方式。
光猫(光调制解调器),运营商提供的宽带接入设备,负责将光纤中的光信号转换为电信号,并实现协议转换(如PPPoE拨号),通常有多个网口和WiFi功能
家庭中使用光猫,与运营商所建设的光纤相连。多个家庭的光猫所连接的光纤集中连接到一个光纤分配器上,再经过一条光纤与运营商的光纤线路端接器(OLT)相连,OLT再通过与交换机/路由器,从而与因特网连接。
企业(和家庭)接人:以太网和WiFi
在公司和大学校园以及越来越多的家庭环境中,使用局域网 (LAN) 将端系统连接到边缘路由器。 尽管有许多不同类型的局域网技术,但是以太网到目前为止是公司、大学和家庭网络中最为流行的接入技术。 如图所示,用户使用双绞铜线与一台以太网交换机相连,以太网交换机则再与更大的因特网相连。(下图中以太网交换机直接与一台边缘路由器相连,当然这台交换机也可以与另外的交换机相连接从而连接更多的子网和设备,当然最终是会有一台交换机与路由器相连,使得设备都接入因特网)
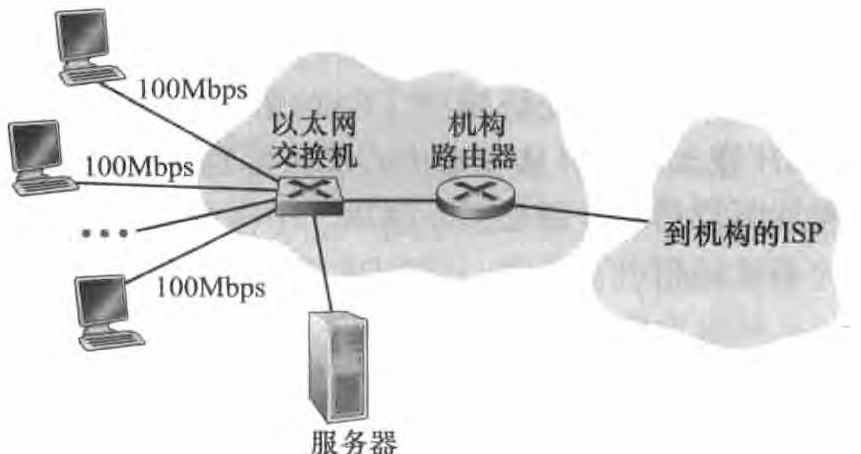
局域网(LAN)是指在有限地理范围内(如家庭、办公室或校园)将多台计算机互联起来,实现高速数据传输和资源共享的网络。
以太网是一种计算机局域网技术。
越来越多的人将便携机、智能手机、平板电脑和其他物品无线接入因特网,在无线局域网环境中,无线用户向一个接入点发送分组,从该接入点接收分组。该无线接入点可能与路由器连接 ,路由器再通过线路与因特网相连。 一个无线LAN 用户通常位于接入点的几十米范围内。 基于IEEE802. 11 技术的无线LAN 接入,更通俗地称为 WiFi, 目前几乎无所不在。
广域无线接人: 4G 和 LTE(书中是3G但目前普遍是4G)
iPhone 和安卓等设备越来越多地用来在移动中发信息、在社交网络中分享照片、观看视频和放音乐。 这些设备应用了与蜂窝移动电话相同的无线基础设施,通过蜂窝网提供商运营的基站来发送和接收分组。 与 WiFi 不同的是, 一个用户仅需要位于基站的数万米(而不是几十米)范围内
仅作了解:
4G是第四代移动通信技术的总称,而LTE(长期演进)是4G的核心技术标准之一。简单说,4G是"家族",LTE是家族里最主流的"成员"。
LTE最初是3G的增强版(3.9G),后来通过技术升级(如载波聚合)达到了4G标准。它采用了OFDM和MIMO等先进技术,在20MHz带宽下能实现100Mbps下行和50Mbps上行速度。运营商常说的"4G LTE"或"LTE-A"都属于4G范畴。
物理媒体(仅作介绍,可自行查阅资料)
在前面的内容中,我们概述了因特网中某些最为重要的网络接入技术。 当我们描述这些技术时,我们也指出了所使用的物理媒体。 例如,我们说过HFC使用了光缆和同轴电缆相结合的技术。 我们说过DSL和以太网使用了双绞铜线。 我们也说过移动接入网使用了无线电频谱。 在这一节中,我们简要概述一下这些和其他常在因特网中使用的传输媒体。
为了定义物理媒体所表示的内容,我们仔细思考一下一个比特的短暂历程。 考虑一个比特从一个端系统开始传输,通过一系列链路和路由器,到达另一个端系统。 这个比特被漫不经心地传输了许许多多次!源端系统首先发射这个比特,不久后其中的第一台路由器接收该比特;第一台路由器发射该比特,接着不久后第二台路由器接收该比特; 等等。 因此,这个比特当从源到目的地传输时,通过一系列"发射器-接收器"对。 对千每个发射器-接收器对,通过跨越一种物理媒体 (physical meclium) 传播电磁波或光脉冲来发送该比特。 该物理媒体可具有多种形状和形式,并且对沿途的每个发射器-接收器对而言不必具有相同的类型。 物理媒体的例子包括双绞铜线、 同轴电缆、 多模光纤缆、陆地无线电频谱和卫星无线电频谱。
网络核心
分组交换
在各种网络应用中、端系统彼此交换报文 (nlessage)。 报文能够包含协议设计者需要的任何东西( 报文可以执行一种控制功能),也可以包含数据,例如电子邮件数据、 JPEG 图像或 MP3 音频文件。 为了从源端系统向目的端系统发送一个报文、 源将长报文划分为较小的数据块,称之为分组( packet) 。 在源和目的地之间,每个分组都通过通信链路和分组交换机 (packet switch) (分组交换机主要有两类:路由器 (router) 和链路层交换机 (link-layer switch) 。)分组以等于该链路最大传输速率的速度传输通过通信链路。 因此,如果某源端系统或分组交换
机经过一条链路发送一个L 比特的分组,链路的传输速率为R 比特/秒,则传输该分组的时间为L/R 秒。
存储转发传输
多数分组交换机在链路的输入端使用存储转发传输 (store-and-forward transmission) 机制。 存储转发传输是指分组交换机开始向输出链路传输该分组的第一个比特之前,必须接收到整个分组。
如下图所示一台路由器通常有多条繁忙的链路, 因为它的任务就是把一个入分组交换到一条出链路。 在这个简单例子中,该路由器的任务相当简单:将分组从一条(输入)链路转移到另一条唯一的连接链路。在图中所示的特定时刻,源已经传输了分组1的一部分,分组1的前部分已经到达了路由器。 因为该路由器应用了存储转发机制,所以此时它还不能传输已经接收的比特,而是必须先缓存(即"存储")该分组的比特。 仅当路由器已经接收完了该分组的所有比特后,它才能开始向出链路传输(转发)该分组。
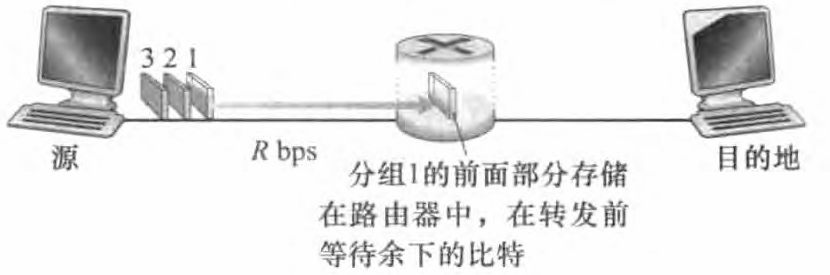
现在我们来计算从源开始发送第一个分组 到 目的地接收到所有三个分组所需的时间。每个分组为L比特,链路传输速度为R bps。与前面一样,在时刻L/R, 路由器已经接收完了第一个分组的所有比特,并后开始转发第一个分组。 而在时刻 L/R 源也开始发送第二个分组,因为它已经完成了第一个分组的完整发送。 因此,在时刻2L/R, 目的地已经收到第一个分组并且路由器已经收到第二个分组。 类似地,在时刻3L/R, 目的地巳经收到前两个分组并且路由器已经收到第三个分组。 最后,在时刻4L/R, 目的地已经收到所有3个分组。
我们现在来考虑下列一般情况: 通过由 N 条速率均为 R 的链路组成的路径(在源和目的地之间有 N-1 台路由器),从源到目的地发送一个分组。 应用如上相同的逻辑,我们看到端到端时延是:
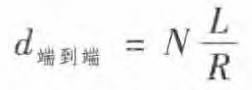
假设有P个分组经过N条链路的总端到端时延是:(N+P-1)L/R
排队时延和分组丢失
每台分组交换机有多条链路与之相连。 对于每条相连的链路,该分组交换机具有一个输出缓存 (output buffer, 也称为输出队列 (output queue)) , 它用于存储路由器准备发往那条链路的分组。 该输出缓存在分组交换中起着重要的作用。 如果到达的分组需要传输到某条链路, 但发现该链路正忙于传输其他分组,该到达分组必须在输出缓存中等待。 因此,除了存储转发时延以外,分组还要承受输出缓存的排队时延 (queuing delay)。 这些时延是变化的,变化的程度取决于网络的拥塞程度。 因为缓存空间的大小是有限的, 一个到达的分组可能发现该缓存巳被其他等待传输的分组完全充满了。 在此情况下,将出现分组丢失(丢包) (packet loss) , 到达的分组或已经排队的分组之一将被丢弃。
转发表和路由选择协议
前面我们说过,路由器从与它相连的一条通信链路得到分组,然后向与它相连的另一条通信链路转发该分组。 但是路由器怎样决定它应当向哪条链路进行转发呢?
在因特网中,每个端系统具有一个称为 IP地址的地址 。当源主机要向目的端系统发送一个分组时,源在该分组的首部包含了目的地的IP地址、 如同邮政地址那样, 该地址具有一种等级结构。 当一个分组到达网络中的路由器时, 路由器检查该分组的目的地址的一部分, 并向一台相邻路由器转发该分组。 更特别的是,每台路巾器具有一个转发表( forwarding table) , 用于将目的地址映射成为输出链路。当某分组到达一台路由器时,路由器检查该地址,并用这个目的地址搜索其转发表,以发现适当的出链路。 路由器则将分组导向该输出链路。
电路交换
通过网络链路和交换机移动数据还有一种基本方法:电路交换 (circuit switching)
在电路交换网络中,在端系统间预留了通信所需要的资源(缓存,链路传输速率)。 在分组交换网络中.这些资源则不是预留的;会话的报文按需使用这些资源,其后果可能是不得不等待(即排队)接入通信线路。 一个简单的类比是,考虑两家餐馆, 一家需要顾客预订,而另一家不需要预订,但不保证能安排顾客。 对于需要预订的那家餐馆,我们在离开家之前必须先打电话预订,但当我们到达该餐馆时,原则上我们能够立即入座并点菜, 对于不需要预订的那家餐馆,我们不必麻烦地预订餐桌,但当我们到达该餐馆时,也许不得不先等待一张餐桌空闲后才能入座。
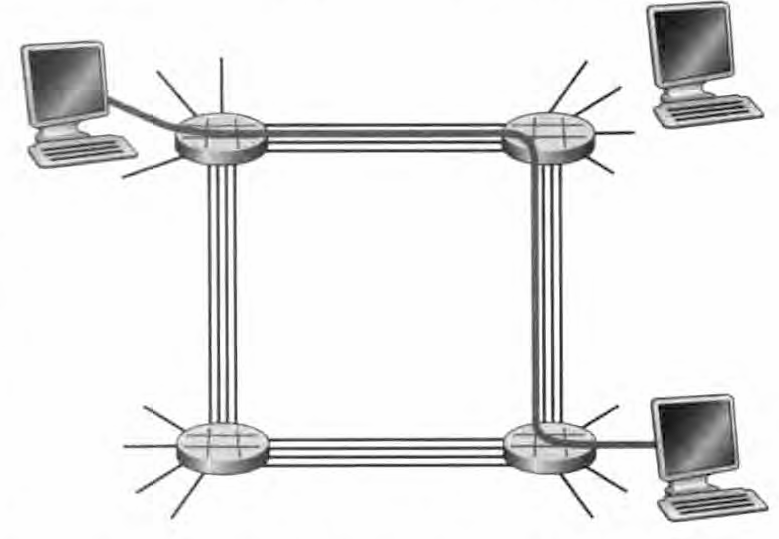
传统的电话网络是电路交换网络的例子,当一个人通过电话网向另一个人发送信息(语音或传真)时所发生的情况。在发送方能够发送信息之前,该网络必须在发送方和接收方之间建立一条连接,这是一个名副其实的连接,因为此时沿着发送方和接收方之间路径上的交换机都将为该连接维护连接状态。 用电话的术语来说,该连接被称为一条电路(circuit) 。
当网络创建这种电路时,它在连接期间在该网络链路上预留了恒定的传输速率(表示为每条链路传输容量的一部分。既然已经为该发送方-接收方连接预留了带宽,则发送方能够以确保的恒定速率向接收方传送数据。
如图显示了一个电路交换网络。在这个网络中,用4条链路互联了4 台电路交换机。这4条链路每条都有4条电路,因此每条链路能够支持4条并行的连接。 每台主机(例如PC 和工作站)都与一台交换机直接相连。当两台主机要通信时,该网络在两台主机之间创建一条专用的端到端连接。因此,主机 A 为了向主机 B 发送报文,网络必须在两条链路上先预留一条电路。在图中,这条专用的端到端连接使用第一条链路中的第二条电路和第二条链路中的第四条电路,因为每条链路具有4 条电路,对于由端到端连接所使用的每条链路而言,该连接在连接期间获
得链路总传输容量的1/4。
与此相反,考虑一台主机要经过分组交换网络(如因特网)向另一台主机发送分组所发生的情况。 与使用电路交换相同,该分组经过一系列通信链路传输。 但与电路交换不同的是,该分组被发送进网络,而不预留任何链路资源之类的东西。 假如此时其他分组也经该链路进行传输,而使链路之一出现拥塞,则该分组将不得不在传输链路发送侧的缓存中等待而产生时延。 因特网尽最大努力以实时方式交付分组,但它不做任何保证。
电路交换网络中的复用
频分复用:频分复用(FDM,Frequency Division Multiplexing)就是将用于传输信道的总带宽划分成若干个子频带(或称子信道),每一个子信道传输1路信号。频分复用要求总频率宽度大于各个子信道频率之和,同时为了保证各子信道中所传输的信号互不干扰,应在各子信道之间设立隔离带,这样就保证了各路信号互不干扰(条件之一)。频分复用技术的特点是所有子信道传输的信号以并行的方式工作
时分复用:时分复用(Time-Di vision Multiplexing, TDM )是采用同一物理连接的不同时段来传输不同的信号,也能达到多路传输的目的。时分多路复以时间作为信号分割的参量,故必须使各路信号在时间轴上互不重叠。将提供给整个信道传输信息的时间划分成若干时间片(简称时隙),并将这些时隙分配给每一个信号源使用,保证资源的利用率。
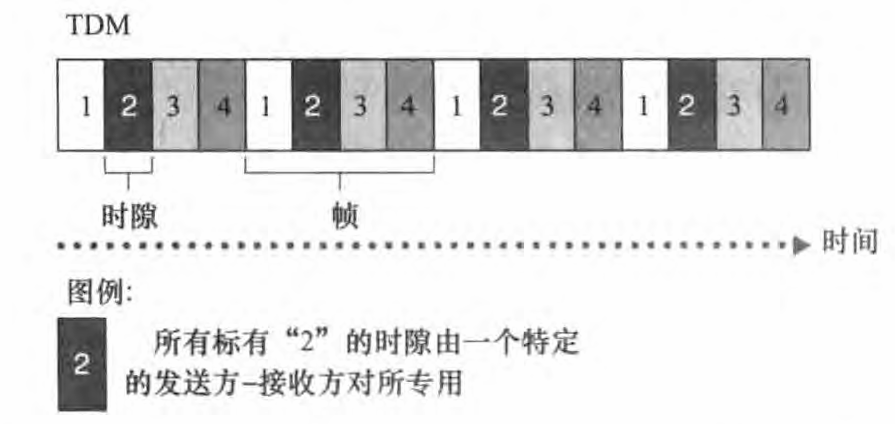
对千 FDM, 每条电路连续地得到部分带宽。 对于TDM, 每条电路在短时间间隔(即时隙)中周期性地得到所有带宽
在频分复用中引入带宽的概念。带宽(Bandwidth)指信号所占据的频带宽度;在被用来描述信道时,带宽是指能够有效通过该信道的信号的最大频带宽度。对于模拟信号而言,带宽又称为频宽,以赫兹(Hz)为单位。例如模拟语音电话的信号带宽为3100Hz(从300Hz到3400Hz)。对于数字信号而言,带宽是指单位时间内链路能够通过的数据量。例如ISDN的B信道带宽为64Kbps。由于数字信号的传输是通过模拟信号的调制完成的,为了与模拟带宽进行区分,数字信道的带宽一般直接用波特率或符号率来描述。
对于波特率和符号率有兴趣的小伙伴可以自行查阅,简单来区分的话模拟信号的带宽一般以赫兹(Hz)为单位。数字信号的带宽一般以bps为单位。
网络的网络
我们在前面看到,端系统 (PC、智能手机、 Web 服务器、 电子邮件服务器等)经过一个接入ISP 与因特网相连。 该接入ISP能够提供有线或无线连接,使用了包括DSL、电缆、 FTTH、 WiFi 和蜂窝等多种接入技术。 值得注意的是接入 ISP 不必是电信局或电缆公司,相反,它能够是如大学(为学生、教职员工和从业人员提供因特网接入)或公司(为其雇员提供接入)这样的单位。 但让端用户和内容提供商连接到接入ISP仅解决了连接难题中的很小一部分,因为因特网是由数以亿计的用户构成的。要解决这个难题,接入ISP 自身必须互联。 通过创建网络的网络可以做到这一点,理解这个短语是理解因特网的关键。
接入ISP 的中心目标,是使所有端系统能够彼此发送分组。 一种幼稚的方法是使每个接入ISP直接与每个其他接入 ISP连接。当然,这样的网状设计对于接入 lSP费用太高,因为这将要求每个接入 ISP要与世界上数十万个其他接入ISP 有一条单独的通信链路。
我们的第一个网络结构即网络结构1,用单一的全球传输ISP互联所有接入ISP。 我们假想的全球传输 ISP是一个由路由器和通信链路构成的网络,该网络不仅跨越全球,而且至少具有一台路由器靠近数十万接入 ISP 中的每一个。 当然,对于全球传输ISP, 建造这样一个大规模的网络将耗资巨大。 为了有利可图,自然要向每个连接的接入ISP收费,其价格反映(并不一定正比于) 一个接入ISP经过全球 ISP交换的流量大小。因为接入 ISP向全球传输ISP付费,故接入ISP被认为是客户 (customer) , 而全球传输 lSP 被认为是提供商 (provider) 。
如果某个公司建立并运营一个可赢利的全球传输ISP, 其他公司建立自己的全球传输ISP, 并与最初的全球传输ISP竞争则是一件自然的事。 这导致了网络结构2, 它由数十万接入ISP 和多个全球传输ISP组成。 接入lSP无疑喜欢网络结构2 胜过喜欢网络结构1。因为,它们现在能够根据价格和服务因素在多个竞争的全球传输提供商之间进行选择。 然而,值得注意的是,这些全球传输ISP之间必须是互联的;不然的话,与某个全球传输ISP连接的接入ISP将不能与连接到其他全球传输ISP的接入ISP进行通信。
刚才描述的网络结构2是一种两层的等级结构,其中全球传输提供商位于顶层,而接入 ISP 位于底层。
现实中、 尽管某些 ISP确实具有令人印象深刻的全球覆盖,并且确实直接与许多接入ISP连接,但世界上没有哪个 ISP 是无处不在的。 相反,在任何给定的区域,可能有一个区域ISP (regional ISP) , 区域中的接入 ISP 与之连接。 每个区域 ISP 则与第一层ISP连接。 第一层 ISP 类似于我们假想的全球传输 lSP, 尽管它不是在世界上每个城市中都存在,但它确实存在,有大约十几个第一层 ISP。
在这样的等级结构中,每个接入 ISP 向其连接的区域 ISP 支付费用,并且每个区域ISP 向它连接的第一层ISP 支付费用。我们称它为网络结构3。
将位于相同等级结构层次的邻近一对ISP 的关系成为对等,也就是说,能够直接将它们的网络连到一起,使它们之间的所有流量直接连接而不是通过上游的ISP传输。 第三方公司创建一个因特网交换点 (Internet Exchange Point, IXP) , IXP 是一个汇合点,多个 ISP能够在这里一起对等传输数据。在网络结构3的基础上引入对等和IXP,我们称这个生态系统为网络结构4。
网络结构5, 它通过在网络结构4顶部增加内容提供商网络 (content provider network) 构建而成。谷歌是当前这样的内容提供商网络的一个突出例子。
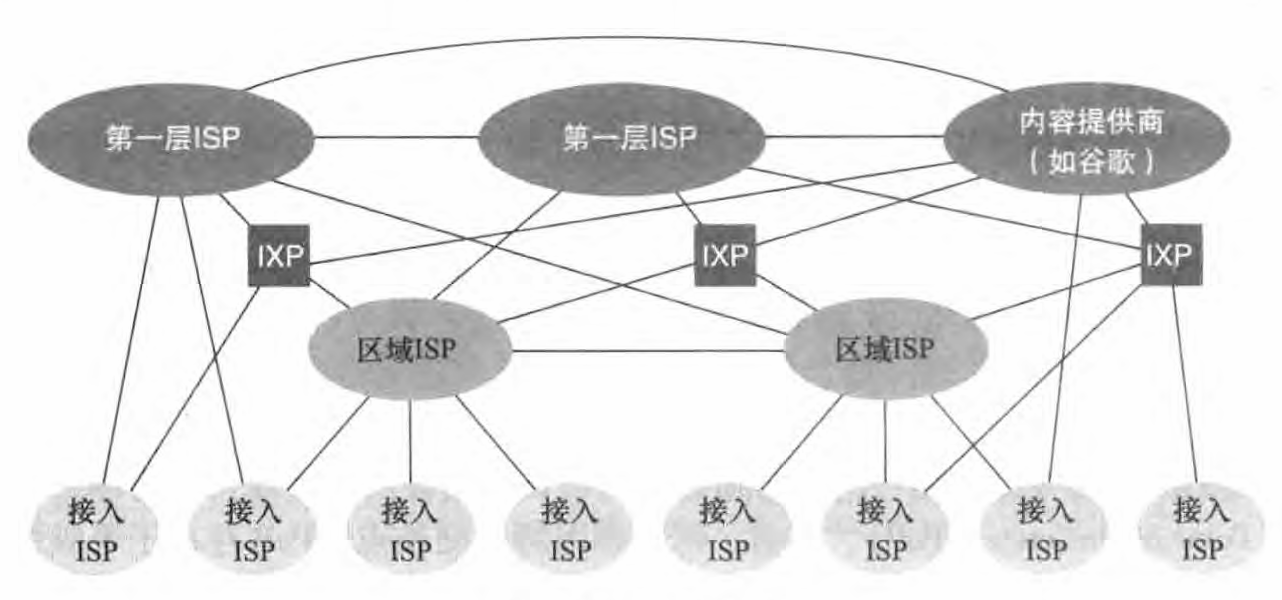
总结一下,今天的因特网是一个网络的网络, 其结构复杂,由十多个第一层ISP和数十万个较低层ISP组成。 ISP覆盖的区域多种多样,有些跨越多个大洲和大洋,有些限于狭窄的地理区域。 较低层的ISP与较高层的 ISP 相连,较高层 ISP彼此互联。 用户和内容提供商是较低层ISP 的客户,较低层ISP 是较高层 ISP 的客户。 近年来,主要的内容提供商也已经创建自己的网络,直接在可能的地方与较低层ISP互联
分组交换网中的时延、丢包和吞吐量
在理想情况下,我们希望因特网服务能够在任意两个端系统之间随心所欲地瞬间移动数据而没有任何数据丢失。 然而,这是一个极高的目标, 实践中难以达到。 与之相反,计算机网络必定要限制在端系统之间的吞吐量 (每秒能够传送的数据量),在端系统之间引入时延,而且实际上也会丢失分组。
分组交换网中的时延概述
当分组从一个节点(主机或路由器)沿着这条路径到后继节点(主机或路由器),该分组在沿途的每个节点经受了几种不同类型的时延。 这些时延最为重要的是节点处理时延 (nodal processing delay) 、排队时延 (queuing delay) 、 传输时延( transmission delay) 和传播时延 (propagation delay) , 这些时延总体累加起来是节点总时延 (total nodal delay)
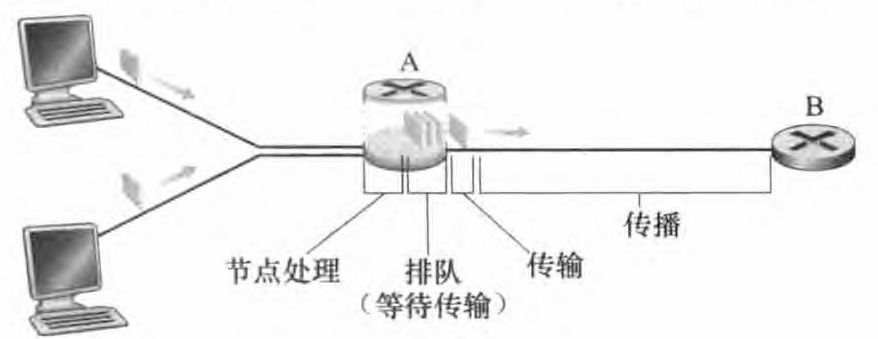
如上图所示,路由器A具有通往路由器B 的出链路。 该链路前有一个队列,分组正在排队等待传输(也称为缓存)。 当分组从上游节点到达路由器A 时,路由器A 检查该分组的首部以决定合适的出链路。在此处,该分组的出链路是通向路由器B 的那条链路。仅当在该链路没有其他分组正在传输 并且 没有其他分组排在该分组前面时,才能在这条链路上传输该分组;如果该链路当前正繁忙 或 有其他分组已经在该链路上排队,则新到达的分组将加入排队。
处理时延
检查分组首部 并 决定将该分组导向何处 所需要的时间是处理时延的一部分。 处理时延也能够包括其他因素,如检查比特级别的差错所需要的时间,该差错出现在从上游节点向路由器A传输这些分组比特的过程中。 高速路由器的处理时延通常是微秒或更低的数量级。在这种节点处理之后,路由器将该分组引向通往路由器B链路之前的队列。
(这里讲的处理时延 是指在路由器或者是交换机上发生的处理,并且处理的任务也不仅仅是所提到的两种。)
排队时延
在队列中,当分组在链路上等待传输时,它经受排队时延。 一个分组的排队时延将取决于先前到达的正在排队等待向链路传输的分组数量。 如果该队列是空的,并且当前没有其他分组正在传输,则该分组的排队时延为0。 另一方面,如果流量很大,并且许多其他分组也在等待传输,该排队时延将很长
传输时延
假定分组以先到先服务方式传输,这在分组交换网中是常见的方式,仅当所有已经到达的分组被传输后,才能传输刚到达的分组。 用L 比特表示该分组的长度,用 R bps 表示从路由器A 到路由器B 的链路传输速率。 例如,对于一条10Mbps的以太网链路,速率R= 10Mbps; 对于 100Mbps 的以太网链路,速率 R = 100Mbps。 传输时延是 L/R。 这是将该分组的所有比特推向链路(即传输)所需要的时间。
传输时延(也称为发送时延)是指数据从网络设备的发送端完全进入传输介质所需的时间。具体来说,它从数据帧开始发送的那一刻起算,到数据帧最后一个比特离开发送端、完全进入链路为止。这个过程的核心是将数据块"推入"网络链路。例如,当一台计算机发送文件时,传输时延就是从第一个比特离开网卡开始,到文件最后一个比特彻底进入光纤或电缆的这段时间。它主要取决于两个因素:数据块的大小(长度)和链路的发送速率(带宽)。计算公式为:传输时延 = 数据帧长度 / 发送速率。因此,数据量越大或带宽越低,传输时延就越长。
传播时延
一旦一个比特被推向链路,该比特需要向路由器B传播。 从该链路的起点到路由器 B传播所需要的时间是传播时延。 该比特以该链路的传播速率传播。该传播速率取决于该链路的物理媒体(即光纤、双绞铜线等), 而与数据量大小无关。该传播时延等于两台路由器之间的距离除以传播速率 即传播时延是d/s 其中 d 是路由器A 和路由器B之间的距离, s 是该链路的传播速率。
传输时延和传播时延的比较
一个类比可以阐明传输时延和传播时延的概念。 考虑一条公路每 100km 有一个收费站,如下图所示。 可认为收费站间的每段公路是链路,收费站是路由器。 假定汽车以100km/h 的速度(也就是说当一辆汽车离开一个收费站时,它立即加速到100km/h 并在收费站间的公路维持该速度)在该公路上行驶(即传播)。 假定这时有10辆汽车作为一个车队在行驶,并且这10 辆汽车以固定的顺序互相跟随。 可以认为每辆汽车是一个比特,该车队是一个分组。 同时假定每个收费站以每辆车12s 的速度服务(即传输) 一辆汽车,并且由于时间是深夜,因此该车队是公路上唯一一批汽车。最后,假定无论该车队的第一辆汽车何时到达收费站,它在入口处等待,直到其他9辆汽车到达并整队依次前行(因为,整个车队在它能够"转发"之前,必须存储在收费站。路由器要转发整个分组之前必须完整接收到整个分组 ) 收费站将整个车队推向公路所需要的时间是 (10 辆车)/(5 辆车/min) = 2min。 该时间类比于一台路由器中的传输时延。一辆汽车从一个收费站出口行驶到下一个收费站所需要的时间是 100km/(100km/h) = 1 h。 这个时间类比于传播时延。 因此,从该车队存储在收费站前 到 该车队存储在下一个收费站前的时间是"传输时延"与"传播时间"总和,在本例中为62min,。

排队时延和丢包
如果10个分组同时到达空队列,传输的第一个分组没有排队时延,而传输的最后一个分组将经受相对大的排队时延(这时它要等待其他9个分组被传输)。什么时候排队时延大,什么时候又不大呢?该问题的答案很大程度取决于流量到达该队列的速率、链路的传输速率和到达流量的性质,即流量是周期性到达还是以突发形式到达。
为了更深入地领会某些要点,令a表示分组到达队列的平均速率 (a 的单位是分组/秒,即 pkt/s) 。 前面讲过 R 是传输速率,即从队列中推出比特的速率(以 bps 即 b/s为单位)。为了简单起见,也假定所有分组都是由 L 比特组成的。 则比特到达队列的平均速率是La bps。 最后,假定该队列非常大,因此它基本能容纳无限数量的比特。 比率La/R被称为流量强度 (traffic intensity) , 它在估计排队时延的范围方面经常起着重要的作用。 如果La/R> 1, 则比特到达队列的平均速率超过从该队列传输出去的速率。 在这种情况下,该队列趋向于无限增加,并且排队时延将趋向无穷大!因此,流量工程中的一条金科玉律是:设计系统时流量强度不能大于1
现在考虑La/R ≤ 1 时的情况。 这时,到达流量的性质影响排队时延。 例如,如果分组周期性到达,即每L/R秒到达一个分组,则每个分组将到达一个空队列中,不会有排队时延。 另一方面,如果分组以突发形式到达而不是周期性到达,则可能会有很大的平均排队时延。 例如,假定每 (L/R)N秒同时到达N个分组。 则传输的第一个分组没有排队时延;传输的第二个分组就有L/R秒的排队时延;更为一般地,第n个传输的分组具有 (n-1)L/R秒的排队时延
通常,到达队列的过程是随机的,即到达并不遵循任何模式,分组之间的时间间隔是随机的。 如果流量强度接近于0, 则几乎没有分组到达并且到达间隔很大,因此,平均排队时延将接近0。随着流量强度接近1 , 平均排队长度变得越来越长。
丢包
在现实中,队列只有有限的容量,排队容量极大地依赖于路由器设计和成本。 因为该排队容量是有限的,随着流量强度接近1 , 排队时延并不真正趋向无穷大。相反,到达的分组将发现一个满的队列。 由于没有地方存储刚到达的分组,路由器将丢弃该分组, 即该分组将会丢失
从端系统的角度看,上述丢包现象看起来是一个分组已经传输到网络核心,但它不会从网络发送到目的地。 分组丢失的比例随着流量强度增加而增加。 因此, 一个节点的性能常常不仅根据时延来度量,还根据丢包的概率来度量。 丢失的分组可能基于端到端的原则重传,以确保所有的数据最终从源传送到了目的地。
端到端时延
前面的讨论一直集中在节点时延上,即在单台路由器上的时延1。我们现在考虑从源到目的地的总时延。 为了能够理解这个概念,假定在源主机和目的主机之间有N -1 台路由器。 我们还要假设该网络此时是无拥塞的(因此排队时延是微不足道的),在每台路由器和源主机上的处理时延是 d p r o c d_{proc} dproc, 每台路由器和源主机的输出速率是 R bps,每条链路的传播时延是 d p r o p d_{prop} dprop
传输时延是 d t r a n s = L / R d_{trans} = L / R dtrans=L/R L是每个分组的长度。
将所有的节点时延加起来得到端到端时延 N ( d p r o c + d p r o p + d t r a n s ) N(d_{proc} + d_{prop} + d_{trans}) N(dproc+dprop+dtrans)
Traceroute
为了对计算机网络中的端到端时延有更清晰的认识,我们可以利用 Traceroute 程序。Traceroute 程序,它能够在任何因特网主机上运行。 当用户指定一个目的主机名字时,源主机中的该程序朝着目的地发送多个特殊的分组。 当这些分组向着目的地传送时,它们通过一系列路由器。 当路由器接收到这些特殊分组之一时,它向源回送一个短报文。 该短报文包括路由器的名字和地址。
更具体的是,假定在源和目的地之间有N-1 台路由器。 源将向网络发送N个特殊的分组,其中每个分组地址指向最终目的地。 这N个特殊分组标识为从1 到N, 第一个分组标识为 1 最后的分组标识为 N。 当第 n 台路由器接收到标识为 n 的第n个分组时,该路由器不是向它的目的地转发该分组,而是向源回送一个报文。 当目的主机接收第N个分组时,它也会向源返回一个报文。 该源记录了从它发送一个分组到它接收到对应返回报文所经历的时间;它也记录了返回该报文的路由器(或目的主机)的名字和地址。 以这种方式,源能够重建分组从源到目的地所采用的路由,并且该源能够确定到所有中间路由器的往返时延。 Traceroute 实际上对刚才描述的实验重复了 3 次,因此该源实际上向目的地发送了3xN个分组。

这里有一个Traceroute 程序输出的例子,输出有 6 列: 第一列是前面描述的n值,即路径上的路由器编号;第二列是路由器的名字;第三列是路由器地址(格式为欢X. XXX. XXX. XXX) ; 最后 3 列是 3 次实验的往返时延。
在上述跟踪中,在源和目的之间有9台路由器。 这些路由器中的多数有一个名字,所有都有地址。 例如,路由器3 的名字是 border4-rt-gi-1-3. gw. umass. edu, 它的地址是128. 119. 2. 194 。 看看为这台路由器提供的数据,可以看到在源和路由器之间的往返时延:3 次实验中的第一次是1.03ms, 后继两次实验的往返时延是0.48ms 和0.45ms。 这些往返时延包括刚才讨论的所有时延,即包括传输时延、传播时延、 路由器处理时延和排队时延。 因为该排队时延随时间变化,所以分组 n 发送到路由器 n 的往返时延实际上可能比分组 n+1 发送到路由器 n+1 的往返时延更长。 的确,我们在上述例子中观察到了这种现象:到路由器6 的时延比到路由器7 的更大
计算机网络中的吞吐量
计算机网络中另一个至关重要的性能测度是端到端吞吐量。 为了定义吞吐量,考虑从主机A到主机B跨越计算机网络传送一个大文件。例如,从一个P2P 文件共享系统中的一个对等方向另一个对等方传送一个大视频片段,在任何时间瞬间的瞬时吞吐量 (instantaneous throughput) 是主机 B 接收到该文件的速率(以 bps 计)。就像下载文件时观察到的瞬时下载速度。如果该文件由 F 比特组成, 主机B接收到所有 F 比特用去 T秒,则文件传送的平均吞吐量 (average throughput) 是 F/T bps。
协议层次及其服务模型
因特网有许多部分:大量的应用程序和协议、各种类型的端系统、分组交换机以及各种类型的链路级媒体。 面对这种巨大的复杂性,存在着组织网络体系结构的希望吗?或者至少存在着我们对网络体系结构进行讨论的希望吗?幸运的是,对这两个问题的回答都是肯定的。
分层的体系结构
先看一个人类社会与之类比的例子,想象如何用一个结构描述航线系统。该系统具有票务代理、行李检查、登机口人员、飞行员、飞机、空中航行控制和世界范围的导航系统。 描述这种系统的一种方式是,描述当你乘某个航班时, 你(或其他人替你)要采取的一系列动作。你要购买机票,托运行李,去登机口,并最终登上这次航班。 该飞机起飞,飞行到目的地。 当飞机着陆后,你从登机口离机并认领行李。 如果这次行程不理想,你向票务机构投诉这次航班。
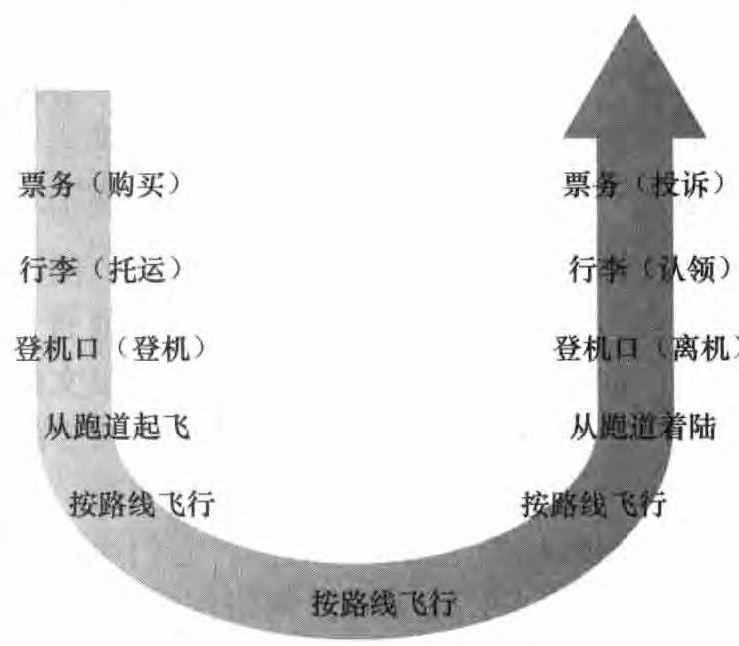
如上图所示,显示了相关情况。我们已经能从这里看出与计算机网络的某些类似: 航空公司把你从源送到目的地;而分组被从因特网中的源主机送到目的主机。 但这不是我们寻求的完全的类似。观察上图 , 我们注意到在每一端都有票务功能;对已经检票的乘客有托运行李功能,对已经从登机口离机的乘客有行李认领功能;对已经检票并登机口 (登机)已经检查过行李的乘客有登机功能,飞机着陆后从登机口对乘客提供离机功能;对于通过登机口的乘客(已经经过检票、行李检查和通过登机口的乘客),有从跑道起飞和从跑到着陆的功能; 并且在飞行中,有飞机按预定路线飞行的功能。
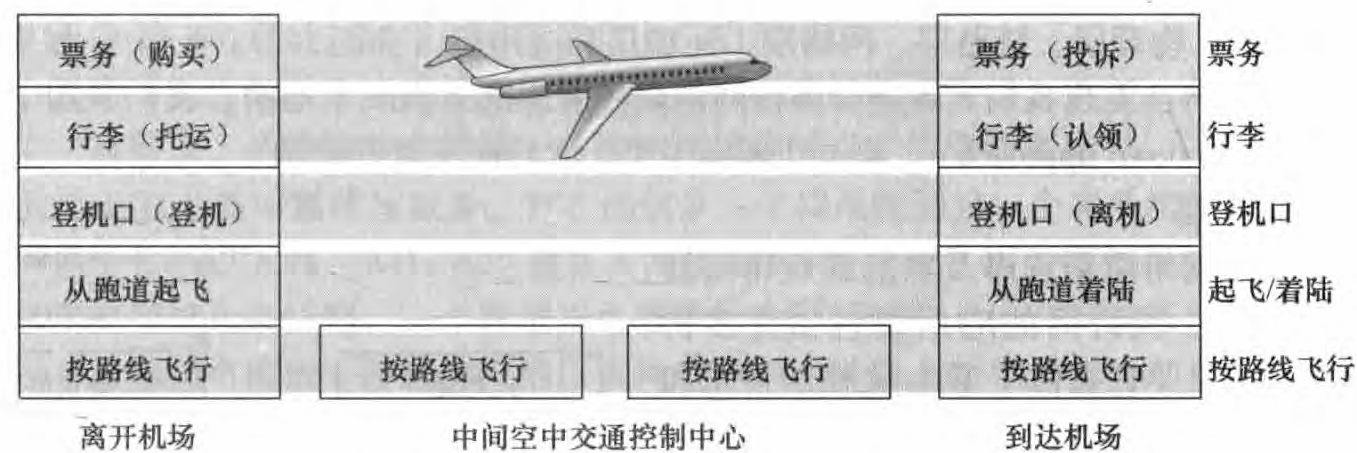
将航线功能划分为一些层次,提供了我们能够讨论航线旅行的框架。 注意到每个层次与其下面的层次结合在一起,实现了某些功能、 服务。 在票务层及以下, 完成了一个人从航线柜台(票务购买)到航线柜台(投诉柜台)。 在行李层及以下,完成了行李托运到行李认领。 注意到行李层仅对已经完成票务的人提供服务。 在登机口层, 完成了人和行李登机到离机。 在起飞/着陆层, 完成了一个人和行李从跑道(起飞)到跑道(着陆)。 每个层次通过以下方式提供服务: 1.在这层中执行了某些动作 (例如,在登机口层,某飞机的乘客登机和离机); 2.使用直接下层的服务(例如,在登机口层,使用起飞/着陆层的跑道实现旅客转移服务)。
利用分层的体系结构,我们可以讨论一个复杂系统的定义。 这种简化本身由于提供模块化而具有很高价值,这使某层所提供的服务实现易于改变。 只要该层对其上面的层提供相同的服务,并且使用来自下面层次的相同服务,当某层的实现变化时,该系统的其余部分保持不变。 例如,如果登机口功能被改变了(例如让人们按身高登机和离机),航线系统的其余部分将保持不变,因为登机口仍然提供相同的功能(人们登机和离机)。
协议分层(5层因特网协议栈)
现将注意力转向网络协议。为了给网络协议的设计提供一个结构,网络设计者以分层的方式组织协议以及实现这些协议的网络硬件和软件,每个协议属于这些层次之一。就像上图所示的航线体系结构中的每种功能属于某一层一样, 我们还关注某层向它的上一层所提供的服务。 就像前面航线例子中的清况一样,每层通过在该层中执行某些动作或使用直接下层的服务来提供服务。
一个协议层能够用软件、硬件或两者的结合来实现。 诸如 HTTP和SMTP这样的应用层协议几乎总是在端系统中用软件实现,运输层协议也是如此。 因为物理层和数据链路层负责处理跨越特定链路的通信,它们通常在与给定链路相关联的网络接口卡(例如以太网或WiFi 接口卡)中实现。 网络层经常是硬件和软件实现的混合体。 还要注意的是,如同分层的航线体系结构中的功能分布在构成该系统的各机场和飞行控制中心中一样, 一个协议也分布在构成该网络的端系统、分组交换机和其他组件中。
将这些综合起来,各层的所有协议被称为协议栈 (protocol stack)。 因特网的协议栈由5 个层次组成:物理层、链路层、网络层、运输层和应用层

-
应用层
应用层是网络应用程序及它们的应用层协议存留的地方。 因特网的应用层包括许多协议,例如HTTP (它提供了 Web 文档的请求和传送)、 SMTP (它提供了电子邮件报文的传输)和FTP (它提供两个端系统之间的文件传送)。应用层协议分布在多个端系统上,而一个端系统中的应用程序使用协议与另一个端系统中的应用程序交换信息分组。 我们把这种位于应用层的信息分组称为报文 (rnessage)。
-
运输层
因特网的运输层在应用程序端点之间传送应用层报文。 在因特网中,有两种运输协议,即TCP和 UDP, 利用其中的任一个都能运输应用层报文。 TCP 向它的应用程序提供了面向连接的服务。 这种服务包括了应用层报文向目的地的确保传递和流量控制(即发送方/接收方速率匹配)。 TCP也将长报文划分为短报文,并提供拥塞控制机制,因此当网络拥塞时,源抑制其传输速率。 UDP协议向它的应用程序提供无连接服务。 这是一种不提供不必要服务的服务,没有可靠性,没有流量控制,也没有拥塞控制。我们把运输层的分组称为报文段 (segment) 。
-
网络层
因特网的网络层负责将称为数据报 (datagram) 的网络层分组从一台主机移动到另一台主机。 在一台源主机中的因特网运输层协议 (TCP或UDP) 向网络层递交运输层报文段和目的地址,就像你通过邮政服务寄信件时提供一个目的地址一样。因特网的网络层包括著名的网际协议IP, 该协议定义了在数据报中的各个字段以及端系统和路由器如何作用于这些字段。 IP仅有一个,所有具有网络层的因特网组件必须运行IP。 因特网的网络层也包括决定路由的路由选择协议,它根据该路由将数据报从源传输到目的地。
-
链路层
因特网的网络层通过源和目的地之间的一系列路由器路由数据报。 为了将分组从一个节点 (主机或路由器) 移动到路径上的下一个节点,网络层必须依靠该链路层的服务。 特别是在每个节点,网络层将数据报下传给链路层,链路层沿着路径将数据报传递给下一个节点。 在该下一个节点,链路层将数据报上传给网络层。链路层的例子包括以太网、 WiFi 等协议。 数据报从源到目的地传送通常需要经过几条链路, 一个数据报可能被沿途不同链路上的不同链路层协议处理。 我们把链路层分组称为帧 (frame)。
-
物理层
物理层的任务是将该帧中的一个个比特从一个节点移动到下一个节点。 在这层中的协议仍然是链路相关的,并且进一步与该链路 (例如,双绞铜线、 单模光纤)的实际传输媒体相关。
OSI 摸型
除上述因特网协议栈, 国际标准化组织 (ISO) 提出计算机网络围绕7层来组织,称为开放系统互连 (OSI) 模型。

OSI参考模型的7 层是:应用层、表示层、会话层、运输层、网络层、数据链路层和物理层。 这些层次中, 5层的功能大致与它们名字类似的因特网对应层的功能相同。 所以,我们来考虑OSI参考模型中附加的两个层,即表示层和会话层。 表示层的作用是使通信的应用程序能够解释交换数据的含义。 这些服务包括数据压缩和数据加密(它们是自解释的)以及数据描述(这使得应用程序不必担心在各台计算机中表示/存储的内部格式不同的问题)。 会话层提供了数据交换的定界和同步功能,包括了建立检查点和恢复方案的方法。
封装
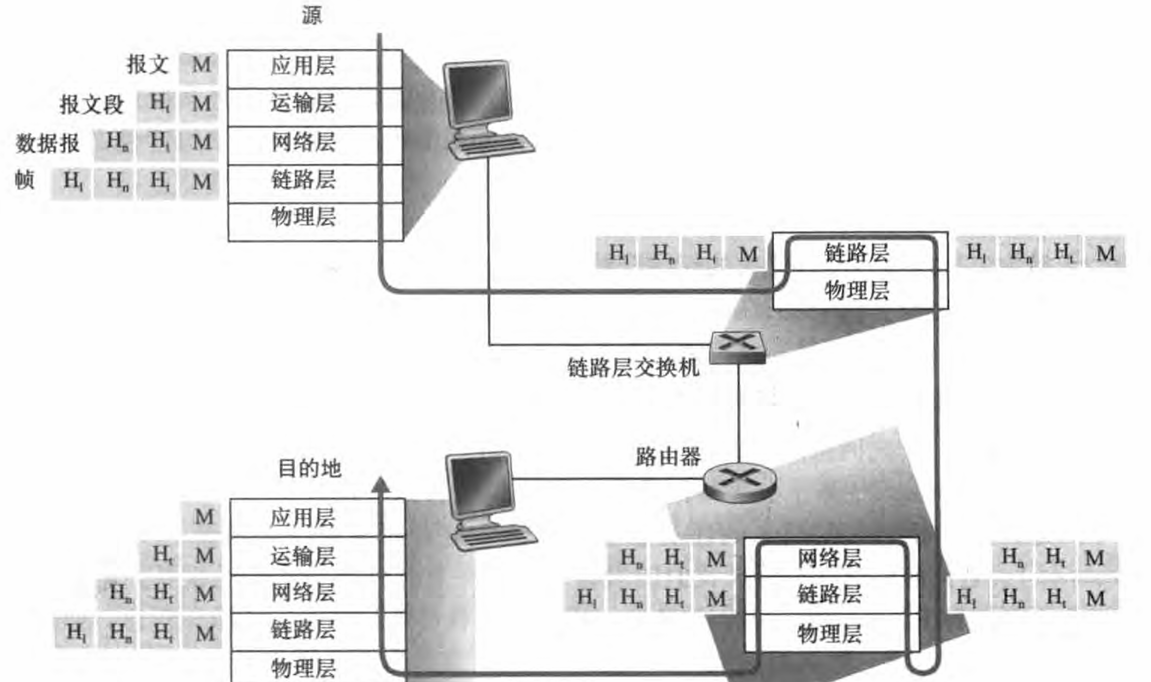
如上图所示,数据从发送端(源)系统的协议栈向下,沿着中间的链路层交换机和路由器的协议栈上上下下,然后向上到达接收端(目的地)系统的协议栈。 路由器和链路层交换机与端系统类似,以多层次的方式组织它们的网络硬件和软件,但并不实现协议栈中的所有层次。 链路层交换机实现了第一层和第二层;路由器实现了第一层到第三层。
该图也说明了一个重要概念:封装 。 在发送主机端, 一个应用层报文(图中的 M) 被传送给运输层。 在最简单的情况下,运输层收取到报文并附上附加信息(所谓运输层首部信息,Ht) 该首部将被接收端的运输层使用。 应用层报文和运输层首部信息一道构成了运输层报文段 。 运输层报文段因此封装了应用层报文。 附加的信息也许包括了下列信息:允许接收端运输层向上向适当的应用程序交付报文的信息; 差错检测位信息,该信息让接收方能够判断报文中的比特是否在途中已被改变。 运输层则向网络层传递该报文段,网络层增加了如源和目的端系统地址等网络层首部信息(图中的 Hn) 生成了网络层数据报 。 该数据报接下来被传递给链路层,链路层增加链路层首部信息并生成链路层帧 。 所以在每一层,一个分组具有两种类型的字段: 首部字段和有效载荷字段。 有效载荷通常是来自上一层的分组。
面对攻击的网络(不做介绍)
计算机网络和因特网的历史(不做介绍)
参考目录
书籍:《计算机网络:自顶向下方法(第七版)》
https://blog.csdn.net/weixin_48024605/article/details/132426862