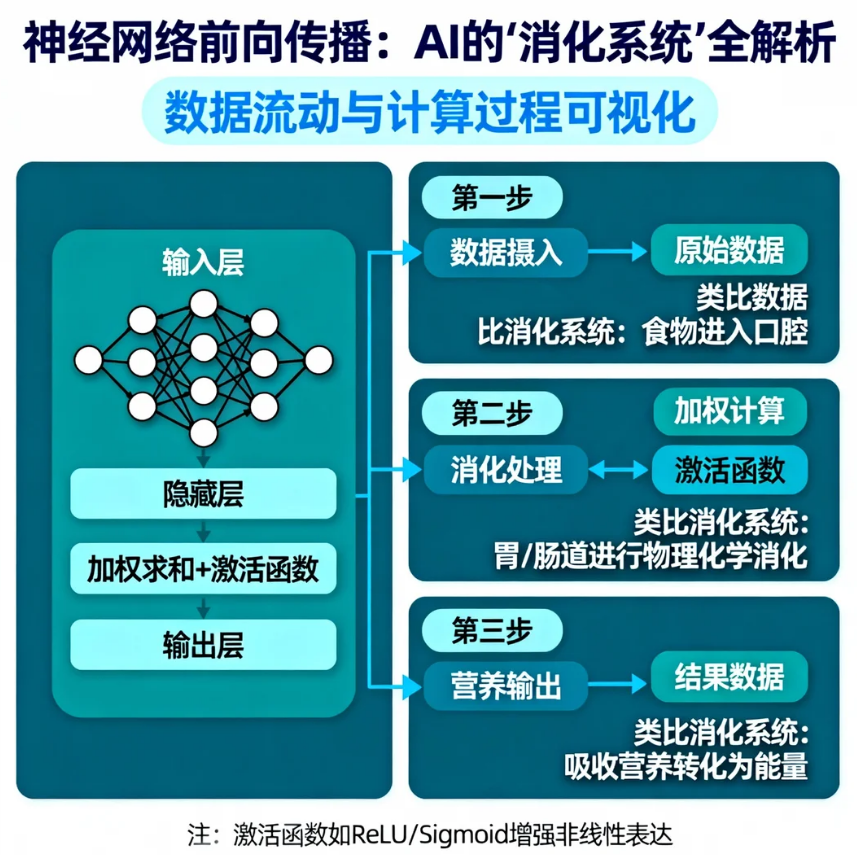
引言:从"认猫"说起
想象你第一次教孩子认猫:
- 你指着一只猫说:"这是猫"
- 孩子看到:尖耳朵、长胡子、圆眼睛、毛茸茸
- 大脑把这些特征组合起来
- 形成"猫"的概念
前向传播就是神经网络的这个"看→思考→判断"过程。
第一部分:从神经元到网络
1.1 神经元:网络的"味蕾"
每个神经元就像舌头上的一个味蕾:
python
# 伪代码:一个神经元的工作
def 神经元(输入信号):
1. 收集信号:耳朵信号 + 胡子信号 + 眼睛信号
2. 加权计算:耳朵×0.8 + 胡子×0.6 + 眼睛×0.9
3. 加上偏置:+0.1(容易兴奋)
4. 判断是否激活:如果总和 > 0.5,就"兴奋"
5. 输出兴奋程度:0.7(很可能是猫!)关键参数解释:
- 权重 :每个特征的重要程度
- 猫耳朵权重高(0.8),猫尾巴权重低(0.2)
- 偏置 :神经元的"兴奋阈值"
- 负偏置:懒得动,需要强信号才兴奋
- 正偏置:容易兴奋,微弱信号就激动
1.2 前向传播的直观比喻:流水线工厂
想象一个汽车工厂的装配线:
plain
原材料(钢板、轮胎) → 冲压车间 → 焊接车间 → 喷漆车间 → 整车
↓ ↓ ↓ ↓ ↓
输入层 隐藏层1 隐藏层2 隐藏层3 输出层每一层都做特定加工:
- 第一层:识别边缘(车轮是圆的,车窗是方的)
- 第二层:组合成部件(车轮+车轴=轮子)
- 第三层:识别对象(轮子+车厢=汽车)
- 输出层:分类(是轿车/卡车/摩托车)
第二部分:单层网络的前向传播(手把手计算)
2.1 最简单的例子:判断水果是苹果还是橙子
已知:
- 特征1:直径(苹果大,橙子小)
- 特征2:颜色红度(苹果红,橙子橙)
plain
输入:直径=8cm, 红度=0.7
权重:[0.6, 0.4] # 直径比颜色更重要
偏置:-3 # 不容易判断为苹果计算步骤:
python
# 步骤1:线性组合
z = (8 × 0.6) + (0.7 × 0.4) + (-3)
= 4.8 + 0.28 - 3
= 2.08
# 步骤2:通过激活函数(Sigmoid)
a = 1 / (1 + e^{-2.08})
≈ 1 / (1 + 0.125) # e^{-2.08} ≈ 0.125
≈ 1 / 1.125
≈ 0.89
# 结果:89%概率是苹果!2.2 激活函数:神经元的"性格"
为什么需要激活函数?因为没有它,多层网络等于单层!
常见激活函数:
| 函数 | 公式 | 比喻 | 适合场景 |
|---|---|---|---|
| Sigmoid | 1/(1+e^{-x}) | 温和派,总是给面子(输出0~1) | 概率输出、二分类 |
| Tanh | (e^x - e{-x})/(ex + e^{-x}) | 激进派,爱恨分明(输出-1~1) | 中间隐藏层 |
| ReLU | max(0, x) | 实干家,负能量直接归零 | 大多数隐藏层 |
| Leaky ReLU | max(0.01x, x) | 宽容的实干家,给负能量一点机会 | 防止神经元"死亡" |
可视化理解:
plain
输入信号 → 神经元 → 激活函数 → 输出信号
↓ ↓ ↓ ↓
水流 → 水桶 → 水阀 → 流出的水
- Sigmoid:缓慢打开的水阀
- ReLU:要么全开,要么全关的水阀第三部分:多层网络前向传播(深入核心)
3.1 真实例子:识别手写数字"8"
假设我们要识别这个"8":
plain
###
# #
###
# #
###网络结构(3层):
plain
输入层(784像素) → 隐藏层(128神经元) → 输出层(10数字)详细计算过程:
第1步:输入层 → 隐藏层
python
# 输入:784个像素的亮度值(0~1)
X = [0.1, 0.9, 0.2, ..., 0.8] # 784维
# 隐藏层第1个神经元计算
z1 = (w11×x1 + w12×x2 + ... + w1,784×x784) + b1
a1 = ReLU(z1) # 如果z1>0则输出z1,否则0
# 所有128个神经元都这样计算
Z1 = W1·X + b1 # 矩阵乘法(128×784)·(784×1)
A1 = ReLU(Z1) # 得到128个激活值第2步:隐藏层 → 输出层
python
# 现在A1有128个值
Z2 = W2·A1 + b2 # (10×128)·(128×1)
A2 = softmax(Z2) # 转换为概率分布Softmax函数:把分数变成概率
plain
原始分数:[2.0, 1.0, 0.1] # 分别对应数字8, 3, 5
softmax后:[0.66, 0.24, 0.10] # 总和为1的概率
# 66%概率是8!3.2 向量化计算:批量处理的魔法
现实中我们一次处理多个样本(比如32张图片):
python
# 单个样本(慢)
for i in range(32):
output[i] = W·input[i] + b
# 批量处理(快!利用GPU并行)
# X形状:(784, 32) # 32个样本,每个784维
# W形状:(128, 784)
Z = np.dot(W, X) + b # 一次计算所有!
# Z形状:(128, 32) # 32个样本的128个神经元输出效率对比:
- 循环:32次矩阵乘法
- 向量化:1次更大的矩阵乘法(快10-100倍!)
第四部分:前向传播的细节与技巧
4.1 权重初始化:好的开始是成功的一半
错误的初始化:
python
W = np.zeros((128, 784)) # 全零 → 所有神经元学一样的东西
W = np.random.randn(128, 784) # 太大 → 梯度爆炸正确的初始化:
python
# Xavier初始化(适合Sigmoid/Tanh)
W = np.random.randn(128, 784) * np.sqrt(1/784)
# He初始化(适合ReLU)
W = np.random.randn(128, 784) * np.sqrt(2/784)物理意义:保证信号在前传过程中强度适中,既不会消失也不会爆炸。
4.2 前向传播中的归一化技术
批量归一化:让每层的输入保持稳定
python
# 传统
z = W·a + b
a_next = activation(z)
# 批量归一化
z = W·a
z_norm = (z - mean(z)) / std(z) # 归一化
z_scaled = γ·z_norm + β # 可学习的缩放和平移
a_next = activation(z_scaled)好处:
- 训练更快更稳定
- 对初始化不敏感
- 有轻微正则化效果
4.3 前向传播的变体:残差连接
问题:网络太深时,信号会衰减
解决方案:跳过连接
python
# 传统
a_l+1 = f(W·a_l + b)
# 残差网络
a_l+1 = f(W·a_l + b) + a_l # 加上原始输入比喻:写文章时保留初稿,每次修改都在原稿基础上进行。
第五部分:代码实战(从零实现)
5.1 用NumPy实现完整前向传播
python
import numpy as np
class NeuralNetwork:
def __init__(self, layer_dims):
"""
参数: layer_dims = [784, 128, 64, 10]
输入784,隐藏层128和64,输出10
"""
self.layer_dims = layer_dims
self.parameters = {}
self.L = len(layer_dims) - 1 # 层数
# 初始化权重和偏置
np.random.seed(42)
for l in range(1, self.L + 1):
# He初始化
self.parameters[f'W{l}'] = np.random.randn(
layer_dims[l], layer_dims[l-1]) * np.sqrt(2/layer_dims[l-1])
self.parameters[f'b{l}'] = np.zeros((layer_dims[l], 1))
def relu(self, Z):
"""ReLU激活函数"""
return np.maximum(0, Z)
def sigmoid(self, Z):
"""Sigmoid激活函数"""
return 1 / (1 + np.exp(-Z))
def softmax(self, Z):
"""Softmax激活函数"""
exp_Z = np.exp(Z - np.max(Z)) # 防止溢出
return exp_Z / np.sum(exp_Z, axis=0, keepdims=True)
def forward(self, X):
"""
前向传播主函数
X形状: (输入维度, 样本数)
返回: 最后一层的输出和缓存(用于反向传播)
"""
caches = []
A = X
# 隐藏层:L-1层使用ReLU
for l in range(1, self.L):
W = self.parameters[f'W{l}']
b = self.parameters[f'b{l}']
Z = np.dot(W, A) + b
A = self.relu(Z)
# 缓存用于反向传播
caches.append((Z, A, W, b))
# 输出层:使用Softmax
W = self.parameters[f'W{self.L}']
b = self.parameters[f'b{self.L}']
Z = np.dot(W, A) + b
AL = self.softmax(Z)
caches.append((Z, AL, W, b))
return AL, caches
def predict(self, X):
"""预测函数"""
AL, _ = self.forward(X)
predictions = np.argmax(AL, axis=0) # 取概率最大的类别
return predictions
# 使用示例
if __name__ == "__main__":
# 1. 创建网络(识别MNIST手写数字)
nn = NeuralNetwork([784, 256, 128, 10])
# 2. 模拟输入数据(100张28x28图片)
X_sample = np.random.randn(784, 100) # 100个样本
# 3. 前向传播
predictions, caches = nn.forward(X_sample)
# 4. 查看结果
print("网络结构:", nn.layer_dims)
print(f"输入形状: {X_sample.shape}")
print(f"输出形状: {predictions.shape}")
print(f"第一个样本的预测概率分布:")
print(predictions[:, 0]) # 10个数字的概率
print(f"预测数字: {np.argmax(predictions[:, 0])}")
# 5. 批量预测
pred_classes = nn.predict(X_sample)
print(f"\n前10个样本的预测结果: {pred_classes[:10]}")5.2 逐行解释关键代码
python
# 最重要的三行:前向传播核心
Z = np.dot(W, A) + b # 线性变换
A = self.relu(Z) # 非线性激活
AL = self.softmax(Z) # 输出层特殊处理
# np.dot(W, A) 的维度检查:
# W形状: (下一层大小, 当前层大小) 如 (128, 784)
# A形状: (当前层大小, 样本数) 如 (784, 100)
# 结果: (128, 100) ← 100个样本的128个神经元输出
# 为什么A要转置?不用!因为W已经在设计时考虑了5.3 可视化前向传播
python
import matplotlib.pyplot as plt
def visualize_activations(X_sample, nn):
"""可视化各层激活值"""
A_current = X_sample
activations = [A_current]
for l in range(1, nn.L + 1):
W = nn.parameters[f'W{l}']
b = nn.parameters[f'b{l}']
Z = np.dot(W, A_current) + b
if l == nn.L: # 输出层
A_current = nn.softmax(Z)
else: # 隐藏层
A_current = nn.relu(Z)
activations.append(A_current)
# 绘制
fig, axes = plt.subplots(1, len(activations), figsize=(15, 3))
for i, (ax, A) in enumerate(zip(axes, activations)):
# 只显示第一个样本
ax.imshow(A[:, 0:1], aspect='auto', cmap='viridis')
ax.set_title(f'Layer {i}')
ax.set_xlabel('Samples')
ax.set_ylabel('Neurons')
plt.tight_layout()
plt.show()
# 运行可视化
visualize_activations(X_sample[:, :5], nn) # 只看前5个样本第六部分:实际应用与高级话题
6.1 卷积神经网络(CNN)的前向传播
CNN专门处理图像,使用卷积核扫描:
python
def conv_forward(A_prev, W, b):
"""
A_prev: 输入图像 (高度, 宽度, 通道数, 样本数)
W: 卷积核 (核高, 核宽, 输入通道, 输出通道)
b: 偏置 (1, 1, 1, 输出通道)
"""
# 1. 卷积操作
Z = conv(A_prev, W) + b
# 2. 激活
A = relu(Z)
# 3. 池化(下采样)
A_pool = max_pool(A)
return A_pool卷积的直观理解:
plain
原图:5×5 → 卷积核3×3扫描 → 特征图3×3
就像用手电筒在黑暗中扫描图案6.2 循环神经网络(RNN)的前向传播
RNN处理序列数据(如文本、时间序列):
python
def rnn_forward(X, h_prev, W, U, b):
"""
X: 当前时间步输入
h_prev: 上一个时间步的隐藏状态
W: 输入权重
U: 循环权重
b: 偏置
"""
# RNN核心公式
Z = np.dot(W, X) + np.dot(U, h_prev) + b
h = np.tanh(Z) # 新的隐藏状态
y = np.dot(V, h) + c # 输出
return h, y物理意义:每个时间步都考虑之前的记忆(h_prev)
6.3 前向传播的优化技巧
1. 混合精度训练:
python
# 使用半精度浮点数,更快更省内存
X_half = X.astype(np.float16)
# 关键计算用全精度,防止精度丢失
Z = np.dot(W.astype(np.float32), X_half.astype(np.float32))2. 计算图优化:
python
# 融合操作:减少内存访问
# 传统:conv → relu → pool
# 融合:conv_relu_pool (一次完成)3. 惰性计算:
python
# 不立即计算所有,需要时才计算
if need_gradient:
compute_full_graph()
else:
compute_only_forward()第七部分:常见问题解答
Q1:为什么要多层?一层不行吗?
A:单层网络只能学习线性关系,多层才能学习复杂模式。
- 例子:单层无法区分两个嵌套的圆圈(XOR问题)
- 但两层就可以!这就是"万能近似定理"
Q2:网络越深越好吗?
A:不一定!太深会带来:
- 梯度消失/爆炸
- 过拟合
- 训练困难
- 实践中:ResNet(152层)效果很好,但不是无限深
Q3:前向传播会出错吗?
A:会的!常见错误:
- 形状不匹配:矩阵乘法维度不对
- 数值溢出:exp(x)太大导致NaN
- 激活函数饱和:Sigmoid在极大/极小值时梯度为0
调试技巧:
python
# 添加检查点
assert Z.shape == (layer_dims[l], X.shape[1])
assert not np.any(np.isnan(Z))
assert np.abs(Z).mean() < 100 # 检查数值范围Q4:前向传播需要多少计算量?
A:以GPT-3为例:
- 参数:1750亿
- 一次前向传播:约3500亿次浮点运算
- 相当于:用计算器按3500亿次按钮!
第八部分:学习路径与资源
8.1 从理解到掌握的四步曲
- 直觉理解 (已完成)
- 用比喻理解前向传播
- 可视化网络结构
- 手动计算
python
# 用计算器或纸笔计算
输入 → 权重 → 求和 → 激活 → 输出- 代码实现
- 实现单神经元
- 实现单层网络
- 实现多层网络
- 实际应用
- 在真实数据集(MNIST)上运行
- 尝试不同激活函数
- 调整网络深度和宽度
8.2 推荐练习项目
初级:
- 用神经网络预测房价(线性回归)
- 手写数字识别(MNIST)
- 鸢尾花分类
中级:
- 猫狗图片分类
- 电影评论情感分析
- 股价预测
高级:
- 自己实现CNN识别CIFAR-10
- 实现简单Transformer
- 训练生成对抗网络(GAN)
8.3 实用工具推荐
- 可视化工具 :
- TensorBoard(PyTorch/TensorFlow)
- Netron(模型结构可视化)
- https://playground.tensorflow.org/
- 学习平台 :
- Coursera:吴恩达深度学习
- 动手学深度学习(中文,有代码)
- PyTorch官方教程
- 调试工具 :
- PyTorch的
torchsummary - 梯度检查函数
- 激活值分布可视化
- PyTorch的
结语:前向传播的哲学思考
前向传播不仅仅是数学计算,它体现了信息加工的哲学:
- 分层抽象:
plain
像素 → 边缘 → 部件 → 物体 → 概念
(从具体到抽象,从细节到整体)- 分布式表示 :
- 不是"一个神经元对应一个概念"
- 而是"一群神经元的模式表示一个概念"
- 非线性创造可能:
plain
线性:只能拉伸、旋转
非线性:可以弯曲、折叠、创造新空间最后记住 :前向传播是神经网络消化信息 的过程,而反向传播是学习改进的过程。两者结合,才让AI从"人工智障"变成"人工智能"。
终极挑战:你能回答吗?
- 生活题 :用做菜比喻多层前向传播
(提示:食材→切配→炒制→调味→装盘) - 计算题:输入1, 2, 3,权重0.1, 0.2, 0.3,偏置0.5,用ReLU激活,输出是多少?
- 思考题:如果所有权重都是0,前向传播输出是什么?网络还能学习吗?
答案速查:
- 原始食材(输入)→ 切配(边缘检测)→ 炒制(特征组合)→ 调味(高层抽象)→ 装盘(输出分类)
- z = 1×0.1 + 2×0.2 + 3×0.3 + 0.5 = 1.9,ReLU(1.9) = 1.9
- 输出全是偏置,没有区分能力;不能学习,因为梯度全为零
现在,你已经理解了神经网络如何"思考"。下一步就是学习它如何"学习"(反向传播)。但记住:没有前向传播,就没有学习的基础。