Day 47 预训练模型与迁移学习@浙大疏锦行
- 理解预训练模型(Pre-trained Models)的概念与优势。
- 掌握迁移学习(Transfer Learning)的两种主要策略:微调(Fine-tuning)与 特征提取(Feature Extraction)。
- 了解常见经典模型结构:ResNet(残差网络)与 MobileNet(轻量级网络)。
概念
迁移学习
利用在大型数据集(如 ImageNet)上训练好的模型权重,来解决新的、数据量较小的任务。
- 优势:收敛速度快,训练数据需求少,泛化能力强。
- 策略 :
- 冻结训练 (Freezing):冻结卷积基(特征提取器),只训练自定义的分类头。
- 微调 (Fine-tuning):解冻部分或全部层,以极小的学习率更新参数,使模型适应新数据分布。
ResNet (残差网络)
- 核心问题:解决深层网络中的梯度消失/爆炸和退化问题。
- 解决方案 :引入残差连接 (Residual Connection) y = F ( x ) + x y = F(x) + x y=F(x)+x。
- 作用:允许梯度直接流向浅层,使得训练数百层的网络成为可能。
MobileNetV2
- 定位:专为移动端设计的轻量级网络。
- 特点:参数量少,推理速度快,适合资源受限环境。
作业:MobileNetV2 on CIFAR-10
使用 ImageNet 预训练的 MobileNetV2 模型对 CIFAR-10 数据集(10类图片)进行分类。
python
# 4. 定义 MobileNetV2 模型
def create_mobilenet_v2(pretrained=True, num_classes=10):
model = models.mobilenet_v2(pretrained=pretrained)
# MobileNetV2 的分类器结构:
# (classifier): Sequential(
# (0): Dropout(p=0.2, inplace=False)
# (1): Linear(in_features=1280, out_features=1000, bias=True)
# )
# 修改最后一层全连接层
# 获取分类器中最后一个线性层的输入特征数
in_features = model.classifier[1].in_features
model.classifier[1] = nn.Linear(in_features, num_classes)
return model.to(device)
# 5. 冻结/解冻模型层的函数
def freeze_model(model, freeze=True):
"""冻结或解冻模型的特征提取层参数"""
# MobileNetV2 的特征提取部分是 'features'
for param in model.features.parameters():
param.requires_grad = not freeze
# 打印冻结状态
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print(f"已冻结模型特征层参数 ({frozen_params}/{total_params} 参数)")
else:
print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")
return model
python
# 6. 训练函数
def train_model(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=1):
train_loss_history = []
test_acc_history = []
# 初始冻结
if freeze_epochs > 0:
model = freeze_model(model, freeze=True)
for epoch in range(epochs):
# 解冻控制
if epoch == freeze_epochs:
print(f"Epoch {epoch}: 解冻所有参数,开始微调...")
model = freeze_model(model, freeze=False)
# 解冻后通常使用更小的学习率
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
if (batch_idx + 1) % 200 == 0:
print(f"Epoch {epoch+1} | Batch {batch_idx+1}/{len(train_loader)} | Loss: {loss.item():.4f}")
epoch_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
# 测试
model.eval()
correct_test = 0
total_test = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
test_acc = 100. * correct_test / total_test
train_loss_history.append(epoch_loss)
test_acc_history.append(test_acc)
if scheduler:
scheduler.step()
print(f"Epoch {epoch+1} End | Train Loss: {epoch_loss:.4f} | Train Acc: {train_acc:.2f}% | Test Acc: {test_acc:.2f}%")
return train_loss_history, test_acc_history
# 主运行逻辑
def run_training():
# 减少 epoch 数以节省时间演示
epochs = 5
freeze_epochs = 2
learning_rate = 0.001
model = create_mobilenet_v2(pretrained=True, num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
print("开始训练 MobileNetV2...")
train_loss, test_acc = train_model(
model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs
)
# 简单绘图
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss, label='Train Loss')
plt.title('Training Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(test_acc, label='Test Acc')
plt.title('Test Accuracy')
plt.legend()
plt.show()
if __name__ == "__main__":
run_training()实现步骤
- 数据适配 :CIFAR-10 图片尺寸为 32x32,而 MobileNetV2 默认输入为 224x224。使用
transforms.Resize(224)进行调整。 - 模型修改:将 MobileNetV2 最后的分类层(1000类)替换为 10 类的全连接层。
- 训练策略 :
- 阶段一:冻结特征层,训练 2 个 Epoch。
- 阶段二:解冻所有层,降低学习率进行微调。
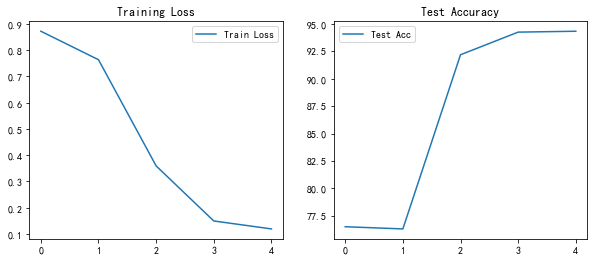
实验结果
基于训练日志:
- 快速收敛:Epoch 1 结束时,测试集准确率已达 76.52%。
- 微调效果 :解冻后 Loss 迅速下降,最终在 Epoch 5 达到 94.31% 的测试集准确率。
- 结论:迁移学习在小数据集上极其有效,MobileNetV2 展现了优秀的特征提取能力。