过去几年,大语言模型(LLM)在文本生成、代码编写和知识问答等任务上取得了突破性进展。然而,随着应用场景从"回答问题"逐步走向"完成任务",人们开始意识到一个关键事实:仅具备推理能力的语言模型,并不足以应对真实世界中的复杂问题。如何让模型在思考的同时采取行动,并根据行动结果不断调整策略,成为推动智能系统演进的核心问题。正是在这一背景下,ReACT Agent 应运而生。
一、什么是 AI Agent:从"会回答"到"会做事"
传统的大语言模型(LLM)本质上是一个条件概率生成器:
给定输入 Token 序列,预测下一个 Token。
但 Agent 的核心目标不是"回答问题",而是"完成任务"。
AI Agent = LLM + 规划能力 + 记忆机制 + 工具执行能力 + 循环控制逻辑
在 Agent 体系中,LLM 不再是终点,而是中枢大脑(Brain)。
1. Agent 的核心组件拆解(抽象层)
可以用一句工程化定义来总结:
Agent 是一个由 LLM 驱动、能够感知环境、进行推理、调用工具并持续迭代直至达成目标的系统。
核心能力一览
| 组件 | 职责 | 对应能力 |
|---|---|---|
| LLM | 推理与决策 | 语言理解、逻辑推演 |
| Planning | 任务拆解 | 子目标、顺序规划 |
| Memory | 状态保存 | 短期上下文、长期知识 |
| Tool Use | 执行动作 | 搜索、代码、API |
| Controller | 循环调度 | 终止条件、异常处理 |
2. Agent 工作原理总览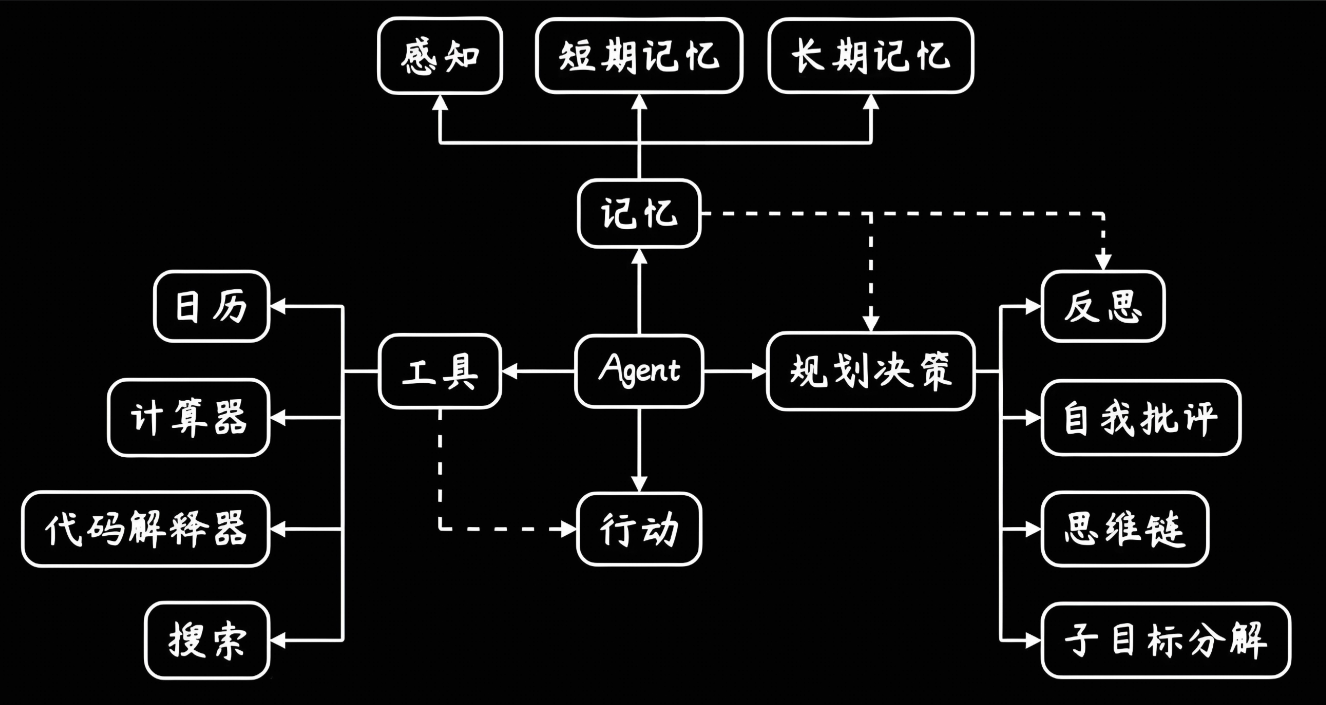
二、Agent 的三大能力模块(深度拆解)
1. 规划(Planning)
1.1 子目标分解(Task Decomposition)
本质问题:LLM 一次性解决复杂问题,容易"思维跳跃"或遗漏关键步骤。
Agent 通过 显式规划 将问题拆分为可执行单元:
示例:
目标:制定季度销售推广方案
拆解为:
- 分析市场趋势
- 识别目标用户
- 调研竞品策略
- 选择推广渠道
- 制定执行计划
这一步通常通过 Prompt 或 Planner Agent 完成
1.2 反思与改进(Reflection)
这是 Agent 区别于普通 LLM 的关键进化点。
常见反思方式:
- 执行失败后总结原因
- 对中间结果进行自我评价
- 调整后续行动策略
工程实现常见形式:
powershell
Previous action failed because ...
I should try a different approach:2. 记忆(Memory)
2.1 短期记忆(Short-term Memory)
- 本质:上下文窗口
- 形式:对话历史、当前步骤
- 限制:Token 上限
Prompt Engineering 就是在"压榨短期记忆"。
2.2 长期记忆(Long-term Memory)
- 存储方式:向量数据库(FAISS / Milvus / Chroma)
- 存储内容:
- 历史任务经验
- 用户偏好
- 外部文档
典型流程:
powershell
文本 → Embedding → Vector DB → 相似度检索 → 注入 Prompt3. 工具使用(Tool Use)
3.1 为什么必须使用工具?
LLM 的权重是"静态的",现实世界是"动态的"。
工具弥补三大缺陷:
- ❌ 无实时信息
- ❌ 无执行能力
- ❌ 无私有数据访问
3.2 常见工具类型
| 工具类型 | 示例 |
|---|---|
| 搜索 | Google / Bing / 内部搜索 |
| 计算 | Python REPL |
| 数据 | SQL / Elasticsearch |
| 系统 | Shell / OS |
| 业务 | 内部 API |
四、ReACT 的提出背景:Reasoning 与 Acting 的"断层问题"
4.1 早期方法的两种极端
| 方法 | 特点 | 问题 |
|---|---|---|
| Chain-of-Thought | 推理清晰 | 无法执行动作 |
| Tool-Augmented LLM | 能调用工具 | 缺乏长期规划 |
核心断层:推理(Reasoning)和行动(Acting)是割裂的。
4.2 ReACT 的核心洞察
ReACT 论文的关键假设是:
人类解决问题时,是在"想--做--看--再想"的闭环中完成的,而不是先想完再一次性执行。
因此,研究团队提出:
让语言模型同时生成推理轨迹(Thought)与行动指令(Action)
五、ReACT Agent 的核心机制:Thought--Action--Observation 循环
5.1 ReACT 的最小抽象
ReACT Agent 可以被抽象为一个 显式状态机:
bash
State = {Thought, Action, Observation}每一轮循环,LLM 都会:
- 生成 Thought(推理)
- 选择 Action(动作)
- 接收 Observation(反馈)
- 进入下一轮推理
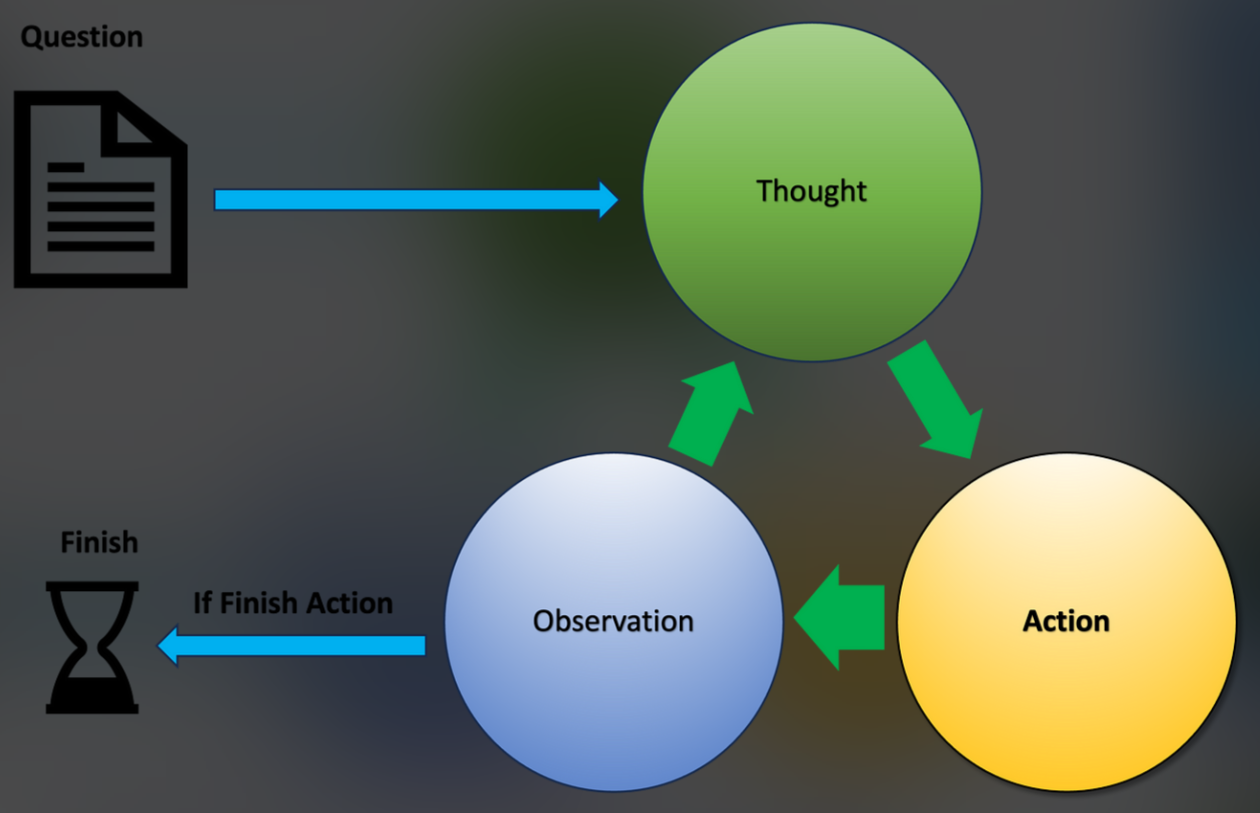
5.2 三个核心状态的语义定义(非常关键)
Thought(思考)
- 内部推理链
- 不直接影响环境
- 决定下一步 Action
示例:
bash
Thought: 我需要确认当前季度电子产品的市场趋势Action(行动)
- 唯一能改变环境的步骤
- 必须是结构化、可执行的
示例:
bash
Action: Search("2025 Q1 电子产品 市场趋势")Observation(观察)
- 工具或环境返回的真实结果
- 是下一轮推理的"事实依据"
示例:
bash
Observation: 多份行业报告指出 AI PC 与可穿戴设备增长迅速六、ReACT Prompt 设计:让模型"学会"循环
6.1 标准 ReACT Prompt 模板(论文级)
bash
You are a ReAct agent.
You must use the following format:
Thought: describe your reasoning
Action: the action to take, one of [Search, Lookup, Finish]
Observation: the result of the action
Repeat until you can answer.
Question: {question}格式约束是 ReACT 成功的关键,而不是模型大小。
6.2 为什么 ReACT 必须"强约束输出格式"?
原因有三:
- 方便 程序解析
- 强制模型 外化推理
- 防止 Action 随机生成
七、ReACT Agent 的工程实现
7.1 ReACT Agent 的核心控制循环
本质:一个由 LLM 驱动的 while 循环
python
class ReActAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = tools
self.history = []
def run(self, question, max_steps=10):
prompt = self.build_prompt(question)
for step in range(max_steps):
response = self.llm(prompt)
thought, action = self.parse(response)
if action.name == "Finish":
return action.args
observation = self.tools[action.name](action.args)
prompt += f"\nObservation: {observation}\n"这段代码就是 ReACT 的"灵魂"
7.2 Action Dispatch(工具路由)
python
TOOLS = {
"Search": search_tool,
"Lookup": lookup_tool
}ReACT 不关心工具怎么实现,只关心能不能用。
八、ReACT 与传统 Agent 框架的本质区别
8.1 与 Planner-Executor 的对比
| 维度 | Planner-Executor | ReACT |
|---|---|---|
| 执行方式 | 先规划后执行 | 边想边做 |
| 动态调整 | 弱 | 强 |
| 中间可解释性 | 低 | 极高 |
| 容错性 | 低 | 高 |
8.2 与 AutoGPT 的对比
| 项目 | AutoGPT | ReACT |
|---|---|---|
| 自主性 | 高 | 可控 |
| 推理可见 | 低 | 高 |
| 工程稳定性 | 低 | 高 |
九、ReACT 的典型应用场景
9.1 检索增强问答(RAG + ReACT)
python
Thought → 是否需要外部信息?
Action → 向量检索 / 搜索
Observation → 文档片段
Thought → 综合答案9.2 自动化运维 / 测试
python
Thought: BMC 温度异常,需确认传感器数据
Action: CallAPI("/redfish/v1/Chassis/...")
Observation: CPU 温度 92℃
Thought: 超过阈值,需要进一步定位9.3 数据分析 Agent
- Thought:选择统计方法
- Action:执行 Python
- Observation:数值结果
十、ReACT 的挑战与工程化改进
10.1 Token 成本问题
- Thought 会显著增加 Token
- 工程方案:
- 隐藏 Thought(生产)
- 压缩历史
- 分层 Agent
10.2 循环失控问题
解决方案:
- 最大步数
- 重复检测
- Reward / Critic Agent
ReACT 并不是"让模型多想几步",而是让模型"像人一样边想边行动"。 它标志着大模型从"语言系统"向"行为系统"的关键跃迁。