论文题目:A lightweight convolutional neural network-based feature extractor for visible images(一个轻量级的基于卷积神经网络的可见图像特征提取器)
期刊:Computer Vision and Image Understanding (CVIU)
摘要:特征提取网络(FENs)作为许多计算机视觉任务的第一步,起着至关重要的作用。之前关于FENs的研究采用了更深入、更广泛的网络来获得更高的准确性,但他们的方法是内存效率低下和计算密集型的。在这里,我们提出了一种基于ShuffleNetV2的精确、轻量级的可见图像特征提取器(RoShuNet)。所提供的改进有三个方面。为了在不降低特征提取能力的前提下使ShuffleNetV2更加紧凑,我们提出了一个聚合对偶群卷积模块;为了更好地辅助信道互流过程,我们提出了𝜸weighted洗牌模块;为了进一步降低模型的复杂性和大小,我们引入了瘦身策略。分类实验证明了RoShuNet的最先进(SOTA)性能,与ShuffleNetV2相比,它提高了准确率,降低了模型的复杂性和大小。泛化实验证明,该方法同样适用于语义分割和多目标跟踪场景下的特征提取任务,具有与其他方法相当的准确率,且具有更大的内存和更高的计算效率。我们的方法为轻量化模型的设计提供了一个新的视角。
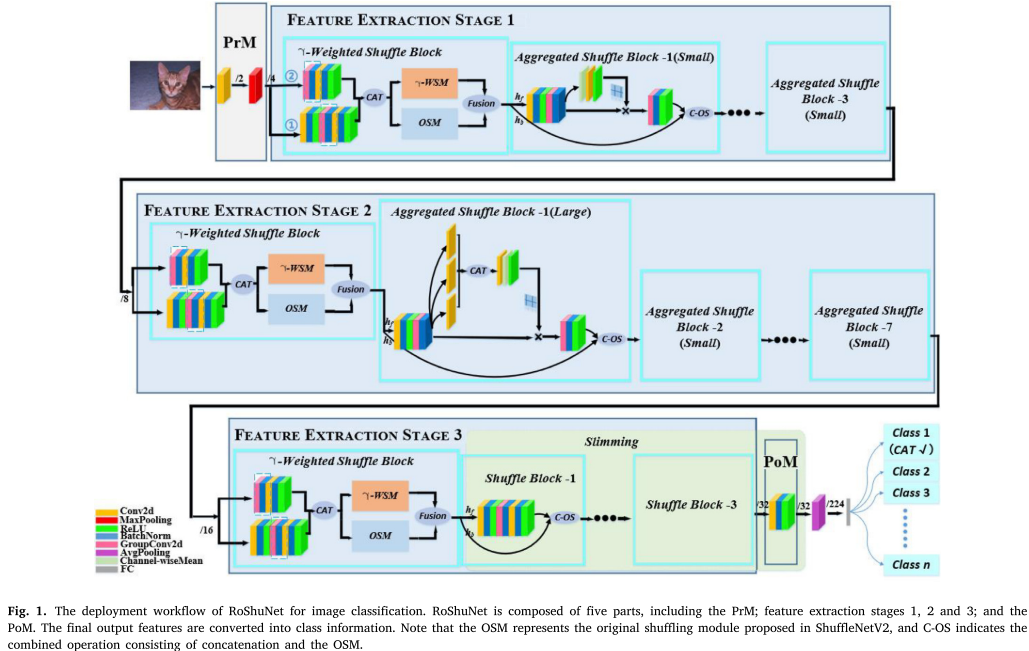
RoShuNet------轻量级CNN的新范式
引言:轻量化网络的困境与突破
在移动端AI应用爆发的今天,如何设计一个既准又小的神经网络成为研究热点。ShuffleNetV2凭借其巧妙的通道混洗机制和组卷积设计,已经成为轻量级网络的标杆。但它真的已经是最优解了吗?
来自哈尔滨工业大学的研究团队在《Computer Vision and Image Understanding》2024年发表的论文给出了否定答案。他们提出的RoShuNet不仅在准确率上全面超越ShuffleNetV2,还进一步压缩了模型体积------这听起来像是在挑战"没有免费午餐"定理,但他们确实做到了。
核心创新点
论文提出了RoShuNet,包含三个主要创新模块:
1. 聚合双组卷积模块(A-DGC)
设计思想:用组卷积替代深度可分离卷积,同时从空间和平面维度提取特征
两个版本:
- A-DGC(s)(小版本):侧重空间维度特征,用于FES-1阶段
- A-DGC(l)(大版本):同时关注空间和平面维度,用于FES-2阶段
技术细节:
- 采用双流设计:主特征提取流(实线箭头)+ 聚合流(虚线箭头)
- 通过通道均值(CMean)聚合跨通道信息
- 使用Hadamard乘积重新缩放通道隔离的特征
效果 :在128通道输入输出时,A-DGC(s)仅需1281个参数,而DSC需要17536个参数(压缩93%)
2. γ加权混洗模块(γ-WSM)
核心思想:基于特征重要性进行智能混洗,而非简单重排
实现机制:
- 使用BatchNorm层的缩放因子γ表示通道重要性
- 按重要性降序排序后进行交叉拼接(cross-piecing)和自拼接(self-piecing)
- 通过映射操作选择最优特征:N次元素级映射 + 行最大化(Rw-Max)
融合策略:
G = η · G_γWSM + (1-η) · G_OSM保留原始混洗模块(OSM),平衡新旧方法(η=0.2)
3. 剪枝策略
针对ShuffleNetV2的块状结构和组卷积特点,提出两个策略:
- 策略1:通道调整:确保组卷积前后通道数相等
- 策略2:块连接:处理块间旁路结构的参数迁移
损失函数:
L = L_c(分类损失) + ϑ_n·||γ||_L1(稀疏正则) + ϑ_c·||W||_L2(权重衰减)核心思想:三个"不满足"
1. 不满足于"假混洗"
问题诊断:ShuffleNet系列引以为傲的channel shuffling,本质上只是把特征图按固定顺序重新排列,就像洗牌时每次都按同一个套路来,根本谈不上"随机"。
解决方案:γ-WSM(γ加权混洗模块)
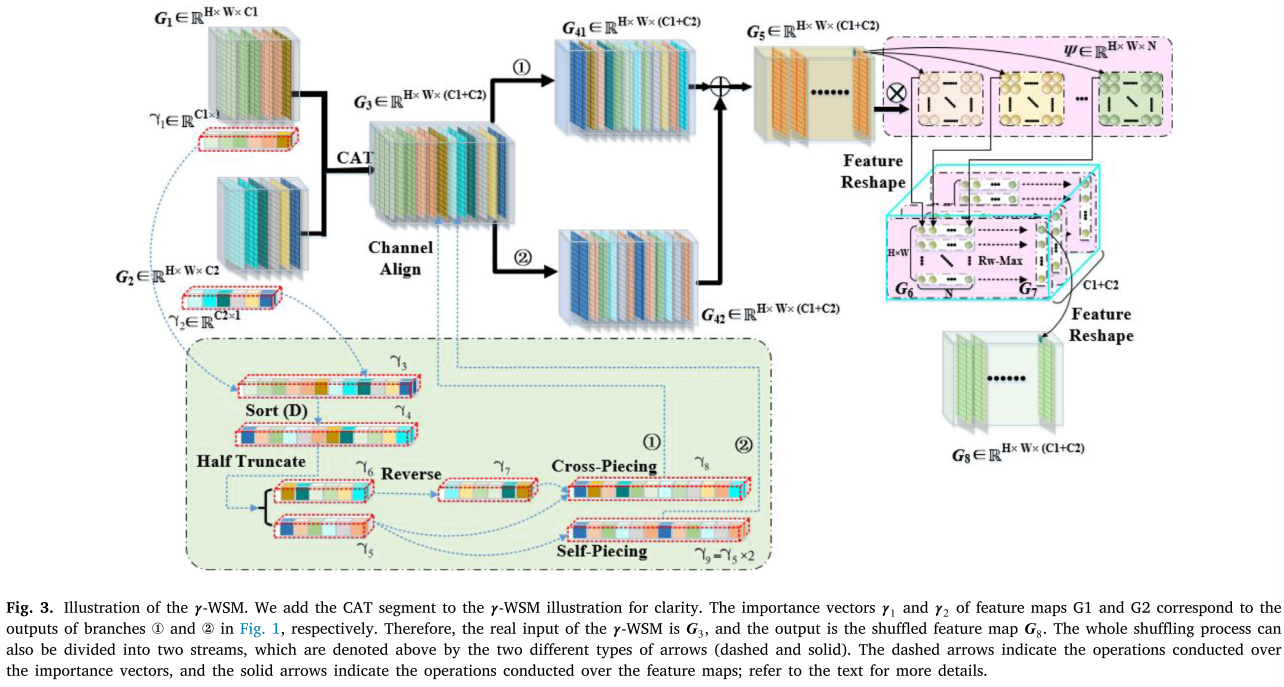
- 给每个通道分配重要性分数γ(从BatchNorm层获取)
- 按重要性降序排序后进行智能拼接
- 重要特征优先进入主分支处理
实验验证:Table 7的消融实验显示,升序排列反而降低准确率(57.54% vs 59.12%),证明"重要的特征应优先利用"这一假设成立。
2. 不满足于深度可分离卷积
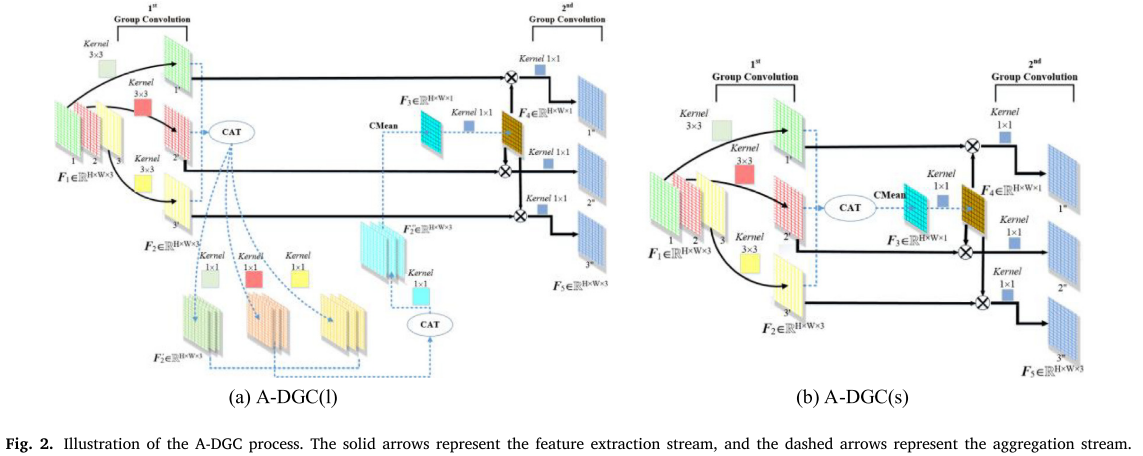
问题诊断:DSC的第二阶段(1×1卷积)仍然是密集连接,在通道数较多时成为内存瓶颈。
解决方案:A-DGC(聚合双组卷积)
- 用双层组卷积替代DSC
- 引入聚合流:通过通道均值操作捕获跨通道依赖
- 大小版本分治:
- A-DGC(s):轻量版,专注空间特征(用于FES-1)
- A-DGC(l):完整版,空间+平面双重提取(用于FES-2)
效果对比:
DSC参数量 = 3×3×128 + 1×128×128 = 17,536
A-DGC(s) = 3×3×128 + 1 + 1×128 = 1,281 ↓92.7%3. 不满足于"一刀切"的剪枝
问题诊断:传统剪枝方法(如Liu et al. 2017)针对VGG这类平铺直叙的结构设计,无法处理:
- 组卷积的通道数约束
- 残差块的旁路连接
解决方案:两步走策略
- 通道调整:确保组卷积前后通道数匹配(否则组操作会失败)
- 块连接:智能计算参数迁移的索引范围,处理跨块依赖
实验亮点:不止于分类
亮点1:多数据集横扫
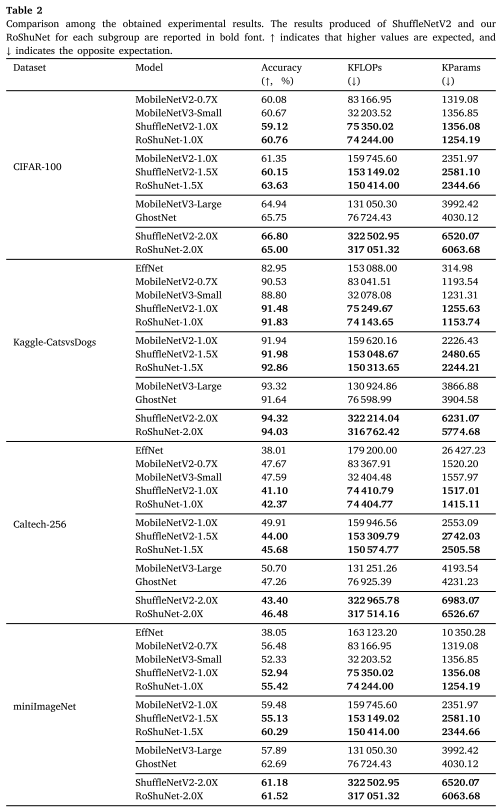
在4个风格迥异的数据集上(小物体低分辨率的CIFAR-100、大物体高分辨率的Caltech-256、二分类的Kaggle猫狗、复杂场景的miniImageNet),RoShuNet-1.0X和1.5X版本全面领先ShuffleNetV2同级别模型。
最惊艳的是miniImageNet:
- ShuffleNetV2-1.5X:55.13%
- RoShuNet-1.5X:60.29%(+5.16%)
- 参数量还减少了9.2%
亮点2:热力图的"眼力见儿"

在Kaggle猫狗数据集的可视化中(Fig. 6),RoShuNet不仅能准确定位目标,还会重点关注识别性强的区域(如动物的脸、四肢),而ShuffleNetV2的注意力分布则显得"心不在焉"。
亮点3:跨任务迁移能力
语义分割:
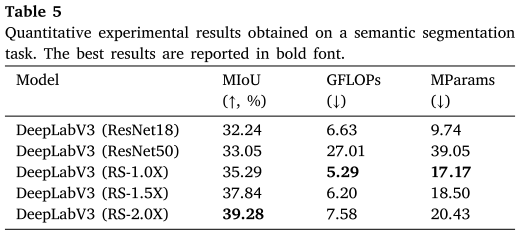
- 用RoShuNet替换DeepLabV3的ResNet50 backbone
- MIoU提升6.23%(33.05%→39.28%)
- 计算量暴降72%(27.01 GFLOPs→7.58 GFLOPs)
多目标跟踪:
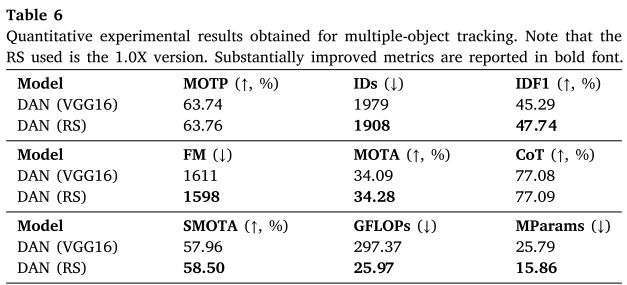
- 在DAN中替换VGG16
- 综合指标SMOTA达58.50%(+0.54%)
- 参数量仅为VGG16的61.5%
技术细节:魔鬼藏在公式里
γ-WSM的数学本质
-
重要性建模:
BN(z) = γ · ẑ + ρ当数据归一化后,γ越大意味着该通道对分类越关键
-
分段拼接:
- 降序排序后对半截断:γ₅(前半)和γ₆(后半)
- 交叉拼接:γ₅\[0, γ₇0, γ₅1, γ₇1, ...]
- 自拼接:γ₅\[0, γ₅0, γ₅1, γ₅1, ...](重要特征复用)
-
特征选择:
G₆ = F(G₅, Ψ) // N次映射 y = Rw-Max(G₆) // 每行取最大值
A-DGC的双流设计
主流(实线):
F₁ → GroupConv3×3 → F₂ → Blend(F₂, F₄) → GroupConv1×1 → F₅聚合流(虚线):
F₂ → Concat → Conv1×1×3 → Concat → Conv1×1 → CMean → Conv1×1 → F₄关键在于Hadamard乘积实现的Blend操作:
F₂''' = F₂ ⊙ F₄ # 逐元素相乘,实现特征重标定实战建议:如何用好RoShuNet
1. 版本选择指南
| 场景 | 推荐版本 | 理由 |
|---|---|---|
| 边缘设备(如树莓派) | RoShuNet-1.0X | 参数量<1.3M,精度已超ShuffleNetV2 |
| 移动端APP | RoShuNet-1.5X | 平衡点:准确率提升明显,仍可实时 |
| 云端服务 | RoShuNet-2.0X | 追求极致准确率 |
| 极致压缩需求 | 剪枝版(b) | 参数量降至998K,准确率仍可接受 |
2. 超参数设置经验
# 训练配置(基于论文Table 1)
optimizer = SGD(lr=0.01, weight_decay=5e-4)
batch_size = 128
input_size = 160 # 分辨率实验显示224后收益递减
# γ-WSM融合系数
eta = 0.2 # 过大会削弱原始混洗的作用
# 剪枝配置
sparsity_weight = 1e-4 # ϑ_n
threshold_a = 0.1059 # 轻度剪枝
threshold_b = 0.1371 # 激进剪枝3. 迁移学习技巧
作为Backbone时的修改:
# 移除PoM后的部分(Table 1中的A层和FC层)
backbone = RoShuNet(
stages=[FES1, FES2, FES3], # 保留三个特征提取阶段
output_stride=32 # 最终下采样倍数
)
# 接入下游任务头
if task == 'segmentation':
model = DeepLabV3(backbone, num_classes=21)
elif task == 'tracking':
model = DAN(backbone, feature_dims=[116, 232, 232])思考:轻量化网络的未来
RoShuNet的成功揭示了三个设计范式:
- 特征重要性感知:不是所有通道生而平等,重要的特征值得更多关注
- 模块化分治:大小版本A-DGC分别处理不同阶段,比one-size-fits-all更高效
- 结构化剪枝:针对特定架构(如组卷积、残差块)设计专用策略
论文的局限也值得关注:
- γ-WSM增加了额外的排序、拼接操作,可能影响推理速度(虽然FPS仍很高)
- 在类别极多的数据集(如ImageNet-1K)上的表现未知
- 未与Transformer-based轻量化方法(如MobileViT)对比
未来方向:作者提到将借鉴RepVGG的结构重参数化思想,在训练时保留复杂结构,推理时转换为简单卷积------这可能进一步加速RoShuNet。
结语 :RoShuNet用"加权混洗"和"双组卷积"两记组合拳,证明了轻量化网络仍有巨大优化空间。更重要的是,它提供了一套可复用的设计哲学------让重要的特征得到更多关注,让不重要的参数优雅退场。这或许才是论文最大的价值。