人类天生就能本能地理解动作。当有人前倾、转头或抬手时,你立刻就能推断出他们在做什么。这是一种无声的、近乎下意识的技能,塑造着我们与他人互动和探索世界的方式。
随着科技在日常生活中日益普及,我们很自然地希望设备能像我们一样流畅地理解动作。近年来人工智能的进步,特别是基于深度学习的发展,正让这成为可能。其中,计算机视觉帮助机器从图像和视频中提取意义,是推动这一进程的关键。
例如,姿态估计是一项常见的计算机视觉任务,它可以预测图像或视频帧中预定义的身体关键点(如肩膀、肘部、髋部、膝盖)的位置。这些关键点可以通过一个固定的骨架定义连接起来,形成一个简化的人体姿态表示。

在本文中,我们将深入探讨姿态估计工具,了解其工作原理、应用场景以及目前可用的顶级模型和库。让我们开始吧!
什么是姿态估计?
姿态估计是一种计算机视觉技术,帮助系统理解人或物体在图像或视频中的姿态。它不是平均分析每个像素,而是预测一组一致的地标点,例如头部、肩膀、肘部、髋部、膝盖和脚踝。
大多数模型会输出这些关键点的坐标,以及一个反映每个预测正确可能性的置信度分数。然后,这些关键点可以通过预定义的骨架布局连接起来,形成一个简单的姿态表示。
当逐帧应用于视频时,得到的关键点可以随时间关联起来以估计运动。这使得动作形式检查、运动分析和基于手势的交互等应用成为可能。

为什么需要姿态估计工具?
人体动作承载着大量信息。一个人的弯腰、伸手或重心转移方式可以揭示其意图、努力程度、疲劳甚至受伤风险。直到最近,要捕捉这种细节通常还需要专门的传感器、动作捕捉服或受控的实验室环境。
姿态估计改变了这一点。从普通图像和视频中提取关键身体地标点,使得计算机能够使用标准摄像头分析动作。这让运动分析变得更加易于获取、可扩展,也更能适应现实世界的实际应用。
以下是姿态估计产生影响的几种方式:
- 更安全的工作场所: 视觉驱动的系统可用于在受伤发生前检测危险姿势、重复性劳损或不安全的举重技术。
- 更好的健身和运动训练: 视觉AI解决方案可以实时评估姿势、平衡和技术,无需可穿戴设备即可为用户提供即时反馈。
- 医疗保健和康复: 临床医生可以使用简单的视频记录远程跟踪恢复进度、姿势和活动范围。
- 互动体验: 姿态估计让数字虚拟形象和沉浸式环境能够更准确地跟随和反映人体运动。
姿态估计算法的演进
姿态估计的想法已经存在多年。早期方法使用简单的几何模型和手工制定的规则,通常只在受控条件下有效。
例如,当一个人静止站立在固定位置时,系统可能表现良好,但当他们在现实场景中开始行走、转身或与物体互动时,系统就可能失效。这些方法往往难以应对自然运动、变化的摄像机角度、杂乱的背景和部分遮挡。
现代姿态估计依靠深度学习来应对这些挑战。通过在大型标注数据集上训练卷积神经网络,模型学习到视觉模式,帮助它们在不同姿态、人物和环境中更可靠地检测关键点。随着看到更多样本,模型会改进其预测,并更好地泛化到新的场景。由于这些进步,姿态估计现在支持广泛的实际应用,包括工作场所监控、人体工程学和体育分析,教练和分析师借此研究运动员的动作。
姿态估计技术的类型
姿态估计根据环境和需要测量的内容,有几种不同的形式。以下是您会遇到的主要类型:
- 2D姿态估计: 这种方法在二维图像或视频帧中检测身体关键点。它适用于标准摄像头,计算效率高,适合基本的运动跟踪、姿势分析和实时姿势反馈等任务。
- 3D姿态估计: 通过额外估计深度信息,3D姿态提供了对身体运动的空间理解。这在前后运动很重要时尤其有用,例如体育分析、康复、生物力学和动画制作。具体来说,3D人体姿态估计捕获三维空间中的关节位置和运动,减少了2D投影可能产生的模糊性。
- 单人姿态估计: 这些系统旨在一次跟踪一个个体。它们通常在受控或半受控环境中表现最佳,例如指导性锻炼应用、视频通话或运动分析设置。
- 多人姿态估计: 为有多人的场景设计,这种方法可以同时检测和跟踪多个个体的姿态。这在繁忙的环境中特别有用,例如工作场所、健身房、公共空间和团体活动中,因为目标人物可能会重叠或相互遮挡。
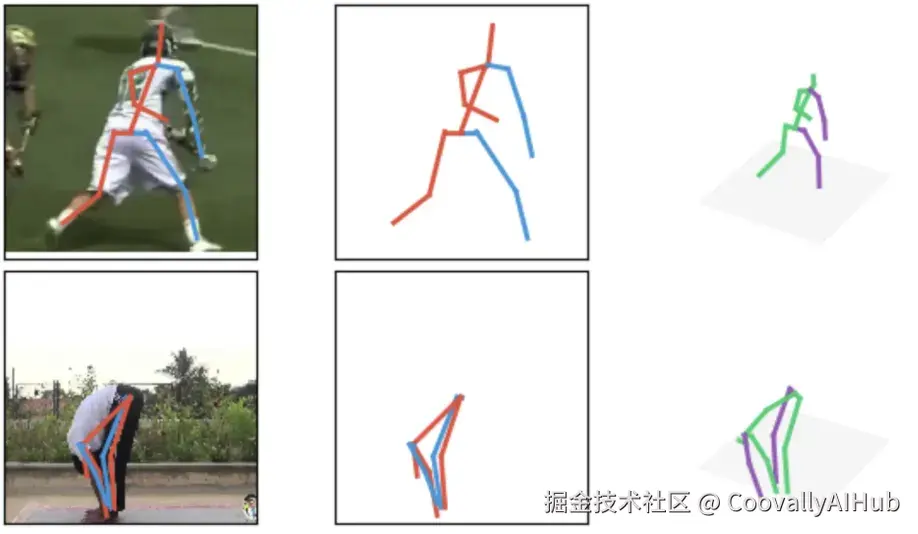
了解人体姿态估计模型如何工作
姿态估计可以应用于许多种类的物体,但为了简单起见,我们重点讨论人体姿态估计。
大多数人体姿态估计系统是在标注数据集上训练的,这些数据集包含大量图像和视频帧,其中人体关键部位被标记出来。通过这些样本,模型学习到与人体地标点(如肩膀、肘部、髋部、膝盖、脚踝)相关的视觉模式,从而能在新场景中准确预测关键点。
另一个关键方面是模型的推理架构,它决定了模型如何检测关键点并将它们组装成完整的姿态。有些系统先检测每个人,然后在每个人的区域内估计关键点;另一些系统则在整个图像中检测关键点,然后再将它们分组到个体身上。较新的单阶段设计可以在一次前向传播中预测姿态,平衡了实时应用的速度和准确性。
接下来,让我们详细了解一下不同的姿态估计方法。
- 自底向上的姿态估计
在自底向上的方法中,模型首先查看整个图像,找出所有身体关键点,比如头、肩、肘、髋、膝、踝。在这个阶段,它并不试图区分不同的人。它只是在整个场景中检测由姿态骨架定义的所有关键点或身体关节。
之后,系统进行第二步来"连接这些点"。它将属于同一个人的关键点连接起来,并分组形成完整的骨架。由于它不需要先检测每个人,自底向上的方法通常在拥挤的场景中表现良好,比如人物重叠、大小不一或部分被遮挡的情况。
- 自顶向下的姿态检测
相比之下,自顶向下的系统首先检测图像中的每个人。它们在每个个体周围放置一个边界框,并将每个框视为独立的分析区域。
一旦一个人被单独隔离出来,模型就会预测该区域内的身体关键点。这种分步进行的设置通常能产生非常准确的结果,尤其是在场景中只有少数人且每个人都清晰可见的情况下。
- 单阶段或混合姿态估计
单阶段(有时称为混合)模型在一次前向传播中预测姿态。它们不是先运行人员检测再进行关键点估计,而是同时输出人员位置和身体关键点。
因为所有步骤都在单一模块中完成,这些模型通常更快、更高效,这使它们非常适用于实时应用,如实时运动跟踪和动作捕捉。
训练和评估姿态估计模型
无论采用哪种方法,姿态估计模型在实际应用中可靠之前,仍然需要仔细的训练和测试。它通常从大型图像(有时是视频)集合中学习,其中身体关键点已被标记,这有助于它处理不同的姿态、摄像机角度和环境。
一些知名的姿态估计数据集包括 COCO Keypoints、MPII Human Pose、CrowdPose 和 OCHuman。当这些数据集不能反映模型在部署时将面临的环境时(例如工厂车间、健身房或诊所),工程师通常会从目标环境中收集并标注额外的图像。

训练后,模型会在标准基准测试上进行评估,以衡量其准确性和鲁棒性,并为实际应用的进一步调优提供指导。结果通常使用平均精度均值(mAP)来报告,该指标通过比较预测姿态与标注的真实姿态,综合了不同置信度阈值下的性能。
在许多姿态基准测试中,预测姿态与真实姿态之间使用对象关键点相似度(OKS)进行匹配。OKS 衡量预测关键点与标注关键点的接近程度,同时考虑了人物的尺度和每个关键点典型的定位难度等因素。
姿态模型还会为检测到的人和各个关键点输出置信度分数。这些分数反映了模型的置信度,用于对预测进行排序和过滤,这在具有遮挡、运动模糊或异常摄像机角度等挑战性的条件下尤其重要。
流行的姿态估计工具
如今有许多姿态估计工具可供选择,各自在速度、准确性和易用性之间取得平衡。以下是一些最常用的工具和库:
- YOLO11: 作为最先进的开源视觉AI模型开发,YOLO11 建立在 YOLOv8 等早期模型之上。它提高了速度、准确性和整体效率,同时支持包括姿态估计在内的各种计算机视觉任务。凭借在从笔记本电脑到边缘设备等各种平台上的强大性能,YOLO11 是许多实际部署场景的绝佳选择。
- Coovally: 这是一个AI模型训练与应用平台。它整合了国内外开源社区1000+模型算法和各类公开识别数据集,无需配置环境、修改配置文件等繁琐操作,即可训练模型,模型可分享与下载。
- MediaPipe: 这是一个用于构建视觉和机器学习管道的跨平台框架。它轻量级,能在移动设备、平板电脑和网络应用中高效运行,并包含全身姿态、面部标志点和手部跟踪等即用型解决方案和模型。
- OpenPose: 这是一个广泛使用的端到端开源姿态估计系统,以多人关键点检测而闻名。它可以同时估计身体、手部和面部的关键点,通常用于研究、动画和运动分析。
- MMPose: MMPose 是 OpenMMLab 生态系统中的一个基于 PyTorch 的姿态估计工具包。它提供了许多模型实现、训练工具和配置选项,这对于实验和深度定制非常有用。
- HRNet 和 AlphaPose: 这些是较早期的姿态估计模型,至今仍在研究中使用。HRNet 是一种能始终保持高分辨率图像特征网络的姿态模型架构,这有助于其精确定位关键点。AlphaPose 是一个广泛使用的多人姿态估计系统,通常在拥挤或复杂场景中需要高精度时使用。
姿态分析与估计的现实应用
姿态估计正越来越多地被用于将普通视频转化为有用的运动洞察。通过逐帧跟踪身体关键点,这些系统可以从摄像头信息中推断姿势、运动和身体行为,使此类技术在许多现实场景中变得实用。
例如,在医疗保健和康复领域,姿态跟踪可以帮助临床医生观察和测量患者在治疗和恢复期间的活动。通过从普通视频记录中提取身体地标点,可用于评估姿势、活动范围和随时间变化的整体运动模式。这些测量可以支持和优化传统的临床评估,并且在某些情况下,可以更轻松地跟踪进展,而无需可穿戴传感器或专用设备。
同样,在体育和广播领域,姿态估计可以直接从视频信息中分析运动员的动作。一个有趣的例子是鹰眼系统,这是一个基于摄像头的追踪系统,用于职业体育中的裁判和广播图形显示。它还能通过从摄像机视图估计运动员的身体关键点来提供骨架跟踪。
选择合适的姿态估计工具
选择合适的姿态估计工具,首先要了解您计算机视觉项目的需求。有些应用优先考虑实时速度,而另一些则需要更高的准确性和细节。
目标部署设备也很重要。移动应用和边缘设备通常需要轻量级、高效的模型,而服务器或云环境则通常更适合较大的模型。
此外,易用性也起着作用。良好的文档、顺畅的部署以及对自定义训练的支持,可以简化您的项目。
简而言之,不同的工具在不同的领域表现出色。例如,对于许多现实世界的姿态估计应用,Ultralytics YOLO 系列模型在速度、准确性和部署便捷性之间提供了实用的平衡。
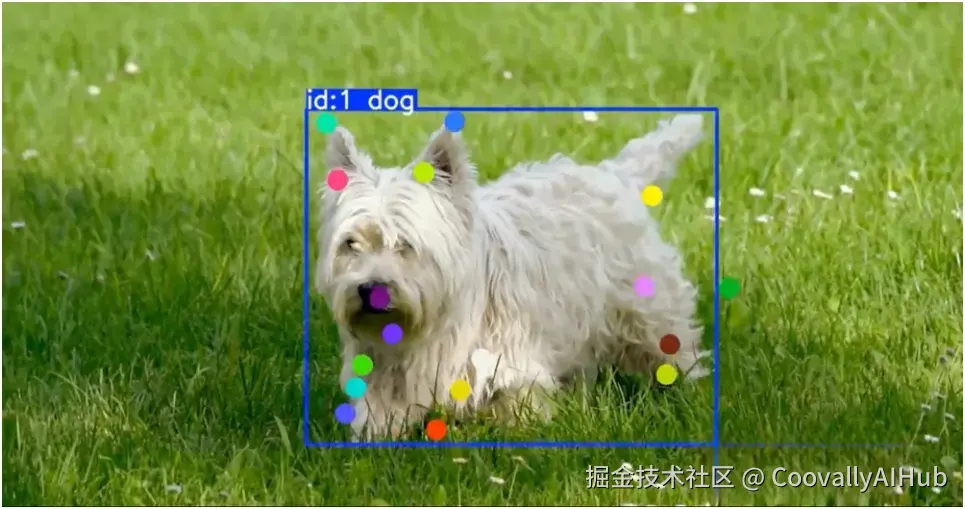
总结
姿态估计通过检测图像和视频中的身体关键点,帮助计算机理解人体运动。像 YOLO11 和 YOLO26 这样的模型使得为体育、医疗保健、工作场所安全和互动体验等领域构建实时应用变得更加容易。随着模型变得越来越快、越来越准确,姿态估计很可能成为许多视觉AI系统中的常见功能。