聚簇索引
索引就是数据,数据就是索引
特点:
- 页内的数据使用单向链表进行连接,页和页之间通过双向链表进行连接。
- B+树的叶子节点存储的是完整的数据记录,也就是说记录中存储了所有的键值。
此种类型的索引并不需要我们手动创建,InnoDB存储引擎会自动帮助我们去创建
- 一般情况下,每个MySQL表只会有一个聚簇索引,通常选择主键列进行索引的构建。
- 若没有主键,InnoDB会选择非空的唯一索引进行替代,如果没有这样的索引,存储引擎会隐式定义一个主键来作为聚簇索引。
优点:
- 数据访问快
- 节省了大量的数据IO操作
缺点:
- 插入速度严重依赖于插入顺序
- 更新主键的代价很高
为了充分利用聚簇索引的特性,InnoDB表的主键通常选择有序的顺序ID来作为主键,不推荐用无序的ID,如:UUID、MD5等
非聚簇索引
在其他字段上建立的索引称之为非聚簇索引,或者二级索引。
页内数据不是完整的数据记录,而是创建索引时所指定的列,以及这条记录的主键值。
页内数据按照指定列的数据进行升序排列。
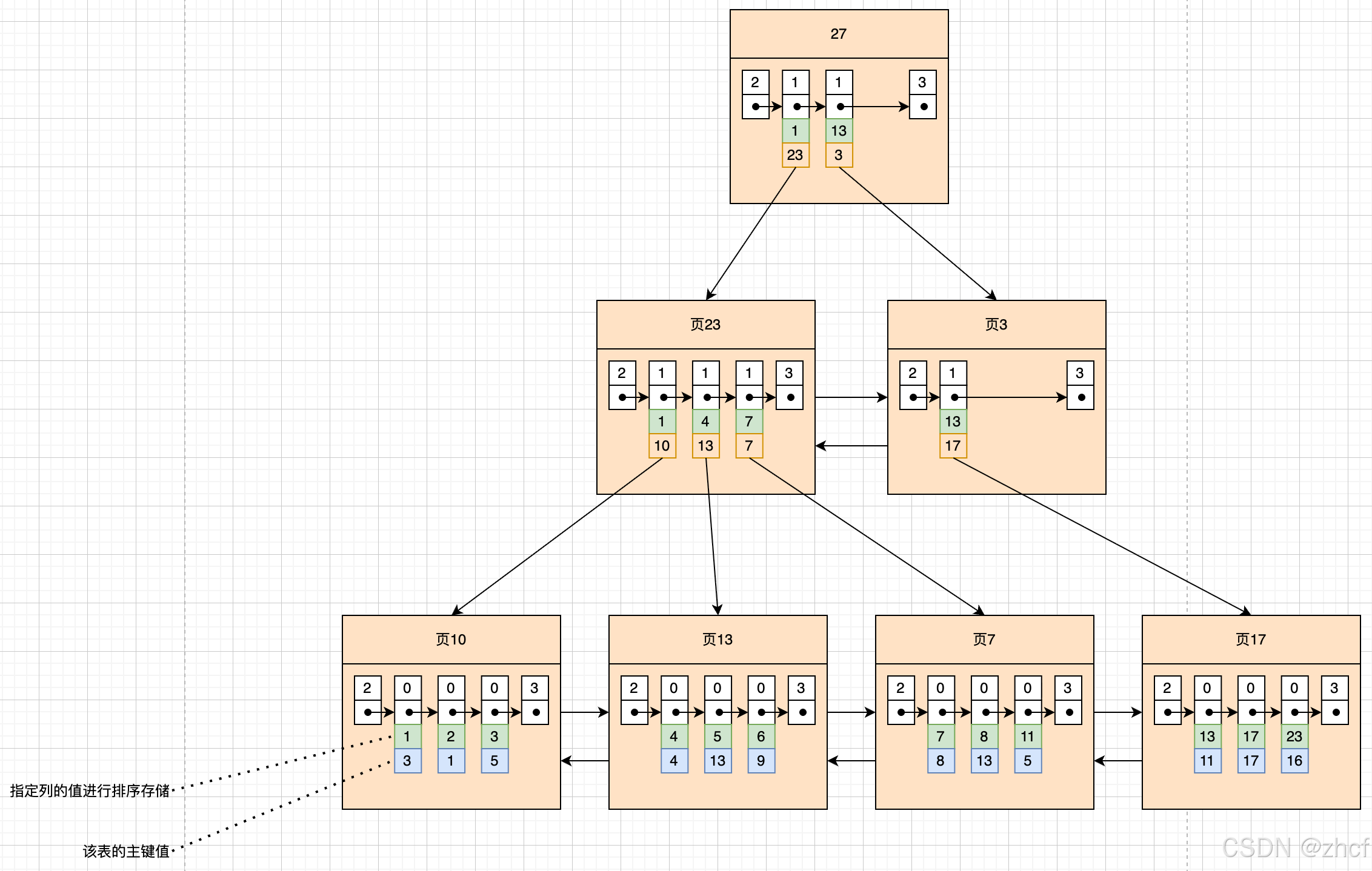
此时如果执行 select * 语句,首先通过非聚簇索引找到这个字段值对应的主键值,然后再回到上述聚簇索引中在进行一次查找,此过程称之为回表。