在计算机视觉与机器人研究领域,人类通过视觉、触觉、本体感受的多模态融合实现精准物理交互,但现有技术长期依赖单一视觉模态,难以捕捉接触力、材质属性等关键信息。MIT、杜克大学等联合团队提出的 OPENTOUCH 框架,以 "野生环境全手触觉数据集" 为核心,通过 "硬件感知系统 - 大规模数据采集 - 多模态基准测试" 的三层技术体系,首次实现真实场景下视觉、触觉、手部姿态的同步建模,为 embodied 学习与机器人操纵提供了全新范式。
论文题目:OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
OpenTouch --- Project Page (opentouch-tactile.github.io):https://opentouch-tactile.github.io/
核心亮点:首个野生环境全手触觉数据集、低 - cost 同步感知硬件、跨模态检索与分类基准、800+ 物体 / 14 场景覆盖
问题根源:真实世界触觉感知的四大核心挑战
OPENTOUCH 的设计逻辑源于对现有多模态研究痛点的精准洞察,四大核心挑战构成技术突破的起点:
模态信息缺失
现有数据集侧重视觉观察,缺乏触觉与力反馈信号,无法区分相似姿态下的不同接触状态(如轻触与按压)。
野生环境适应性差
传统触觉感知系统依赖实验室控制场景,硬件笨重且环境多样性不足,难以迁移到真实生活场景。
多模态同步难题
视觉、触觉、姿态数据的时间对齐精度低,传感器噪声与延迟导致跨模态信息融合困难。
标注效率低下
真实场景中物体种类繁杂、交互行为多样,人工标注成本极高,难以形成大规模高质量数据集。

方案设计:OPENTOUCH 的三层技术闭环
针对上述挑战,OPENTOUCH 构建了 "硬件感知 - 数据采集 - 基准测试" 的完整技术闭环,层层递进实现真实世界全手接触建模:

第一层:硬件感知系统 ------ 低 - cost 同步触觉 - 视觉 - 姿态采集
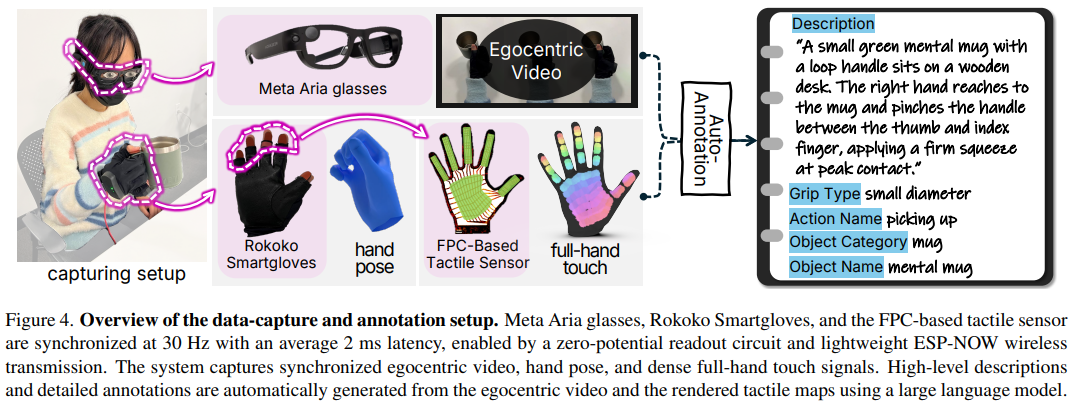
为实现野生环境下的高精度多模态采集,设计了轻量化、高鲁棒性的硬件套件:
- 全手触觉传感手套:基于柔性印刷电路(FPC)技术,集成 16×16 电极网格与压阻薄膜,形成 169 个触觉传感点(taxels),均匀覆盖手掌与手指,兼顾 PCB 级精度与穿戴灵活性,成本低且可批量生产;
- 手部姿态追踪手套:采用 Rokoko Smartglove 专业动捕设备,通过 IMU 与 EMF 传感器融合,以 30Hz 频率输出 7 个 6DOF 姿态数据,旋转精度达 ±1°,经系统校准确保姿态一致性;
- 第一视角视觉采集:利用 Meta Project Aria 智能眼镜,同步采集 1408×1408 分辨率 RGB 视频(30Hz)、眼动追踪、音频与 IMU 数据,110° 视场角覆盖完整交互场景;
- 多模态时间同步:通过终端视觉触发信号实现跨设备校准,将视频、触觉、姿态数据的时间延迟控制在 2ms 内,确保时序一致性。
第二层:大规模数据采集 ------ 野生环境多维度标注数据集
为解决数据稀缺问题,构建了覆盖真实生活场景的大规模多模态数据集:
-
多样化采集场景:在 14 个日常环境(厨房、工作室、办公室等)中,让参与者自由操纵 800+ 类物体,采集 5.1 小时同步数据,其中 3 小时为高密度标注的接触 - rich 交互片段;
-
智能标注流水线:采用 GPT-5 自动化标注 + 人工验证机制,选取接触力变化的关键帧(接近 - 峰值 - 释放),生成物体名称、类别、环境、动作、抓握类型、自然语言描述 6 类标签,标注准确率达 90%;
-
多模态数据维度:数据集包含 RGB 视频、全手触觉压力图、3D 手部姿态、眼动轨迹、音频等多源数据,支持跨模态关联分析(如图 2 展示的标签分布与触觉图谱对应关系)。

第三层:基准测试体系 ------ 跨模态检索与触觉分类任务
基于数据集构建两大核心基准任务,量化多模态融合的有效性:
- 跨模态检索任务:包括视频↔触觉、姿态↔触觉、多模态→单模态(如视频 + 姿态→触觉)三类子任务,要求模型学习共享表征空间,实现不同模态信号的精准匹配;
- 触觉模式分类任务:分为手部动作识别与抓握类型分类,验证触觉信号对交互意图与接触方式的判别能力;
- 评估指标与基线:采用 Recall@1/5/10、平均精度均值(mAP)评估检索性能,分类任务使用准确率指标,基线模型包括 CCA、PLSCA 线性方法与 CLIP-style 对比学习框架。

验证逻辑:从定量指标到定性分析的全面性能验证
OPENTOUCH 通过 "跨模态性能 - 关键因素消融 - 真实场景应用" 的三级验证体系,充分证明其技术有效性:
跨模态任务性能突破
在核心基准测试中,多模态融合模型显著优于单模态与线性基线:
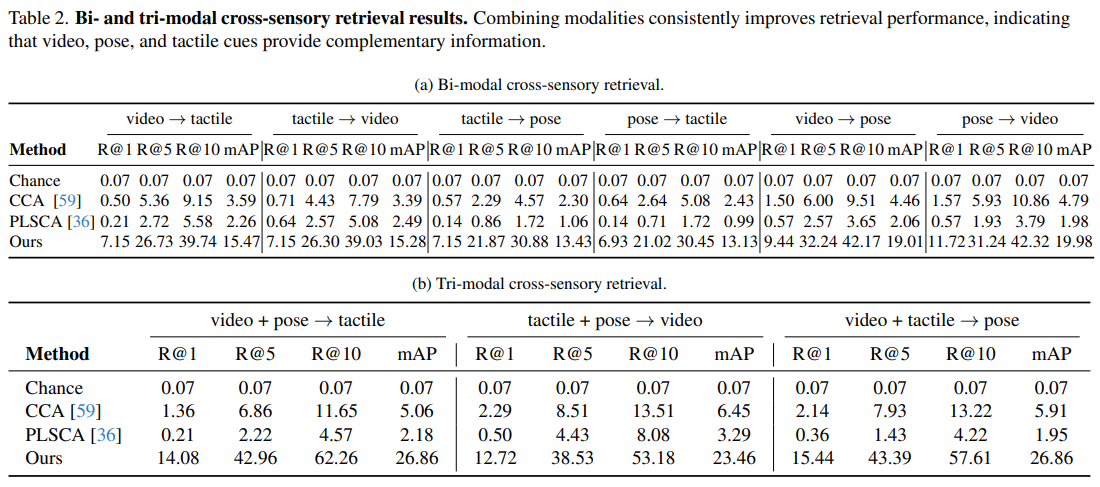
-
跨模态检索:视频 + 姿态→触觉检索的 mAP 达 26.86%,较 CCA 线性方法提升 5 倍以上;触觉单独检索姿态的 Recall@1 达 7.15%,远超随机猜测的 0.07%;
-
分类任务:触觉 + 视觉融合的抓握类型分类准确率达 68.09%,触觉单独分类准确率达 60.23%,证明触觉信号对抓握方式的强判别能力;
-
定性结果:检索任务中,模型能精准匹配相似接触模式(如抓取圆形物体、放置动作),即使视觉上存在遮挡或物体透明,触觉信号仍能提供关键线索(如图 5、图 6 展示的跨模态匹配案例)。


关键因素消融分析
通过系统消融实验,验证了核心设计的必要性:
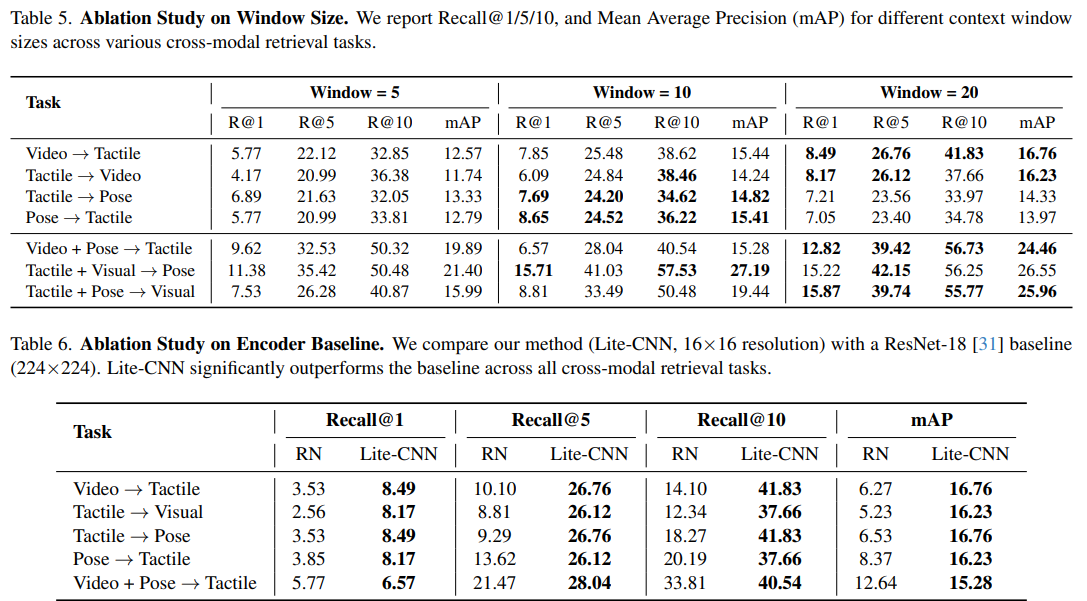
- 时间窗口长度:20 帧窗口(约 0.67 秒)的检索性能最优,较 5 帧窗口的 Recall@1 提升 47%,证明长时程时序动态对接触模式识别的重要性;
- 触觉编码器设计:轻量化 CNN 编码器(16×16 输入)在所有任务中优于 ResNet-18(224×224 上采样输入),mAP 最高提升 10.49%,说明触觉信号的稀疏结构化特性更适合紧凑编码器。
真实场景应用拓展
在 Ego4D 野生视频数据集上的零样本检索实验中,OPENTOUCH 模型能从输入视频中检索到语义相似的触觉序列,证明其泛化能力:

- 给定人类操纵物体的视频查询,模型返回的触觉信号与真实接触模式高度一致(如转动门把手、研磨咖啡);
- 该应用可将大规模视觉视频数据集与触觉信息关联,为机器人操纵提供丰富的接触力先验知识。
局限与未来方向
OPENTOUCH 作为野生环境全手触觉研究的突破性工作,仍存在可优化空间:
- 触觉维度局限:当前仅捕捉法向压力,未涵盖剪切力、温度、振动等触觉子模态,难以区分滑动与稳定接触;
- 硬件耐用性:FPC 传感器在反复弯曲与汗液侵蚀下可能出现线路断裂,需优化封装工艺提升使用寿命;
- 标注精细化:部分遮挡或低光照场景下的标注准确率仍有提升空间,可结合多帧上下文与 3D 重建优化标注流程;
- 跨模态融合深度:未来可探索 transformer 架构实现模态间的细粒度交互,进一步提升检索与分类性能。
总结:OPENTOUCH 的范式价值与行业影响
OPENTOUCH 的核心贡献不仅在于构建了首个野生环境全手触觉数据集,更在于建立了 "感知硬件 - 数据标注 - 基准测试" 的完整技术链路:通过低 - cost 同步硬件破解真实场景采集难题,通过 AI 辅助标注解决大规模数据构建瓶颈,通过跨模态基准揭示触觉与视觉、姿态的互补关系。其 5.1 小时多模态数据、硬件设计方案与开源代码,为计算机视觉、机器人学、神经科学等领域提供了统一研究平台,推动多模态 embodied 学习从实验室走向真实世界,加速通用自主机器人的落地进程。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?