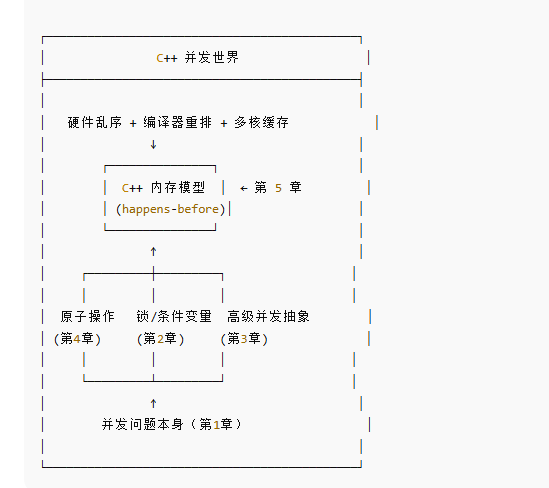
本书的章节安排

C++中的位域


5.1 C++中的原子操作及其类型
5.2.1 标准原子类型
is_lock_free() ,准许使用者判定某一给定类型上的操作是能由原子指令(atomic instruction)直接实现(x.is_lock_free()返回true),还是要借助编译器和程序库的内部锁来实现(x.is_lock_free()返回false)。这一功能可在许多情形中派上大用场,原子操作的关键用途是取代需要互斥的同步方式。但是,假如原子操作本身也在内部使用了互斥,就很可能无法达到所期望的性能提升,而更好的做法是采用基于互斥的方式,该方式更加直观且不易出错。无锁数据结构正属于这种情况,我们将在第7章讨论。


- 原子类型的新旧别名不要混用

原子类型的第二个参数取值:
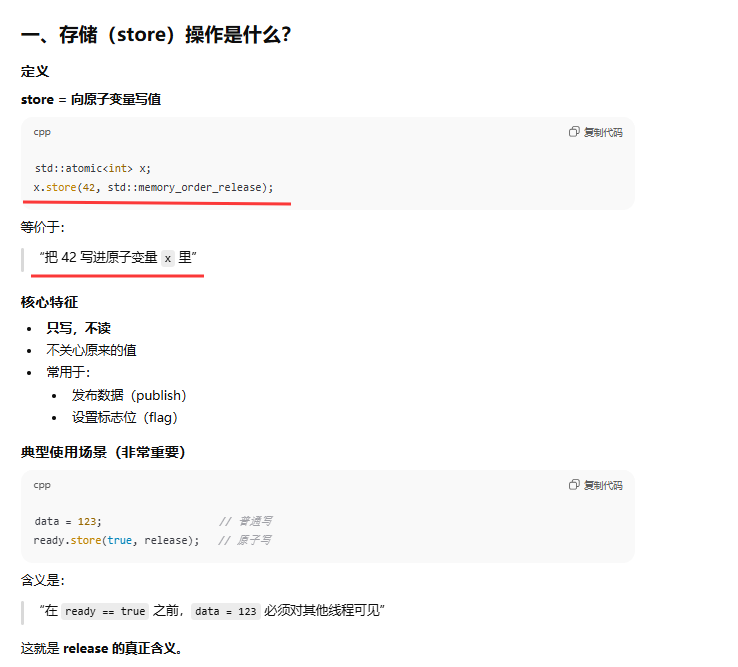
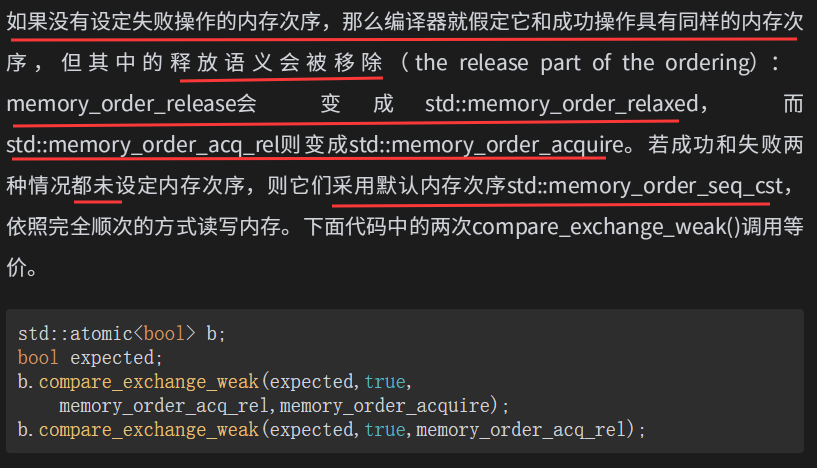
存储(store)操作 ,可选用的内存次序有std::memory_order_relaxed、std::memory_order_release或std::memory_order_seq_cst。
载入(load)操作 ,可选用的内存次序有std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire或std::memory_order_seq_cst。
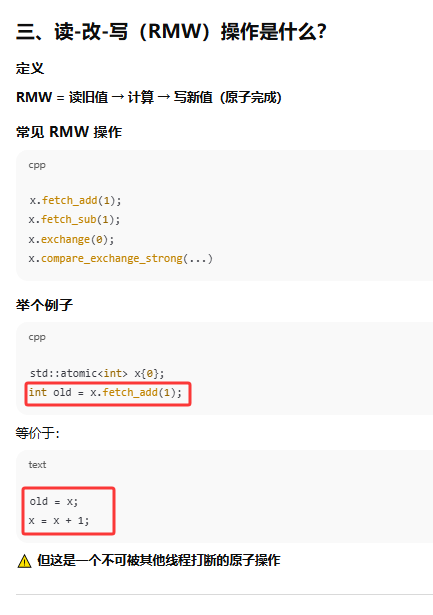
读-改-写"(read-modify-write)操作,可选用的内存次序有std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire、std::memory_order_release、std::memory_order_acq_rel或std::memory_order_seq_cst。

5.2.2 操作std::atomic_flag
std::atomic_flag类型的对象必须由宏ATOMIC_FLAG_INIT初始化。也是唯一保证无锁的原子类型
-
原子操作为什么禁止拷贝构造和拷贝赋值?
原子类型上的操作全都是原子化的,但拷贝赋值和拷贝构造都涉及两个对象,而牵涉两个不同对象的单一操作却无法原子化。在拷贝构造或拷贝赋值的过程中,必须先从来源对象读取值,再将其写出到目标对象。这是在两个独立对象上的两个独立操作,其组合不可能是原子化的。
-
使用std::atomic_flag()实现无锁
cpp
#include <iostream>
#include <list>
#include <algorithm>
#include <thread>
#include <future>
class SpinLockMutex
{
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
SpinLockMutex() : flag(ATOMIC_FLAG_INIT) {}
void lock()
{
while (flag.test_and_set(std::memory_order_acquire))
;
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};5.2.3 操作std::atomic
奇怪的赋值操作
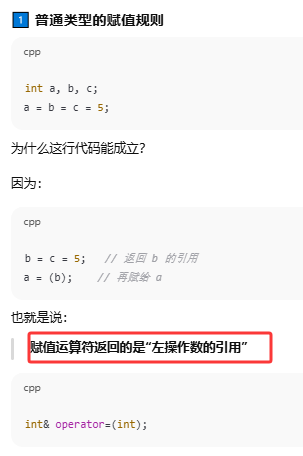
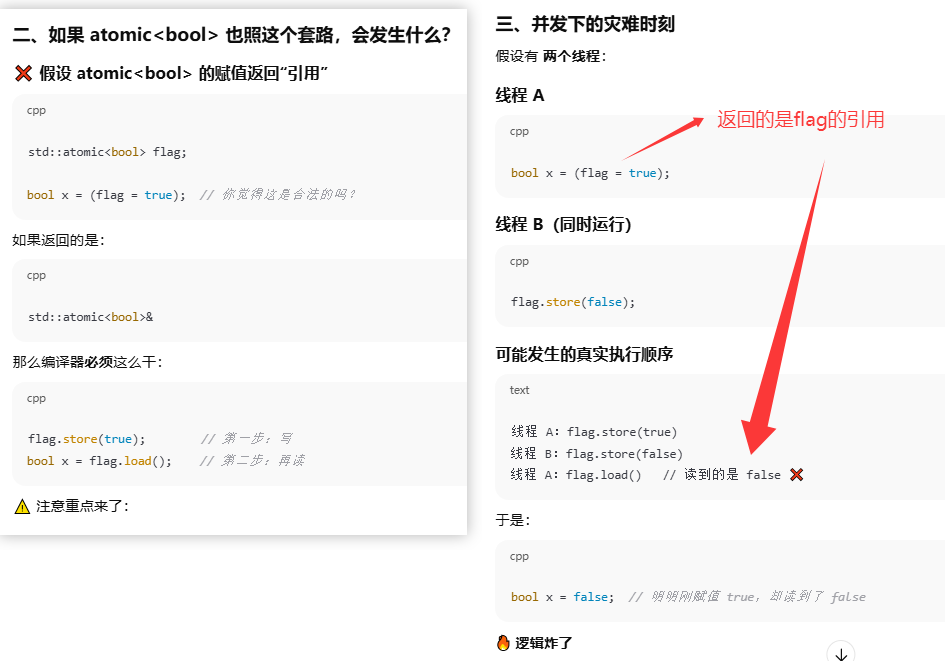

atomic 的赋值运算符不返回引用,是为了防止你"刚赋完值,却被别人抢先改了,然后你又把改后的值当结果用"
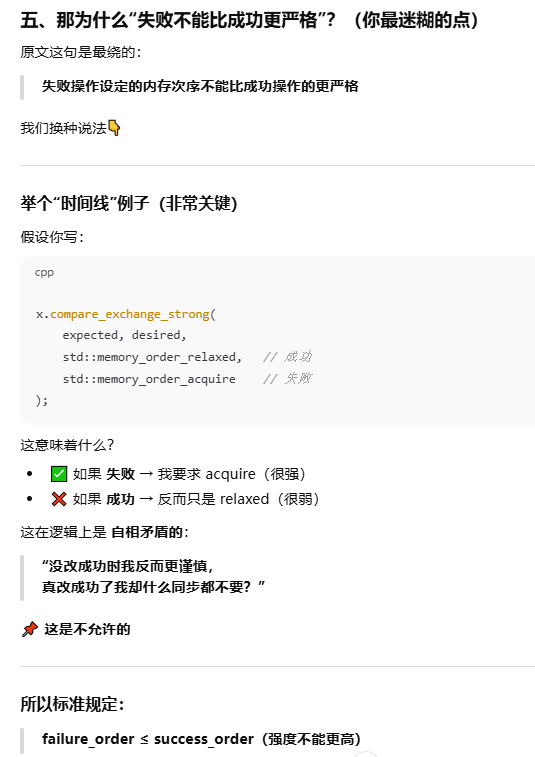
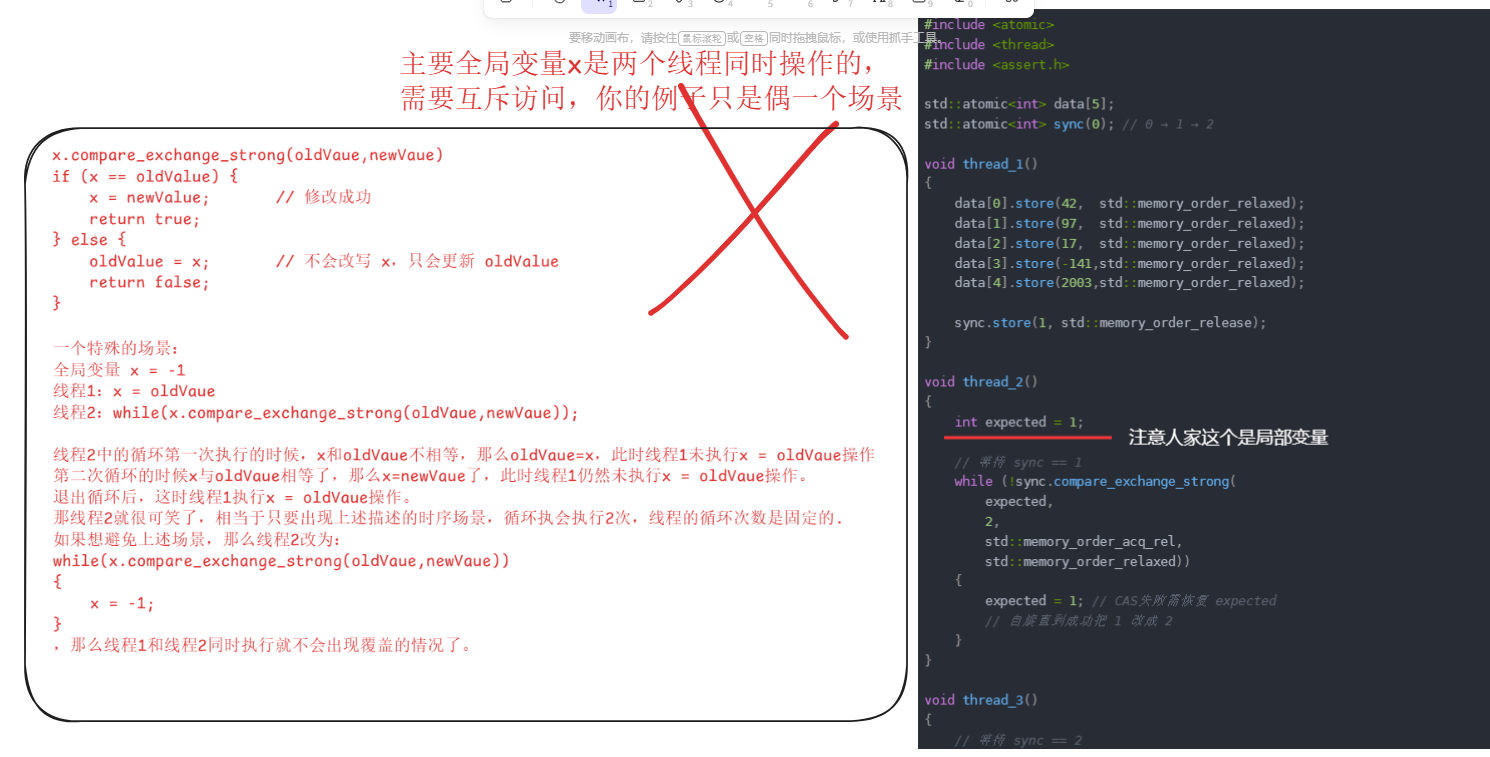
"比较-交换"(compare-exchange)
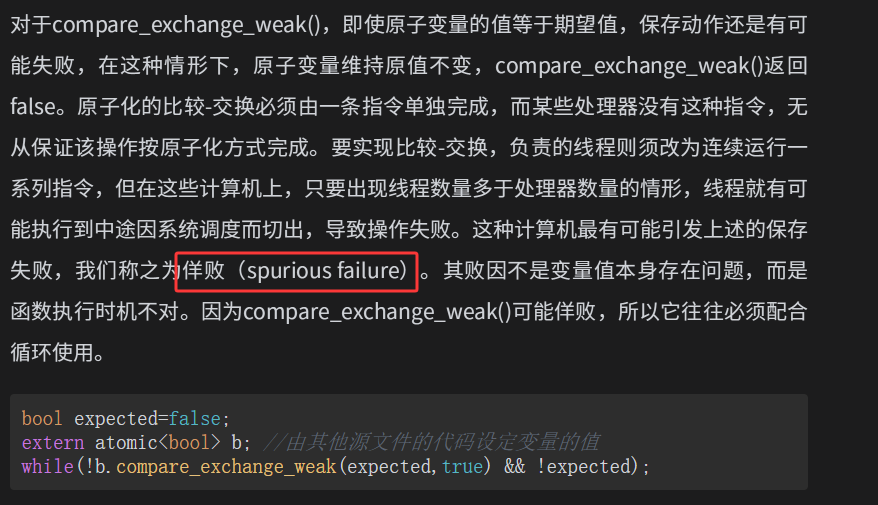

compare_exchange_weak(),返回false有有两种情况,一种是正常现象即和预期值不相等,第二种是原子化的比较-交换必须由一条指令单独完成,而某些处理器没有这种指令,无从保证该操作按原子化方式完成。要实现比较-交换,负责的线程则须改为连续运行一系列指令,但在这些计算机上,只要出现线程数量多于处理器数量的情形,线程就有可能执行到中途因系统调度而切出,导致操作失败,从而返回false,所以为了避免第二🀄情况的出现,我们一般使用对于compare_exchange_weak()使用while
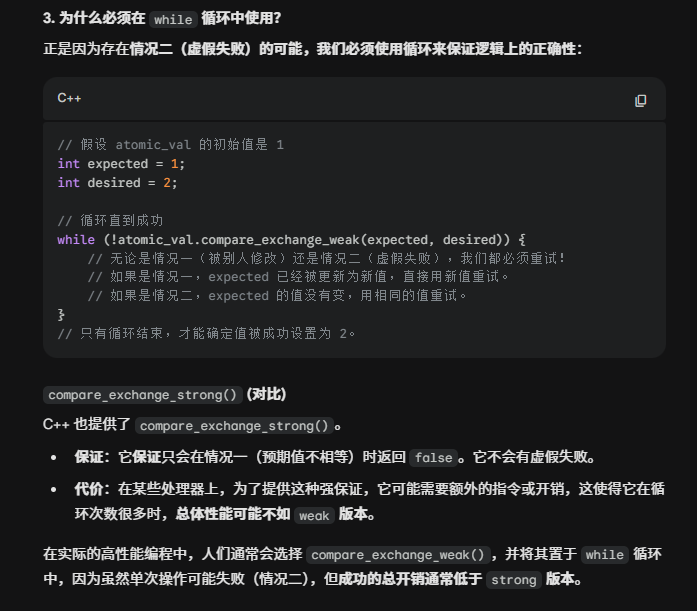
cpp
// 假设 atomic_val 的初始值是 1
int expected = 2;
int desired = 3;
// 循环直到成功
while (!atomic_val.compare_exchange_weak(expected, desired))
{
// 第一次循环:atomic_val=1, expected=2 -> 失败,expected被更新为1,此时expected=1,返回false
// 第二次循环:atomic_val=1, expected=1 -> 成功,atomic_val被更新为3,返回true
}
成功或失败

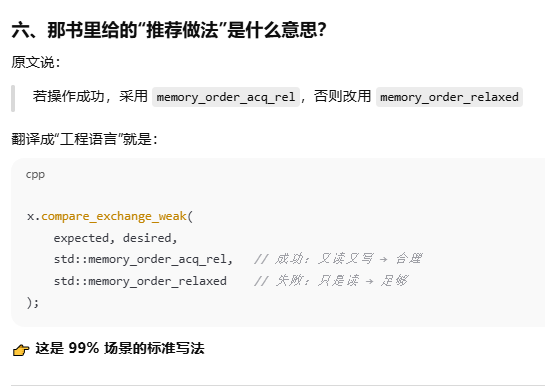
5.2.4 操作std::atomic<T*>:算术形式的指针运算
fetch_add()和fetch_sub()都是"读-改-写"操作

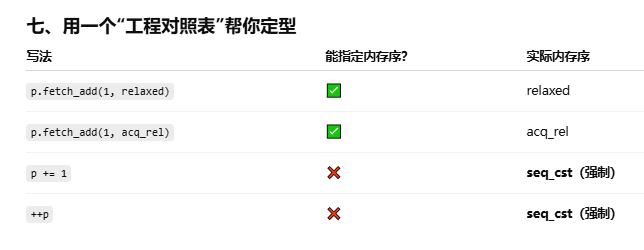
整数原子类型上的相关操作尚不算全面,但已经近乎完整,所缺少的重载运算符仅仅是乘除与位移
5.2.6 泛化的std::atomic<>类模板
std::atomic 只适用于"把对象当作一整块不可分割内存来比较和交换,而完全不关心其业务语义"的平凡数据类型。
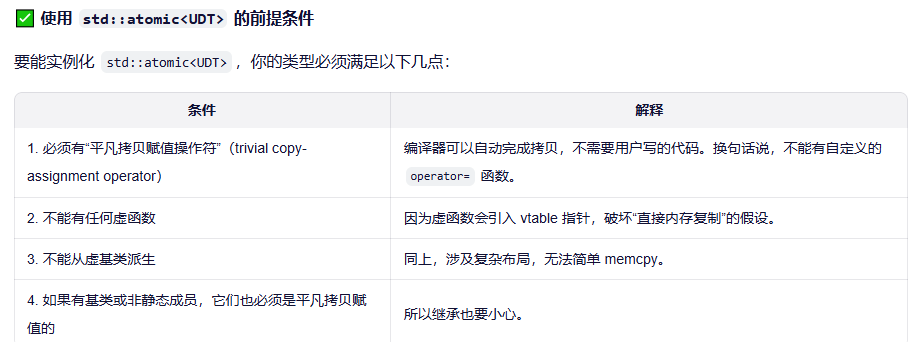

std::atomic 允许你对自定义类型做原子操作,但仅限于那些结构简单、能被 memcpy 安全复制的类型。它的比较是位级别的,不受你写的 == 影响,也不能用于复杂对象。如果不满足条件,就别硬用,改用 std::mutex 更安全。
5.3 同步操作和强制次序
同步关系只存在于原子类型的操作之间。
先后一致次序(memory_order_seq_cst)、获取-释放次序(memory_order_consume、memory_order_acquire、memory_order_release和memory_order_acq_rel)、宽松次序(memory_order_relaxed)。
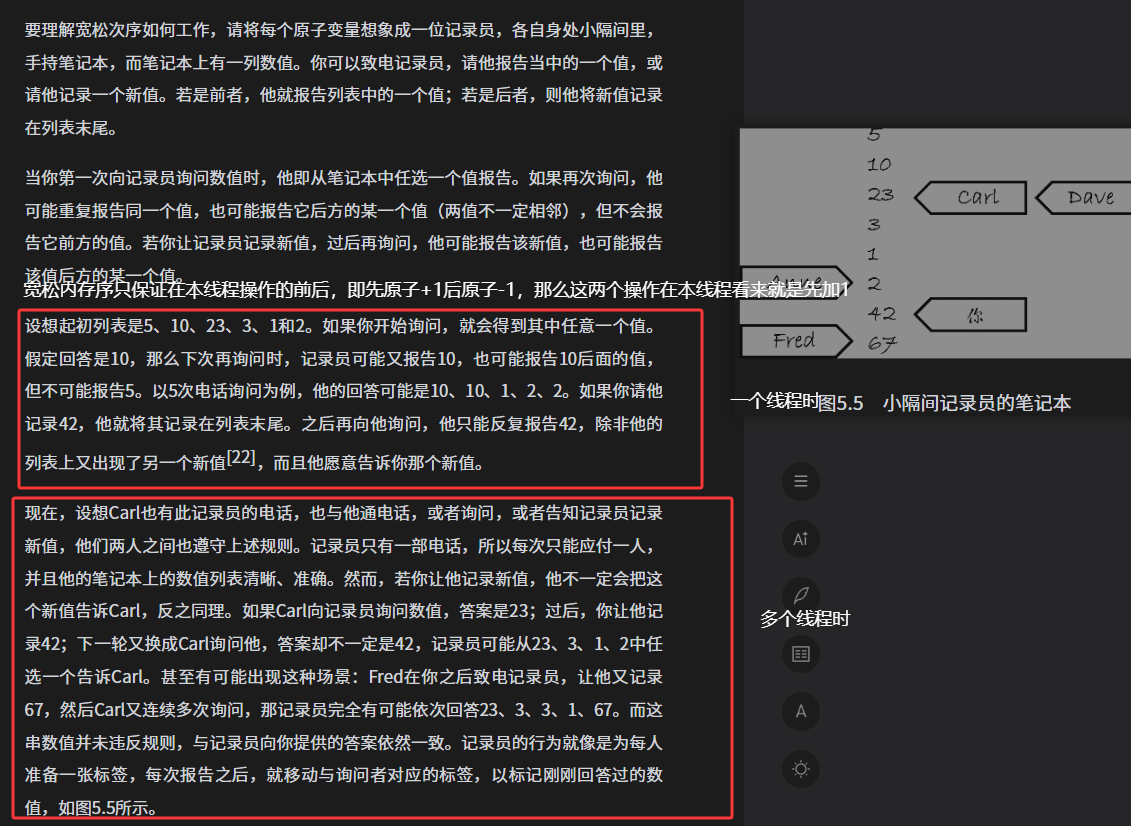
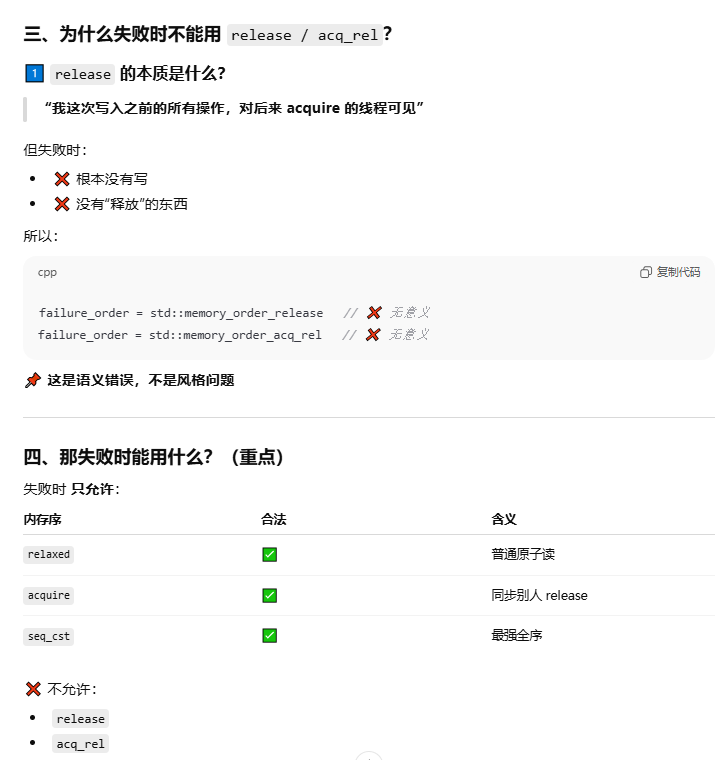
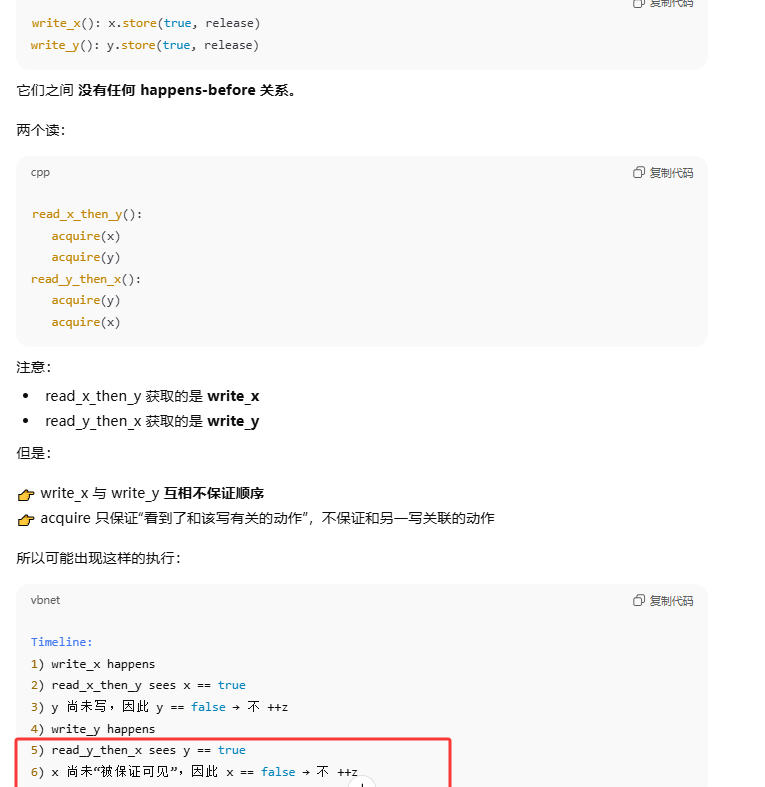
对于memory_order_acquire和memory_order_release的重要纠偏
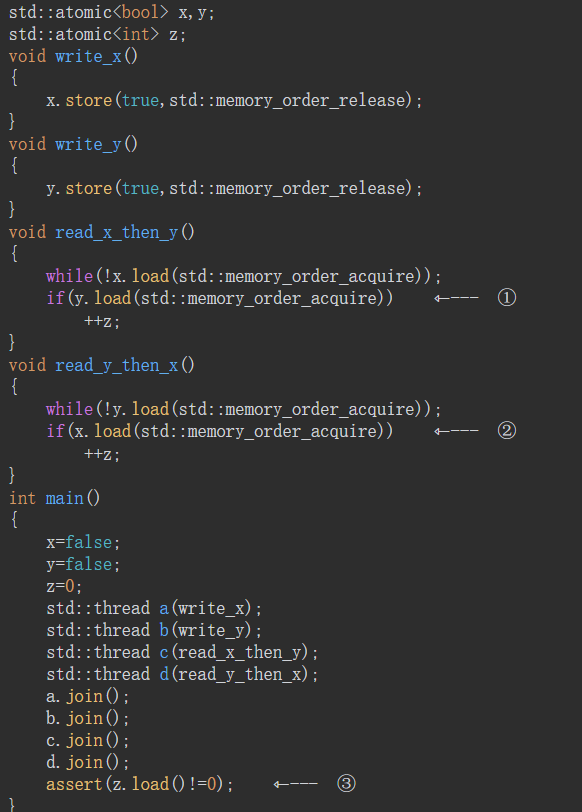
read_x_then_y执行到if时,一定保证x为true。read_y_then_x执行到if时,一定保证y为true。所以最终的x和y都会为true,注意这是最终,也就是aeesrt时,但是!!!!在read_x_then_y和read_y_then_x两个线程并不能保证执行到if时会使if为真。write_x()和write_y()并没有一个前后关系。如果两个有前后关系的话比如写x在前,那么执行到read_y_then_x线程一定可以使z++
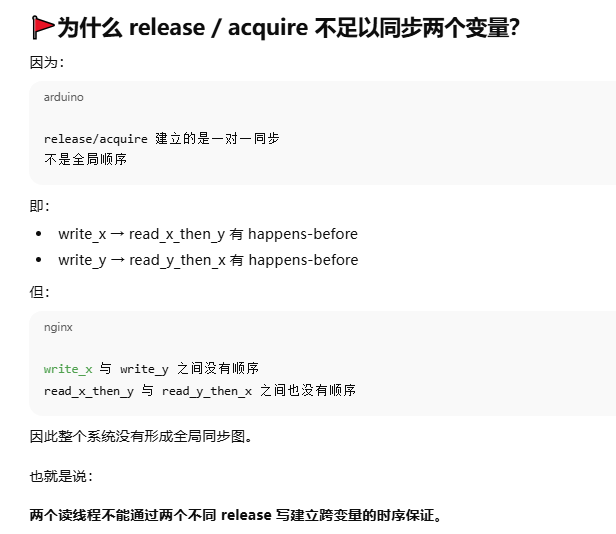
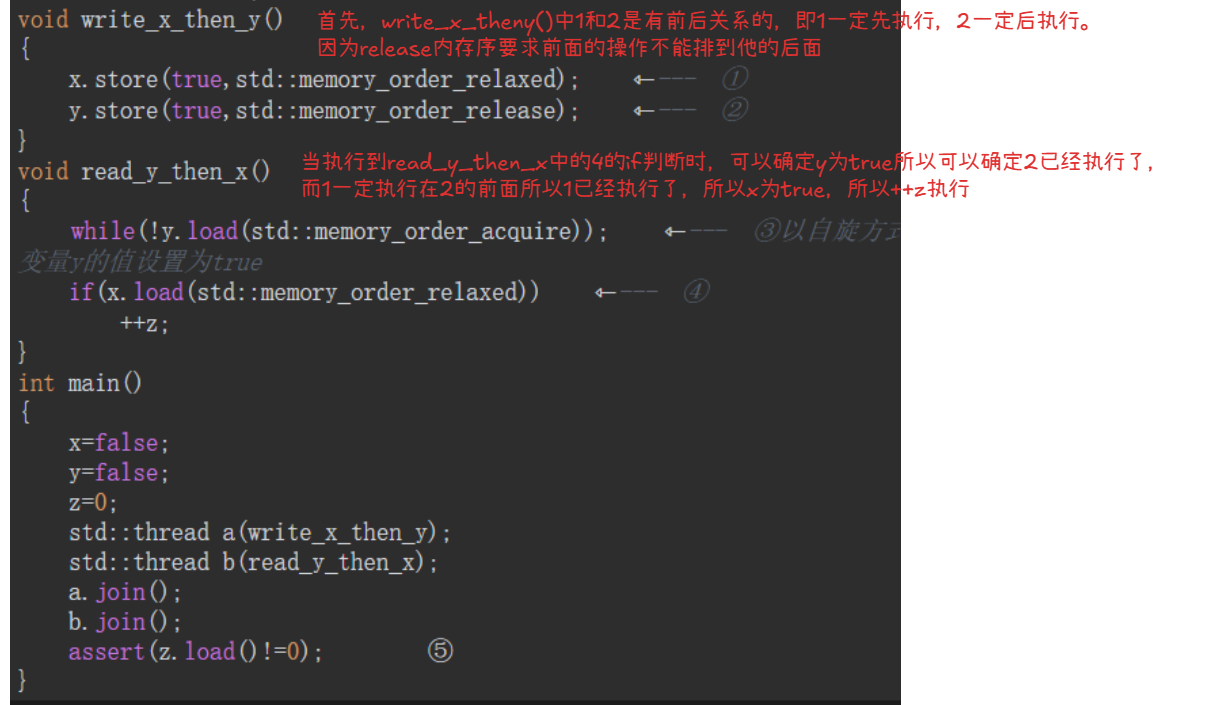
通过获取-释放次序传递同步
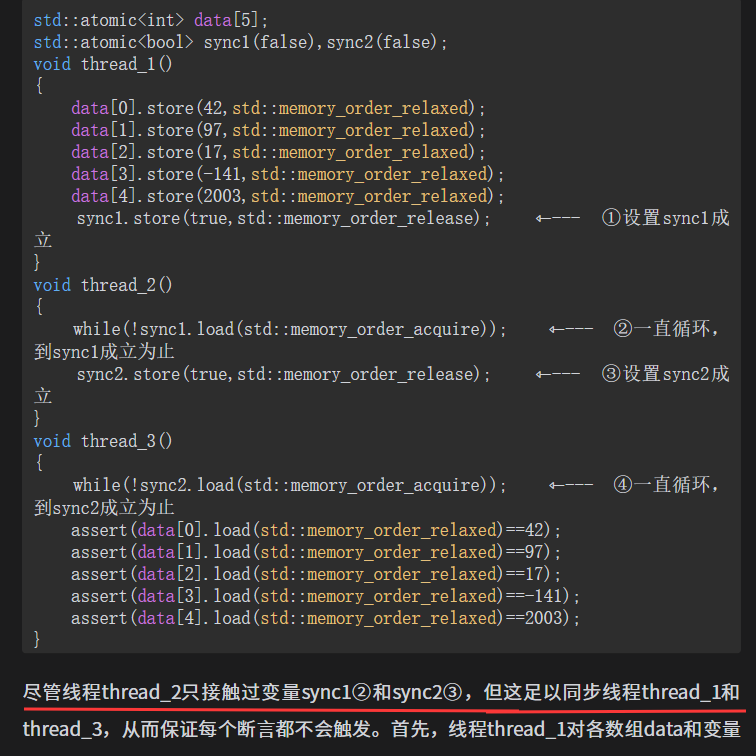
注意relaxed和released配合可以实现同步
上面的两个同步变量sync1和sync2变为1个:
cpp
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<int> data[5];
std::atomic<int> sync(0); // 0 → 1 → 2
void thread_1()
{
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141,std::memory_order_relaxed);
data[4].store(2003,std::memory_order_relaxed);
sync.store(1, std::memory_order_release);
}
void thread_2()
{
int expected = 1;
// 等待 sync == 1
while (!sync.compare_exchange_strong(
expected,
2,
std::memory_order_acq_rel,
std::memory_order_relaxed))
{
expected = 1; // CAS失败需恢复 expected
// 自旋直到成功把 1 改成 2
}
}
void thread_3()
{
// 等待 sync == 2
while(sync.load(std::memory_order_acquire) != 2);
assert(data[0].load(std::memory_order_relaxed)==42);
assert(data[1].load(std::memory_order_relaxed)==97);
assert(data[2].load(std::memory_order_relaxed)==17);
assert(data[3].load(std::memory_order_relaxed)==-141);
assert(data[4].load(std::memory_order_relaxed)==2003);
}
int main()
{
std::thread t1(thread_1);
std::thread t2(thread_2);
std::thread t3(thread_3);
t1.join();
t2.join();
t3.join();
}



"保序语义"(Sequential Consistency,即 memory_order_seq_cst)
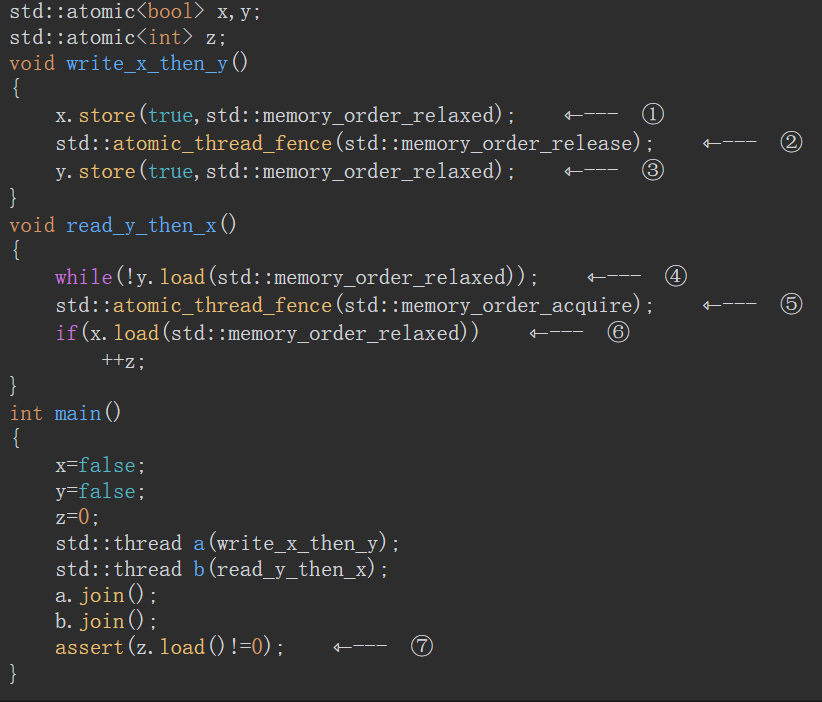



5.3.5 栅栏
栅栏具备多种操作,用途是强制施加内存次序,却无须改动任何数据。通常,它们与服从memory_order_relaxed次序的原子操作组合使用。

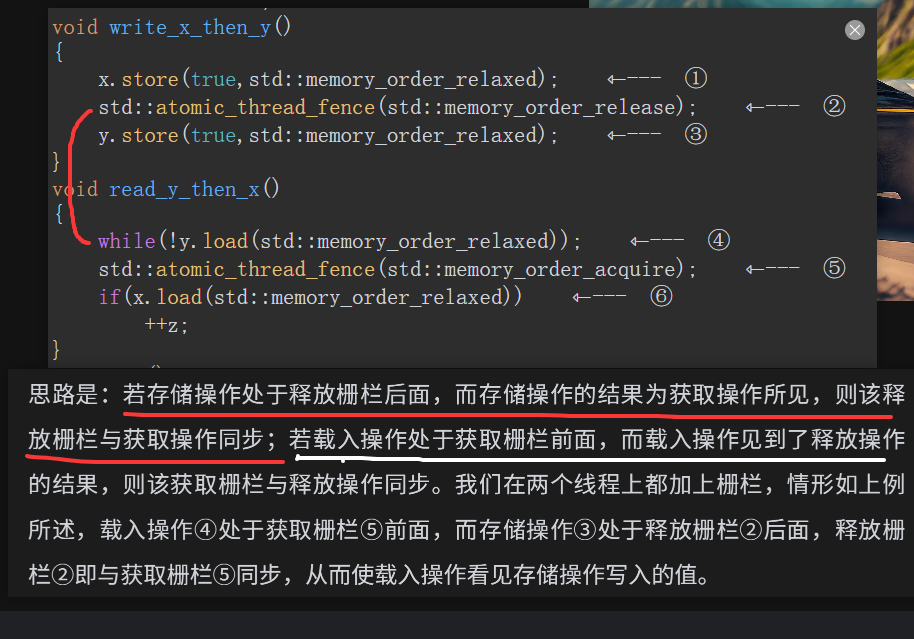

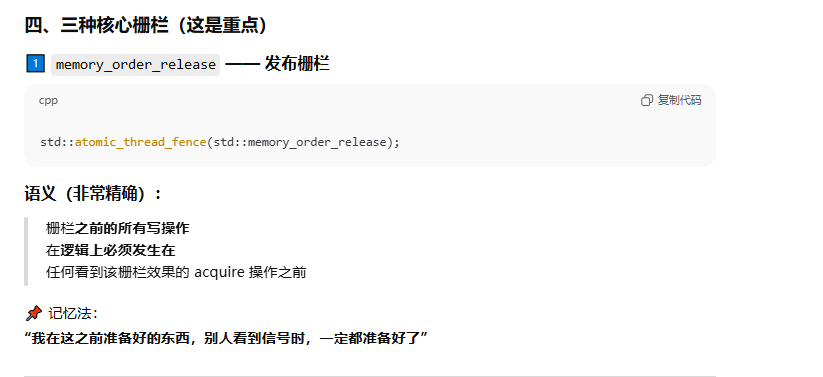
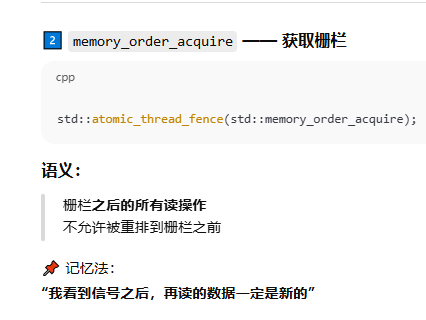

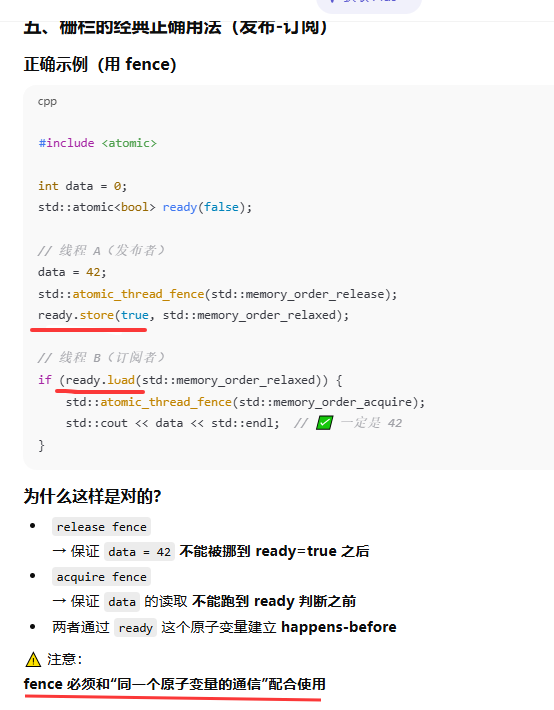
普通变量本身不具备内存顺序语义
但只要它们"夹在原子操作中间",
就会被"强制拖进"内存模型的秩序里
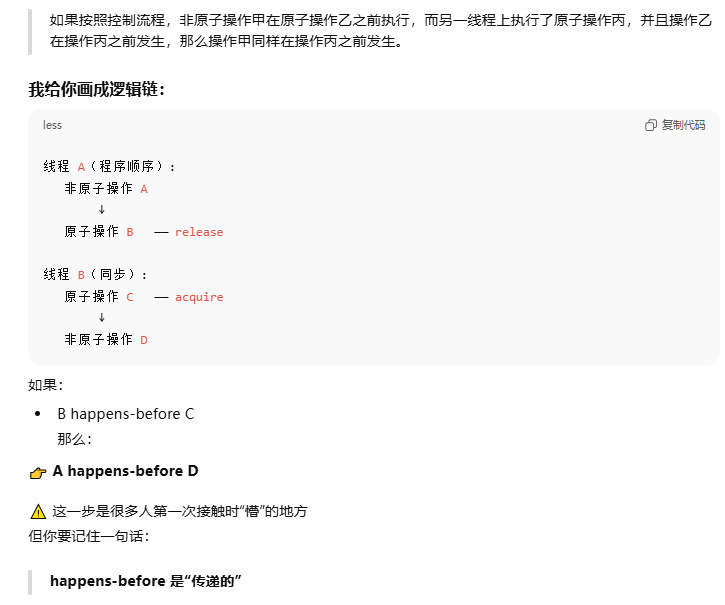
什么是"先行关系(happens-before)"?
不是"时间先后",而是:
A happens-before B ⇒ A 的结果对 B 必须可见
前五章的总结