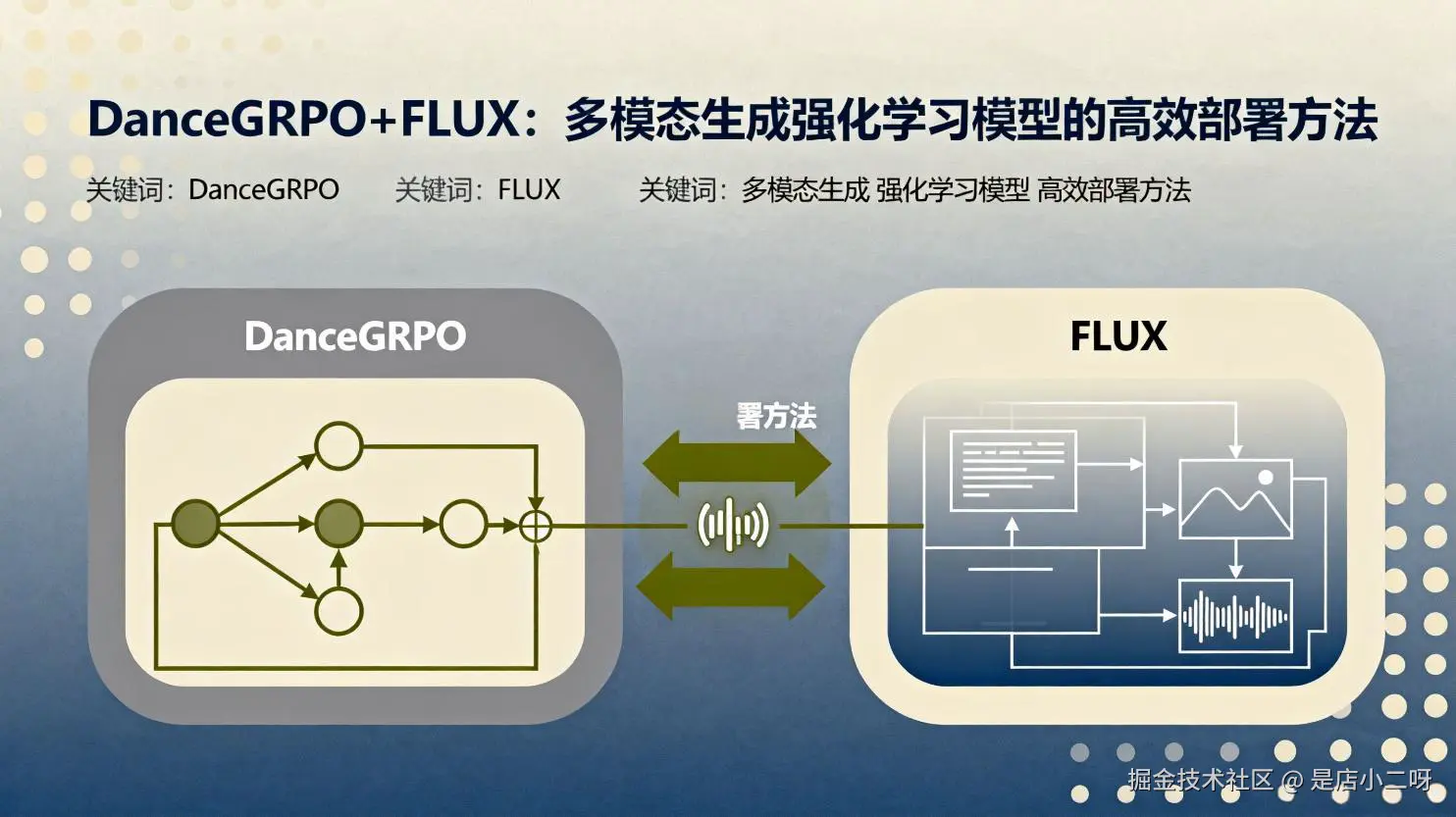
一、背景介绍
Flux 模型 :小模型高效生成高质量图像的基础
Flux 虽是百亿级参数的大模型家族,但其中的轻量化变体(如 Flux.1 (schnell))以及核心技术,为小尺寸模型提供了高效生成的范式。其关键技术优势适配小模型的优化需求,具体体现在两点。一是采用 Rectified Flow(校正流)技术,拉直了传统扩散模型从噪声到图像的生成路径,将生成过程优化为近似直线的最短路径,大幅减少采样步数。像 Flux.1 (schnell) 仅需 4 步左右采样就能生成合理图像,这对小模型而言,意味着在降低计算成本的同时,还能避免多步迭代带来的精度损耗。二是创新的多模态融合架构,通过双文本编码器(CLIP+T5)精准解析文本语义,再结合双流转单流的 Transformer 注意力机制,实现文本与图像特征的深度交互。这种设计让小模型无需复杂结构,就能高效捕捉图文关联,提升生成图像的内容一致性。
DanceGRPO 框架:通过强化学习进一步提升小模型性能
DanceGRPO 是专门针对视觉生成领域 RLHF 方案不成熟的问题设计,能精准解决小模型训练中质量提升的核心痛点,具体优势有三。其一,兼容性强,适配 Flux 的核心范式。该框架创新性地将扩散模型和校正流模型(如 Flux)统一视为随机插值的特殊情况,二者的采样过程均可通过 SDE 实现,这让它能无缝对接 Flux 模型,针对性地开展强化学习优化,无需对 Flux 的基础架构做大幅修改,降低了小模型适配强化学习的成本。其二,显存压力低,适配小模型训练资源限制。此前 ReFL 等强化学习方案需对奖励模型和 VAE 解码特征反向传播,在视频生成等场景中显存压力极大,根本不适合小模型。而 DanceGRPO 通过采样部分时间步加速训练、去除作用不大的 KL 散度正则项等设计,大幅降低了计算和显存开销,同时还能让小模型在更多提示词样本上学习,提升泛化能力。其三,强化学习效果显著,精准优化核心指标。该框架通过多奖励模型叠加(图像美感、图文匹配等五类指标),让小模型能针对性提升薄弱项;同时通过固定初始化噪声、控制梯度更新频率等优化手段,避免训练中的奖励作弊和多样性下降问题。
强化学习框架对比

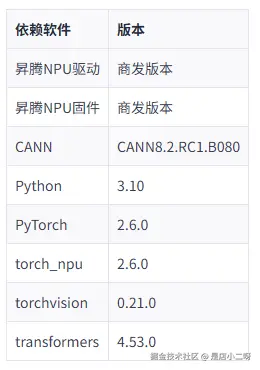
二、环境依赖
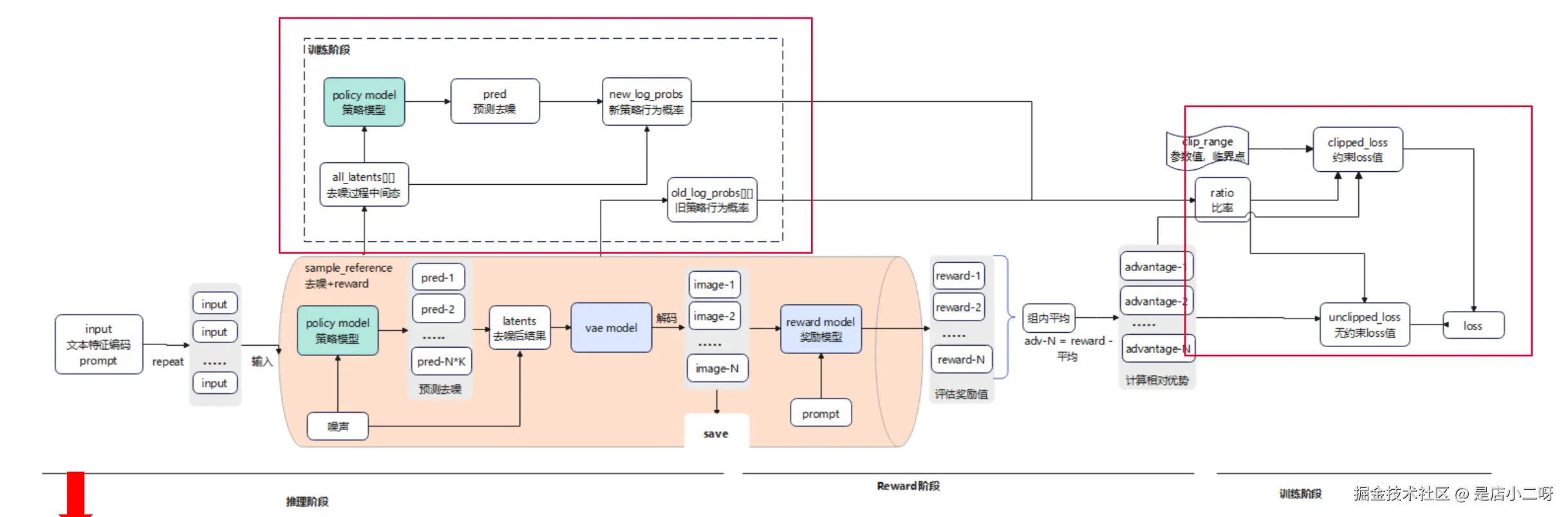
三、DanceGRPO+FLUX 整体流程
推理阶段(去噪生成图片,用于训练过程观察)
- 加载文本信息: 获取初始数据,将数据复制成 N 份作为输入。
- 去噪: 生成初始噪声,input 和当前噪音输入到 policy mode 预测噪声成分,去噪生成 latents。
- 图片生成保存: 基于推理阶段输出 latents,经过 vae mode 解码成 image,保存为文件用于观察过程。
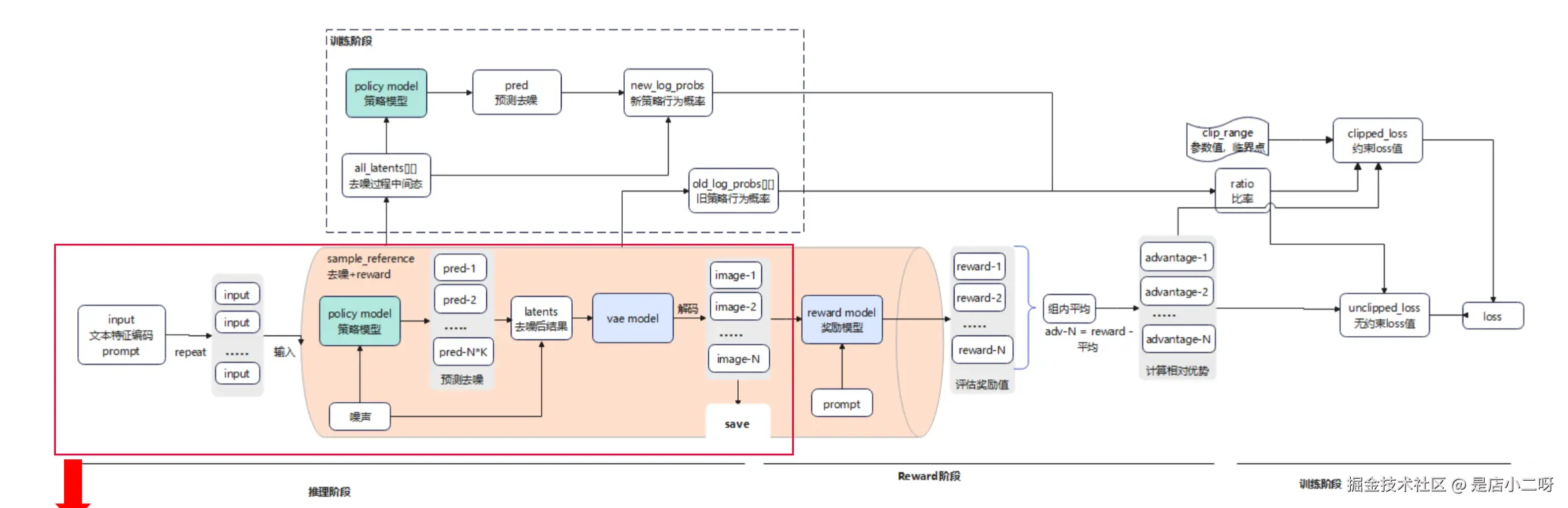
关键点
- 推理去噪生成图像:该模型中,默认一组生成 12 哥样本,即一个 prompt 会生成 12 哥大体相似而细节不同的图像,每个图像默认经过 16 步迭代去噪生成。
- 去噪步长:步长随时间步长从大到小,因为初始噪声成分较多,相当于勾勒轮廓去噪步长可以大些,后面要收敛到正确终点,相当于描绘细节,需要慢慢去噪。
- 图像多样性:去噪过程会加入随机扰动,局部优化,因此会有一组默认 12 张图片,每张整体相似而细节有差异的图片;一组内会进行对比,提升优势动作的概率。

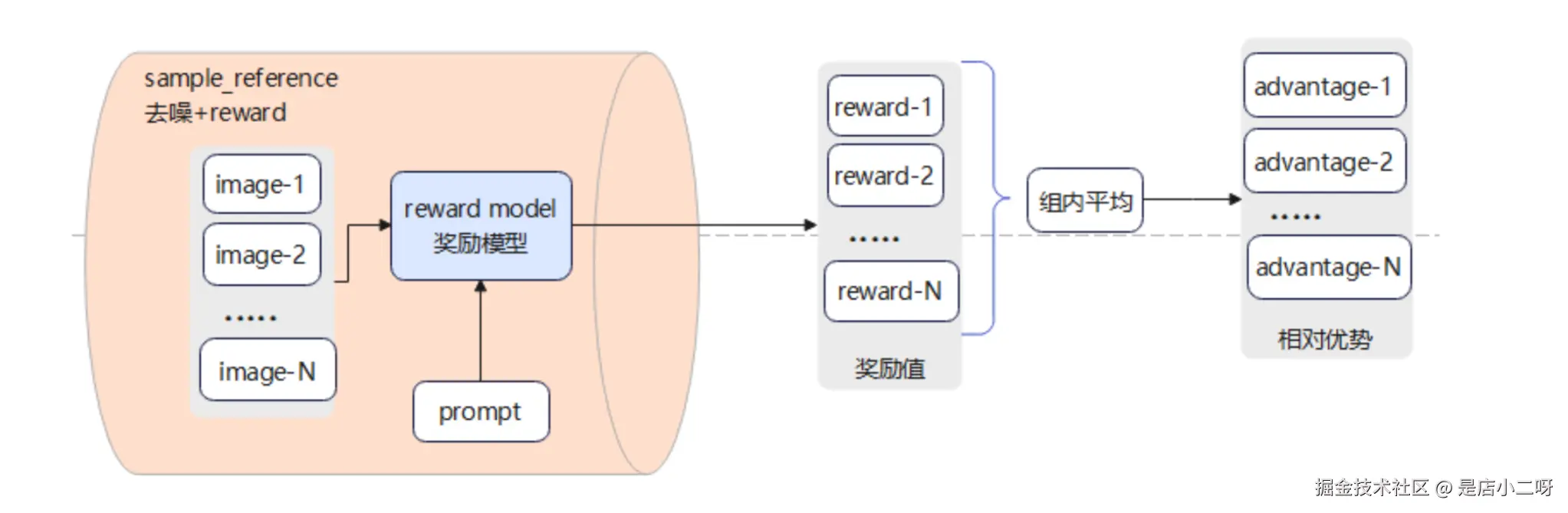
Reward 阶段(jisaunq reward 值)
- 计算奖励值: image 和 prompt 输入到 reward model,计算得到 reward 值。
- 计算相对优势值: 计算 reward 的组内平均值,每个 reward 和平均值比较,得到 advantage(组内相对优势)。
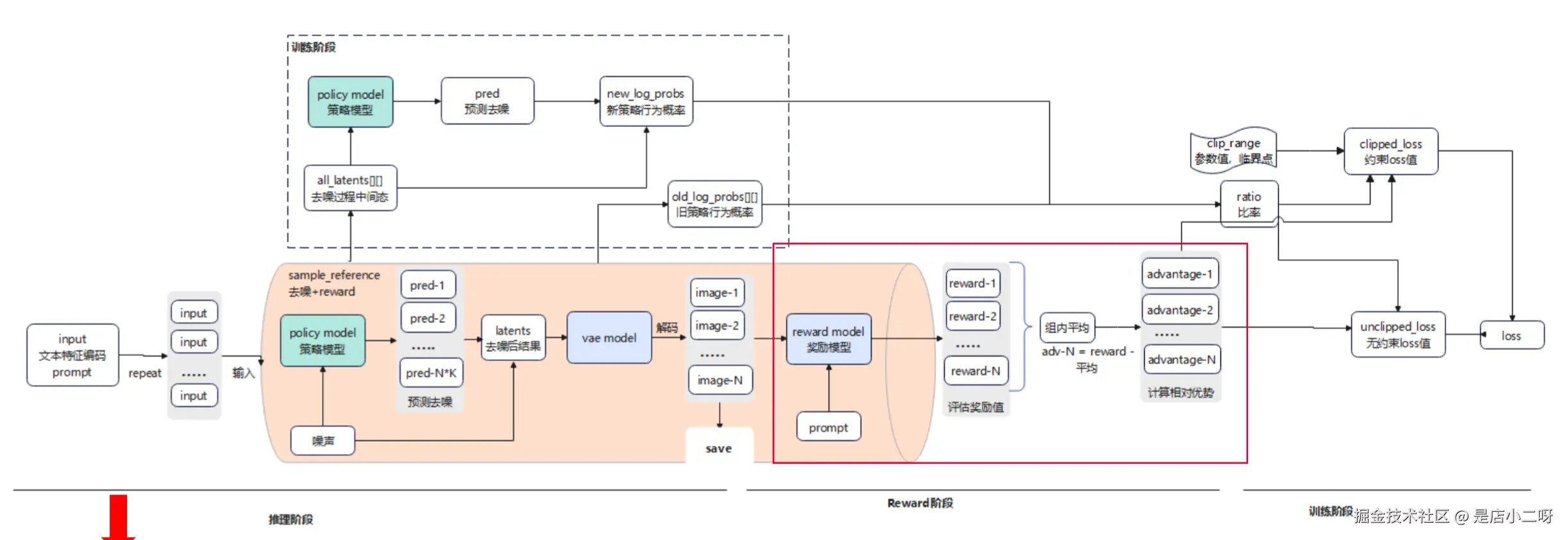
reward 详细流程
- 计算 reward 值:基于 prompt,图例阶段得到的完全去噪的 image 值,输入到 reward mode 中,经过一系列计算得到每个 image 的 reward 值。
- 计算 advantage 值:reward 值经过组内平均得到平均值,再用每个 iamge 的 reward 值和平均值对比,得到 advantage (相对优势值)。
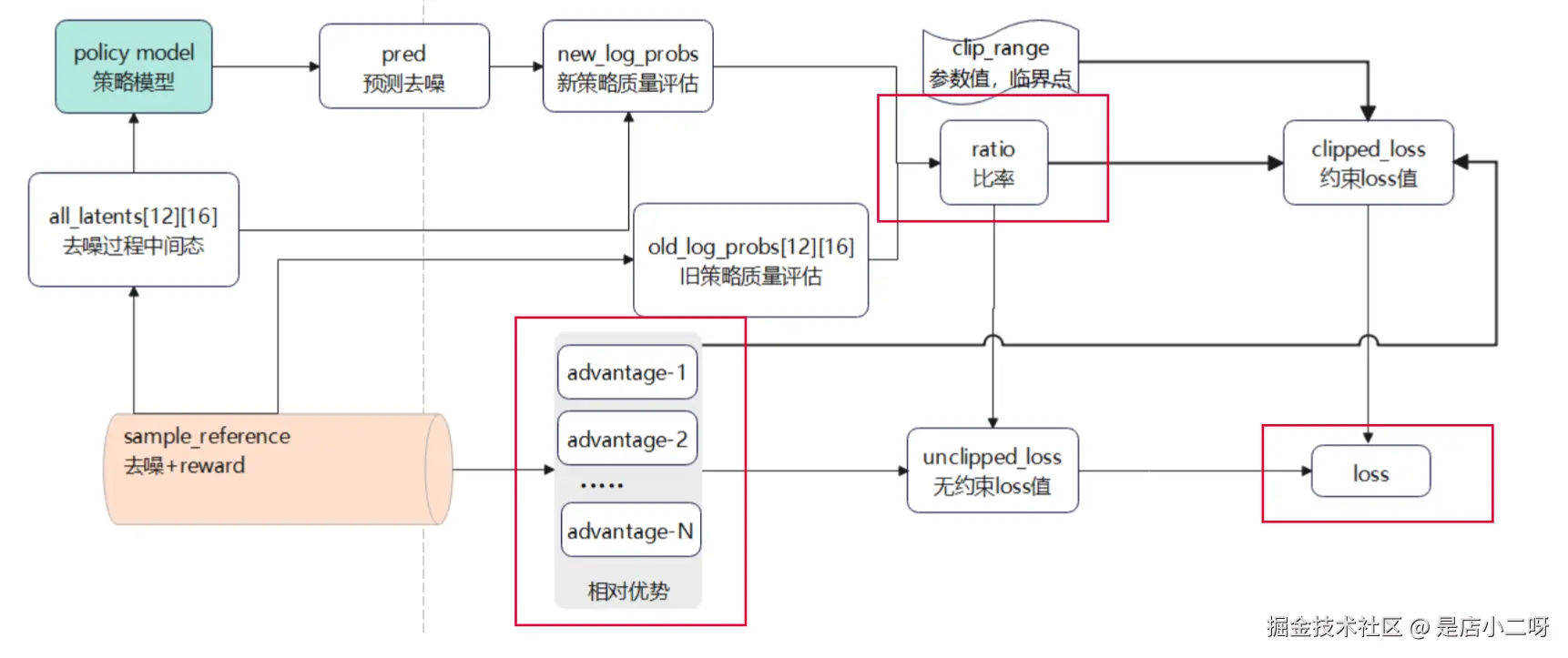
训练阶段(计算 loss,更新梯度)
- 记录去噪过程: 前面步骤会记录每个样本的去噪过程状态,包括 reward 值,advantag 值,log_p 值(代表当时策略的对数)。
- 计算新策略对数: 此时 policy model 会生成新预测值,根据新预测值计算出 new_log_p 值(代表新策略的对数)。
- 计算旧策略比率: f(new_log, old_log) = ratio,代表某行为在新旧策略的概率比。
- 计算 loss 值: 基于 ratio 和 advantage 计算出 loss 值。
训练详细流程
- loss 是基于 advantage 和 ratio 计算得出的,当 advantage 和 ratio 处于不同值时代表不同的含义
| ADVANTAGE | RATIO | 含义 |
|---|---|---|
| >0 | >1 | 该动作为优势动作,且新策略该动作概率更大,新策略正确的提升了该动作的概率,新策略更优 |
| >0 | <1 | 该动作为优势动作,且新策略该动作概率更小,新策略错误的抑制了优势动作,后续需要提高 ratio |
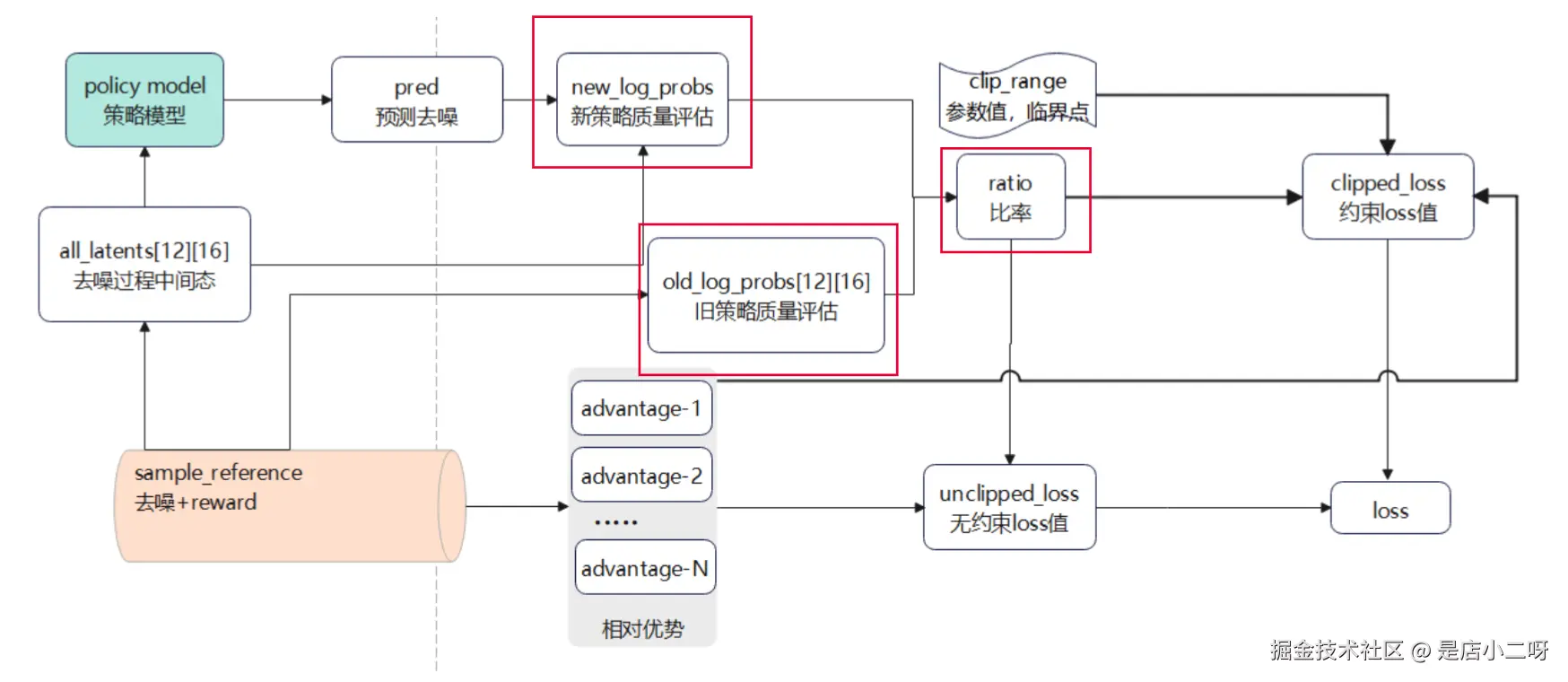
- 第一次计算 loss 时,policy mode 还没有更新权重,此时 new_log_p 和 old_log_p 实际上是一样的,就是虽然定义上是新旧策略,但实际上新旧策略的权重一样。
- loss 值会基于 advantage 和 ratio 一并计算,所以开始的 loss 值依赖于样本的 advantage 值,默认的梯度更新频率为 4 哥样品一次,当处理本组第四个样品后 ratio 就会开始变化了。
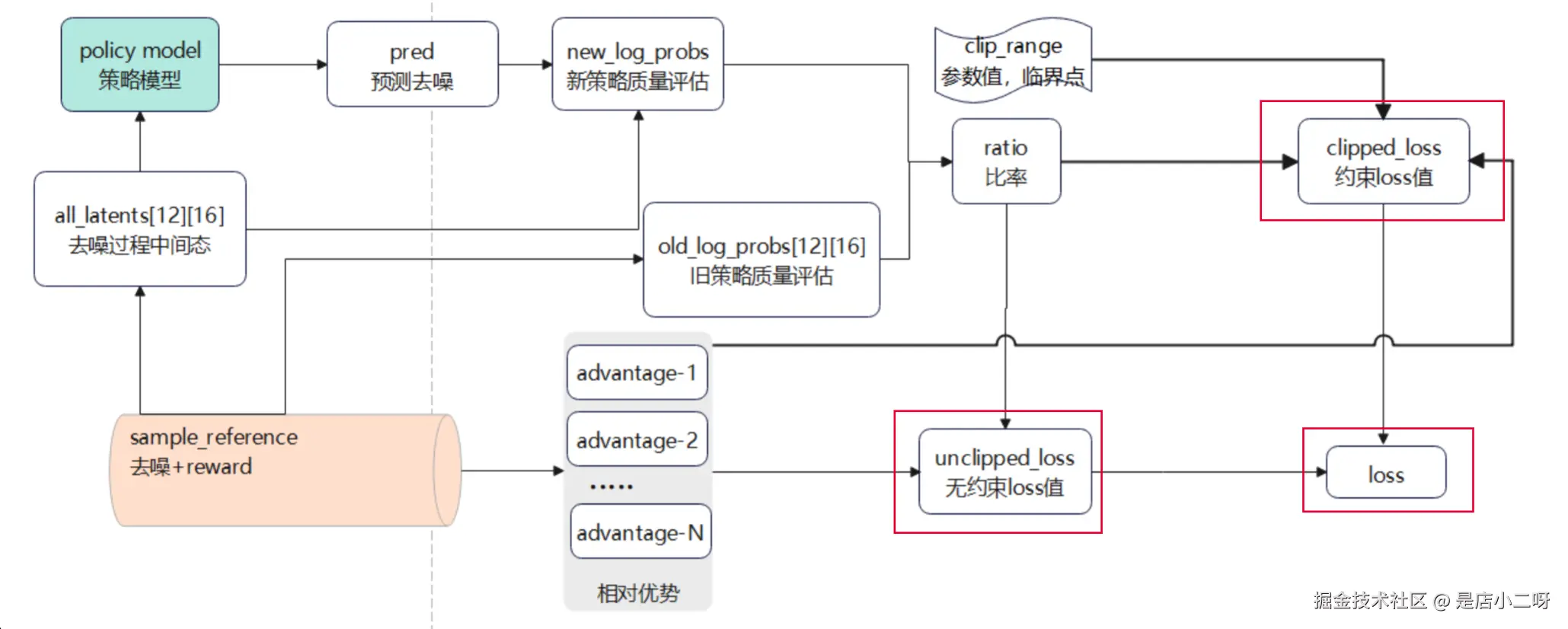
存在两个 loss 值,clipped_loss 和 unclipped_loss,都是基于 advantage 和 ratio 计算得到的,但是 clipped_loss 的计算中加入了 clip_range,约束了最终计算值的范围,防止局部过度优化。
四、模型部署流程
bash
git clone https://github.com/XueZeyue/DanceGRPO.git
- 下载权重
FLUX:huggingface.co/black-fores...
HPS:huggingface.co/xswu/HPSv2/...
open_clip:huggingface.co/laion/CLIP-...
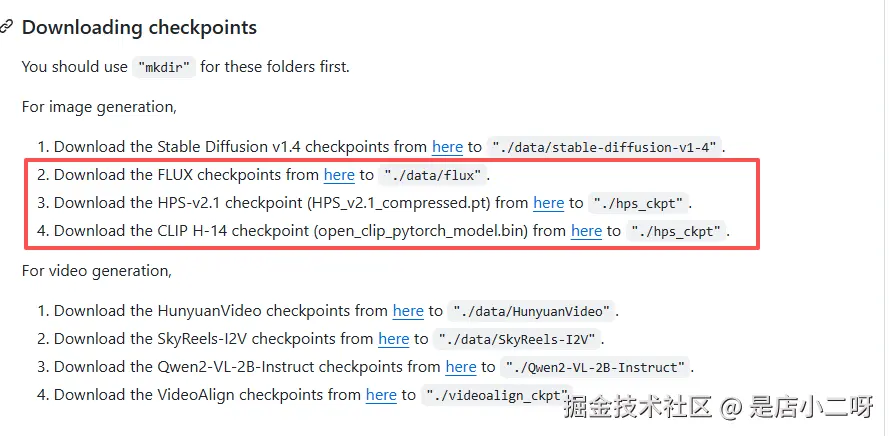
- 其它依赖安装
- 仓库未实现懒加载,所以会导入许多用不到的三方库,可以直接注释,避免引入太多无用的依赖,耗费开发时间。
- 一些为调用的接口也可以进行规避,例如 flashatth 三方库接口等。
python
# DanceGRPO/fastvideo/models/mochi_hf/modeling_mochi.py
# 注释掉以下
from liger_kernel.ops.swiglu import LigerSiLUMulFunction;flash_attn_no_pad.py
# flash_attn_no_pad.py
# 注释掉flash_attn的导包,flash_attn_no_pad注释掉中间逻辑,直接return;执行安装脚本:
bash
./env_setup.sh fastvideo- 修改
<font style="color:rgb(37, 43, 58);background-color:rgb(246, 247, 249);">preprocess_flux_embedding.py</font>:
python
# # 引入torch_npu
import torch_npu
from torch_npu.contrib import transfer_to_npu
# "./data/flux"写死的路径改成参数
# 原 : pipe = FluxPipeline.from_pretrained("./data/flux", torch_dtype=torch.bfloat16).to(device)
pipe = FluxPipeline.from_pretrained(args.model_path, torch_dtype=torch.bfloat16).to(device)- 修改
<font style="color:rgb(37, 43, 58);background-color:rgb(246, 247, 249);">train_grpo_flux.py</font>:
python
# # 引入torch_npu
import torch_npu
from torch_npu.contrib import transfer_to_npu- 执行 Flux GRPO 脚本:
bash
bash ./scripts/finetune/finetune_flux_grpo.sh五、模型验证
验证流程将 GRPO 的推理、reward、训练三个阶段单独抽离对齐,再进行全流程验证,采用"分 - 合" 验证策略:
- 单独阶段对齐能隔离不同模型和框架的差异,聚焦每个环节的前向计算准确性(比如推理阶段的动作生成、reward 阶段的评分计算、训练阶段的梯度更新),避免因单个阶段误差累积掩盖问题。
- 全流程对齐则能验证阶段间数据传递的一致性,尤其要关注跨框架交互时的数据格式、精度损失等细节。
记录关键节点的对齐数据(如中间特征、概率分布、loss 值、梯度等),既能作为阶段验证的基准,也能在全流程中快速定位误差来源。
随机性固定
load 版本(准确但麻烦)
通过
torch.save、torch.load的方式将程序中涉及随机性的变量,在 NPU 和 GPU 上保持一致。
- 关闭
shuffle,固定训练的数据顺序
ini
# fastvideo/train_grpo_flux.py中,shuffle设为false
sampler = DistributedSampler(train_dataset, rank=rank, num_replicas=world_size, shuffle=False, seed=args.sampler_seed)- prev_sample 固定
markdown
0. GPU代码修改如下,在GPU上运行后保存下来
ini
# 1. 添加全局变量COFF_STEP,控制coff生成的step数
COFF_STEP = 0
def flux_step():
global COFF_STEP
......
if grpo and prev_sample is None:
coff = torch.randn_like(prev_sample_mean)
torch.save(coff, f"saves/coff_{COFF_STEP}_{torch.distributed.get_rank()}.pt")
prev_sample = prev_sample_mean + coff * std_dev_t
COFF_STEP += 1
markdown
2. NPU 上加载
python
coff = torch.load(f"saves/coff_{COFF_STEP}_{torch.distributed.get_rank()}.pt", map_location=f"cuda:{torch.cuda.current_device()}")- input_latents 固定
markdown
0. GPU代码修改如下,在GPU上运行后保存下来
python
def sample_reference_model(
args,
device,
transformer,
vae,
encoder_hidden_states,
pooled_prompt_embeds,
text_ids,
reward_model,
tokenizer,
caption,
preprocess_val,
step, # # # 增加参数输入,用于序列文件记录,找到相关调用处,加上该入参
)
def train_one_step(
args,
device,
transformer,
vae,
reward_model,
tokenizer,
optimizer,
lr_scheduler,
loader,
noise_scheduler,
max_grad_norm,
preprocess_val,
step, # # # 增加参数输入,用于序列文件记录,找到相关调用处,加上该入参
)
def sample_reference_model();
......
if args.init_same_noise:
input_latents = torch.randn(
(1, IN_CHANNELS, latent_h, latent_w), # (c,t,h,w)
device=device,
dtype=torch.bfloat16,
)
torch.save(input_latents, f"saves/input_latents_{step}_{torch.distributed.get_rank()}.pt")
markdown
2. NPU上加载
python
input_latents = torch.load(f"saves/input_latents_{step}_{torch.distributed.get_rank()}.pt", map_location=f'cuda:{device}')- perms 固定
markdown
0. GPU代码修改如下,在GPU上运行后保存下来
scss
def train_one_step():
......
perms = torch.stack(
[
torch.randperm(len(samples["timesteps"][0]))
for _ in range(batch_size)
]
).to(device)
torch.save(perms, f"saves/perms_{step}_{torch.distributed.get_rank()}.pt")
css
2. <font style="color:rgb(37, 43, 58);">NPU上加载</font>
python
perms = torch.load(f"saves/perms_{step}_{torch.distributed.get_rank()}.pt", map_location=f'{device}')使用 CPU 进行随机性固定
固定seed可用于模型训练复现,但是不同的设备如GPU和NPU在同样的seed下生成的值也是不一样的,但是不同设备上都有CPU,因此可以固定seed后使用CPU生成张量,以此让GPU和NPU上生成的张量输入保持相同
fastvideo/train_grpo_flux.py:91修改为
css
if grpo and prev_sample is None:
prev_sample = prev_sample_mean + torch.randn_like(prev_sample_mean.cpu()).to(
prev_sample_mean.device) * std_dev_t<font style="color:rgb(59, 62, 85);">fastvideo/train_grpo_flux.py:270</font>修改为
ini
if args.init_same_noise:
input_latents = torch.randn(
(1, IN_CHANNELS, latent_h, latent_w), # (c,t,h,w)
dtype=torch.bfloat16,
).to(device)fastvideo/train_grpo_flux.py:657修改为
ini
sampler = DistributedSampler(
train_dataset, rank=rank, num_replicas=world_size, shuffle=False, seed=args.sampler_seed
)fastvideo/train_grpo_flux.py:1061增加
python
import random
def seed_all_own(seed=1234, mode=True, is_gpu=True):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['GLOBAL_SEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.use_deterministic_algorithms(mode)
if is_gpu:
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
torch.cuda.manual_seed_all(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enable = False
torch.backends.cudnn.benchmark = False
else:
import torch_npu
os.environ['HCCL_DETERMINISTIC'] = 'true'
os.environ['CLOSE_MATMUL_K_SHIFT'] = '1'
torch_npu.npu.manual_seed_all(seed)
torch_npu.npu.manual_seed(seed)
print("====== seed all ========")
seed_all_own(is_gpu=False)
from msprobe.pytorch import seed_all
seed_all(mode=True)
推理流程对齐
推理流程对齐的内容主要是 GRPO 去噪后生成的 latents,latents 解码成图片后对比:固定随机性,将GPU、NPU上使用相同noise的latents使用vae解码,再保存,此时只需要对比生成图片的差异。 关键代码:decoded_image[0].save(img_path),这里会保存训练过程中,模型在每个step,每次generation中生成的图片,可以直观的看到训练过程中的的变化。
ini
# # # # sample_reference_model函数
def sample_reference_model():
with torch.inference_mode():
with torch.autocast("cuda", dtype=torch.bfloat16):
latents = unpack_latents(latents, h, w, 8)
latents = (latents / 0.3611) + 0.1159
image = vae.decode(latents, return_dict=False)[0]
decoded_image = image_processor.postprocess(
image)
decoded_image[0].save(f"./images/flux_{step}_{rank}_{index}.png")
Reward Model 对齐
DanceGRPO 模型涉及多个 model,强化学习中需要对齐的主要是loss和reward值,这里讲的是如何对齐reward。
此处采取的方法是把reward model单独拿出来,for循环多步,对比GPU和NPU的值reward值,代码修改如下:
css
for step in range(1, 1001):
# text = tokenizer([batch_caption[0]]).to(device=device, non_blocking=True)
image = torch.load(f"/home/grpo/DanceGRPO/save/images-1/image_{step}_{rank}.pt")
text = torch.load(f"/home/grpo/DanceGRPO/save/texts-1/text_{step}_{rank}.pt")
# torch.save(image, f"/home/GRPO/DanceGRPO/save/images-1/image_{step}_{rank}.pt")
# torch.save(text, f"/home/GRPO/DanceGRPO/save/texts-1/text_{step}_{rank}.pt")
if rank == 0:
print(f"image_{rank}_{step}: ", image, "\n\n")
print(f"text_{rank}_{step}: ", text, "\n\n")
with torch.no_grad():
with torch.amp.autocast("cuda"):
outputs = reward_model(image, text)
if rank == 0:
print(f"output_{rank}_{step}: ", outputs, "\n\n")
image_features, text_features = outputs["image_features"], outputs["text_features"]
logits_per_image = image_features @ text_features.T
hps_score = torch.diagonal(logits_per_image)
all_rewards = []
all_rewards.append(hps_score)
all_rewards = torch.cat(all_rewards, dim=0)
samples = {
"rewards": all_rewards.to(torch.float32)
}
if rank == 0:
print(f"samples_{rank}_{step}: ", samples, "\n\n")
gathered_reward = gather_tensor(samples["rewards"])
if rank == 0:
print(f"gather_reward_{rank}_{step}: ", gathered_reward, "\n\n")
if dist.get_rank() == 0:
print("gathered_hps_reward", gathered_reward)
with open('./hps_reward.txt', 'a') as f:
f.write(f"{gathered_reward.mean().item()}\n")
samples_batched = {
k: v.unsqueeze(1)
for k, v in samples.items()
}
samples_batched_list = [ dict(zip(samples_batched, x)) for x in zip(*samples_batched.values()) ]
for i, sample in list(enumerate(samples_batched_list)):
if rank == 0:
print(f"sample_{rank}_{step}: ", sample["rewards"], "\n\n")
if dist.get_rank() % 8 == 0:
print("hps reward", sample["rewards"].item(), "\n\n\n\n\n")
# print("ratio", ratio)
# print("advantage", sample["advantages"].item())
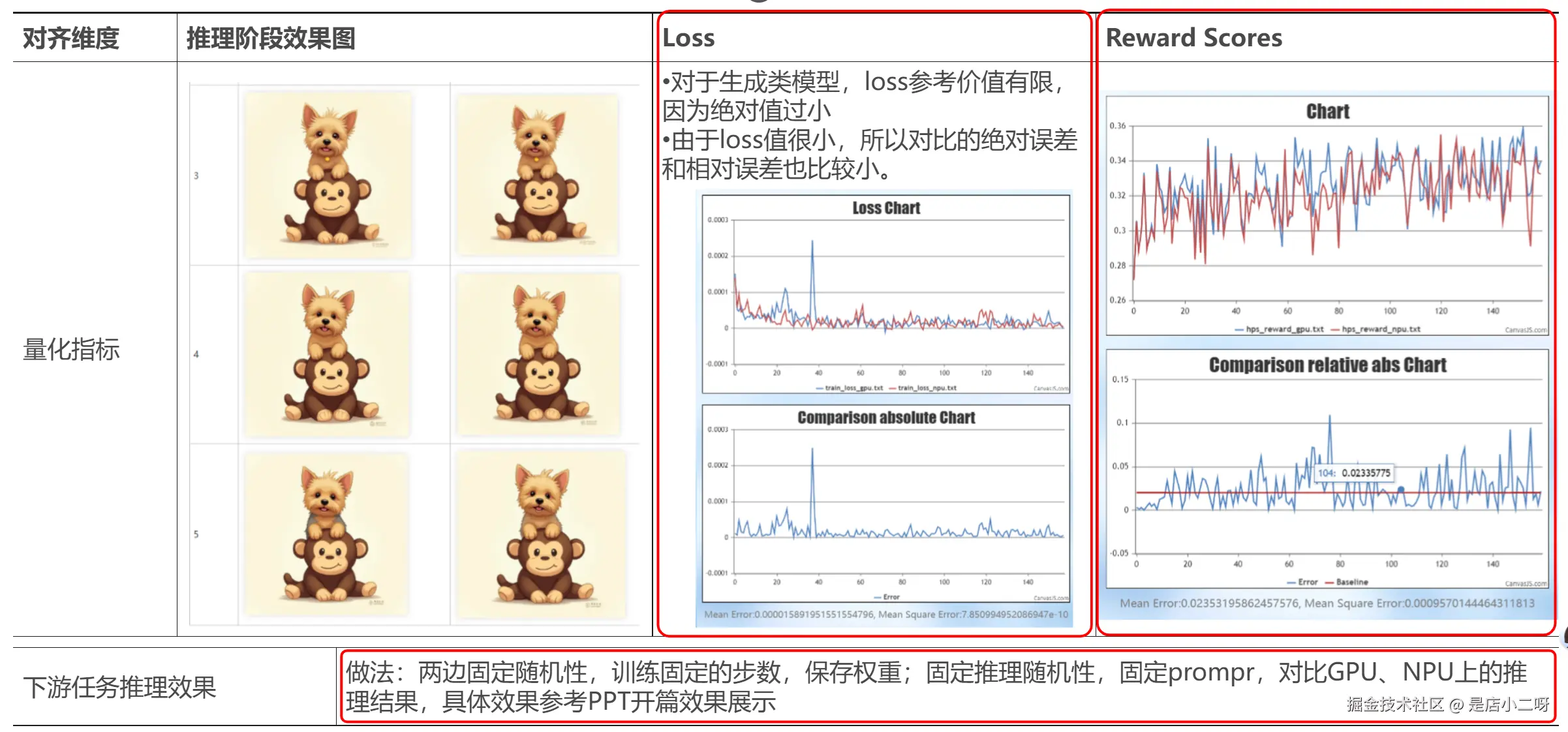
# print("final loss", loss.item())生成1000个reward值,其精度对比效果如下(绝对误差≈0.015%):
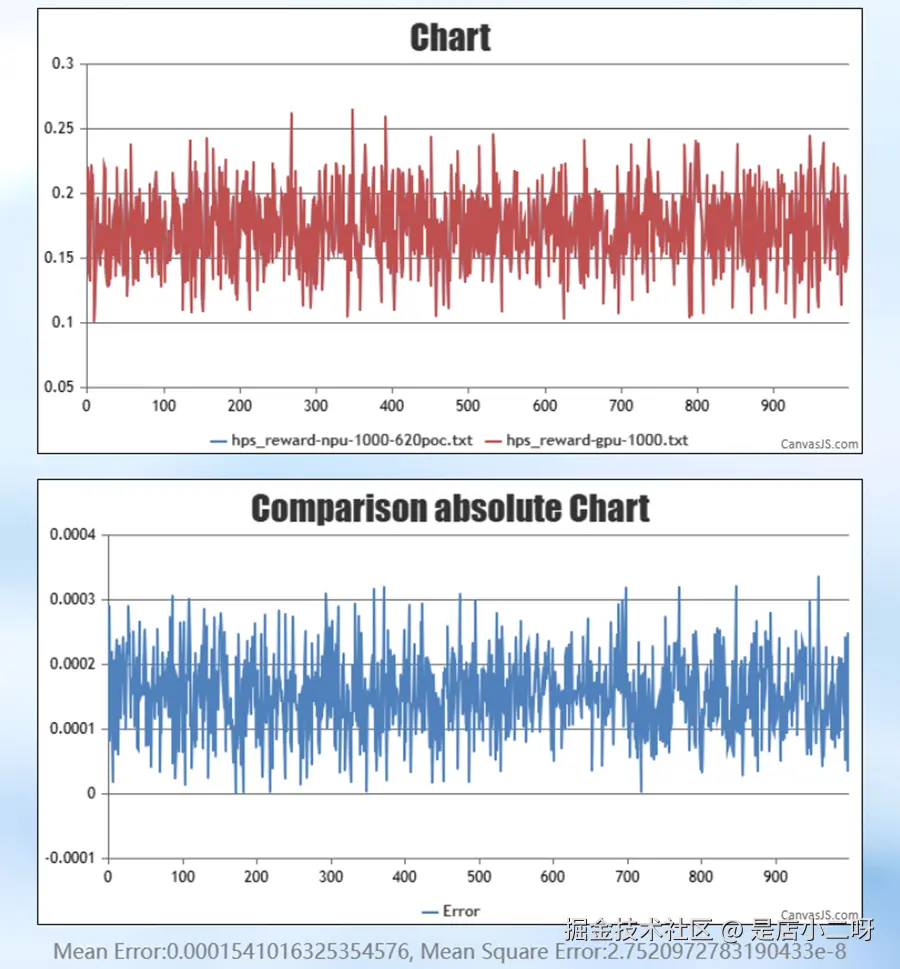
数据、图片来自昇腾官方数据。
端到端对齐
对齐标准
固定随机性后,需要按照如下标准关注对齐结果:
- 关注推理阶段生成的图片,主观对齐
- 关注训练过程中的loss(生成模型loss较小,参考价值有限)
- 关注reward scores,200步误差5%以内
对齐步骤
端到端对齐流程主要关注两方面,一方面是综合度量模型训练的指标:推理阶段图片+loss+rward scores,另一方面是下游任务推理效果。
全流程对齐具体步骤:
- 两边加载相同的预训练权重。
- 固定随机性:整体随机性与确定性计算固定(seed_all,mode=True),noise在cpu侧生成。
- 保存关键信息:推理阶段的图片、reward阶段的rewardvalues、训练阶段模型loss,同时保存权重,用于对齐推理效果,此处注意需要持续关注推理阶段生成图片的效果,具体例子为在替换rope融合算子时,loss结果与reward差异不大,但推理阶段出现了花图。
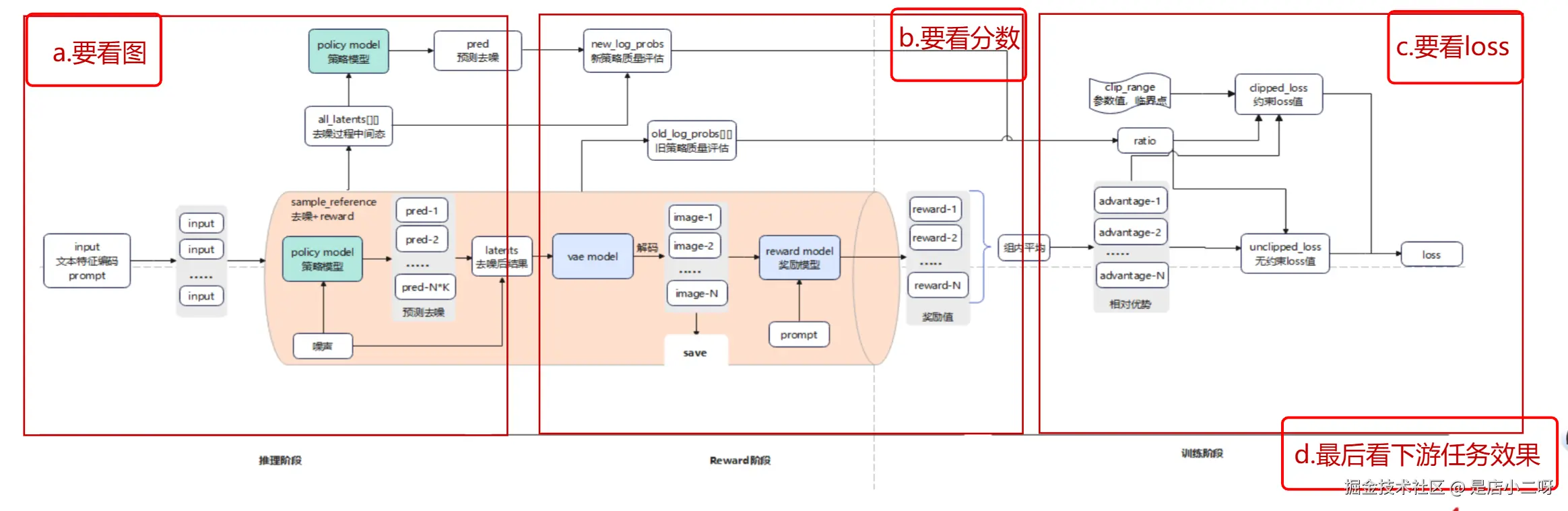
端到端流程结构
六、常见问题
如遇到ROPE部分不支持complex128计算问题,NPU场景需要适配修改___CODE_BLOCK_PLACEHOLDER___211250行
ini
is_mps = ids.device.type == "mps"
is_npu = ids.device.type == "npu" #增加改行
##下面增加is_npu判断
freqs_dtype = torch.float32 if is_mps or is_npu else torch.float64七、总结
DanceGRPO+FLUX 模型在 AI 生图领域,解决 FLUX 在生成过程中与人类审美、语义对齐等方面的适配问题,大幅提升其生图质量与稳定性。展望未来,多模态生成强化学习模型有望在更多领域开花结果,如影视特效制作中实现更逼真的虚拟场景与角色创建,教育领域中打造沉浸式的学习环境,医疗领域辅助医生进行手术模拟与病情可视化分析等 。同时,随着技术发展,模型将不断优化,生成效率与质量进一步提升,在处理复杂任务、理解模糊指令等方面取得更大突破,为各行业数字化转型与创新发展注入强大动力 。
注明:昇腾PAE案例库对本文写作亦有帮助。