TL;DR
- 场景:用"十杯红酒辨别品种"引出分类问题,串起机器学习的核心概念与流程。
- 结论:监督/无监督/半监督/强化学习的差异本质在"标签、反馈信号与目标函数"。
- 产出:一份可直接用于入门复盘的概念框架:特征空间→建模→评估→过拟合治理→算法选型。
版本矩阵
| 属性 | 说明 |
|---|---|
| 已验证说明 | 不适用 |
| 内容定位 | 本文为概念与方法论梳理,不依赖具体代码与框架 API |
| 版本兼容性 | 不绑定版本更利于长期复用参考 |
| 叙述语境 | 默认覆盖 2025 年主流实践(如 scikit-learn、PyTorch 的通用术语与流程),但不声称逐条对齐某个具体版本实现 |
| 可迁移性 | 监督/无监督/强化学习、过拟合/欠拟合、交叉验证等概念在不同语言与框架中定义一致,迁移成本低 |
简单案例
在一个酒吧里,吧台上摆着十杯几乎一样的红酒,老板说想不想玩个游戏,赢了免费喝酒,输了需要付三倍的酒钱。眼前的十杯红酒,每杯都略有不同,前五杯属于【赤霞珠】,后五杯属于【黑皮诺】,现在重新倒一杯酒,你需要正确的说出属于哪一类?
 我的问题 :
我的问题 : 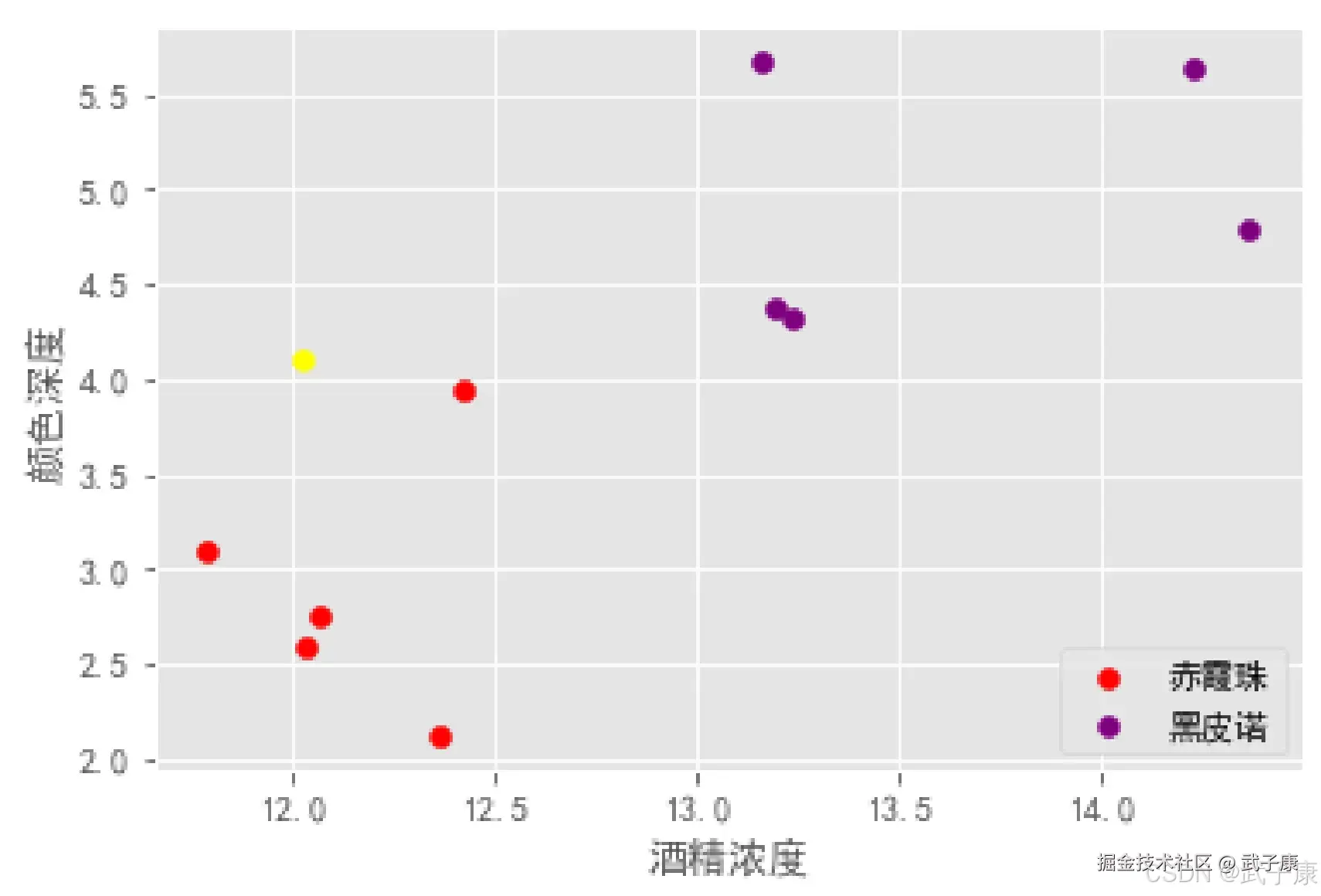
算法体系
机器学习(Machine Learning, ML)是人工智能(AI)的一个分支,旨在通过数据和算法使计算机系统能够像人类一样学习和做出决策,而无需明确编程指令。机器学习的核心是从数据中提取模式,并使用这些模式对新数据进行预测或分类。
机器学习 h的方法是基于数据产生的模型算法,也称学习算法。包括有:
- 有监督学习 (supervised learning)
- 无监督学习(unsupervised learning)
- 半监督学习(semi-supervised learning)
- 强化学习(reinforcement learning)
机器学习是一种基于数据的学习方法,它依赖于大规模数据的分析,通过算法构建模型,使机器能够从数据中学习经验,进行预测、分类、聚类等操作,而无需人工明确设定规则。
有监督学习(Supervised Learning)
指对数据的若干特征与若干标签(类型)之间的关联性进行建模,只要模型被确定,就可以用用到新的未知数据上。 这类学习过程可以进一步为:【分类】classification 任务 和 【回归】regression 任务。
- 分类任务中,标签都是离散值
- 回归任务中,标签都是连续值
监督学习是指算法在训练过程中依赖标注好的数据集。数据集中的每一个样本都有一个对应的正确输出,算法通过这些"输入-输出"对,学习如何从输入数据预测输出。
- 应用:分类问题(如垃圾邮件识别)、回归问题(如房价预测)。
- 常见算法:线性回归、决策树、随机森林、支持向量机(SVM)、神经网络等。
无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning)是机器学习中重要的学习范式之一,其核心特点是不依赖于人工标注的标签数据。与监督学习不同,无监督学习让算法自主探索数据内在的结构和模式,是一种典型的"数据驱动"学习方式。
详细定义
无监督学习通过对未标记数据集的统计分析,自动发现数据中隐藏的模式或结构。这种学习方式模拟了人类通过观察自然现象来发现规律的过程。算法需要从原始数据中提取有意义的特征,而不依赖任何外部指导信号。
主要任务类型
-
聚类(Clustering):
- 目标:将相似的数据点自动分组
- 典型算法:
- K-means聚类:基于距离的经典算法
- 层次聚类:可形成树状聚类结构
- DBSCAN:基于密度的聚类方法
- 应用场景:
- 客户细分(如电商用户分群)
- 文档主题分类
- 异常检测(如信用卡欺诈识别)
-
降维(Dimensionality Reduction):
- 目标:减少特征数量同时保留重要信息
- 典型方法:
- 主成分分析(PCA):线性降维方法
- t-SNE:非线性可视化降维
- 自编码器(Autoencoder):基于神经网络的降维
- 应用场景:
- 高维数据可视化(如基因表达数据)
- 特征工程预处理
- 图像压缩
关键技术特点
- 不需要标注数据,节省人工成本
- 能够发现人类难以察觉的隐藏模式
- 对数据分布不做强假设,适应性较强
- 结果解释性通常较监督学习弱
典型应用领域
- 商业智能:市场篮子分析、用户行为模式挖掘
- 生物信息学:基因表达数据分析
- 计算机视觉:图像特征学习、异常检测
- 自然语言处理:主题建模、词向量学习
算法发展
近年来,无监督学习算法持续创新,特别是:
- 深度生成模型(如GAN、VAE)
- 对比学习(Contrastive Learning)
- 自监督学习(Self-supervised Learning)
这些进展大大拓展了无监督学习的应用边界,使其在缺乏标注数据的场景中展现出巨大价值。
半监督学习
另外,还有一种半监督 semi-supervised leaning 方法,介于有监督学习和无监督学习之间,通过可以在数据不完整的时候使用。
强化学习 (Reinforcement Learning)
强化学习是一种基于试错机制的机器学习方法,与监督学习有着本质区别。监督学习依赖于预先标记的训练数据,而强化学习则是通过与环境的动态交互来学习最优策略。在这个过程中,智能体(agent)通过执行动作(action)与环境(environment)交互,并根据环境反馈的奖励(reward)信号来调整其行为策略。
强化学习的核心机制可以概括为"状态-动作-奖励"的循环:
- 智能体观察当前环境状态(state)
- 根据当前策略选择并执行一个动作
- 环境给出相应的即时奖励和新的状态
- 智能体根据奖励信号更新策略
典型应用场景包括:
- 机器人控制:如机械臂抓取物体时,通过尝试不同动作来学习最优抓取策略
- 自动驾驶:车辆通过模拟环境学习如何安全高效地行驶
- 游戏AI:AlphaGo通过自我对弈不断优化下棋策略
- 资源调度:数据中心通过强化学习优化服务器资源分配
常见算法类型:
-
基于价值的算法(如Q-learning):
- 学习状态-动作价值函数(Q函数)
- 示例:在迷宫游戏中,学习每个位置各个移动方向的价值
-
基于策略的算法(如策略梯度):
- 直接优化策略函数
- 示例:机器人直接学习最优动作选择概率
-
演员-评论家算法:
- 结合价值和策略方法
- 示例:同时学习价值评估和策略改进
深度强化学习(如DQN)将深度神经网络与强化学习结合,能够处理高维状态空间的问题。这类方法在Atari游戏、机器人控制等领域取得了突破性进展。强化学习系统的性能高度依赖于奖励函数的设计,不合理的奖励设置可能导致智能体学习到非预期行为。
输入输出空间与特征空间
在上面的场景中,每一杯酒作为一个样本,十杯就组成一个样本集。酒精浓度、颜色深度等信息称做【特征】。这十杯酒分布式在一个【多维特征空间】中。 进入当前程序的"学习系统"的所有样本称做【输入】,并组成【输入空间】。 在学习过程中,所产生的随机变量的取值,称做【输出】,并组成【输出空间】。 在有监督的学习过程中,当输出变量均为连续变量时,预测问题成为回归问题,当输出量为有限个离散变量时,预测问题称为分类问题。
过拟合和欠拟合
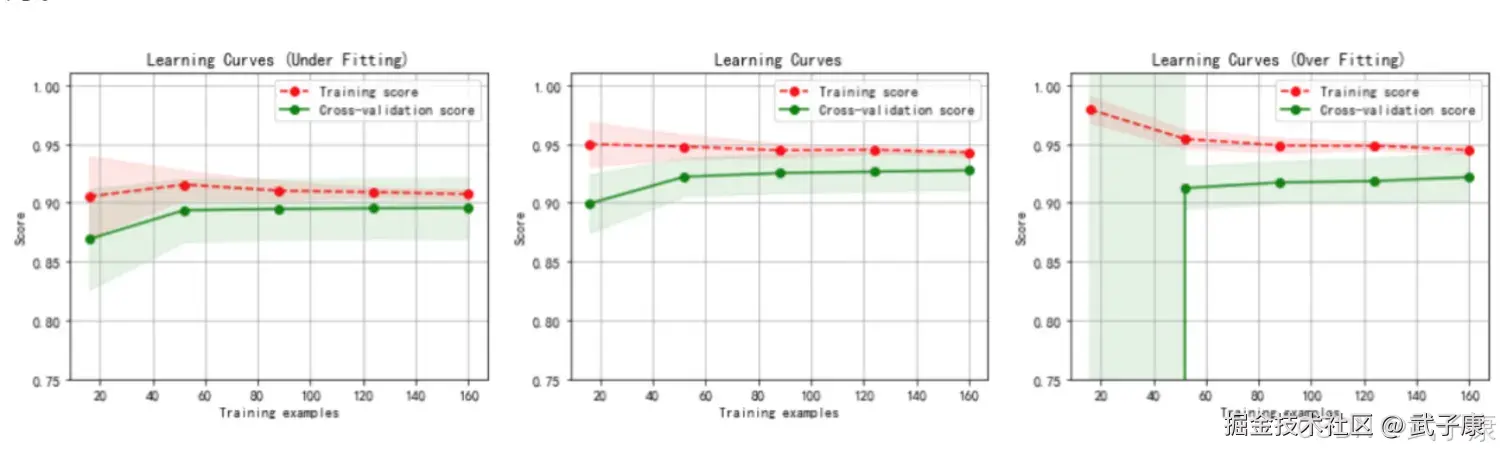
当假设空间中含有不同复杂的模型时,就要面临模型选择的问题。 我们希望获得的新样本上能表现得很好的学习器,为了达到这个目的,我们应该从训练样本中尽可能学习到适用于所有潜在样本的"普遍规律"。 我们认为假设空间存在这种"真"模型,那么所选择的模型应该逼近真模型。 拟合度可以简单理解为模型对与数据集背后客观规律的掌握程度,模型对于给定数据集如果拟合度较差,则对规律的捕捉不完全,用作分类和预测时可能准确率不高。 换句话说,当模型把训练样本学的太好了,很可能已经训练样本本身的一些特点当作所有潜在样本的普遍性质,这时候所选的模型的复杂度往往会比真的模型要高,这样就会导致泛化性能下降,这种现象叫做过拟合(overfitting)。可以说,模型选择皆在避免过拟合并提高模型的预测能力。 与过拟合相对的是欠拟合(under fitting),指在学习能力低下,导致对训练样本的一般性质尚未学好。
- 虚线:针对训练数据集计算出来的分数,即针对训练数据集拟合的准确性。
- 实线:针对交叉数据集计算出来的分数,即针对交叉验证数据集预测的准确性。
上图中【左图】的内容,一阶多项式,欠拟合:
- 训练数据集的准确性(虚线)和交叉验证数据集的准确性(实现)靠的很近,总体水平比较高。
- 随着训练数据集的增加,交叉验证数据集的准确性(实现)逐渐增大,逐渐和训练数据集的准确性(虚线)靠近,但总体水平比较低,收敛在 0.88 左右。
- 训练数据集的准确性也比较低,收敛在 0.90 左右
- 当发生高偏差时,增加训练样本数量不会对算法准确性有较大的改善
上图中【中图】的内容,三阶多项式,较好拟合了数据集:
- 训练数据集的准确性(虚线)和交叉验证数据集的准确性(实线)靠的很近,总体水平较高。
上图中【右图】的内容,十阶多项式,过拟合:
- 随着训练数据集的增加,交叉验证数据集的准确性(实现)也在增加,逐渐和训练数据集的准确性(虚线)靠近,但两者之间的间隙比较大。
- 训练数据集的准确性很高,收敛在 0.95 左右
- 交叉验证数据集的准确性较低,最终收敛在 0.91 左右。
从上图我们看出,对于复杂的数据,低阶多项式往往是欠拟合的状态,而高阶多项式则过分捕捉噪声数据的分布规律,而噪声数据之所以称为噪声,是因为其分布毫无规律可言,或者其分布毫无价值,因此就算高阶多项式在当前训练集上拟合度很高,但其捕捉到无用规律无法推广到新的数据集上,因此该模型在测试数据集上执行过程将会有很大误差,即模型训练误差很小,但泛化的误差会很大。
机器学习的工作流程
机器学习通常包含以下几个步骤:
数据收集与预处理
数据是机器学习的基础。通常从各种来源收集数据,然后进行清洗、归一化、处理缺失值等预处理操作,以确保数据的质量。
特征工程
特征工程是指从原始数据中提取有用的特征。这一步骤对模型的性能至关重要。常见的特征处理方法包括特征选择、特征缩放、编码等。
模型选择
根据问题的类型(分类、回归、聚类等)选择适合的算法模型。不同的算法适用于不同类型的数据和任务。
模型训练
将预处理后的数据输入到选定的机器学习算法中,使用数据集中的训练数据让模型学习如何做出预测。
模型评估
训练完成后,使用测试集评估模型的性能。常用的评估指标包括准确率、精确率、召回率、F1分数、均方误差等。
模型调优
通过调整模型的参数或引入更多数据等手段,进一步优化模型的表现。
模型部署与应用
一旦模型通过了评估,它就可以被部署在实际应用中,比如推荐系统、自动驾驶、语音识别等。
常见的机器学习算法
线性回归(Linear Regression)
线性回归是解决回归问题的基础算法,通过寻找输入变量(X)和输出变量(Y)之间的线性关系建立模型。其数学表达式为 Y = β₀ + β₁X + ε,其中β₀是截距,β₁是斜率,ε是误差项。典型应用包括房价预测(基于面积、位置等特征)、销售额预测等。最小二乘法是最常用的参数估计方法,通过最小化残差平方和来确定最佳拟合线。例如,可用线性回归分析广告投入与销售额之间的关系。
逻辑回归(Logistic Regression)
逻辑回归是解决二分类问题的经典算法,虽然名称中有"回归",实际上是分类算法。它通过Sigmoid函数将线性回归的输出映射到(0,1)区间,表示属于某一类别的概率。当概率大于0.5时通常判为正类,否则为负类。广泛应用于垃圾邮件识别(判断是否为垃圾邮件)、疾病诊断(是否患病)等场景。逻辑回归的优势在于模型可解释性强,可以输出特征的重要性权重。
决策树(Decision Tree)
决策树是基于树形结构的算法,通过递归地划分数据空间来构建模型。每个内部节点表示一个特征测试,每个分支代表测试结果,每个叶节点代表预测结果。构建过程包括特征选择(常用信息增益、基尼系数等指标)、树的生成和剪枝。典型应用有贷款审批决策(基于收入、信用记录等)、客户分类等。决策树易于理解和解释,可以处理数值型和类别型数据,但容易过拟合。
随机森林(Random Forest)
随机森林是决策树的集成方法,通过构建多个决策树并综合其预测结果(投票或平均)来提高性能。其核心思想是"集体智慧",通过引入两个随机性(样本随机性和特征随机性)确保树之间的多样性。相比单一决策树,随机森林具有更好的泛化能力,能有效降低过拟合风险。常用于金融风险评估、图像分类等复杂任务。另一个优势是可以评估特征重要性,为特征选择提供参考。
支持向量机(SVM)
支持向量机是一种强大的分类和回归算法,其核心是找到最优的决策边界(超平面),最大化不同类别之间的间隔。对于线性不可分问题,可通过核技巧(如RBF核、多项式核)将数据映射到高维空间实现分离。SVM特别适合小样本、高维度的场景,如文本分类、生物信息学等领域。其优势在于理论完备、全局最优,但对大规模数据计算成本较高,且对参数和核函数选择敏感。
K均值聚类(K-Means Clustering)
K均值聚类是一种无监督学习算法,目标是将n个数据点划分为k个簇,使得同一簇内的点尽可能接近,不同簇的点尽可能远离。算法流程包括:1)随机选择k个初始中心点;2)将每个点分配到最近的中心点形成簇;3)重新计算簇中心;4)重复2-3步直至收敛。应用于客户细分、图像压缩等场景。需注意k值选择(可用肘部法则或轮廓系数评估)和对初始中心点敏感的问题。
神经网络(Neural Networks)
神经网络模仿生物神经元结构,由输入层、隐藏层(可有多层)和输出层组成,通过激活函数(如ReLU、Sigmoid)实现非线性变换。深度学习中的卷积神经网络(CNN)擅长图像处理,循环神经网络(RNN)适合序列数据。神经网络通过反向传播算法调整权重,需要大量数据和计算资源。应用领域包括:计算机视觉(图像识别)、自然语言处理(机器翻译)、语音识别等。随着模型深度增加,可能面临梯度消失/爆炸等问题,需配合适当初始化、正则化等技术。
机器学习面临的挑战
- 数据质量:模型的性能很大程度上依赖于数据的质量和数量,缺失值、噪声、偏差等问题都会影响学习效果。
- 模型过拟合:模型在训练数据上表现优异,但在新数据上效果不佳,称为过拟合。这通常发生在数据量少且模型复杂的情况下。
- 可解释性:复杂的机器学习模型(如深度学习)往往难以解释其内部的决策逻辑,使得模型的透明度和信任度成为一个问题。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 把"逻辑回归"当成回归问题 | 名称误导:输出是类别概率,本质是分类 看输出:是否为离散类别/概率阈值判定 | 明确"回归/分类"按标签类型区分:连续→回归,离散→分类 |
| 训练集分数很高,验证集分数明显低 | 过拟合:模型复杂度过高或数据噪声被记住 对比训练/验证曲线是否长期存在明显间隙 | 降复杂度、正则化、更多数据、特征筛选、交叉验证、早停 |
| 训练集和验证集都低且接近 | 欠拟合:模型能力不足或特征表达弱 两条曲线贴合但收敛在较低水平 | 增强特征、换更强模型、放宽假设空间、训练更充分 |
| "无监督=没有目标/随便学"误解 | 无监督仍有优化目标(如簇内距离/重构误差) 看算法目标函数:K-Means 最小化簇内距离、PCA 最大化方差等 | 用"目标函数"解释无监督:没有人工标签,不等于没有优化方向 |
| 强化学习训练不稳定、学到怪策略 | 奖励函数设计不当或探索策略问题 观察 reward 曲线与策略行为是否偏离业务目标 | 重构奖励、加入约束/惩罚项、调整探索率、引入基线与稳定训练技巧 |
| 读者看完仍不知道"怎么落地做一个模型" | 流程缺少可执行的评估闭环(指标、数据切分、验证方式) 检查是否明确:训练/验证/测试划分、指标选择、交叉验证 | 在流程段补齐:数据切分策略、指标(Accuracy/F1/MSE 等)、调参与上线验证 |
| 文本层面出现明显笔误影响可信度 | 个别错字与术语拼写(如 "机器学习 h的方法") 搜索孤立字符/断词、术语中英文是否一致 | 统一术语与拼写;删掉无意义字符;中英文括号与大小写规范化 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解