你是否经历过这样的"灵异事件":
业务监控显示,你的日志服务每秒只写入了 50MB 的数据,全天累计写入 1TB。
但在云厂商的账单,或者内网交换机的监控上,流量却高达 100MB/s,全天消耗了 2TB 的带宽。
网卡经常莫名其妙被打满,造成正常的业务请求卡顿、丢包。
排查了一圈:
-
不是 TCP 重传(Retransmission 正常)。
-
不是 SSL 握手膨胀(HTTPS 开销没那么大)。
-
也不是监控系统算错了(交换机端口统计实打实的跑满了)。
最后抓包一看,差点气晕过去:
你的客户端,为了把这 1TB 的数据发给服务端,实际上在网线上跑了 2TB 的量。
因为它每发一次数据之前,都要先"假装"发一次被拒,然后再"真"发一次。
今天,我们就来揭秘这吃光你带宽的"隐形复读机"------非抢先认证(Non-Preemptive Auth),并教你如何用更优雅的方式帮公司省下一半的流量费。
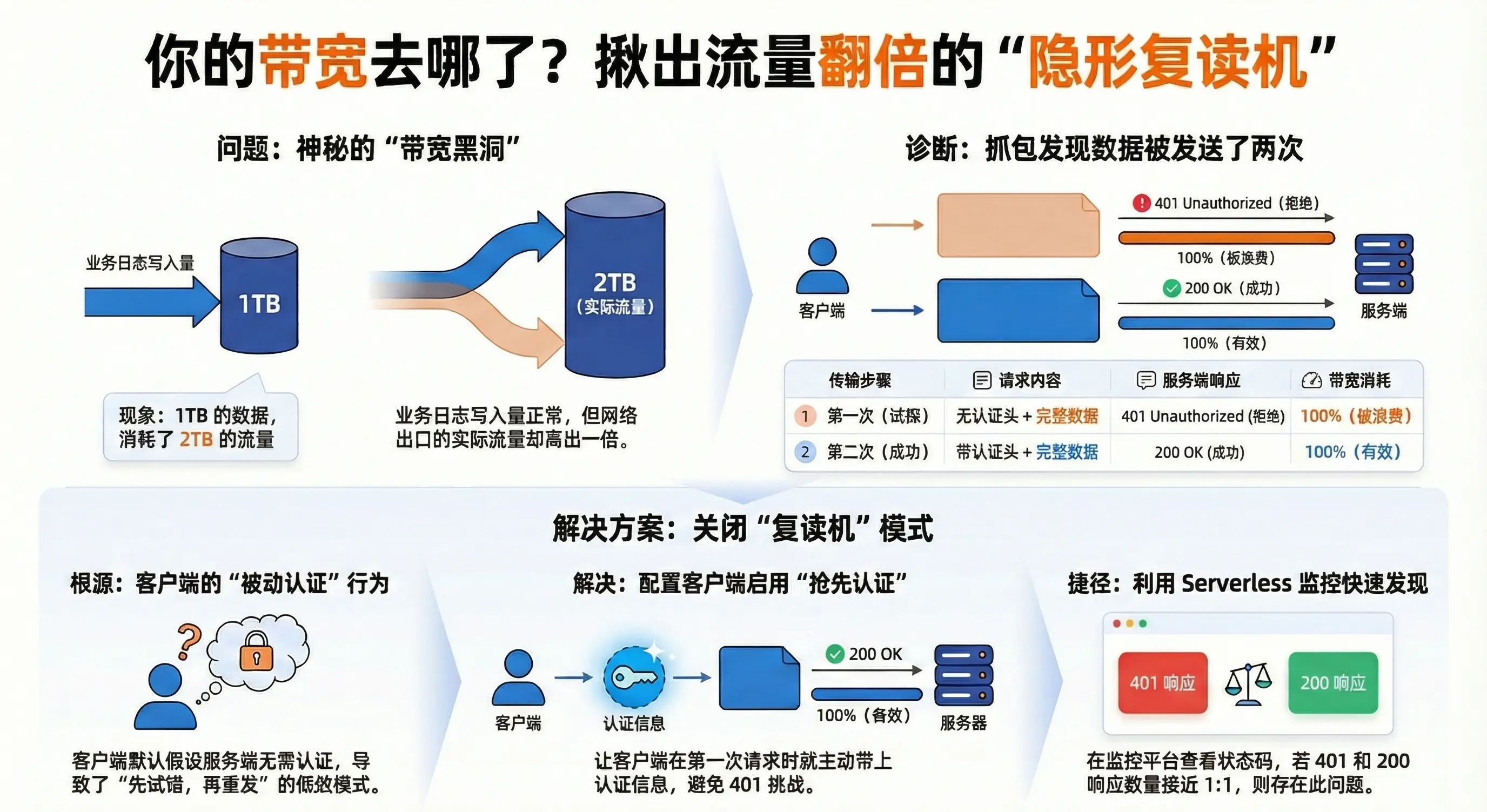
一、案发现场:带宽莫名其妙"爆"了
故事发生在一个大数据量的日志写入场景。
-
业务侧 :开发拍着胸脯说:"我算过了,每条日志 1KB,每秒 5万条,流量绝对只有 50MB/s,千兆网卡绰绰有余。"
-
网络侧 :运维看着监控大屏一脸懵逼:"大哥,网卡出口流量已经顶到 100MB/s 了,带宽利用率 100%,开始丢包了!"
这凭空多出来的 50MB/s 是哪来的?
最离谱的是,客户端日志一切正常, ES 集群也一切正常,写入成功率 100%,仿佛只是默默地吞下了这双倍的流量。
二、传统排查:终端里的一眼定乾坤
在自建环境中,要查清楚带宽去哪了,不需要复杂的分析工具,用 tcpdump 看一眼报文实体就真相大白了。
祭出 tcpdump(抓"实锤")
怀疑是重传?直接在生产环境抓取端口流量,并用 -A 参数打印包的内容:
shell
# -A: 以 ASCII 打印包内容,能看到 HTTP Body
# -s 0: 抓取完整包,防止截断 Body
tcpdump -i eth0 port 9200 -A -s 0 -c 100 -w bandwidth_leak.pcap当你打开抓包文件,你会看到令人崩溃的一幕:
每一个 POST 请求的 Body(业务数据),在网络上传输了两次!
-
第一次传输(无效):
-
Header:
POST /_bulk(无 Auth 头) -
Body:
{"index":{...}} ...(5MB 的真实数据被发出去了!) -
Response:
401 Unauthorized(ES 拒收,但这 5MB 流量已经占用了带宽)
-
-
第二次传输(有效):
-
Header:
POST /_bulk(带 Auth 头) -
Body:
{"index":{...}} ...(同样的 5MB 数据,又完整发了一遍) -
Response:
200 OK
-
结论: 你的客户端不仅是在"虚晃一枪",它是"全量试探 "------每次被拒之前,都先把沉甸甸的数据包完整地发一遍。带宽就是这么翻倍的。
无法抓包?应用层也有"呈堂证供"
如果你没有服务器的 root 权限无法运行 tcpdump,或者想从应用层进一步确认,日志也能提供确凿的证据。
-
搜查客户端日志 :将客户端(如 Apache HttpClient)的日志级别调至 DEBUG。你会发现日志里充斥着
Authentication required------ 每一条成功的请求背后,都紧跟在一次失败的尝试之后。 -
调阅服务端审计(高危) :临时开启 ES 的 Audit Log(警告:全量审计极其消耗性能,生产环境慎开)。你会看到同一个请求总是成对出现:先是
access_denied,紧接着才是access_granted。
三、深度解析:为什么客户端这么"傻"?
为什么客户端不能先问问需不需要密码,非要先把数据扔过去被拒一次?
1. 默认行为的代价(RFC 的锅)
老版本的 Java 客户端(Apache HttpClient 4.x 内核)和部分 Python 客户端,默认遵循 RFC 2617 的**"被动认证"**流程:
它假设服务器可能不需要密码。为了"兼容性",它直接把请求(包含 Header 和 Body)发过去。
-
Round 1 : 客户端发送 Header + Body (1GB)。
-
Round 2 : 服务端收到,发现没权限。丢弃收到的 1GB Body ,返回
401,并在 Header 里喊话:"我要密码!"。 -
Round 3 : 客户端收到 401,发现需要密码。于是带上密码,重新发送 Header + Body (1GB)。
-
Round 4: 服务端校验通过,接收数据。
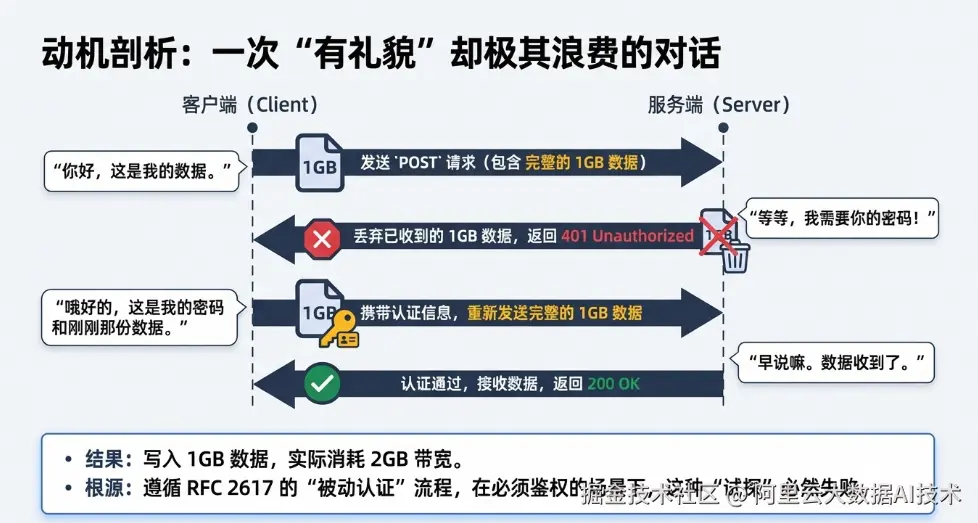
2. "带宽黑洞"的形成
在内网 ES 这种必须鉴权的场景下,运气永远是不好的。
于是,逻辑变成了:
-
你要写 1GB 数据?
-
系统实际传输:先发 1GB (被拒) + 再发 1GB (成功) = 消耗 2GB 带宽。
这不仅打爆了网卡,还浪费了 ES 的 HTTP 解析线程和 SSL 解密开销(如果是 HTTPS)。
四、解决方案:更优雅的"抢答模式"
解决思路非常简单:不要试探,第一次请求就直接把"身份证"亮出来。
1. Java 客户端
场景 A:ES 8.x 新版 Java Client (官方推荐)
如果你使用的是最新的 co.elastic.clients,虽然上层 API 变了,但底层依然依赖 RestClient。你需要确保在底层的 RestClientBuilder 中正确配置凭据。
java
// 1. 准备凭据提供者
final CredentialsProvider credentialsProvider =
new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("user", "password"));
// 2. 配置底层 RestClient
RestClient restClient = RestClient.builder(
new HttpHost("es-host", 9200))
.setHttpClientConfigCallback(httpClientBuilder ->
// 关键点:注入默认凭据提供者
// 这会激活 HttpClient 内部的 AuthCache,实现抢占式认证
httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider)
).build();
// 3. 构建 ES8 Client
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);场景 B:老版本 RestHighLevelClient (维护模式)
很多老系统还在用这个。务必检查是否禁用了缓存,或者忘记配置 CredentialsProvider。
java
// 方式一(优雅):配置 CredentialsProvider(同上)
// 方式二(硬核):直接焊死 Header,绝对不给 401 任何机会
Header[ ] defaultHeaders = new Header[ ]{
new BasicHeader("Authorization",
"Basic " + Base64.getEncoder().encodeToString("u:p".getBytes()))
};
RestClientBuilder builder = RestClient
.builder(new HttpHost("es-host", 9200))
.setDefaultHeaders(defaultHeaders); 2. Python 客户端
场景 A:Python Client v8 (官方推荐)
在 v8 版本中,官方废弃了 http_auth,改用 basic_auth。使用标准写法时,默认就是抢占式的,无需额外操心。
python
from elasticsearch import Elasticsearch
# ✅ 官方推荐写法:使用 basic_auth
# 底层逻辑已优化,默认开启 Preemptive Auth,不会浪费带宽
client = Elasticsearch(
"http://es-host:9200",
basic_auth=("user", "password")
)场景 B:手动注入 Header (全版本通用)
如果你还在用老版本,或者不确定 SDK 内部行为,手动注入 Header 是最稳妥的。
python
import base64
import requests
# 构造 Header
token = base64.b64encode(b"user:password").decode("ascii")
headers = { 'Authorization': f'Basic {token}' }
# 第一包数据就会带上 Auth,绝无浪费
r = requests.post(url, data=big_payload, headers=headers)💡 Pro Tips:鉴权最佳实践
解决"401 试探"最彻底的方法是使用 API Key(它不受 Basic Auth 协议的"试探"逻辑束缚,天生就是抢占式的),但需要注意:
-
PaaS / 自建用户 :强烈推荐使用 API Key 取代传统的账号密码。不仅性能更好,权限控制也更精细,安全性更高。
-
Serverless 用户 :目前 ES Serverless 暂不支持 API Key。请使用上述的 Basic Auth 抢占式配置方案 (如
basic_auth或CredentialsProvider),同样可以完美解决带宽翻倍问题。
五、Serverless 价值:从"黑盒抓瞎"到"上帝视角"
看到这里,你可能会问:"原理我懂了,但我怎么知道我的系统里有没有藏着这个流量黑洞?总不能天天去生产环境抓包吧?"
这正是自建 ES 集群的痛点:你只看得到带宽爆了,却不知道是哪部分流量在搞鬼。
而在 阿里云 ES Serverless 中,这显而易见。
1. 状态码大盘:一眼定真伪
Serverless 提供了基于网关层的全链路监控。你只需要点开控制台的"端到端请求指标"监控:
如果你看到 401 的曲线 和 200 的曲线 高度重合(甚至数量 1:1),如下图所示:
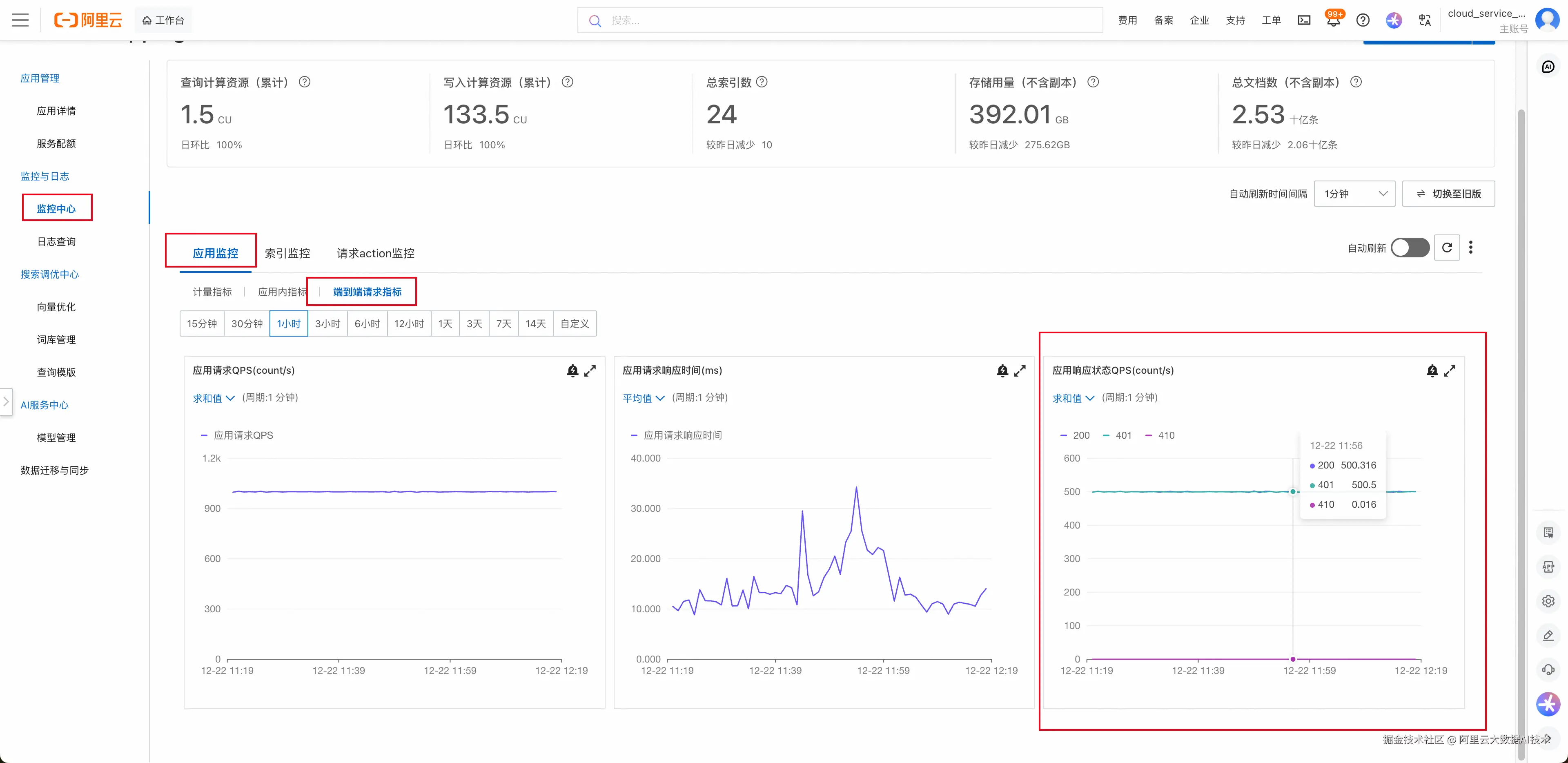
这就意味着:你每一字节的有效数据,都伴随着一字节的无效带宽消耗。
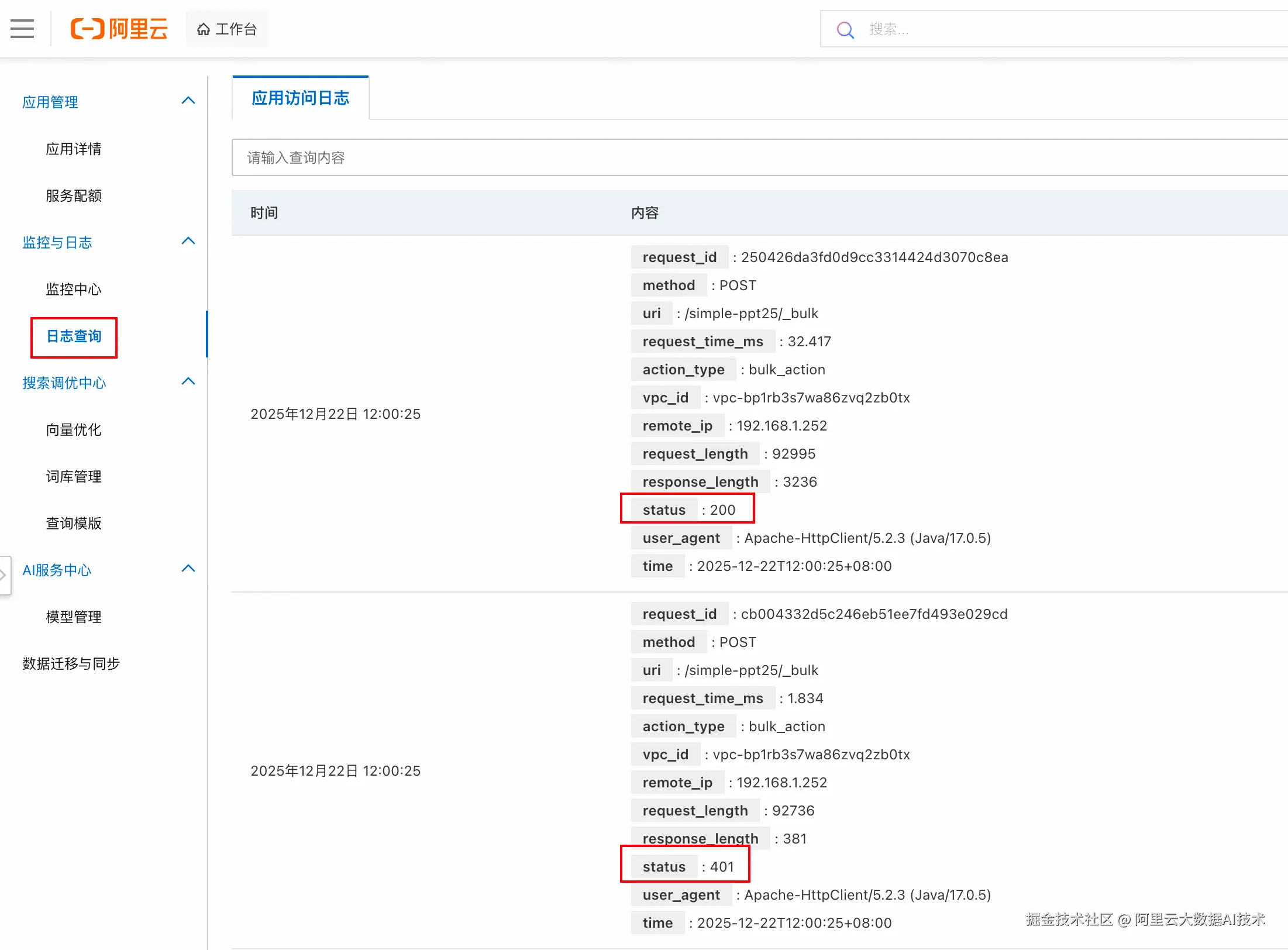
2. 全量 Access Log:精准定责
如果监控曲线异常,下一步就是找"谁干的"。 Serverless 的"**日志查询"**中可以直接查看每个请求的 user_agent 或 remote_ip。 瞬间就能找到是哪个开发团队干的,随后你就可以把截图甩给负责该业务的开发团队:"看,这 50% 的废流量都是你们服务发出来的。"
结语

只有看得见,才能省下来。
带宽就是金钱,但看不见的浪费,才是最大的成本。别让你的预算消耗在毫无意义的"被动试探"上。
快去检查一下你的监控大盘:
-
流量是不是比业务量大一倍?
-
401 占比是不是 50%?
也许只需改一行配置,你的集群带宽压力就能瞬间减半,流量费立省 50%。
立即体验阿里云 ES Serverless,用端到端监控,让流量黑洞无处遁形!