背景
近期,由于旧服务器性能无法满足日益增长的服务需求,需要将核心中间件平滑迁移至一台高性能的新服务器节点。涉及的服务包括 Elasticsearch、Kafka 集群,以及 PostgreSQL 和 RabbitMQ 等开发环境服务,我觉得还是有必要记录一下的,就算各位佬友用不到,对我自己来说,也是一次运维经验的整理。
我把这些工作分了下面这几个阶段。
第一阶段:准备迁移
开始迁移之前,准备一下要迁移的服务,以及大体的迁移路线。
这一阶段,我这边的场景是分别准备
- postgreSQL
- RabbitMQ
- ElasticSearch
- Kafka
以上4个软件的安装环境,我这里RabbitMQ和PG只是作为开发环境的服务,作为一个单节点服务运行,要求不高,因此安装相对简单,基本按照官方文档或者操作习惯,从头安装即可。
主要还是ES和Kafka两个集群节点的迁移,我这里是把安装文件和相关的配置文件从即将下线的服务器直接scp到了新服务器节点,然后修改配置,重启服务的路线。
第二阶段:系统底层环境标准化
在新节点部署前,需要执行以下初始化,确保环境与其他服务器节点对齐。
1. 内核与资源限制
bash
# 修改内核参数
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
# 修改资源限制
cat <<EOF >> /etc/security/limits.conf
# 👇这里可以直接限制具体的资源对象,也可以像这样直接搞个*
* soft nofile 65536
* hard nofile 65536
EOF修改完成后的输出如下

这个按需执行即可,如果你要跑的服务不需要限制资源,那不用考虑
2. JDK环境
我这里要安装JDK是因为我的kafka集群是基于Kraft模式,依赖jdk。
而es启动文件里虽然已经包含了一个JDK,但仅限es自身使用,因此其他应用也依赖JDK的话还是要安装一下。
plain
# 安装系统全局 JDK
yum install -y java-17-openjdk-devel
由于我的JDK环境要给到Kafka帐户使用,因此要给Kafka也进行授权
bash
# 创建 kafka 用户并授权安装目录
useradd kafka
chown -R kafka:kafka /home/tony/kafka然后切到kafka用户下,看一下输出也ok即可

第二阶段:Elasticsearch 节点平滑平移
我这里,es做了安全配置,增加了X-Pack安全验证和SSL证书,因此迁移的时候,新节点上的配置必须"像素级"和原来的节点对齐,否则无法通过握手,甚至会导致集群脑裂或拒绝连接。
以下是具体步骤,在这之前,我已经完成了安装文件和证书文件的迁移。
修改配置
es的配置复杂度基本都收拢到了elasticsearch.yml文件里,因此要修改这个文件就可以了.
关键的配置如下,我对敏感信息做了脱敏(密码和ip地址)
yaml
# ---------------------------------- Cluster -----------------------------------
# 集群名称
cluster.name: magicloud-cluster
# ------------------------------------ Node ------------------------------------
# 修改节点名以区分
node.name: es-node214
node.master: true
node.data: true
# ----------------------------------- Paths ------------------------------------
# 确保新节点上这些目录存在且es用户有权读写
path.data: /usr/local/elasticsearch/data
path.logs: /usr/local/elasticsearch/logs
# ---------------------------------- Network -----------------------------------
# IP配置
network.host: xx.xxx.xx.xxx
http.port: 9200
# --------------------------------- Discovery ----------------------------------
# 种子节点写现有的节点
discovery.seed_hosts: ["xx.xxx.xx.xx1:9300", "xx.xxx.xx.xx2:9300", "xx.xxx.xx.xx3:9300"]
# ---------------------------------- Various -----------------------------------
action.destructive_requires_name: true
# 当前节点的IP地址
transport.host: xx
transport.tcp.port: 9300
# ------------------------ X-Pack Security Settings ------------------------
# 以下和原节点保持一致,注意证书路径要放对
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.http.ssl.truststore.path: certs/elastic-certificates.p12
# 密码保持一致
xpack.security.transport.ssl.keystore.password: "xxx"
xpack.security.transport.ssl.truststore.password: "xxx"
xpack.security.http.ssl.keystore.password: "xxx"
xpack.security.http.ssl.truststore.password: "xxx"
xpack.security.http.ssl.verification_mode: certificate这里涉及到配置ES安全属性的内容,有不了解的小伙伴可以参考Elastic的官网,笔者之前也写过相关的博客**,**欢迎感兴趣的小伙伴点击翻阅,传送门👉:https://mp.weixin.qq.com/s/5v4Q4fyRwD6QSsW96VELRQ
修改权限
因为es处于安全考虑,严禁root用户启动服务,因此要在新节点上创建相关的用户组并配置权限。
- 创建用户组
bash
# 创建用户组
groupadd elsearch
# 创建用户并加入组
useradd elsearch -g elsearch
# 设置密码(可选,如果只是 su 切换则不一定需要)
# passwd elsearch- 操作目录授权
bash
# 1. 赋予安装目录权限
chown -R elsearch:elsearch /opt/es/elasticsearch-7.14.1/
# 2. 赋予数据和日志目录权限(根据你之前的配置路径)
chown -R elsearch:elsearch /usr/local/elasticsearch/data
chown -R elsearch:elsearch /usr/local/elasticsearch/logs- 检查jvm堆内存
确保给新节点分配的内存(比如 -Xms4g -Xmx4g)不要超过系统可用内存的一半。
启动新节点并验证加入
- 启动
bash
su - elsearch -c "/opt/es/elasticsearch-7.14.1/bin/elasticsearch -d"
- 启动无误后,到原来的任意一个节点上验证一下加入情况
bash
curl -X GET "http://10.185.3.176:9200/_cat/nodes?v"注意,此时即将准备下线的那个节点还是正常运行的,因此正常情况下,列表数量应该是N+1个记录,比如我这里原来是3个节点,此时就是4个。

触发分片驱逐 (迁移数据)
这一步就是让集群主动的"踢掉"准备下线的那个节点,并把那个节点上的数据同步到其他节点,这正是ElasticSearch作为一个分布式日志系统的强大之处!
bash
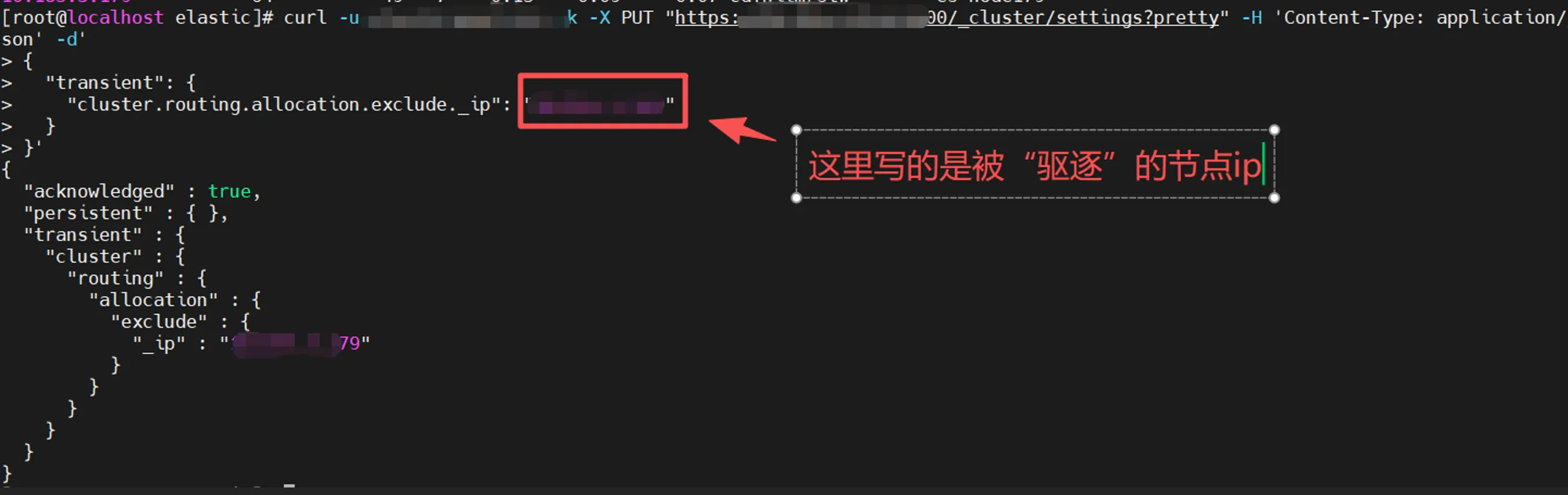
curl -X PUT "http://{xxx,这里是在一个原有的节点上}:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.exclude._ip": "{被驱逐的节点ip}"
}
}'执行后的响应如下
监控迁移进度
可以通过一下命令观察待驱逐的节点shards数量变化,直到它变成0,这一步需要一定的执行时间,时间长短和日志文件的大小有关,耐心等待即可。
plain
curl -u elastic -k "https://xx.xxx.xx.xxx:9200/_cat/allocation?v"也可以借助一些可视化的监控工具查看迁移进度

迁移完成后

收尾与配置刷新
上一步完成收,线上的ES集群实际上就已经是全新的集群了,但由于原来的集群节点我们还没有修改,当服务重启后,还是会有问题。所以我们还要逐一修改原有的节点配置,这里只要配置服务发现的节点数组对象就可以了
bash
# 以下xxx代表实际的ip地址
discovery.seed_hosts: ["xxx1:9300", "xxx2:9300", "xxx3:9300"]修改完成后,还要接触前面设置的驱逐限制,这一步也很重要,否则新节点以后也会受限
bash
curl -u elastic -k -X PUT "https://xxx:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"transient": {
"cluster.routing.allocation.exclude._ip": null
}
}'
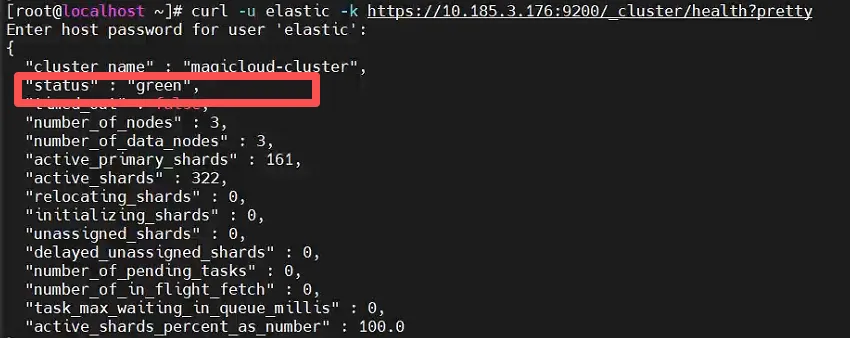
全部执行完成后,需要把集群内所有的节点再重启一遍,虽然有点繁琐,但这是必须的,重启完成后,看一下集群状态
bash
curl -u elastic -k https://xxx:9200/_cluster/health?pretty或者通过管理面板查看,变成"Green"即可

好了,值此ElasticSearch的迁移工作完成,可以把准备替换的那台节点上的es节点干掉了。
bash
ps -ef | grep elasticsearch | grep -v grep | awk '{print $2}' | xargs kill -9注意,这里别忘了要把新增节点上的端口放开
bash
# 开放 9200 和 9300 端口
firewall-cmd --permanent --add-port=9200/tcp
firewall-cmd --permanent --add-port=9300/tcp
# 重新加载防火墙配置使生效
firewall-cmd --reload
# 查看是否生效
firewall-cmd --list-ports第三阶段:Kafka节点平滑迁移
修改配置
和es的迁移一样,我这里也是提前把安装文件,配置文件等都拷贝到了新节点,然后修改配置文件,我这里的Kafka集群使用的新的Kraft模式,这里修改的是Kraft目录里的配置,主要修改voters参数和node.id,注意node.id必须是一个集群里没出现过的id
bash
############################# Server Basics #############################
# 基本配置
process.roles=broker,controller
node.id=214
controller.quorum.voters=214@xxx:9093,178@xxx:9093,176@xxx:9093
# =============================默认配置======================= #
listeners=PLAINTEXT://xxx:9092,CONTROLLER://10.185.3.214:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://xxx:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# ========================================默认配置结束=================================== #
controller.listener.names=CONTROLLER
process.cluster.id=xxxx
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
log.dirs=/usr/kafka/kraft-combined-logs
num.partitions=3
default.replication.factor=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000节点环境准备
和ElasticSearch的迁移一样,创建用户组和授权
bash
groupadd kafka && useradd kafka -g kafka
mkdir -p /usr/kafka/kraft-combined-logs
chown -R kafka:kafka /usr/kafka/kraft-combined-logs
chown -R kafka:kafka /home/tony/kafka/数据重分配 *
这一步,看你的Kafka实际作用,如果只是传递实时消息,那迁移完成后直接重置消息日志也是可以的,前提是你确实不需要迁移的哈
- 提取原来的Topic
bash
# 先把所有 topic 名字提出来,存到 topics.txt
bin/kafka-topics.sh --bootstrap-server xx.xxx:9092 --list | grep -v "__consumer_offsets" > topics.txt
# 将其转换为 Kafka 识别的json格式
echo '{"topics": [' > topics-to-move.json
sed 's/.*/ {"topic": "&"},/' topics.txt | sed '$s/,$//' >> topics-to-move.json
echo '], "version": 1}' >> topics-to-move.json这样就得到了一个完整的 topics-to-move.json。
- 生成迁移方案
bash
bin/kafka-reassign-partitions.sh --bootstrap-server 10.185.3.176:9092 \
--topics-to-move-json-file topics-to-move.json \
--broker-list "176,178,214" \
--generate上面的176这些,就是node.id的名称,这个要确保集群内唯一
执行后,屏幕会打印出两段长长的json串,我们需要把第二段(proposed partition reassignment configuration)下面的全部内容拷贝下来保存到一个文件里,比如execute-reassign.json
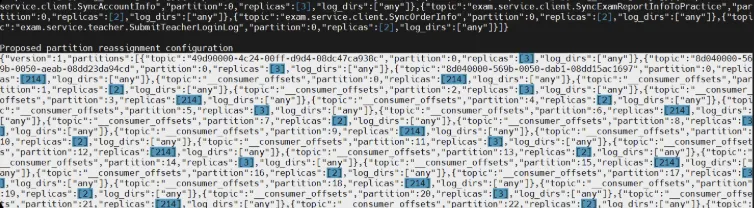
- 搬家
上面文件保存后,就可以搬家了
bash
./bin/kafka-reassign-partitions.sh --bootstrap-server 10.185.3.176:9092 \
--reassignment-json-file execute-reassign.json \
--execute执行这个命令查看搬家进度
bash
./bin/kafka-reassign-partitions.sh --bootstrap-server xxx:9092 \
--reassignment-json-file execute-reassign.json \
--verify如果看到 Reassignment of partition ... is in progress,就说明搬家正在进行中。直到所有分区都显示: Status: completed successfully。此时,你可以去新节点的存储目录看一眼,确认数据量是否已经上来:
等原节点被掏空后,就可以下线掉它了,至此,Kafka集群已经是全新的集群了
收尾与配置刷新
和es的迁移一样,这里集群里原来的节点也要进行修改,主要是修改controller.quorum.voters,集群里每个节点的配置要保持一致。
然后滚动重启即可
可能出现的问题 *
迁移Kafka的时候,非常容易出现问题,比如我这里就遇到了下面这个问题,实际上这个错误就是kafka在进行三方校验的时候出错了,元数据日志里记录了旧集群的状态,可以通过编辑或者查看/usr/kafka/kafka-3.8-176/kraft-combined-logs/meta.properties这个文件来确认
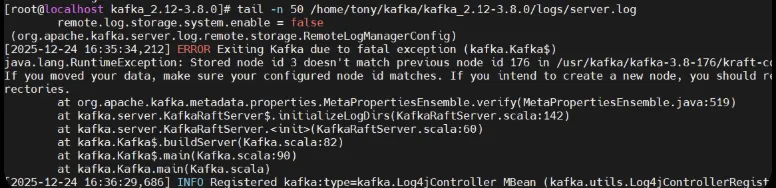
我也试过手动修改这个元数据文件,但不起作用,如果前面的数据重新分配步骤已经完成,或者说你不需要重洗分配,那最简单蛮粗暴的方法就是重置他们。
- 停止所有kafka的进程
- 清空元数据(慎重)
bash
rm -rf /usr/kafka/kraft-combined-logs/*- 重新格式化
bash
su - kafka -c "/home/tony/kafka/kafka_2.12-3.8.0/bin/kafka-storage.sh format -t {配置文件里设置的集群id} -c /home/tony/kafka/kafka_2.12-3.8.0/config/kraft/server-cluser.properties"- 重启
bash
su - kafka -c "/home/tony/kafka/kafka_2.12-3.8.0/bin/kafka-server-start.sh -daemon /home/tony/kafka/kafka_2.12-3.8.0/config/kraft/server-cluser.properties"第四阶段:定期打扫
ES日志自动清理
我们的场景里,ES搜集的是所有业务系统的操作日志,可以方便的定位问题。但问题就是日志量比较庞大,我这里的策略是写了一个监控程序,跑在一台业务服务器,然后滚动删除日期比较早的日志。这部分我是使用C#接入ES的官方SDK,NEST来做的,代码比较简单不在灌入。
这个看实际情况,我们的情况是比较早的日志就不保留了,直接删除释放空间,当然也可以打包下载下来做归档。
Kafka日志自动清理任务
Kafka产生的持久化数据主要有有业务数据和集群元数据,其中存储在"/kraft-combined-logs/"路径下的文件绝对不能手动删除,Kafka本身会自动清理它。而在安装文件的logs目录下产生的目录是可以删除的,而且他也是无限增长的,所以我们可以搞个脚本,然后挂到计划任务里,定期删掉他;
plain
#!/bin/bash
# 1. 定义路径
LOG_DIR="/home/tony/kafka/kafka_2.12-3.8.0/logs"
CLEAN_LOG="/home/tony/shells/cleanlog.log"
# 确保存放清理记录的目录存在
mkdir -p /home/tony/shells
echo "--- 开始清理任务: $(date +'%Y-%m-%d %H:%M:%S') ---" >> "$CLEAN_LOG"
# 2. 直接获取文件列表,避免子 Shell 导致计数器失效
# 使用 .log.* 匹配被压缩或切分后的历史日志(如 server.log.2025-12-24-1)
files=$(find "$LOG_DIR" -type f -name "*.log.*" -mtime +30)
count=0
for file in $files; do
if [ -f "$file" ]; then
rm -f "$file"
if [ $? -eq 0 ]; then
echo "[SUCCESS] 已删除: $file" >> "$CLEAN_LOG"
((count++))
else
echo "[ERROR] 无法删除: $file" >> "$CLEAN_LOG"
fi
fi
done
# 3. 记录总结
echo "本次任务共清理 $count 个文件." >> "$CLEAN_LOG"
echo "------------------------------------------------" >> "$CLEAN_LOG"
bash
# 编辑计划任务
crontab -e
# 添加如下内容(每天凌晨 02:00 执行一次)
00 02 * * * /bin/bash /home/tony/shells/clean_kafka_log.sh > /dev/null 2>&1第五阶段:搞定rabbitmq和pg
这两个在我这里就是开发测试用,所以我就是参照官方文档和网上的一些教程还有AI的搭配,重新安装的,但是pg安装完成后有一个数据恢复的过程,这里简单过一下吧
PostgreSQL
pg的安装我采用的是源码安装方式,因为我这里是open Euler系统,官方的提供rpm包我试着安装失败,所以改成了通过源码的方式。具体大家参考官网就好。
- 安装依赖
bash
sudo dnf check-update
sudo dnf install -y gcc gcc-c++ make readline-devel zlib-devel openssl-devel libicu-devel systemd-devel bison flex- 创建用户与目录
bash
# 创建 postgres 用户组和用户
sudo groupadd postgres
sudo useradd -g postgres postgres
# 创建安装目录和数据目录
sudo mkdir -p /opt/pgsql17
sudo mkdir -p /var/lib/pgsql/17/data
sudo chown -R postgres:postgres /opt/pgsql17 /var/lib/pgsql/17/data- 下载安装源码
bash
# 切换到临时目录
cd /usr/local/src
# 下载 PG 17.6 源码
sudo wget https://ftp.postgresql.org/pub/source/v17.6/postgresql-17.6.tar.gz
# 解压
sudo tar -zxvf postgresql-17.6.tar.gz
cd postgresql-17.6- 配置编译
bash
# 配置(启用 OpenSSL 和 Systemd 支持)
./configure --prefix=/opt/pgsql17 \
--with-openssl \
--with-systemd \
--with-icu
# 编译
make
# 安装
sudo make installmake的时候会消耗一点时间
- 配置环境变量
bash
# 编辑 /etc/profile.d/pgsql.sh
sudo bash -c 'cat > /etc/profile.d/pgsql.sh << EOF
export PGHOME=/opt/pgsql17
export PGDATA=/var/lib/pgsql/17/data
export PATH=\$PGHOME/bin:\$PATH
EOF'
# 使配置生效
source /etc/profile.d/pgsql.sh- 初始化数据库
bash
# 切换用户
sudo -i -u postgres
# 执行初始化
/opt/pgsql17/bin/initdb -D /var/lib/pgsql/17/data --locale=en_US.UTF-8 --encoding=UTF8
# 退出用户
exit- 配置开机启动
bash
sudo vim /etc/systemd/system/postgresql-17.service写入下面内容(这些教程上都有,我也是copy的,这里直接镜像一份)
bash
[Unit]
Description=PostgreSQL 17 database server
After=network.target
[Service]
Type=notify
User=postgres
Group=postgres
ExecStart=/opt/pgsql17/bin/postmaster -D /var/lib/pgsql/17/data
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
KillSignal=SIGINT
TimeoutSec=0
[Install]
WantedBy=multi-user.target- 启动和验证
bash
# 重新加载系统服务
sudo systemctl daemon-reload
# 启动并设置开机自启
sudo systemctl enable --now postgresql-17
# 检查状态
sudo systemctl status postgresql-17- 恢复备份
bash
# 切换到 postgres 用户
sudo -i -u postgres
# 创建一个新数据库(例如叫 mydb)
createdb mydb
# -d 指定目标数据库,-f 指定备份文件路径
psql -d mydb -f /root/pgbackup/pg14_full_backup.sql- 我这里是全量备份的,所以直接这样
bash
psql -f /tmp/pg14_full_backup.sql postgres原节点的pg版本是14,新节点是17
- 异常处理
执行过程中,openEuler开启了用那个的权限控制,所以可能要只ing一下操作
bash
# 确保 postgres 用户对二进制文件夹有进入权限。
sudo chmod +x /opt/pgsql17/bin/postgres
sudo chown -R postgres:postgres /opt/pgsql17
# openEuler 的 SELinux 可能会阻止自定义路径下的程序执行。你可以临时关闭它测试一下
sudo setenforce 0
# 然后在重启下RabbitMQ
上面pg的安装说了太多了,rabbitmq就精简点吧,大家自己搜一下也行,而且他这个有中文文档,也很详细。我这里就不多说了哈
直接跳过了!
结语
上面这点事儿,白天折腾了一整天,晚上趁着热乎赶紧整理,主要还是怕自己忘了,因为有些步骤我在之前部署集群的时候确实是不熟练,所以把这些运维知识点也算是巩固对齐了一下。没想到,一整理起来,洋洋洒洒写了这么多。
最后,希望大家的服务器,永不宕机,永不重启!