第一步先完成相关包的导入
python
# 导包
import pandas as pd
import seaborn as sns # 底层依赖 Matplotlib
import matplotlib.pyplot as plt
import os
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
os.chdir(r'D:\LLM\pandasProject') # 设置当前工作目录1、Pandas绘图
介绍: Pandas绘图可以基于 df对象直接绘图, 它的底层依赖 Matplotlib
python
# 1. 加载数据集, 并设置 第1列为 索引列.
df = pd.read_csv('./data/winemag-data_first150k.csv', index_col=0)
df
# 列展示
# print(df.columns)
# Index(['country', 'description', 'designation', 'points', 'price', 'province',
# 'region_1', 'region_2', 'variety', 'winery'],
# dtype='object')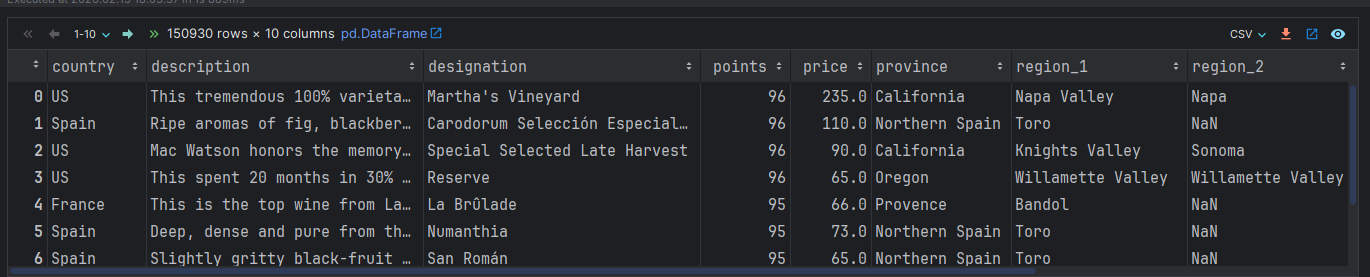
python
# 2. 查看数据集.
df.info()
df.describe()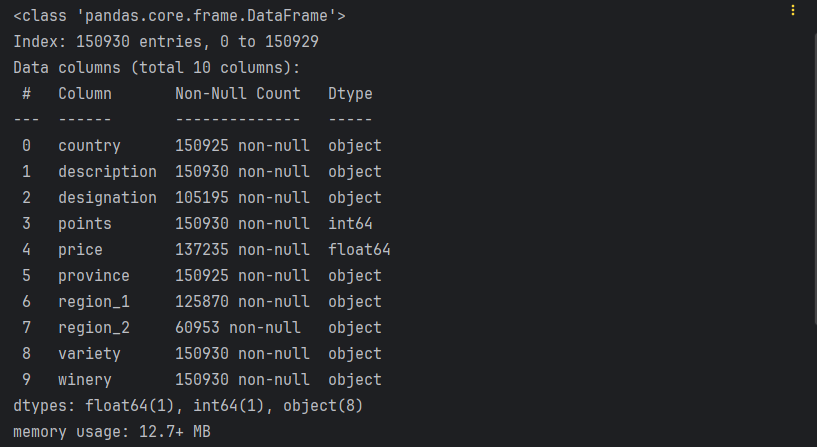
需求1: 绘制图形, 展示 产葡萄酒最多的10个产地的信息.
python
# 3. 分组统计
# 思路1: 根据产地(province)分组, 基于points列(也可以是其它的不包含缺失值的列) 进行count统计即可.
df.groupby('province', as_index=False).points.count().sort_values('points', ascending=False).head(10)
# 思路2: value_counts() 值的个数, 且会自动降序排列, 它相当于: groupby() + count() + sort_values()
df['province'].value_counts().head(10)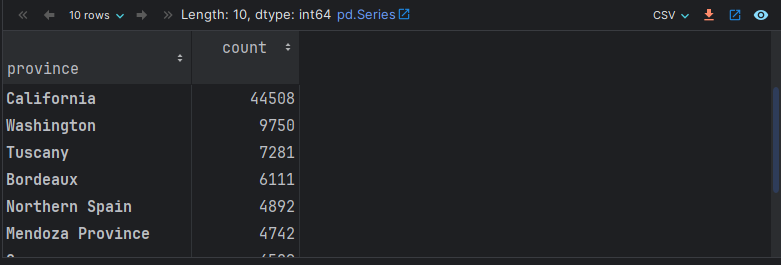
python
# 4. 针对于上述的结果, 绘图展示.
df['province'].value_counts().head(10).plot() # 折线图, 语法糖
# df['province'].value_counts().head(10).plot.line(figsize=(10, 5), color=['r', 'g', 'b', 'y', 'c', 'm', 'k', 'pink', 'gray']) # 折线图
df['province'].value_counts().head(10).plot.bar(figsize=(10, 5), color=['r', 'g', 'b', 'y', 'c', 'm', 'k', 'pink', 'gray'], fontsize=15) # 柱状图
# 5. 最终写法.
# step1: 定义变量, 记录参数, 字典形式.
text_kwargs = dict(figsize=(10, 5), color=['r', 'g', 'b', 'y', 'c', 'm', 'k', 'pink', 'gray'], fontsize=15)
# print(text_kwargs)
# step2: 绘图, 传参.
df['province'].value_counts().head(10).plot.bar(**text_kwargs)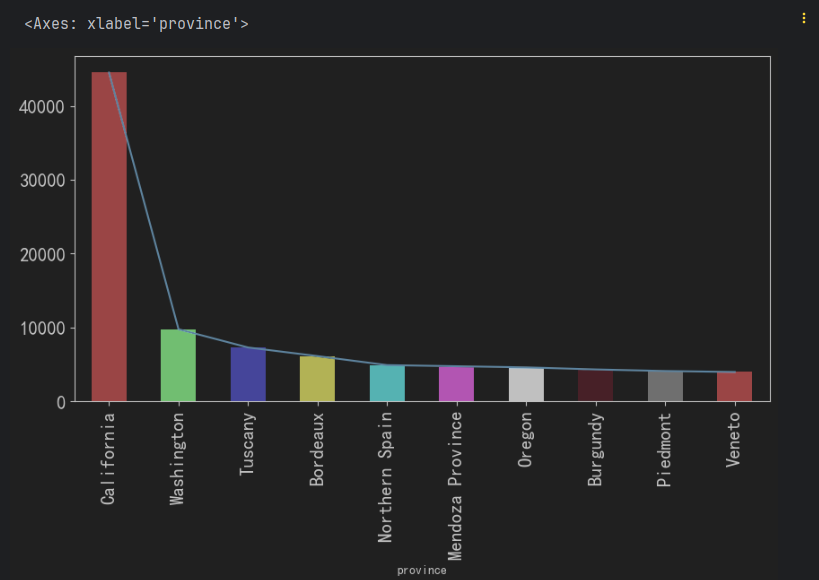
需求2: 绘制图形, 展示 葡萄酒最多的10个产地的 占比
python
# 1. 计算 葡萄酒最多的10个产地.
df['province'].value_counts().head(10)
# 2. 计算 每个产地的 占比, 即: 产地产的葡萄酒数量 / 总共的葡萄酒数量
# len(df) # 150930
df['province'].value_counts().head(10) / len(df)
# 3. 绘图
(df['province'].value_counts().head(10) / len(df)).plot.bar(**text_kwargs)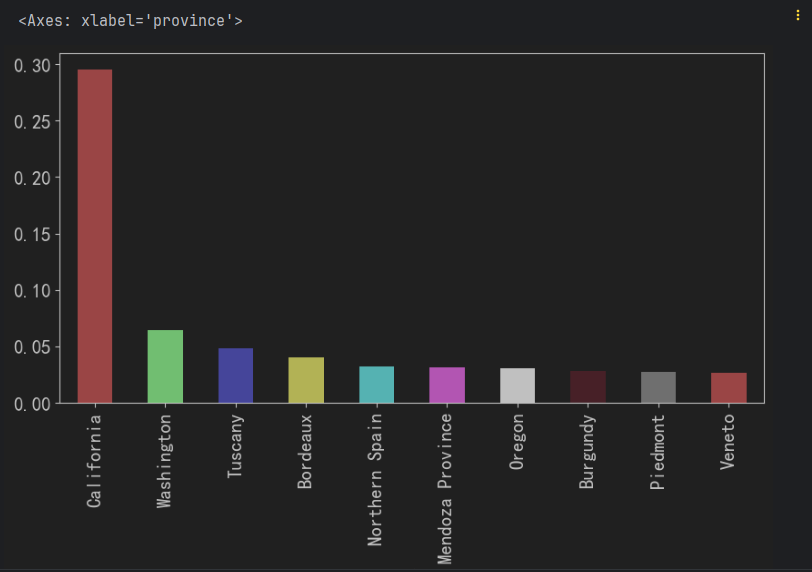
需求3: 展示 每个评分的葡萄酒种类(个数), 即: 80分 -> 多少种酒, 85分 -> 多少种酒, 90分 -> 多少种酒, 95分 -> 多少种酒, 100分 -> 多少种酒
python
# df.points.value_counts().sort_index().plot.line(**text_kwargs) # 折线图
# df.points.value_counts().sort_index().plot.area(**text_kwargs) # 面积图, 就是把区域内进行填充
df.points.value_counts().sort_index().plot.bar(**text_kwargs) # 柱状图, 就是把区域内进行填充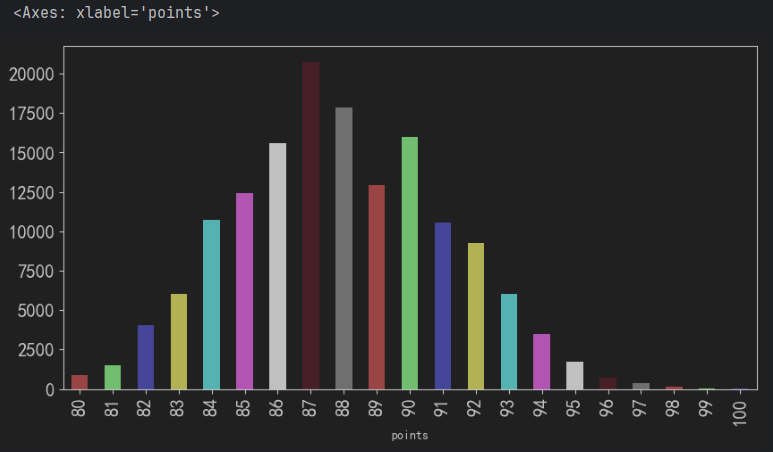
2、Seaborn绘图
# 介绍: Seaborn 是一个 Python 数据可视化库, 它基于 Matplotlib, 并且它提供了更高级的绘图功能. # Pandas中绘图直接写单词, 例如: hist(), Seaborn中绘图是 图形名 + plot(), 例如: histplot()
python
# 1. 加载数据集.
# df = pd.read_csv('./data/tips.csv') # 离线方式.
df = sns.load_dataset('tips') # 在线方式(电脑要联网), tips是Seaborn自带的数据集
df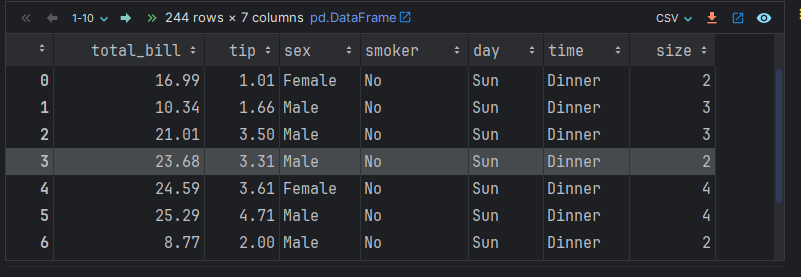
需求1: 绘制图形, 展示 男女总账单的情况
python
# 1. 创建画布
fig, ax = plt.subplots(figsize=(10, 5))
# 2. 绘制图形.
# 参1: data: 数据集
# 参2: x: x轴的列名
# 参3: hue: 分组依据的列名
sns.histplot(data=df, x='total_bill', hue='sex')
# 3. 添加标题.
ax.set_title('男女总账单的情况', fontsize=15)
# 4. 展示图形.
plt.show()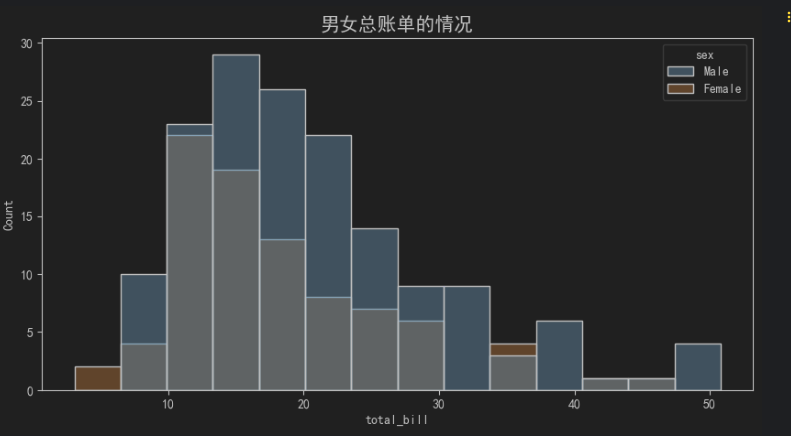
散点图, scatter(), regplot(), jointplot()
python
# 需求: 描述 总账单 和 小费的分布情况
# 1. 创建画布
fig, ax = plt.subplots(figsize=(10, 5))
# 2. 绘制散点图
# 思路1: 散点图, scatter()
# 参1: data: 数据集
# 参2: x: x轴的列名, 总账单
# 参3: y: y轴的列名, 小费
# sns.scatterplot(data=df, x='total_bill', y='tip')
# 思路2: regplot(), 可以绘制散点图, 且可以绘制 拟合回归线(底层是: 线性回归)
# sns.regplot(data=df, x='total_bill', y='tip')
sns.regplot(data=df, x='total_bill', y='tip', fit_reg=True) # 绘制拟合回归线
# sns.regplot(data=df, x='total_bill', y='tip', fit_reg=False) # 不绘制拟合回归线
# 思路3: jointplot(), 可以绘制散点图, 且可以绘制 拟合回归线(底层是: 线性回归)
# sns.jointplot(data=df, x='total_bill', y='tip', kind='hex') # kind=hex -> 蜂巢图
# 3. 添加标题.
ax.set_title('总账单 和 小费的分布情况', fontsize=15)
# 4. 展示图形.
plt.show()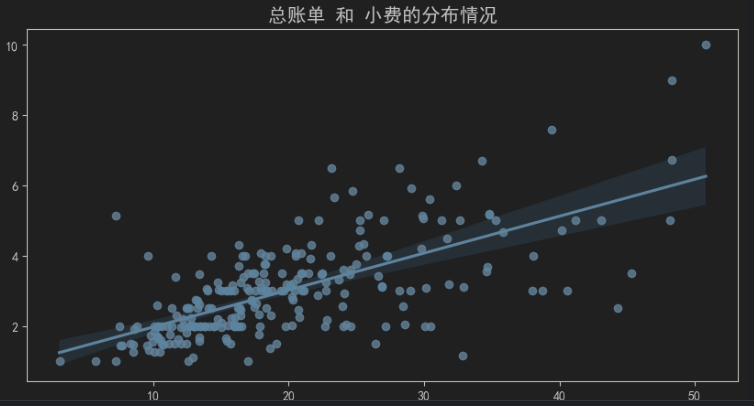
箱线图, boxplot(), violinplot()
python
# 绘制箱线图(也叫: 盒须图), 展示: 时间(time) 和 账单总金额(total_bill) 的分布情况
sns.boxplot(data=df, x='time', y='total_bill')
plt.show()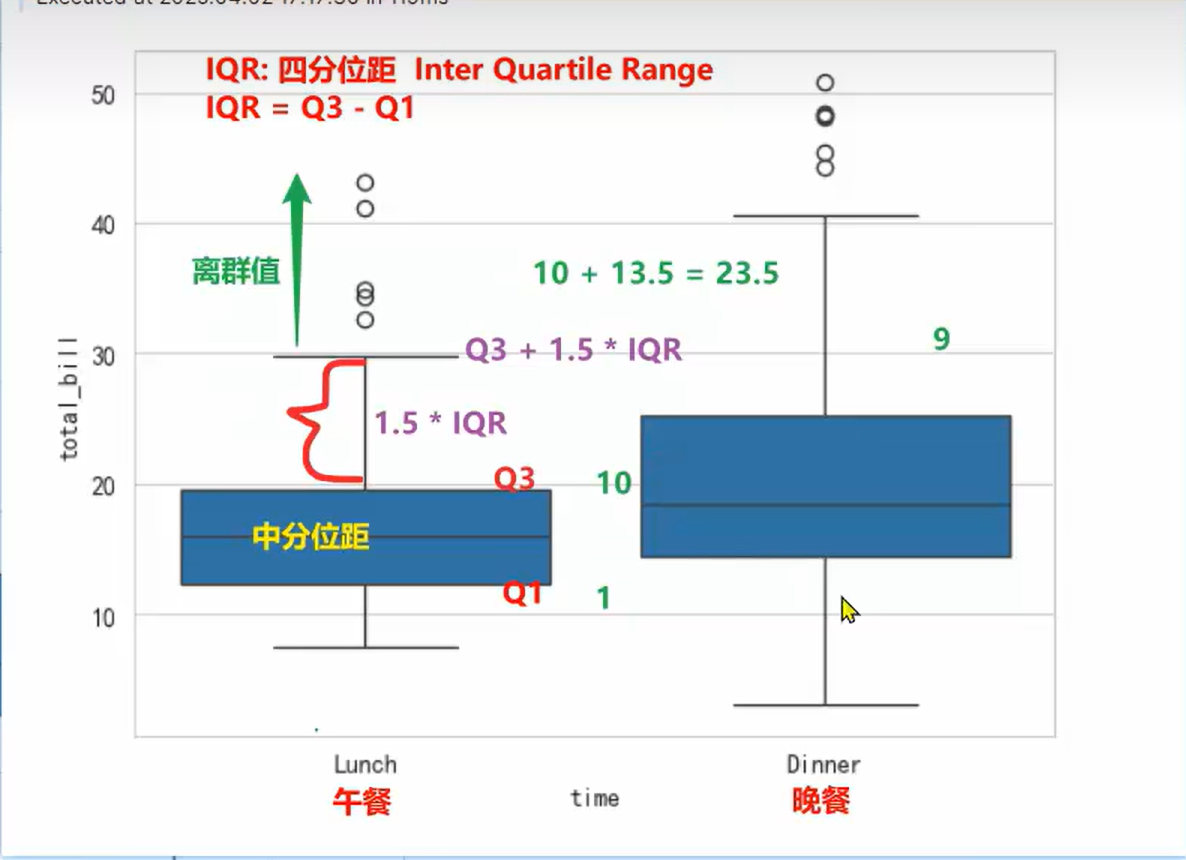
python
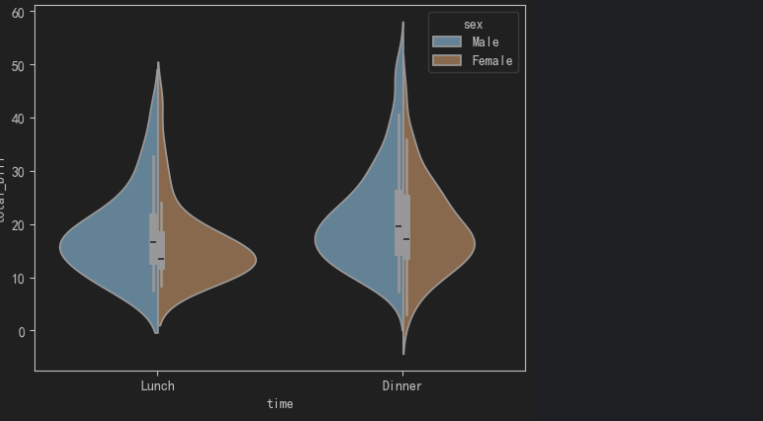
# 需求: 查看 性别(sex) 和 账单总金额(total_bill), 时间(time) 的分布情况
# 小提琴图, 适用于: 箱线图 + 密度图
# 参1: data: 数据集
# 参2: x: x轴的列名, 时间(time)
# 参3: y: y轴的列名, 账单总金额(total_bill)
# 参4: hue: 分组依据的列名, 性别(sex)
# 参5: split: 是否将箱线图进行分割, 默认为False, 即不进行分割
sns.violinplot(data=df, x='time', y='total_bill', hue='sex', split=True)
plt.show()