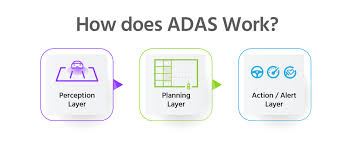
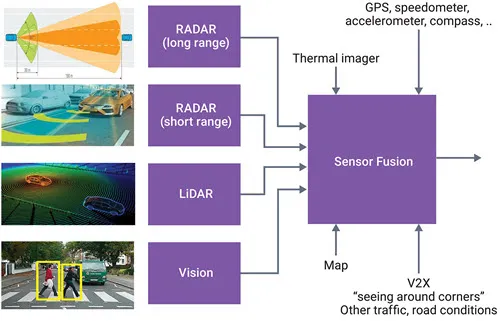
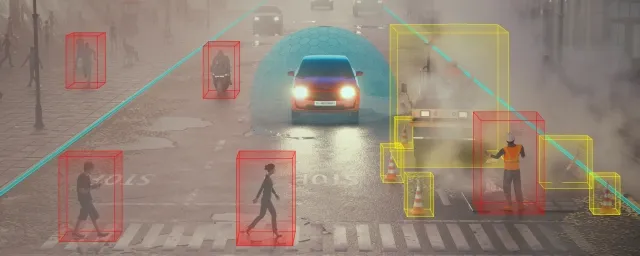
本文总结各传感器的感知算法
这是指域控制器(Domain Controller,如 Orin-X, Thor, FSD芯片)接收到传感器传来的数据(图像、点云、目标列表等)后,运行的深度学习(Deep Learning)或几何算法。
这一步的目标是从数据中"理解"世界,完成检测、分割、跟踪和定位。
- "眼睛"和"耳朵"------传感器的角色 自动驾驶汽车要像人一样"看见"和"听见"周围的世界,需要多种传感器协同工作:
| 传感器 | 主要功能 | 为什么需要它 |
|---|---|---|
| 摄像头 | 捕捉彩色图像,识别车道、交通标志、行人等细节 | 类似人眼,提供丰富的视觉信息 |
| 毫米波雷达 | 发射电磁波,测量目标距离和相对速度,抗雾雨能力强 | 在恶劣天气下仍能可靠探测 |
| 激光雷达(LiDAR) | 发射激光点云,生成高精度的 3D 环境模型 | 精确定位障碍物的形状和位置 |
| 超声波传感器 | 短距离测距,常用于泊车和低速场景 | 对近距离障碍物的快速感知 |
这些传感器各有优势,组合起来可以实现信息冗余和互补,提升整体感知的可靠性。
-
从原始信号到"可理解的世界"------感知算法的核心任务
-
目标检测:在图像或点云中找出"这是什么",比如车辆、行人、交通灯。
-
目标分类:进一步判断它们的具体类型(行人 vs. 骑行者、红灯 vs. 绿灯)。
-
语义分割:把每个像素标记为道路、车道线、建筑等,实现像素级的环境理解。
-
目标跟踪:在连续帧之间关联同一目标,预测它的运动轨迹。
这些任务构成了感知系统的"基本功",是后续决策与控制的输入。
- 多模态信息融合------把"听到的"和"看到的"合在一起 单一传感器往往会出现盲区或噪声。例如摄像头在夜间或雨天容易失真,而雷达在复杂城市环境中可能出现误检。感知算法会把来自不同传感器的数据 融合,形成统一的环境模型。常见的融合方式包括:
-
前融合:直接在原始数据层面合并(如把激光点云投影到摄像头图像上)。
-
特征融合:先分别提取各传感器的特征,再在中间层进行融合。
-
后融合:分别得到检测结果后,再通过规则或学习模型统一决策。
融合技术能够显著提升检测的准确率和鲁棒性。
- 深度学习的"思考方式"------从 2D CNN 到 BEV‑Transformer 早期感知主要依赖 卷积神经网络(CNN) 对摄像头图像进行 2D 检测。随着需求升级,出现了两大趋势:
| 发展阶段 | 关键技术 | 主要优势 |
|---|---|---|
| 2D + CNN(2017‑2019) | 直接在摄像头图像上做检测 | 对视觉细节捕捉好,但缺乏全局空间感 |
| BEV + Transformer(2020 起) | 将多传感器特征投影到鸟瞰视角(BEV),再用 Transformer 处理全局关联 | 能同时利用 3D 信息,提升对远距离和遮挡目标的感知能力 |
| 端到端感知(2022‑今) | 用统一的大模型直接从原始传感器数据输出感知结果,省去中间手工设计的步骤 | 信息损失更小,推理速度更快,但对算力和数据量要求更高 |
Transformer 的自注意力机制让模型能够"看到"更远、更全的场景,类似人类在鸟瞰图上整体把握道路布局。
- 实时性与安全------感知算法的硬性要求 自动驾驶的每一步决策只能在 几十毫秒 内完成。为满足这一苛刻的时延要求,感知算法在实现上会进行:
-
模型压缩与量化:把大模型裁剪、降低精度,以适配车载芯片。
-
算子优化:针对硬件特性(GPU、ASIC)做专门加速。
-
安全降级:在算力或传感器受限时,只保留最关键的检测(如大型移动目标和车道线),并交由驾驶员介入。
这些措施确保感知结果既快速又可靠,为后续的路径规划和控制提供坚实基础。
-
小结:感知算法到底在干什么? 感知算法 = "把车外的光、声、激光信号转化为机器能理解的'地图',并实时标记出道路、障碍物、行人等关键要素。" 它的工作流程大致是:
-
采集:摄像头、雷达、激光雷达等多模态传感器获取原始数据。
-
预处理:去噪、校准、投影到统一坐标系。
-
特征提取 & 融合:使用 CNN、Transformer 等深度模型抽取特征并融合。
-
任务执行:检测、分类、分割、跟踪等,输出结构化的环境信息。
-
实时输出:在毫秒级完成,供决策系统规划路径并控制车辆。
正是这些"看得见、分得清、跟得上"的感知能力,让自动驾驶汽车能够在复杂的真实道路上安全行驶。

1、Camera 感知算法
视觉是目前算法最丰富、迭代最快的领域,通常基于 CNN(卷积神经网络)或 Transformer 架构。
-
2D/3D 目标检测 (Object Detection):
-
2D: 在图像画框(Bounding Box)。算法如 YOLO, Faster R-CNN。识别车、人、骑行者、交通锥。
-
3D: 估算物体的长宽高、距离和朝向(Yaw)。算法如 FCOS3D, DETR3D。
-
语义分割 (Semantic Segmentation):
-
像素级分类。将图像分为:可行驶路面、人行道、草地、天空、车辆。算法如 SegFormer, U-Net。
-
车道线检测 (Lane Detection):
-
识别车道线位置、类型(虚/实/黄/白)和拓扑关系。算法如 LaneNet, PolyLaneNet。
-
交通标志/红绿灯识别 (TSR / TLR):
-
识别限速牌数值、红绿灯颜色及箭头指向。
-
BEV (Bird's Eye View) 转换 - 当前主流:
-
将多路摄像头的图像特征投影到统一的俯视坐标系。算法如 BEVDet, BEVFormer, LSS (Lift-Splat-Shoot)。这是实现"纯视觉测距"的核心。
-
Occupancy Network (占用网络):
-
不识别具体物体是什么,只识别空间中"哪里有东西,哪里是空的"。用于处理异形障碍物(如翻倒的卡车)。
感知任务层(核心算法)
-
目标检测(车辆、行人、骑行者)
-
车道线/道路标线检测
-
交通标志/信号灯识别
-
语义/实例分割(像素级理解)
-
深度/距离估计(单目、双目或多目)
-
3D 检测 & BEV(鸟瞰视图)
主流算法技术路线
| 任务 | 传统方法 | 深度学习方法 | 近期趋势 |
|---|---|---|---|
| 目标检测 | HOG+SVM、基于颜色/形状的模板匹配 | YOLOv5/YOLOX、Faster‑RCNN、SSD | 轻量化 Transformer(DETR‑Tiny) |
| 车道线检测 | Canny 边缘 + Hough 变换、颜色阈值分割 | SCNN、LaneNet、PolyLaneNet | 基于 BEV + Transformer 的端到端车道感知 |
| 交通标志 | Haar‑cascade、颜色/形状特征 | Faster‑RCNN、YOLO‑P、EfficientDet | 多任务学习(HydraNet)统一检测与分割 |
| 语义分割 | 基于 CRF、随机森林 | DeepLabV3+, HRNet, SegFormer | 大模型微调 + 多模态融合 |
| 深度估计 | 双目视差、基于已知尺寸的几何推算 | Monodepth2、MiDaS、AdaBins | 结合 BEV + Occupancy 网络的 3D 场景重建 |
| 3D 检测 / BEV | 基于投影的几何模型 | CenterNet‑3D、Lift‑Splat‑Shoot、BEVFormer | 前融合 BEV + Transformer(Tesla FSDBetaV9) |
关键技术进展
多任务统一模型
HydraNet(特斯拉)实现单一网络同时完成车辆、标志、车道等多任务,显著降低算力需求。
BEV(Bird‑Eye‑View)+ Transformer
将多摄像头视角投射到统一的鸟瞰平面,再通过 Transformer 进行特征融合,实现更精准的 3D 检测与路径规划。
Occupancy 网络
将图像空间映射为占据/未占据的体素网格,能够预测动态物体的运动趋势,为高阶自动驾驶提供前瞻性信息。
端到端感知‑决策
通过"一体化端到端"或"双系统并行"(大模型 + VLM)实现从原始图像直接输出轨迹或行为指令,提升系统整体效率。
硬件协同
ISP + NPU 的深度协同加速图像预处理与神经网络推理,典型方案如黑芝麻的 ISP+DynamAINN NPU。
高分辨率摄像头(8M+)提升检测距离与视场角,配合大光圈、HDR 等硬件特性,显著改善弱光下的感知能力。
常用数据集与评估指标
| 数据集 | 主要内容 | 适用任务 |
|---|---|---|
| KITTI | 实景道路、标注 3D 框、深度图 | 目标检测、深度估计、3D 检测 |
| Waymo Open Dataset | 大规模多摄像头+激光雷达 | 多模态融合、BEV 感知 |
| nuScenes | 360° 摄像头、雷达、标注 | 端到端感知、轨迹预测 |
| BDD100K | 城市道路、标志、车道 | 目标检测、分割、车道线 |
- 评估指标:mAP(目标检测)、IoU(分割)、RMSE(深度)、ATE(轨迹误差)等。
实际系统的感知流水线(示例)
图像采集 → ISP 去畸变、自动曝光、HDR
校准 & 坐标转换 → 生成相机坐标系下的点云(单目深度)
特征提取 → 轻量化 CNN/Transformer backbone(如 EfficientNet‑B0)
多任务头 →
-
检测头(YOLO‑X) → 车辆/行人/骑行者
-
分割头(SegFormer) → 车道、道路、障碍物
-
深度头(MiDaS) → 单目深度图
多摄像头 BEV 融合 → Transformer‑based BEV encoder
后处理 → NMS、轨迹关联、占据网格生成
输出 → 3D 边界框、车道曲线、占据网格、风险评估
该流水线在 地平线征程6 系列 SoC(560 TOPS)上可实现 30 fps 实时感知。
车载摄像头的感知算法已经从传统的几何/特征匹配演进到以深度学习为核心的多任务、端到端体系。近期的技术热点包括BEV + Transformer、Occupancy 网络、以及HydraNet等多任务统一模型,配合高分辨率摄像头 + ISP + NPU的硬件协同,能够在实时性与精度之间取得更好的平衡。随着算力提升和多模态融合的成熟,车载视觉感知将在 L3‑L4 级别的自动驾驶中发挥越来越关键的作用。
2、Lidar 感知算法
LiDAR 数据是稀疏的 3D 点云,算法重点在于处理无序性和稀疏性。
-
点云预处理:
-
去畸变 (Motion Compensation): 利用 IMU 数据修正车辆运动导致的点云扭曲。
-
地面分割 (Ground Segmentation): 算法如 RANSAC, Patchwork。移除地面点,只保留障碍物点。
-
3D 目标检测:
-
基于体素 (Voxel) 的方法:如 VoxelNet, SECOND(速度快)。
-
基于点 (Point) 的方法:如 PointNet++, PointRCNN(精度高)。
-
基于 Pillar (柱) 的方法:如 PointPillars(工业界最常用,平衡速度与精度)。
-
点云分割/聚类:
-
欧式聚类 (Euclidean Clustering):将挨得近的点聚成一坨。
-
语义分割:识别点云是树木、建筑物还是车辆。算法如 Cylinder3D。
感知系统整体框架
车载激光雷达的感知算法一般分为 数据预处理 → 特征提取/分割 → 目标检测与分类 → 目标跟踪/预测 → 场景建图(SLAM) 四大阶段。感知层负责把原始点云转化为可供决策层使用的高价值信息,如障碍物位置、可行驶区域、运动轨迹等。
传统点云处理方法(基于几何/统计的算法)
| 步骤 | 常用技术 | 说明 |
|---|---|---|
| 去噪/下采样 | 体素网格(Voxel Grid)滤波、统计离群点移除 | 降低点云密度、提升后续计算效率 |
| 地面分割 | RANSAC 平面拟合、基于极坐标/球坐标网格的局部平面拟合、基于高度阈值的分层方法 | 将地面点与非地面点分离,为障碍物聚类做准备 |
| 聚类/分割 | Euclidean 聚类、DBSCAN、连通分量标记(CCL) | 将同一物体的点云聚合为簇,得到粗略目标框 |
| 特征描述 | PFH、FPFH、Spin Image 等局部几何特征 | 为后续的匹配或分类提供描述子 |
| 配准/建图 | ICP、NDT、图优化(Pose Graph) | 将多帧点云拼接形成全局地图(SLAM) |
这些方法实现简单、实时性好,但对复杂场景(遮挡、稀疏点云)的鲁棒性有限,已逐步被深度学习方法所补足。
深度学习的 3D 检测与分类
近年来,基于点云的端到端网络成为主流,典型代表包括:
| 方法 | 关键思路 | 适用场景 |
|---|---|---|
| PointNet / PointNet++ | 直接对原始点云做对称函数聚合,捕获全局/局部特征 | 小规模点云、实时检测 |
| Voxel‑based(SECOND、VoxelNet) | 将点云离散为体素,使用 3D 卷积提取特征 | 大规模点云、工业级检测 |
| PointPillars | 将点云投影为柱状(Pillar),使用 2D 卷积实现高效检测 | 实时性要求高的车规级系统 |
| PV‑RCNN、CenterPoint | 先生成候选框(Region Proposal),再进行精细回归 | 高精度 3D 检测 |
| Transformer‑based(CT3D、DETR‑3D) | 用自注意力建模点云全局关系,提升对稀疏点云的感知能力 | 复杂城市道路、长距离检测 |
| BEV‑Fusion(BEVFormer、OccNet) | 将点云映射到鸟瞰视角(BEV),与摄像头特征融合,统一完成检测、分割、占用预测 | 多模态感知、占用网格生成 |
这些网络大多在公开数据集(KITTI、nuScenes、Waymo Open Dataset)上取得了 70% 以上的 3D mAP,已在多家车企的感知堆栈中落地。
BEV(Bird‑Eye‑View)与占用网格
-
BEV 表示:把点云投射到水平面上形成稠密的鸟瞰图,便于使用 2D 卷积进行多任务学习(检测、分割、路径规划)。
-
占用网格(Occupancy Grid):在 BEV 上生成每个格子的占用概率,常用于路径规划和安全冗余。最新的 0‑CC 占用网络 通过 Transformer 直接输出高分辨率占用图,已在 L4 级无人车中验证。
多模态融合
车载感知往往采用 激光雷达 + 摄像头 + 毫米波雷达 的组合,以弥补单一传感器的局限。常见融合方式:
-
早期融合:在原始点云或图像上进行投影配准后一起送入网络(如 PointPainting、FusionPainting)。
-
中期融合:分别提取 LiDAR 与摄像头特征,再在特征层面进行注意力或跨模态 Transformer 融合。
-
后期融合:独立检测后在决策层进行结果级融合(如 NMS、置信度加权)。
商业实现方面,速腾聚创 HyperVision 系列 已实现低算力(<0.5 TOPS)下的多模态感知,支持目标检测、可行驶区分割等功能;九识智能 则在 L4 货运车上采用车规级固态 LiDAR + 双目视觉 + 大模型融合,实现了高效的 4D 感知。
动态目标跟踪与预测
-
基于卡尔曼/扩展卡尔曼滤波 的多目标跟踪(MOT)是最常见的实时方案。
-
基于图优化或深度学习的轨迹预测(如 LSTM、Transformer)能够对目标的未来运动进行 0.5 s--2 s 的预测,为规划提供安全余量。
-
4D 检测(Spatio‑Temporal):在点云序列上直接学习时空特征,输出带速度的 3D 框,已在 Waymo Open Dataset 中取得领先成绩。
常用开源平台与商业实现
| 平台/工具 | 特色 | 适用范围 |
|---|---|---|
| Autoware | 完整的 ROS‑based 自动驾驶感知堆栈,内置点云分割、聚类、3D 检测(CenterPoint)等模块 | 学术研究、教学、原型验证 |
| OpenPCDet | 开源的点云检测框架,支持 PointPillars、SECOND、PV‑RCNN 等多种模型 | 研发实验、模型对比 |
| PCL(Point Cloud Library) | 传统几何处理库,提供滤波、配准、分割等基础算法 | 低算力嵌入式或算法原型 |
| 商业感知套件(如 HyperVision、LidarSense) | 已优化的端到端感知流水线,兼容车规级硬件,提供 API 与 SDK | 整车厂、ADAS 供应商 |
发展趋势与挑战
-
固态 LiDAR 与千元化:成本下降促使多激光雷达冗余布局,提升感知可靠性。
-
Transformer‑BEV 与 Occupancy‑Net:统一感知与占用预测,支持端到端规划决策。
-
大模型跨模态融合:利用预训练的多模态大模型(如 CLIP‑3D)进行少样本学习,降低标注成本。
-
实时性与算力平衡:在车规级芯片(如 Orin X)上实现 0.5 TOPS 级别的高精度检测仍是关键挑战。
-
极端天气鲁棒性:雨、雾、雪等环境仍是激光雷达感知的薄弱环节,需要融合雷达、摄像头以及自适应噪声抑制算法。
小结
车载激光雷达感知算法已经从最初的几何分割、聚类演进到基于深度学习的端到端 3D 检测、BEV 融合以及多模态大模型。传统方法在去噪、地面分割等前置环节仍发挥重要作用;而高精度、实时性的需求推动了 PointPillars、CenterPoint、Transformer‑BEV 等新技术的落地。结合商业套件(HyperVision、九识智能)和开源平台(Autoware、OpenPCDet),开发者可以在不同算力约束下快速构建完整的感知系统。未来的重点在于 算力‑感知‑安全三位一体的协同优化,以及 跨模态大模型 在极端工况下的鲁棒提升。
3、Radar感知算法
雷达原始输出通常是稀疏的目标点(PointCloud)或目标列表(Object List)。
-
聚类 (Clustering):
-
如 DBSCAN 算法。将雷达打在同一辆车上的多个反射点归为同一个物体。
-
目标跟踪 (Tracking) - 核心算法:
-
卡尔曼滤波 (Kalman Filter / EKF): 预测目标的下一时刻位置,平滑速度测量值。
-
数据关联 (Data Association): 如匈牙利算法 (Hungarian Algorithm)。判断这一帧的雷达点是上一帧的哪辆车,防止ID跳变。
-
静止目标抑制:
-
通过速度阈值过滤掉护栏、路灯等静止物体(对于ACC/AEB至关重要)。
-
4D 雷达算法 (新兴):
-
处理类似 LiDAR 的点云,使用类似 PointPillars 的网络进行 3D 检测。
- 信号预处理(Signal‑Level Processing)
| 步骤 | 关键技术 | 说明 |
|---|---|---|
| Range‑FFT | 对每个 chirp 的采样序列做一维 FFT,得到距离维谱 | 基本的距离分辨率实现方式 |
| Doppler‑FFT | 对同一目标在多个 chirp 上的回波做二次 FFT,得到速度(多普勒)维谱 | 通过多普勒频移直接估算目标相对速度 |
| Angle‑FFT / DOA | 对天线阵列的相位差做 FFT、MUSIC、ESPRIT 等方向估计,得到方位角/俯仰角 | 4‑D(Range、Velocity、Azimuth、Elevation)点云的生成关键 |
| MTI / 静态目标抑制 | 零速度通道置零或基于相位差的移动目标指示(MTI)算法,剔除静止背景 | |
| 去噪 & 滤波 | 小波、经验模态分解(EMD)等时频去噪手段,提升信噪比 | 对抗强噪声环境尤其有效 |
最新趋势:压缩感知(CS)与超分辨率技术被用于在保持硬件成本不变的前提下提升角分辨率,典型实现方式包括稀疏重建、相位编码 FMCW 等。
- 目标检测与聚类
| 方法 | 典型实现 | 适用场景 |
|---|---|---|
| CFAR(恒虚警率) | 基于局部噪声统计自适应阈值,区分真实回波与噪声 | FMCW 雷达的标准检测模块 |
| DBSCAN / 密度聚类 | 对 Range‑Doppler‑Angle 三维点云进行密度聚类,自动分离多目标 | 适用于目标数量不确定、形状不规则的场景 |
| 基于机器学习的分类器 | SVM、随机森林、决策树等对提取的特征(RCS、速度、形状)进行目标类别判别 | 行人、车辆、障碍物等细分任务 |
| 深度学习检测网络 | PointNet、VoxelNet、3D‑CNN、Transformer‑based 检测头(如 Radar‑RCNN) | 端到端点云检测,能够捕获复杂空间关系 |
实用提示:在资源受限的车载平台上,常采用 CFAR + DBSCAN + 轻量级 SVM 的组合,以兼顾实时性与检测精度。
- 目标跟踪
| 算法 | 核心思想 | 备注 |
|---|---|---|
| 卡尔曼滤波(KF) | 线性高斯模型下的递推估计,适用于单目标或低交互目标 | 基础且计算量低 |
| 扩展卡尔曼滤波(EKF) / 无迹卡尔曼滤波(UKF) | 处理非线性运动模型(如转弯) | 在高速转向场景中表现更好 |
| 多假设跟踪(MHT) | 同时维护多条轨迹假设,解决目标交叉/遮挡 | 计算复杂度高,适用于后端服务器或高算力 ECU |
| 基于深度学习的关联网络 | 使用 Siamese / Transformer 关联特征,实现端到端的多目标跟踪 | 近年研究热点,已在部分高阶 AD 系统中验证 |
融合策略:将雷达的距离/速度信息与视觉的外观特征进行 跨模态关联,可显著提升遮挡情况下的跟踪鲁棒性。
- 高层感知与多传感器融合
| 融合层级 | 典型方法 | 关键收益 |
|---|---|---|
| 低层融合(原始点云) | 直接将雷达点云与激光点云、摄像头深度图拼接,统一坐标系后做聚类/检测 | 提升空间分辨率、补偿雷达角度粗糙度 |
| 特征层融合 | 对雷达的速度特征、视觉的纹理特征分别抽取后在网络中拼接(如 BEV‑Fusion) | 兼顾速度估计的准确性与视觉的语义信息 |
| 决策层融合 | 各传感器独立检测后,用贝叶斯或投票机制融合结果 | 简单、易于验证,适用于安全关键的冗余设计 |
| 时序融合(SLAM) | 将雷达的距离/速度信息与视觉/里程计的位姿估计结合,构建 4‑D 环境地图 | 支持长期定位、路径规划,已在部分车企的 ASSAR300 成像雷达中实现 |
最新进展:基于 Transformer 的跨模态注意力机制能够在统一的 BEV(鸟瞰视图)空间中自适应加权雷达与摄像头特征,显著提升远距离小目标检测率。
- 超分辨率与压缩感知(Super‑Resolution & Compressive Sensing)
-
压缩感知(CS):利用信号稀疏性在采样阶段就降低数据量,再通过稀疏重建恢复高分辨率图像。行易道的 ASSAR300 采用 CS‑SAR 成像,实现 < 1° 角分辨率、每秒 > 10 k 点云。
-
MUSIC / ESPRIT / MVDR:基于阵列信号的高分辨率 DOA 估计,可在不增加硬件天线数的情况下提升角度分辨率。
-
相位编码 FMCW:通过伪随机相位码降低同频干扰,同时提升距离分辨率。
- 抗干扰与鲁棒性提升
| 干扰类型 | 对策 | 参考 |
|---|---|---|
| 同频干扰 | 采用相位编码 FMCW、伪随机循环正交序列 | |
| 异频干扰 | 频谱抑制、时域门控、干扰信号模型估计后滤除 | |
| 噪声抑制 | 小波/EMD 去噪、机器学习噪声分类器 | |
| 硬件非理想 | 校准误差补偿、温度漂移自适应校正 | 行业报告中提及的硬件校准技术(未列出具体文献) |
-
实际部署建议
-
模块化流水线:在 ECU 中实现 FFT → CFAR → DBSCAN → KF 的硬件加速路径,满足 10 Hz--20 Hz 实时需求。
-
软硬件协同:利用 压缩感知 减少 ADC 采样率,配合 DSP/FPGA 完成稀疏重建,降低功耗(7 W 左右)。
-
多模态融合:在高阶 AD(L3/L4)系统中,建议采用 特征层融合 + Transformer,兼顾雷达的速度优势与摄像头的语义信息。
-
安全冗余:关键感知任务(如前向碰撞预警)应保留 雷达+摄像头双通道,并在决策层使用贝叶斯融合实现容错。
车载毫米波雷达的感知算法已经从传统的 FFT‑CFAR‑KF 流程,演进到 机器学习/深度学习‑压缩感知‑跨模态融合 的综合体系。当前的研究热点集中在:
-
超分辨率与压缩感知(提升角分辨率、降低硬件成本)
-
深度学习点云检测(端到端 4‑D 目标检测)
-
抗干扰编码(相位编码 FMCW、伪随机序列)
-
雷达‑视觉融合(自适应特征融合、Transformer)
这些技术的组合能够在保证实时性、低功耗的前提下,实现更高的检测精度和鲁棒性,为 L2‑L4 级自动驾驶提供可靠的感知支撑。
4、USS感知算法
超声波通常不使用深度学习,主要靠几何计算。
-
三角定位 (Triangulation):
-
利用相邻两个探头探测同一障碍物的距离差,计算障碍物的 (x,y)(x,y) 坐标。
-
空间车位构建 (Slot Searching):
-
在车辆行驶过程中,将超声波探测到的路沿、旁边车辆的边缘连接起来,拟合出空闲车位(垂直/平行/斜列)的矩形框。
-
最近点跟踪:
-
泊车过程中,实时计算障碍物离车身最近点的距离,用于刹车决策。
- 基本工作原理
超声波雷达通过压电换能器发射 20 kHz 以上的超声波,声波在空气中往返的时间直接决定障碍物距离(TOF)。声速随环境温度变化,需要实时温度补偿,常用公式 C = 332 + 0.607 × T(T 为摄氏度)。
-
信号预处理
-
去噪与滤波:采用带通滤波抑制低频噪声和高频干扰;对回波进行峰值检测,提取有效回波。
-
时序校正:在多探头阵列中,使用动态时序调整(如专利 CN202210851075.5)同步各通道的发射/接收时刻,降低误报率。
-
增益补偿:针对不同工作距离的衰减,采用深度增益补偿电路或软件增益映射,保证远距离回波仍可被检测。
-
距离与角度估计
-
距离:利用 TOF 直接计算,误差控制在 ±0.5 m 以内。
-
角度:单探头只能测距,需通过 多探头阵列(2--8 个)实现波束形成或相位差法估算方位角。
- 回波特征提取与障碍物判别
| 步骤 | 典型方法 | 说明 |
|---|---|---|
| 时域特征 | 峰值幅度、上升沿、回波宽度 | 区分硬质障碍(如金属)与软质障碍(如塑料) |
| 频域特征 | FFT 能谱、谐波结构 | 用于识别回波多径或干扰信号 |
| 机器学习 | SVM、随机森林、轻量化 CNN(1‑D 卷积) | 训练分类模型对回波进行 静态/动态、车/人/障碍物 区分 |
- 多目标检测与聚类
-
阈值分割:先对距离点云进行阈值过滤(如 0.2--3 m),得到原始点集合。
-
聚类:常用 DBSCAN、Mean‑Shift 或基于欧氏距离的层次聚类,将相邻回波归为同一目标。
-
形状建模:对聚类结果进行最小外接矩形或椭圆拟合,得到目标的 宽高 信息,进而用于车位检测。
-
动态障碍过滤与跟踪
-
速度阈值:对连续帧的距离变化率进行计算,若 v > 0.5 m/s 则标记为动态障碍物。
-
卡尔曼滤波:对每个目标的状态(位置、速度)进行递归估计,平滑噪声并预测短期轨迹。
-
粒子滤波:在复杂环境(多回波叠加、遮挡)下使用粒子滤波提升鲁棒性。
-
传感器融合
超声波雷达的探测范围短、分辨率低,通常与 摄像头、毫米波雷达、激光雷达 进行融合。融合策略包括:
-
时间同步:统一时间戳,保证多源数据的对应关系。
-
坐标统一:将超声波点云转换到车辆坐标系,再与其他传感器的点云或图像特征进行配准。
-
融合算法:基于贝叶斯滤波或深度学习的 多模态特征融合网络,提升低速泊车、盲区检测的感知精度。
- 高层感知与应用
-
泊车辅助(APA/AVP):利用超声波点云生成 占用网格(Occupancy Grid),配合路径规划实现自动泊车。
-
盲区监测:在车辆侧后方布置 4--6 个探头,实时检测侧后方障碍物并触发声光警示。
-
车位检测:基于聚类与几何拟合,自动识别车位起止点并输出车位尺寸,已在多家车企的泊车系统中落地。
-
前沿研究与趋势
-
压缩感知与超分辨:在不增加硬件成本的前提下,利用稀疏约束实现更高分辨率的超声波成像。
-
深度学习端到端感知:将原始回波波形直接输入轻量化卷积网络,输出障碍物类别与位置,显著降低传统特征工程的复杂度。
-
自适应时序调度:根据环境噪声水平动态调整发射频率和采样窗口,提高在雨雪等恶劣天气下的可靠性。
-
全链路数据闭环:通过车端采集、云端标注、模型迭代,实现超声波感知算法的持续优化,已成为车企提升感知能力的关键手段。
-
实际部署要点
| 项目 | 关键实现 | 注意事项 |
|---|---|---|
| 硬件选型 | 40 kHz ~ 80 kHz 超声波换能器,支持多通道阵列 | 确保防水、防尘,满足汽车级可靠性 |
| 实时性 | 采样频率 ≥ 200 kHz,处理延时 ≤ 10 ms | 采用 MCU/FPGA 并行处理或专用 DSP |
| 温度补偿 | 实时读取车内/车外温度,动态更新声速 | 防止温度剧变导致距离误差 |
| 软件架构 | 分层结构:驱动 → 预处理 → 特征提取 → 检测/跟踪 → 融合 | 便于后期算法升级与功能扩展 |
| 安全验证 | 通过 ISO 26262 功能安全评估,设定冗余检测阈值 | 超声波失效时自动切换至其他传感器 |
结语 车载超声波雷达凭借成本低、近距离感知强的优势,已成为泊车、盲区监测等低速场景的核心传感器。其感知算法从最底层的信号预处理、距离/角度估计,到中层的回波特征分类、聚类、跟踪,再到高层的多传感器融合与决策,形成了完整的技术链路。随着压缩感知、深度学习以及全链路数据闭环的持续突破,超声波雷达的感知精度与鲁棒性正快速提升,未来将在更广泛的 ADAS 与 L2‑L3 级别自动驾驶系统中发挥更大作用。
5、总结
感知算法的数据流向
-
原始数据输入: 图像(Pixels)、点云(Points)、脉冲(Signals)。
-
特征提取 (Backbone): 通过 CNN/Transformer 提取特征。
-
视角转换 (Neck): 将 2D 图像特征转为 3D BEV 特征。
-
多模态融合 (Fusion): 拼接视觉、雷达、LiDAR 的特征。
-
检测头 (Head): 输出目标框、速度、类别。
-
跟踪与预测: 分配 ID,预测未来 3-5 秒的轨迹。
-
输出: 完整的环境模型 (Environmental Model) 给规划控制模块。