研究方向:Image Captioning
1. 论文介绍
传统方法通常需要大量的图像-文本对数据进行训练,这在数据获取方面提出了挑战;
零样本方法不使用图像-文本对进行训练,而是通过检索共享实体、概念或类似句子作为锚点来匹配。通过在利用文本表示来模拟图像表示的文本重构任务上训练文本生成模型,这些方法旨在实现不依赖配对数据的图像-文本生成;
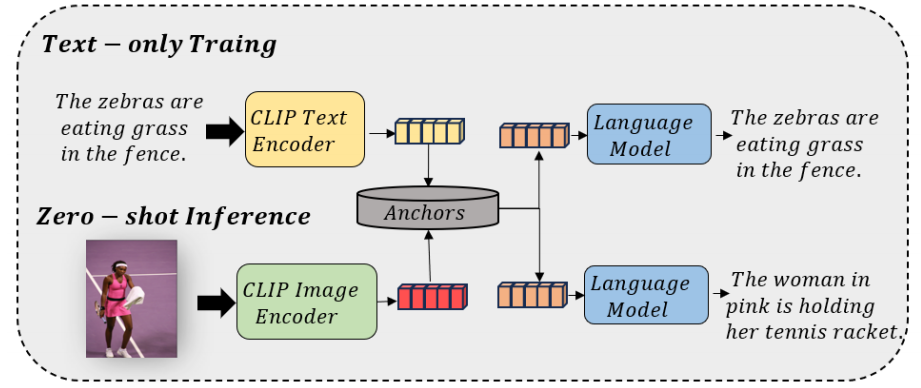
解释:
第一阶段:纯文本训练
模型只看文字,不看图片 。教会语言模型向量 + 关键词 = 完整句子。
把文本输入CLIP 的文本编码器变成向量。为了模拟真实图片的"模糊感"和"不确定性",这里通常还会人为加上一些噪声。
从文本中提取出关键词,这些具体的词就是Anchors 。
GPT-2 接收CLIP 文本编码器的"模糊向量"和提取的"Anchors",尝试把原始文本给还原出来 。
第二阶段:零样本推理
给一张图片放入CLIP图像编码器得到图像的向量。CLIP把图像和文本向量映射到同一个嵌入空间里。
系统用这个图片的向量,去实体库里搜索最匹配的Anchors。
GPT-2 接收"真图片向量" + "搜到的 Anchors"生成描述。
而最近的零样本图像字幕生成方法主要侧重于将检测到的概念(如实体)整合到输入中,较少关注在零样本设置下通过对比学习等技术训练图像与实体之间的匹配关系,导致模型生成的文本包含更多无关内容,准确率较低。
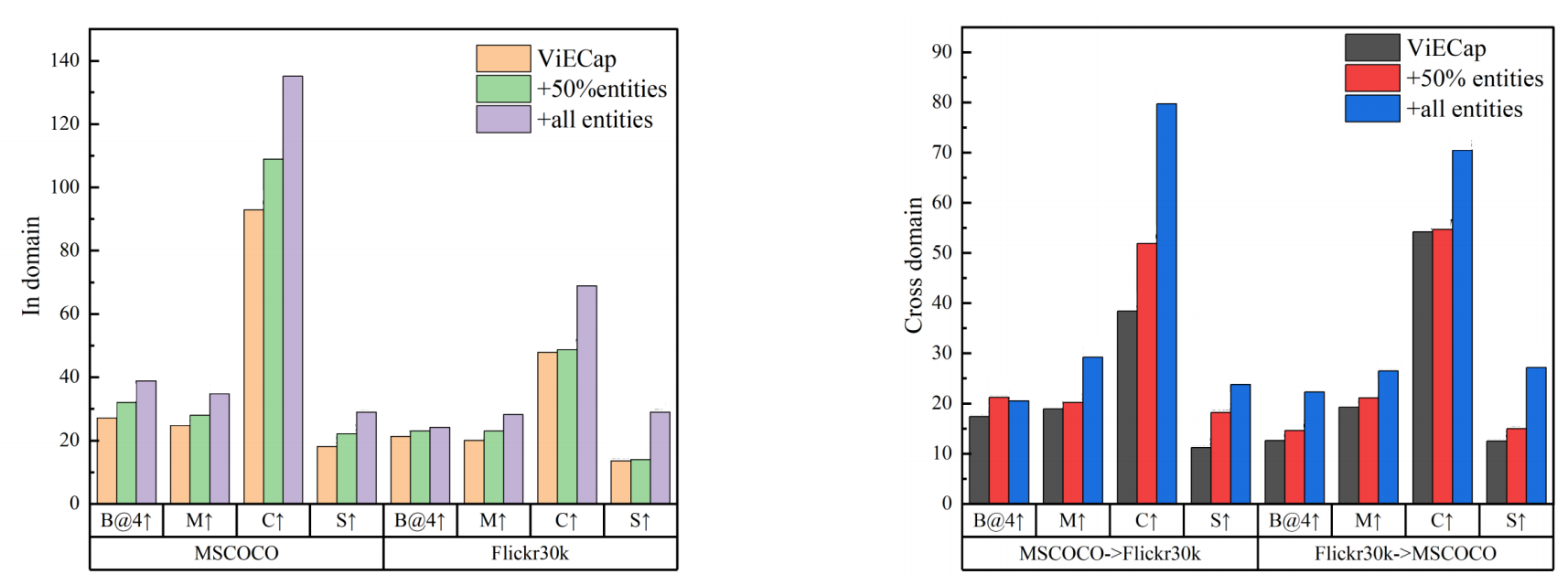
ViECap :原始模型,依靠自身能力检索实体。;+50% entities :人为提供 50% 的正确实体 ;+all entities:人为提供所有正确实体(理想情况/上限)。
上图显示加入实体显著提高了生成字幕的质量(域内+域外)
本文提出了MERCap,一种采用多种类型实体表示检索的零样本图像字幕生成方法。
首先使用文本的CLIP表示和高斯噪声来近似图像表示,以解决模态间的差距。
然后,训练一个GPT-2,使其能够利用实体作为硬提示以及CLIP表示作为软提示来重构文本。
此外,还构建了一个特定领域的实体集,为每个实体分配多个表示,并通过对比学习优化它们的表示向量。在推理过程中,我们重新检索实体并将它们输入到解码器中,以生成相应的字幕。
2. 方法介绍
2.1 目标定义
本文的目标是为每张图像生成符合图像描述的文本描述。给定实体集,对于每张图像,首先使用检索算法 R 检索其隐含实体。随后,通过生成模型 G 生成相应的文本。
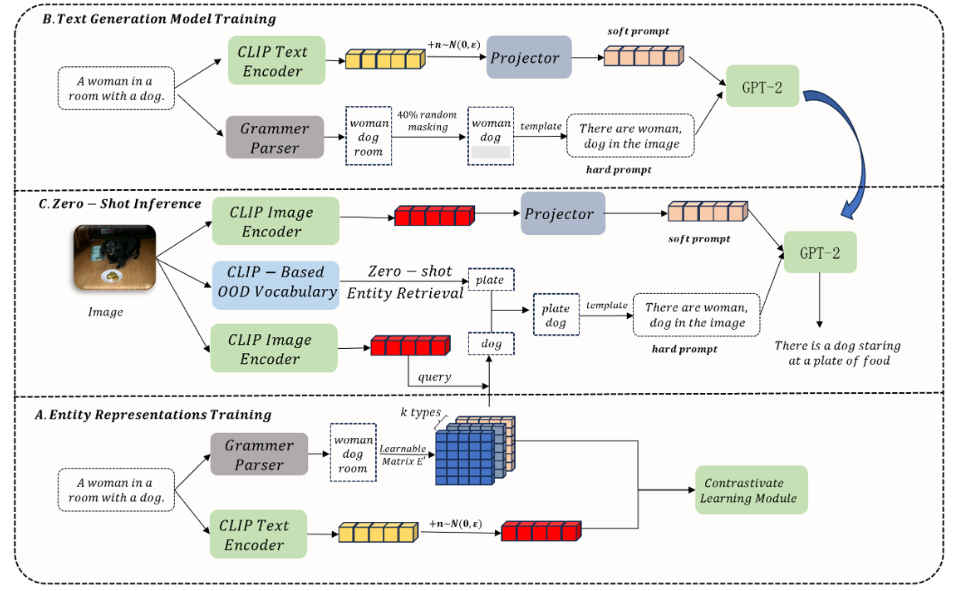
2.2 实体表征训练
使用CLIP实现图像及其对应文本的初步对齐,使得可以使用文本表示来近似图像表示
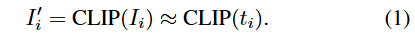
使用球形空间内的噪声之和来代替图像表示,从而用文本表示来近似图像表示,n服从正态分布,0
为均质,ϵ为方差
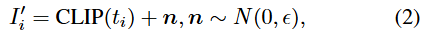
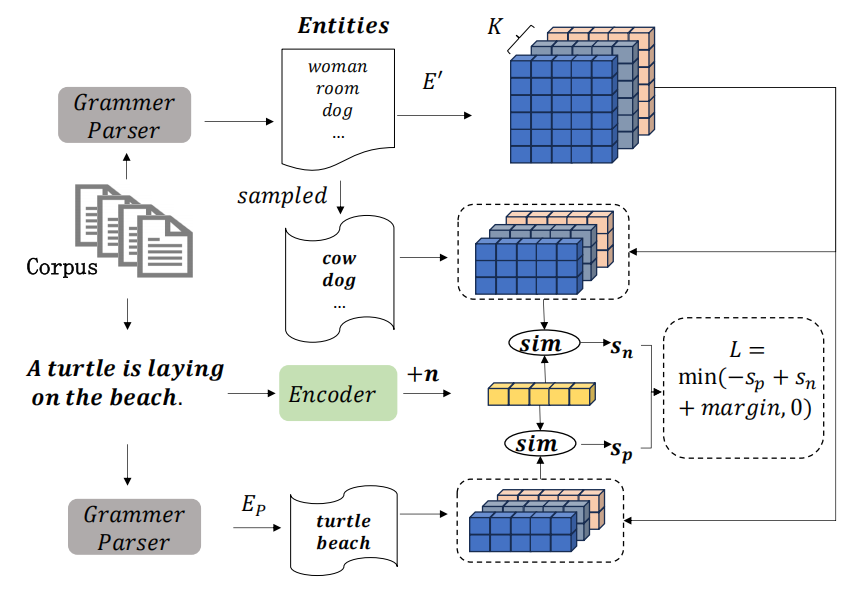
为每个实体分配一个表示,使我们能够基于指定的相似性度量函数捕捉与给定图像相关的实体。
首先,我们从语料库中提取出现超过次的所有名词,以构建实体集。然后,我们初始化一个可学习的矩阵E`
,其中M是实体的数量。每个实体的向量维度是Kd,其中d是与图像类似的维度,K代表每个实体的指定表示类型数量。
用 NLTK工具来提取实体(每段文本的所有名词短语),形成相应的正面实体集 。此外,从总实体集 E′中随机选择 N′个负面实体,构建负面实体集
。
-
目标 :希望
(正样本相似度)尽可能大,
-
理想状态 :
如果做到了这一点(
-
惩罚状态:如果不满足上述条件(例如,错误答案的得分比正确答案还高,或者虽然正确答案赢了但赢得不够多),括号内的值就会大于 0。
这时 Loss
因此,对比学习损失函数可以表示为:
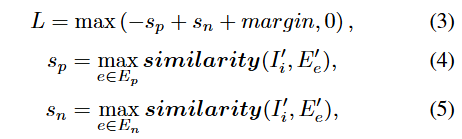
注意:矩阵E`是一个包含了所有实体的大矩阵,对应具体某个实体 e(比如单词 "dog")的那一部分切片,
margin是允许的差距,由于每个实体有K种表示方式,我们使用图像表示与这些多种表示方式之间的最大余弦相似度来衡量相似性,具体如下:
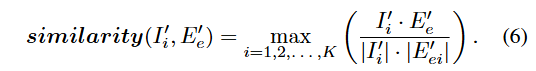
2.3 文本生成模型训练
训练一个语言解码器,使其能够通过感知实体来重构文本,所以我们从与图像对应的真实文本中提取两种类型的信息
1)实体信息
创建一个硬编码,使解码模型能够理解实体信息:
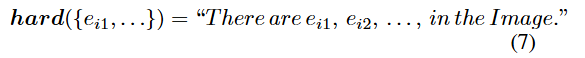
2)嵌入信息
用带噪声的文本表示来模拟图像表示,将几个与输入特征具有最高余弦相似度的训练文本的特征连接起来,形成一个软提示
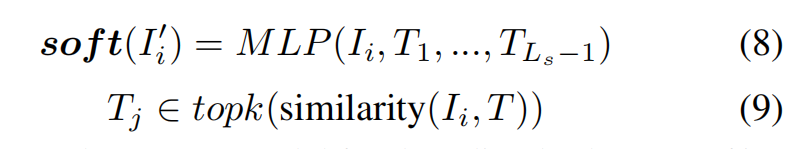
指的是整个纯文本训练语料库的特征集合,语料库来源于各大图像描述数据集的标注文件
微调GPT-2模型以解码两种类型的信息,使用自回归目标函数来训练参数为 θ的模型G
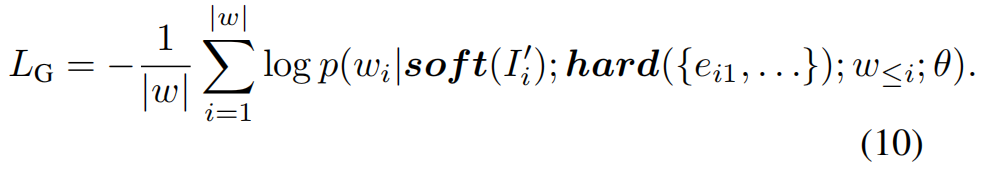
2.4 零样本推理
通过计算图像特征与实体库( E`)中所有实体表示的余弦相似度,选取概率大于阈值 的前
个实体,组成域内实体集
借鉴了 ViECap 的做法,引入了一个外部词表。通过同样的检索方式从这个巨大的外部词表中检索实体,得到域外实体集
最终用于生成的实体集合是两者的并集
最终描述生成:
