一、pandas文件读取
python跨平台,Windows,MacOS,Linux都可以运行。功能比Excel,PowerBI tableau等软件强大。Python在非结构化数据(文本,图像)和深度学习领域更有优势。
numpy(Numerical Python)是Python语言的一个扩展程序库。是一个运行速度非常快的数学库,主要用于数组计算。
Pandas 是一个强大的分析结构化数据的工具集。它的使用基础是Numpy(提供高行呢个的矩阵运算)。用于数据挖掘和数据分析,同时也提供数据清洗功能。
Matplotlib是一个功能强大的数据可视化开源Python库。
Seaborn是一个Python数据可视化开源库。建立在Matplotlib之上,并继承了pandas的数据结构。面向数据集的API,与pandas配合使用更方便。
环境准备
anaconda:
cmd 启动 进conda base
conda install 包名字
或者 Anaconda prompt 以管理员身份启动。

conda 命令:
bash
conda install 包名字
conda create -n 虚拟环境名字
conda activate
conda deactivate
conda remove -n
conda list env
conda search pymysqlpip安装:
pip install 包名字
使用pip安装时要指定安装源。
阿里云:https://mirrors.aliyun.com/pypi/simple/
豆瓣:https://pypi.douban.com/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:https://pypi.mirrors.ustc.edu.cn/simple/
bash
pip install pymysql
pip install pymysql == 1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install sqlalchemy
pip install sqlalchemy == 2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
bash
# 版本错误 执行如下:
pip uninstall sqlalchemy
pip install sqlalchemy ==1.4.312.1 pandas操作csv
方法:
read_xxx
to_xxx
pandas.read_csv(文件路径,分隔符默认',',指定读取的列名)
step1.导包,修改相对路径的位置;(引入文件)
python
import pandas as pd
import numpy as np
import os
from spyder_kernels.utils.lazymodules import pandas
os.chdir(r'D:\python_work\python_work\day02') # 修改相对路径
# 解决中文显示问题,
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #如果是Mac本,不支持SimHe的时候,可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = Falsestep2.读取csv文件。
python
# 1. Pandas操作csv 文件;
data = pd.read_csv("./data/LJhouse.csv",sep=',',usecols=['open','hign','close','close']) # 用df
datastep3.写入csv文件。
python
# 2. Pandas操作csv 文件,保存为csv文件 ;把读取到的数据保存为csv文件 写到文件中;
data[:10].to_csv("./data/my_file1.csv",sep=',',index=False) # 不要索引列 index=False
print('写入成功!')step4.读写tsv文件。
python
# 3.特殊csv文件 tsv 文件
# tsv文件以 tab 键为分隔符
data[:5].to_csv("./data/my_file2.tsv",sep='\t',index=True) # 要索引; 右键刷新data
print('写入成功!')
# 4. 读取tsv 文件
df2 = pd.read_csv("./data/my_file2.tsv",sep='\t',index_col=0) # 第一列设置为索引列 index_col=0
df2完整代码:
python
import pandas as pd
import numpy as np
import os
from spyder_kernels.utils.lazymodules import pandas
os.chdir(r'D:\python_work\python_work\day02') # 修改相对路径
# 解决中文显示问题,
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #如果是Mac本,不支持SimHe的时候,可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False
# 1. Pandas操作csv 文件;
data = pd.read_csv("./data/LJhouse.csv",sep=',',usecols=['open','hign','close','close']) # 用df
data
# 2. Pandas操作csv 文件,保存为csv文件 ;把读取到的数据保存为csv文件 写到文件中;
data[:10].to_csv("./data/my_file1.csv",sep=',',index=False) # 不要索引列 index=False
print('写入成功!')
pd.read_csv("./data/test.csv")
# 3.特殊csv文件 tsv 文件
# tsv文件以 tab 键为分隔符
data[:5].to_csv("./data/my_file2.tsv",sep='\t',index=True) # 要索引; 右键刷新data
print('写入成功!')
# 4. 读取tsv 文件
df2 = pd.read_csv("./data/my_file2.tsv",sep='\t',index_col=0) # 第一列设置为索引列 index_col=0
df22.2 Pandas操作mysql
方法:
read_sql
to_sql
前期准备:anaconda需要安装模块:pymysql 和sqlalchemy
管理员运行anaconda prompt , 安装pymysql 和sqlalchemy ;
bash
pip install 模块名
bash
pip install pymysql
bash
pip install pymysql
pip install pymysql == 1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install sqlalchemy
pip install sqlalchemy == 2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/运行版本有问题执行如下:
bash
# 版本错误 执行如下:
pip uninstall sqlalchemy
pip install sqlalchemy ==1.4.31查看mysql表;
sql
show databases;
use test;
show tables;step1.导入包
python
#2.导包
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import os
import pymysql
os.chdir(r'F:\Dev\Python_Code\Python_numpy')
# 1.准备写到mysql数据表的数据
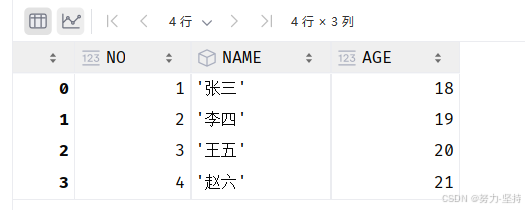
data = pd.read_csv("./data/my_file2.csv",sep=',') # encoding='gbk' ,index_col=0
data运行如下图:
step2. 数据写入Mysql数据库
python
# 3.创建引擎对象
engine = create_engine('mysql+pymysql://root:asdfjkl@localhost:3306/test?charset=utf8')
# 4.具体的写数据的动作
#df2 = pd.read_csv("./data/my_file2.tsv",sep='\t',index_col=0) # 第一列设置为索引列 index_col=0
#df2
# 参数说明:1. 数据表明, 2. 引擎对象, 3. 是否把索引写入数据库, 4. 如果表存在如何处理
data.to_sql('my_table',con=engine,if_exists='append') # index=False,
#5. 提示
print('写入成功!')运行如下图:

step3.查看MySQL数据。
python
# df2.to_sql('my_table',con=engine,if_exists='append',index=False) # if_exists='append'
# 6.查看数据
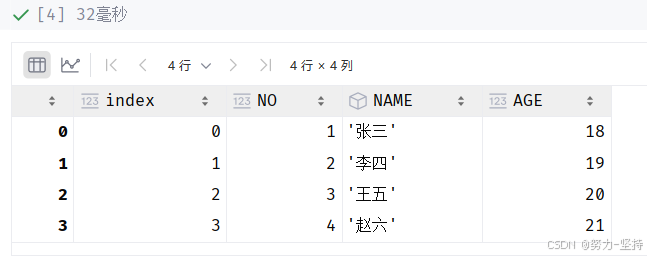
sql_df = pd.read_sql('my_table',con=engine) # select * from my_table limit 0,2
sql_df运行如下图:
2.3 读写json
read_json
to_json
方法:读取pandas.read_json(typ='frame',lines=False)
step1.读取json文件。
bash
#2.导包
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import os
import pymysql
# 解决中文显示问题,
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #如果是Mac本,不支持SimHe的时候,可以修改为 'Microsoft YaHei' 或者 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False
os.chdir(r'F:\Dev\Python_Code\Python_numpy')step2.打印读取到的内容。
bash
# 1.读取json文件。 参数1.文件路径 2.读取的格式 3.是否按行读取;
json_df = pd.read_json('./data/test.json',orient='columns',lines=True)
# 2. 打印读取到的内容
json_dfstep3.写入到json文件。
bash
# 3. 把上述的数据,写到json文件中
json_df.to_json('./data/test1.json',orient='records',lines=True) #
print('写入成功')2.4 读写excel
read_excel
to_excel
二、 Pandas数据分析
Pandas分析房产数据示例步骤:
step1.导入包。
python
# 导包
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\Python_Code\Python_Code\day02')step2.加载数据集。
python
# 1.加载数据集
house_df = pd.read_csv("./data/LJhouse.csv")
house_dfstep3.查看数据集。
python
# 3.查看数据集 ;
# 1.查看数据前5行
house_df.head()
# 2.查看列数据分布
house_df.info()
# 3.查看列统计指标 ctrl +回车 house_df.discribe(include = all)
house_df.discribe() # 默认只统计 数值型数据
# 默认统计所有数据(包括字符串)
# 4.查看数据形状
house_df.shape #(2760,13)step4.分析具体需求。
python
# 具体需求
# 1.找到租金最低,和租金最高的房子
# 思路1 排序
house_df.sort_values(by='小区价格',ascending=True).head(1) #最便宜的
house_df.sort_values(by='小区价格',ascending=False).tail(1) #最贵的 价格一样的考虑不到
# 思路2 最小值 最大值 筛选
house_df[house_df.price==1300] #house_df.price.min()
house_df[house_df.price==house_df.price.max()]
house_df[house_df['小区价格']==house_df['小区价格'].min()]
# 思路3
house_df.nlargest(1,'小区价格') # 最大的n个 ,参数1 最大的一个,参数2 列名 思路1的简化版;
house_df.nsmallest(1,'小区价格') # 最小的那个
#%%
# 2. 找到最近新上的10套房源
house_df.sort_values(by='小区房龄',ascending=False).head(10)
# 不能这么写;
# house_df.nlargest(10,'小区房龄')
#%%
# 3.查看所有更新时间
house_df.更新时间.unique() Python完整代码:
python
# 导包
import pandas as pd
import numpy as np
import os
os.chdir(r'D:\Python_Code\Python_Code\day02')
# F:\Dev\Python_Code\Python_numpy ctrl +shift +c 项目右键复制路径
# os.getcwd() # 相对路径hangge
# shift +回车 切换第二个
#%%
# 1.加载数据集
house_df = pd.read_csv("./data/LJhouse.csv")
house_df
# 2.修改列名为英文---------------------------
house_df['地址']
house_df.columns = ['district ','address' ,'title','house_type ','price ','area ','house_type ','orientation ','floor ','total_floor ','age ','subway ','subway_distance ','subway_line ','subway_name ','subway_direction ','subway_distance ','subway_line ','subway_name ','subway_direction ','subway_distance ','subway_line ','subway_name ','subway_direction ','subway_distance ','subway_line']
# 'district' ,'address' ,'title' ,house_type ,price ,area ,house_type ,orientation ,floor ,total_floor ,age ,subway ,subway_distance ,subway_line ,subway_name ,subway_direction ,subway_distance ,subway_line ,subway_name ,subway_direction ,subway_distance ,subway_line ,subway_name ,subway_direction ,subway_distance ,subway_line
# ['id', '小区名称', '小区地址', '小区类型', '小区价格', '小区面积', '小区房型', '小区朝向', '小区楼层', '小区总楼层', '小区房龄', '小区地铁', '小区地铁距离', '小区地铁线路', '小区地铁名称', '小区地铁方向', '小区地铁距离', '小区地铁线路', '小区地铁名称', '小区地铁方向', '小区地铁距离', '小区地铁线路', '小区地铁名称', '小区地铁方向', '小区地铁距离', '小区地铁线路', '小区地铁名称', '小区地铁方向', '小区地铁']
house_df
#%%
# 3.查看数据集 ;
# 1.查看数据前5行
house_df.head()
# 2.查看列数据分布
house_df.info()
# 3.查看列统计指标 ctrl +回车 house_df.discribe(include = all)
house_df.discribe() # 默认只统计 数值型数据
# 默认统计所有数据(包括字符串)
# 4.查看数据形状
house_df.shape #(2760,13)
#%% md
#%%
# 具体需求
# 1.找到租金最低,和租金最高的房子
# 思路1 排序
house_df.sort_values(by='小区价格',ascending=True).head(1) #最便宜的
house_df.sort_values(by='小区价格',ascending=False).tail(1) #最贵的 价格一样的考虑不到
# 思路2 最小值 最大值 筛选
house_df[house_df.price==1300] #house_df.price.min()
house_df[house_df.price==house_df.price.max()]
house_df[house_df['小区价格']==house_df['小区价格'].min()]
# 思路3
house_df.nlargest(1,'小区价格') # 最大的n个 ,参数1 最大的一个,参数2 列名 思路1的简化版;
house_df.nsmallest(1,'小区价格') # 最小的那个
#%%
# 2. 找到最近新上的10套房源
house_df.sort_values(by='小区房龄',ascending=False).head(10)
# 不能这么写;
# house_df.nlargest(10,'小区房龄')
#%%
# 3.查看所有更新时间
house_df.更新时间.unique()