Pandas读写CSV、Excel、JSON文件
- [一、 读取和写入 CSV 文件](#一、 读取和写入 CSV 文件)
-
- [1、读取 CSV (`pd.read_csv`)](#1、读取 CSV (
pd.read_csv)) - [2、写入 CSV (`df.to_csv`)](#2、写入 CSV (
df.to_csv))
- [1、读取 CSV (`pd.read_csv`)](#1、读取 CSV (
- [二、读取和写入 Excel 文件](#二、读取和写入 Excel 文件)
-
- [1、读取 Excel (`pd.read_excel`)](#1、读取 Excel (
pd.read_excel)) - [2、写入 Excel (`df.to_excel`)](#2、写入 Excel (
df.to_excel))
- [1、读取 Excel (`pd.read_excel`)](#1、读取 Excel (
- [三、读取和写入 JSON 文件](#三、读取和写入 JSON 文件)
-
- [1、读取 JSON (`pd.read_json`)](#1、读取 JSON (
pd.read_json)) - [2、写入 JSON (`df.to_json`)](#2、写入 JSON (
df.to_json))
- [1、读取 JSON (`pd.read_json`)](#1、读取 JSON (
一、 读取和写入 CSV 文件
CSV (Comma-Separated Values) 是一种非常常见的纯文本数据格式。
1、读取 CSV (pd.read_csv)
这是最常用的读取方式。
python
import pandas as pd
# 基本读取
df_csv = pd.read_csv('data.csv') # 文件路径
# 常用参数
df_csv = pd.read_csv(
'data.csv',
sep=',', # 分隔符,默认是逗号,也可以是 '\t' 等
header=0, # 指定哪一行作为列名(表头),默认第0行。header=None 表示没有表头
index_col=0, # 指定哪一列作为行索引
names=['col1', 'col2', 'col3'], # 自定义列名(尤其当 header=None 时)
dtype={'col1': int, 'col2': str}, # 指定列的数据类型
skiprows=[0, 2], # 跳过指定的行(如标题行后的说明行)
na_values=['NA', 'missing'], # 指定哪些值应被视为缺失值 (NaN)
encoding='utf-8' # 文件编码,常用 'utf-8', 'gbk' (中文可能需此)
)
print(df_csv.head()) # 查看前几行使用示例:
假设CSV文件内容如下,保存在"data.csv"文件中
autohotkey
Name,Age,Occupation
John,30,Engineer
Jane,25,Designer读取"data.csv"文件
python
import pandas as pd
# 基本读取
df_csv = pd.read_csv(
'data.csv',
header=0, # 指定哪一行作为列名(表头),默认第0行。header=None 表示没有表头
names=['col1', 'col2', 'col3'], # 自定义列名(尤其当 header=None 时)
)
print(df_csv.head(3)) # 查看前几行输出:
python
col1 col2 col3
0 John 30 Engineer
1 Jane 25 Designer2、写入 CSV (df.to_csv)
将 DataFrame 保存为 CSV 文件。
python
# 基本写入
df_csv.to_csv('output.csv') # 默认会写入索引 (index)
# 常用参数
df_csv.to_csv(
'output.csv',
index=False, # 不写入行索引
sep='\t', # 指定分隔符,例如制表符分隔 (TSV)
columns=['col1', 'col3'], # 只写入指定列
header=True, # 是否写入列名 (表头),默认 True
na_rep='NULL', # 缺失值 (NaN) 用什么字符串表示
encoding='utf-8' # 指定编码
)使用示例:
python
import pandas as pd
data = {
"Name": ["John", "Jane"],
"Age": [30, 25],
"Occupation": ["Engineer", "Designer"]
}
df = pd.DataFrame(data)
df.to_csv("output.csv", index=False)二、读取和写入 Excel 文件
Excel 文件 (.xlsx, .xls) 是电子表格格式。
1、读取 Excel (pd.read_excel)
需要安装 openpyxl (用于 .xlsx) 或 xlrd (用于 .xls) 引擎。
python
# 基本读取
df_excel = pd.read_excel('data.xlsx') # 默认读取第一个 Sheet
# 常用参数
df_excel = pd.read_excel(
'data.xlsx',
sheet_name='Sheet1', # 指定 Sheet 名称或索引 (0, 1, ...)
header=0, # 同 read_csv
index_col=0, # 同 read_csv
names=['col1', 'col2'], # 同 read_csv
dtype={'col1': str},
skiprows=3, # 跳过开头 N 行
usecols='A:C, E', # 指定读取哪些列 (例如 A列到C列,以及E列)
engine='openpyxl' # 引擎,通常自动选择,但可指定
)
print(df_excel.head())使用示例:
假设"data.xlsx"文件内容如下图所示
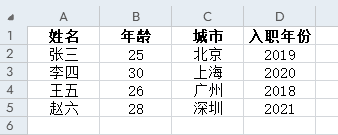
读取"data.xlsx"文件内容:
python
import pandas as pd
# 基本读取
df_excel = pd.read_excel('data.xlsx') # 默认读取第一个 Sheet
print(df_excel)输出:
python
姓名 年龄 城市 入职年份
0 张三 25 北京 2019
1 李四 30 上海 2020
2 王五 26 广州 2018
3 赵六 28 深圳 20212、写入 Excel (df.to_excel)
需要安装 openpyxl 或 XlsxWriter 引擎。
python
# 基本写入
df_excel.to_excel('output.xlsx') # 默认写入第一个 Sheet,会覆盖原文件!
# 常用参数
df_excel.to_excel(
'output.xlsx',
sheet_name='NewData', # 指定 Sheet 名称
index=False, # 不写入行索引
columns=['col1', 'col3'], # 只写入指定列
header=True, # 是否写入表头
na_rep='', # 缺失值表示
engine='openpyxl' # 引擎
)
# 写入多个 Sheet (需创建 ExcelWriter 对象)
with pd.ExcelWriter('multi_sheet.xlsx', engine='openpyxl') as writer:
df1.to_excel(writer, sheet_name='Sheet1')
df2.to_excel(writer, sheet_name='Sheet2')
# ... 可以继续添加更多 DataFrame 到不同 Sheet使用示例:
python
import pandas as pd
# 创建示例 DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 28],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
# 写入 Excel 文件
df.to_excel("output.xlsx", index=False) # index=False 表示不写入行索引输出效果:
python
# 生成的 output.xlsx 内容如下:
姓名 年龄 城市
张三 25 北京
李四 30 上海
王五 28 广州三、读取和写入 JSON 文件
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。
1、读取 JSON (pd.read_json)
JSON 格式比较灵活,读取时可能需要指定结构。
python
# 基本读取 - 适用于行格式 (每行是一个 JSON 对象)
# 示例 data.json: [{"name": "Alice", "age": 30}, {"name": "Bob", "age": 25}]
df_json = pd.read_json('data.json')
# 适用于列格式 (orient='columns') 或拆分格式 (orient='split')
# 示例 data.json: {"columns":["name","age"], "index":[0,1], "data":[["Alice",30],["Bob",25]]}
df_json = pd.read_json('data.json', orient='split') # 指定格式
# 常用参数
df_json = pd.read_json(
'data.json',
orient='records', # 常见格式:'records' (行对象), 'split', 'index', 'columns', 'values'
lines=True, # 如果文件是每行一个 JSON 对象 (json lines)
dtype={'age': int},
encoding='utf-8'
)
print(df_json.head())使用示例:
python
import pandas as pd
df_read = pd.read_json('data.json')
# 显示读取的数据
print(df_read)输出:
python
姓名 年龄 城市
0 张三 25 北京
1 李四 30 上海
2 王五 28 广州2、写入 JSON (df.to_json)
可以指定不同的输出格式。
python
# 基本写入 - 默认是列方向 (columns) 格式
df_json.to_json('output.json')
# 常用参数和格式
df_json.to_json(
'output.json',
orient='records', # 常用:每行数据作为一个 JSON 对象 [{...}, {...}]
lines=True, # 配合 'records' orient,输出为每行一个 JSON 对象
index=False, # 是否包含行索引
force_ascii=False # 允许输出非 ASCII 字符 (如中文)
)
# 格式化输出 (indent) - 但 lines=True 时不适用
df_json.to_json('pretty.json', orient='records', indent=2)使用示例:
python
import pandas as pd
# 创建一个示例 DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 28],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
# 将 DataFrame 写入 JSON 文件 (默认以 'columns' 方向存储)
df.to_json('data.json', orient='records', force_ascii=False, indent=4)
# 参数说明:
# orient='records': 将数据存储为记录列表格式 (每行是一个字典)
# force_ascii=False: 允许保存非 ASCII 字符 (如中文)
# indent=4: 使用缩进美化输出,提高可读性输出效果:
写入后的 data.json 文件内容类似于:
json
[
{
"姓名": "张三",
"年龄": 25,
"城市": "北京"
},
{
"姓名": "李四",
"年龄": 30,
"城市": "上海"
},
{
"姓名": "王五",
"年龄": 28,
"城市": "广州"
}
]注意事项
- 文件路径 :可以使用相对路径 (如
'data.csv') 或绝对路径 (如'C:/Users/data.csv')。注意路径中的斜杠/或反斜杠\(在字符串中,反斜杠可能需要转义'C:\\Users\\data.csv'或使用原始字符串r'C:\Users\data.csv')。 - 编码问题 :处理中文或其他非英文字符时,
encoding参数非常重要。常见的有'utf-8','gbk','latin1'等。如果读取时出现乱码,尝试不同编码。 - 缺失值处理 :
na_values(读取时) 和na_rep(写入时) 可以帮助处理缺失值。 - 文件存在性:写入操作会覆盖同名文件!请小心操作。
- 依赖库 :读写 Excel 需要额外的库 (
openpyxl,xlrd)。确保已安装 (pip install openpyxl xlrd)。