立即注册👉https://aiping.cn/#?channel_partner_code=GQCOZLGJ 注册登录立享30元算力金
1. 先说结论:这次上线更像"工程能力"的分水岭
如果你把大模型当作"更强的搜索框",那评测重点往往是知识点覆盖与文风;但当你开始把它接进研发与业务流程,评测重点会立刻变成:
- 需求拆解是否靠谱,能不能形成可执行的交付路径
- 多轮迭代是否稳定,是否会在长链路里逐步跑偏
- 成本与吞吐是否可控,是否适合持续运行的 Agent 工作流
GLM-4.7 与 MiniMax M2.1 的组合,刚好覆盖这三类诉求:一个更偏"复杂任务一次性交付",一个更偏"长时运行效率与吞吐"。
而 AI Ping 的价值在于:你可以在同一平台里用真实指标对比不同供应商,并用同一套接口把模型接入到工程里,减少试错与维护成本。
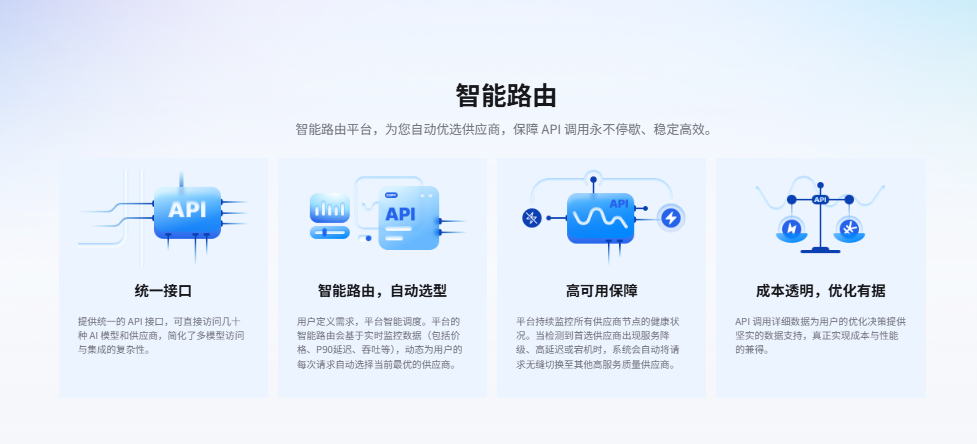
2. AI Ping 解决的不是"能不能用",而是"怎么稳定用"
很多团队第一次接入大模型时,会踩到三个常见坑:
- 供应商切换成本高:每家接口、参数、限流策略都不一样,换一家等于重写一遍。
- 线上体验不稳定:同一模型在不同时段延迟波动大,Agent 一超时就全链路断。
- 选型缺少依据:只靠主观体验对比,难以解释"为什么选它"。
AI Ping 把这些问题收敛成平台能力:
- 多供应商统一接入:业务只对接一次,后续切换供应商更多是"配置问题"
- 指标看板:把吞吐、延迟、上下文等关键数据摆到台面上
- 智能路由:高峰期自动挑更优供应商,降低抖动对业务的冲击

这会带来一个很现实的变化:模型接入不再是"集成一次就别动",而是变成可持续优化的运行时能力。
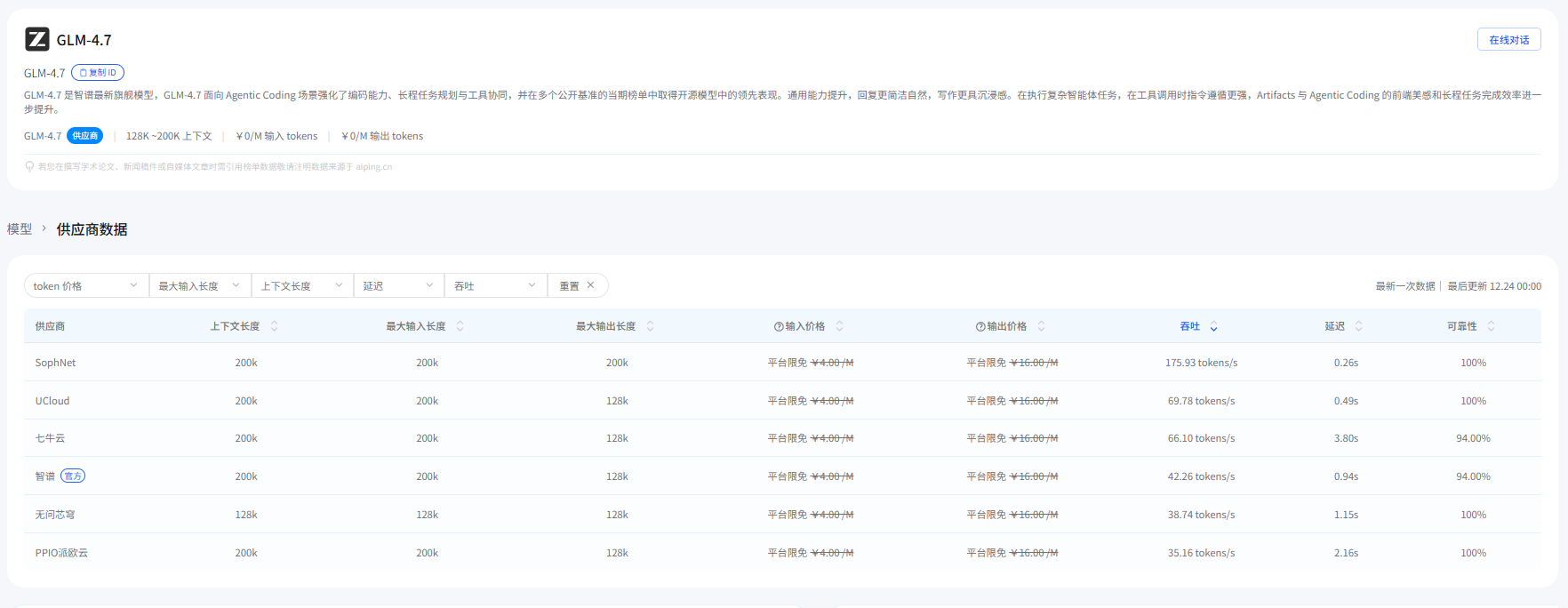
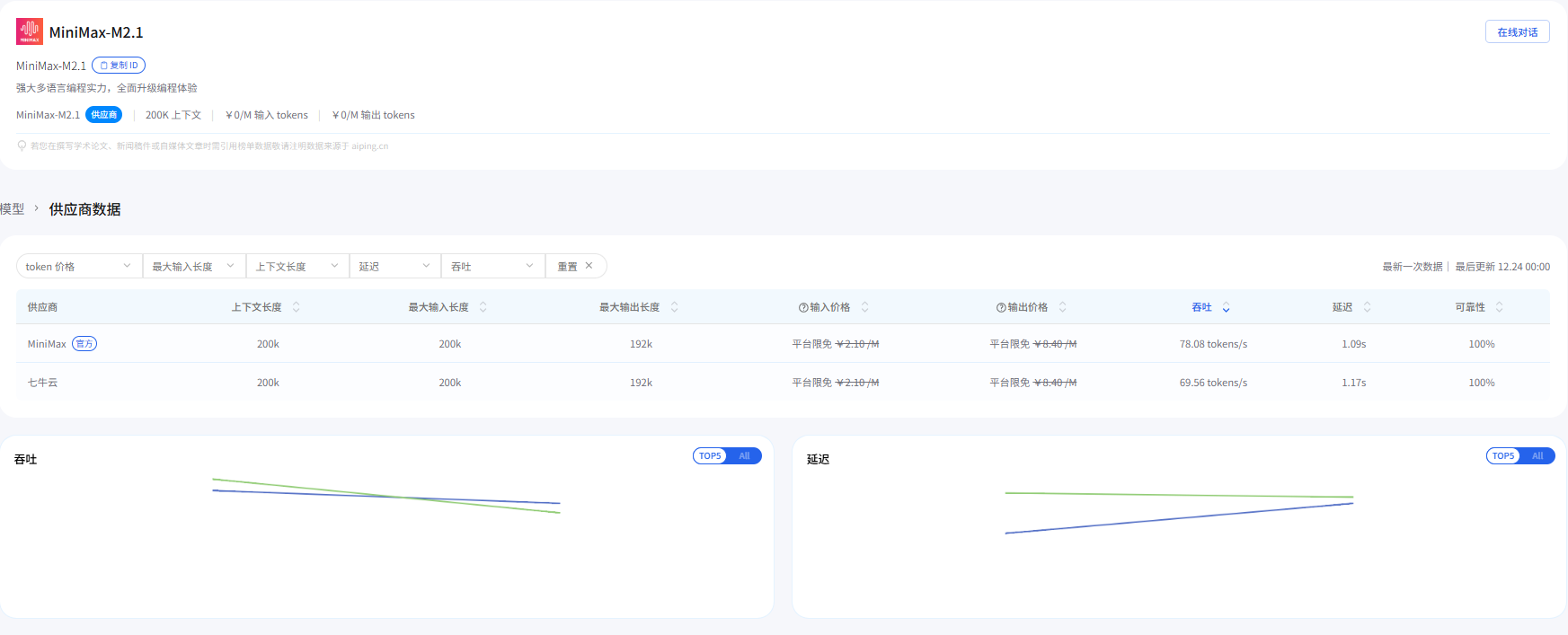
3. 用数据看差异:同一模型在不同供应商上会有明显不同
AI Ping 公布了平台实测数据。把关键指标整理如下(输入/输出价格在表中为免费,可靠性为 100%):
3.1 GLM-4.7(不同供应商)
| 供应商 | 吞吐量 (tokens/s) | 延迟 P90 (s) | 上下文长度 |
|---|---|---|---|
| PPIO 派欧云 | 50.47 | 3.64 | 200k |
| 智谱(官方) | 50.30 | 10.61 | 200k |
| 七牛云 | 37.64 | 2.52 | 200k |
| 无问芯穹 | 22.94 | 3.93 | 128k |
3.2 MiniMax M2.1(不同供应商)
| 供应商 | 吞吐量 (tokens/s) | 延迟 P90 (s) | 上下文长度 |
|---|---|---|---|
| 七牛云 | 99.75 | 0.54 | 200k |
| MiniMax(官方) | 89.56 | 0.72 | 200k |
这组数据对工程决策的意义可以用一句话概括:
- 想要交互更丝滑 ,盯
延迟 P90 - 想要长输出/长链路更快 ,盯
吞吐量 - 想要一次塞进更多需求+代码+日志 ,盯
上下文长度
如果你做的是"持续运行的 Agent",通常会同时看 P90 和可靠性,再决定是固定供应商还是交给路由。
4. GLM-4.7 与 MiniMax M2.1:更实用的任务分工方式
与其抽象地说"哪个更强",不如按任务拆分:
4.1 适合优先用 GLM-4.7 的任务
- 需求复杂、验收严格:必须输出可执行步骤、可验证结果、风险点与回滚方案
- 需要频繁工具协同:读文件、查依赖、对齐接口、生成补丁并回归验证
- 关键节点交付:例如发布前最后一轮"全量修复建议 + 变更清单 + 风险评估"
4.2 适合优先用 MiniMax M2.1 的任务
- 连续编码与重构:多轮往返,吞吐与延迟直接影响整体效率
- 长链路 Agent:需求更新、日志追加、再修复、再验证,循环次数多
- 多语言工程:尤其是 Rust / Go / Java / C++ 等偏"工程肌肉"的代码任务
实际落地时,很推荐做成"按场景路由":把模型当作一组可切换的能力,而不是一个固定依赖。
5. 从 0 到 1:在 AI Ping 上完成一次可复现的接入
下面用"最小可行路径"把接入讲清楚:拿 Key → 发请求 → 验证流式输出 → 加上路由筛选。
5.1 获取 API Key(只做一次)
- 登录 AI Ping官网
- 进入控制台的
API Key页面创建 Key - 把 Key 放进环境变量(避免写入仓库)
PowerShell 示例:
powershell
$env:AIPING_API_KEY="YOUR_API_KEY"5.2 最小请求:Chat Completions(非流式)
bash
curl "https://aiping.cn/api/v1/chat/completions" ^
-H "Authorization: Bearer %AIPING_API_KEY%" ^
-H "Content-Type: application/json" ^
-d "{\"model\":\"GLM-4.7\",\"messages\":[{\"role\":\"user\",\"content\":\"用三句话解释吞吐量和延迟的差别。\"}],\"temperature\":0.2}"如果你在 Windows 上更习惯用 WSL 或 Git Bash,把换行符改成反斜杠即可。核心不变:Authorization: Bearer ... + model + messages。
5.3 流式请求:适合 UI 与 Agent 逐步产出
Python(Requests)示例:
python
import os
import requests
api_key = os.environ["AIPING_API_KEY"]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
payload = {
"model": "MiniMax-M2.1",
"messages": [
{
"role": "user",
"content": "Hello"
}
],
"stream": True,
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
}
}
response = requests.post(
"https://aiping.cn/api/v1/chat/completions",
headers=headers,
json=payload,
stream=True,
timeout=(10, None)
)
response.encoding = "utf-8"
response.raise_for_status()
try:
for line in response.iter_lines(decode_unicode=True):
if line:
print(line)
except KeyboardInterrupt:
print("流被手动中断。")如果你直接用浏览器访问 https://aiping.cn/api/v1/chat/completions,会看到 Method Not Allowed,这是因为该接口需要用 POST 调用(浏览器地址栏默认是 GET)。
同一段代码想切到 GLM-4.7,只需要把 payload["model"] 改成 "GLM-4.7"。
5.4 用 extra_body.provider 做"可解释的路由筛选"
当你希望把"选择哪家供应商"这件事从拍脑袋变成可解释策略时,可以使用 extra_body.provider(字段以页面示例为准):
only:只允许命中某些供应商(白名单)order:优先级顺序(当存在多个候选时)sort:按某个指标排序(例如优先低延迟)input_length_range:对上下文长度有要求时使用throughput_range/latency_range:按吞吐或延迟做筛选
示例(以 GLM-4.7 为例,结构与页面示例一致,值按你的策略填写):
json
{
"model": "GLM-4.7",
"stream": true,
"messages": [{"role": "user", "content": "请给出一份可落地的接口改造方案。"}],
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": null,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
}
}在工程实践中,更推荐两种模式:
- 日常业务:交给平台自动路由,省运维、抗波动
- 发布前/关键链路:固定或强约束供应商,保证可复现与可排障
6. 两个"拿来就用"的实战模板:把模型能力落到交付件上
为了避免模型输出"看起来很对但落不了地",建议每次都让它产出可验证的交付物。
一个"实际调用 + 返回展示"的最小示例如下:
python
import os
import json
import requests
api_key = os.environ["AIPING_API_KEY"]
url = "https://aiping.cn/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
payload = {
"model": "GLM-4.7",
"messages": [
{
"role": "user",
"content": "你是资深工程师。请按以下顺序输出:1) 根因假设列表(按概率排序)2) 最小验证步骤(每步说明预期现象)3) 最小修复方案(用补丁/伪代码表达)4) 回归清单(必须覆盖的边界条件)",
}
],
"temperature": 0.2,
"stream": False,
"extra_body": {
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": [],
}
},
}
resp = requests.post(url, headers=headers, json=payload, timeout=(10, 120))
resp.raise_for_status()
print(resp.status_code)
print(json.dumps(resp.json(), ensure_ascii=False, indent=2))返回示例:
6.1 模板 A:让模型输出"可回归的修复补丁方案"
适用:线上报错、CI 失败、依赖升级导致的不兼容。
输入建议包含:
- 目标:修复什么、验收标准是什么
- 约束:不能改哪些模块、不能引入哪些依赖
- 证据:错误日志、关键代码片段、运行环境
提示词骨架:
text
你是资深工程师。请按以下顺序输出:
1) 根因假设列表(按概率排序)
2) 最小验证步骤(每步说明预期现象)
3) 最小修复方案(用补丁/伪代码表达)
4) 回归清单(必须覆盖的边界条件)GLM-4.7 通常更适合在"根因假设+验证步骤"阶段承担主力;MiniMax M2.1 更适合在"反复改补丁+再验证"的循环阶段保持效率。
6.2 模板 B:让模型输出"可交付的技术方案文档"
适用:需求评审、架构设计、接口改造、性能优化方案。
要求它输出:
- 关键决策与取舍(为什么这么选)
- 里程碑拆分(每个阶段的验收标准)
- 风险与回滚(出现问题怎么退回去)
提示词骨架:
text
请用面向团队评审的方式写方案:
- 背景与目标
- 方案对比(至少 2 个备选)
- 详细设计(数据结构/接口/流程)
- 实施计划(按周拆解)
- 风险与回滚7. 小结:把"会写"升级为"能交付、可持续"
GLM-4.7 与 MiniMax M2.1 的这次上线,最值得关注的不是某一条基准测试分数,而是它们对工程链路的覆盖:前者更利于复杂任务的稳定完成,后者更利于长链路与持续迭代的效率。而 AI Ping 让这件事更容易落地:你能看到不同供应商的真实表现,用统一接口完成接入,并通过路由策略把稳定性与效率做成可配置的工程能力。
当你把模型放进真实业务之后,"选择模型"就不该是一锤子买卖,而应当像选择数据库与缓存一样:持续观测、按场景切换、用数据说话。