hive实战
-
-
-
- 需求描述
- 数据结构
- 准备工作
- [安装 Tez 引擎](#安装 Tez 引擎)
- 业务分析
-
-
- [统计视频观看数 Top10](#统计视频观看数 Top10)
- [统计视频类别热度 Top10](#统计视频类别热度 Top10)
- [统计出视频观看数最高的 20 个视频的所属类别以及类别包含Top20 视频的个数](#统计出视频观看数最高的 20 个视频的所属类别以及类别包含Top20 视频的个数)
- [统计视频观看数 Top50 所关联视频的所属类别排序](#统计视频观看数 Top50 所关联视频的所属类别排序)
- [统计每个类别中的视频热度 Top10,以 Music 为例](#统计每个类别中的视频热度 Top10,以 Music 为例)
- [统计每个类别视频观看数 Top10](#统计每个类别视频观看数 Top10)
- [统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前 20 的视频](#统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前 20 的视频)
-
- 常见错误及解决方案
-
-
需求描述
统计硅谷影音视频网站的常规指标,各种 TopN 指标:
--统计视频观看数 Top10
--统计视频类别热度 Top10
--统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数
--统计视频观看数 Top50 所关联视频的所属类别排序
--统计每个类别中的视频热度 Top10,以 Music 为例
--统计每个类别视频观看数 Top10
--统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前 20 的视频
数据结构
- 视频表
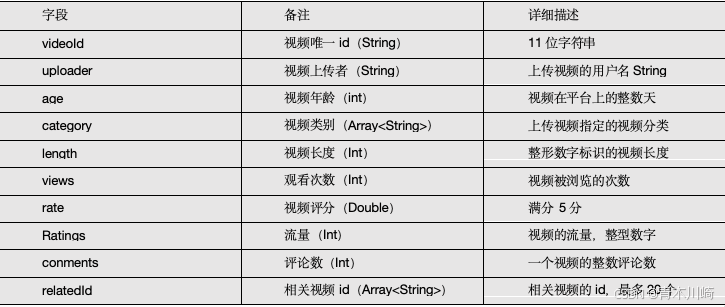
- 用户表

准备工作
sql
# 创建原始数据表:
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
# 创建 orc 存储格式带 snappy 压缩的表
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");
# 向 ori 表插入数据
load data local inpath "/opt/module/data/video" into table gulivideo_ori;
load data local inpath "/opt/module/user" into table gulivideo_user_ori;
# 向 orc 表插入数据
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;安装 Tez 引擎
Tez 是一个 Hive 的运行引擎,性能优于 MR。为什么优于 MR 呢?看下。
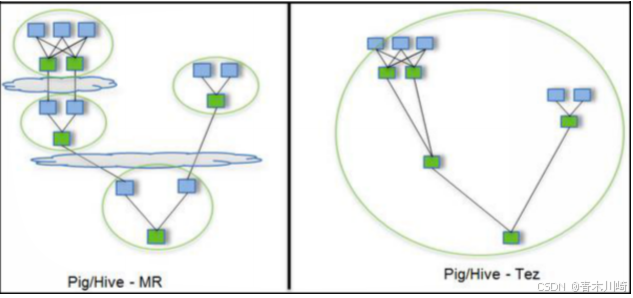
用 Hive 直接编写 MR 程序,假设有四个有依赖关系的 MR 作业,上图中,绿色是 Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到 HDFS。
Tez 可以将多个有依赖的作业转换为一个作业,这样只需写一次 HDFS,且中间节点较少,从而大大提升作业的计算性能。
安装教程
sql
# 将 tez 安装包拷贝到集群,并解压 tar 包
[root@hadoop102 software]$ mkdir /opt/module/tez
[root@hadoop102 software]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez
# 上传 tez 依赖到 HDFS
[root@hadoop102 software]$ hadoop fs -mkdir /tez
[root@hadoop102 software]$ hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez
# 新建 tez-site.xml
[root@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xml
# 添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
# 修改 Hadoop 环境变量
[root@hadoop102 software]$ vim
$HADOOP_HOME/etc/hadoop/shellprofile.d/tez.sh
# 添加 Tez 的 Jar 包相关信息
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after hadoop_add_classpath "/opt/module/tez/*" after hadoop_add_classpath "/opt/module/tez/lib/*" after
}
# 修改 Hive 的计算引擎
[root@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml
# 添加
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
# 解决日志 Jar 包冲突
[root@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar业务分析
统计视频观看数 Top10
思路:使用 order by 按照 views 字段做一个全局排序即可,同时我们设置只显示前 10条。
sql
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY views DESC
LIMIT 10;统计视频类别热度 Top10
思路:
(1)即统计每个类别有多少个视频,显示出包含视频最多的前 10 个类别。
(2)我们需要按照类别 group by 聚合,然后 count 组内的 videoId 个数即可。
(3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要 group by 类别,
需要先将类别进行列转行(展开),然后再进行 count 即可。
(4)最后按照热度排序,显示前 10 条。
sql
SELECT t1.category_name,
COUNT(t1.videoId) hot
FROM (
SELECT videoId,
category_name
FROM gulivideo_orc lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY t1.category_name
ORDER BY hot DESC LIMIT 10统计出视频观看数最高的 20 个视频的所属类别以及类别包含Top20 视频的个数
思路:
(1)先找到观看数最高的 20 个视频所属条目的所有信息,降序排列
(2)把这 20 条信息中的 category 分裂出来(列转行)
(3)最后查询视频分类名称和该分类下有多少个 Top20 的视频
sql
SELECT t2.category_name,
COUNT(t2.videoId) video_sum
FROM (
SELECT t1.videoId,
category_name
FROM (
SELECT videoId,
views,
category
FROM gulivideo_orc
ORDER BY views
DESC LIMIT 20
) t1 lateral VIEW explode(t1.category) t1_tmp AS category_name) t2
GROUP BY t2.category_name统计视频观看数 Top50 所关联视频的所属类别排序
sql
SELECT t6.category_name,
t6.video_sum,
rank() over (ORDER BY t6.video_sum DESC ) rk
FROM (
SELECT t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM (
SELECT t4.relatedid_id,
category_name
FROM (
SELECT t2.relatedid_id,
t3.category
FROM (
SELECT relatedid_id
FROM (
SELECT videoId,
views,
relatedid
FROM gulivideo_orc
ORDER BY views
DESC LIMIT 50
) t1 lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
) t2
JOIN
gulivideo_orc t3
ON
t2.relatedid_id = t3.videoId
) t4 lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY t5.category_name
ORDER BY video_sum
DESC
) t6统计每个类别中的视频热度 Top10,以 Music 为例
(1)要想统计 Music 类别中的视频热度 Top10,需要先找到 Music 类别,那么就需要将category 展开,所以可以创建一张表用于存放 categoryId 展开的数据。
(2)向 category 展开的表中插入数据。
(3)统计对应类别(Music)中的视频热度。
sql
SELECT t1.videoId,
t1.views,
t1.category_name
FROM (
SELECT videoId,
views,
category_name
FROM gulivideo_orc lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
WHERE t1.category_name = "Music"
ORDER BY t1.views
DESC LIMIT 10统计每个类别视频观看数 Top10
sql
SELECT t2.videoId,
t2.views,
t2.category_name,
t2.rk
FROM (
SELECT t1.videoId,
t1.views,
t1.category_name,
rank() over (PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM (
SELECT videoId,
views,
category_name
FROM gulivideo_orc lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
) t2
WHERE t2.rk <= 10统计上传视频最多的用户 Top10 以及他们上传的视频观看次数在前 20 的视频
1)求出上传视频最多的 10 个用户
(2)关联 gulivideo_orc 表,求出这 10 个用户上传的所有的视频,按照观看数取前 20
sql
SELECT t2.videoId,
t2.views,
t2.uploader
FROM (
SELECT uploader,
videos
FROM gulivideo_user_orc
ORDER BY videos
DESC LIMIT 10
) t1
JOIN gulivideo_orc t2
ON t1.uploader = t2.uploader
ORDER BY t2.views
DESC LIMIT 20常见错误及解决方案
- 如果更换 Tez 引擎后,执行任务卡住,可以尝试调节容量调度器的资源调度策略将$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml 文件中的
xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications.
</description>
</property>
<!-- 改成 -->
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>1</value>
<description>
Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications.
</description>
</property>- 连接不上 mysql 数据库
(1)导错驱动包,应该把 mysql-connector-java-5.1.27-bin.jar 导入/opt/module/hive/lib 的不是这个包。错把 mysql-connector-java-5.1.27.tar.gz 导入 hive/lib 包下。
(2)修改 user 表中的主机名称没有都修改为%,而是修改为 localhost
- hive 默认的输入格式处理是 CombineHiveInputFormat,会对小文件进行合并。
sql
hive (default)> set hive.input.format; hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
# 可以采用 HiveInputFormat 就会根据分区数输出相应的文件。
hive (default)> set
hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;- 不能执行 mapreduce 程序
可能是 hadoop 的 yarn 没开启。
- 启动 mysql 服务时,报 MySQL server PID file could not be found! 异常。
在/var/lock/subsys/mysql 路径下创建 hadoop102.pid,并在文件中添加内容:4396
- 报 service mysql status MySQL is not running, but lock file (/var/lock/subsys/mysql失败)异常。
解决方案:在/var/lib/mysql 目录下创建: -rw-rw----. 1 mysql mysql hadoop102.pid 文件,并修改权限为 777。
- JVM 堆内存溢出
描述:java.lang.OutOfMemoryError: Java heap space 解决:在 yarn-site.xml 中加入如下代码
xml
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>- 虚拟内存限制
在 yarn-site.xml 中添加如下配置:
xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>