在构建大模型智能体(LLM Agents)时,记忆系统是其核心。无论是为了记住用户的偏好,还是为了处理长达数月的对话历史,我们通常会给 AI 挂载一个"外部存储器"。
然而,目前的记忆检索系统大多遵循简单的 "检索-回答"(Retrieve-then-Answer) 模式:用户提问 系统去数据库捞数据 把捞到的扔给模型。

https://arxiv.org/pdf/2512.20237
Memory Retrieval via Reflective Reasoning for LLM Agents
基于 LangGraph 构建,其核心是一个智能路由(Router),它可以在三个动作之间自主选择:
- 检索(Retrieve):如果当前信息不足,更新查询词(Query Refinement),再次进入数据库寻找精准证据。
- 反思(Reflect):对已获取的证据进行逻辑推演。比如虽然没直接找到"领养间隔",但通过对比两个不同日期的证据,推算出时间差。
- 回答(Answer):当证据链完整时,生成最终响应。
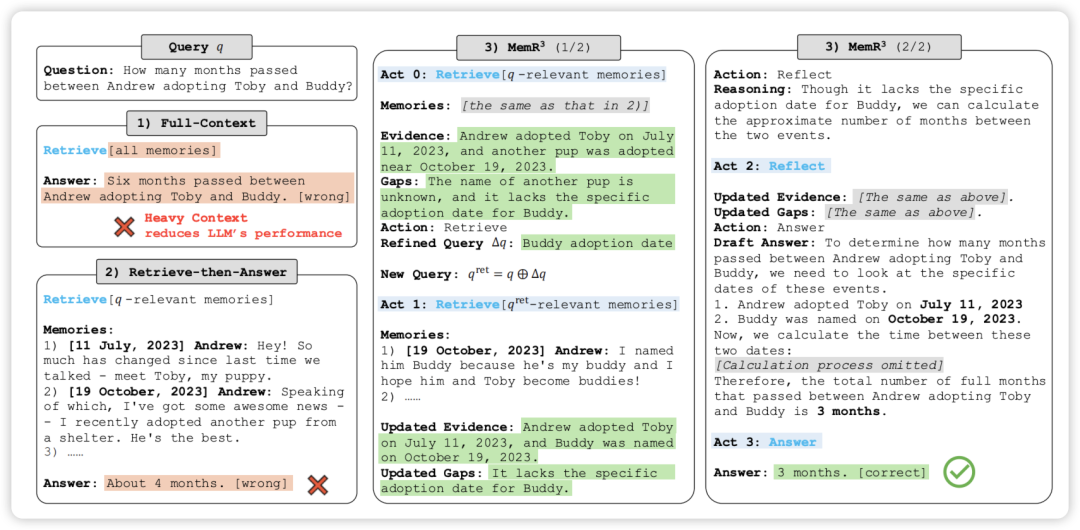
相比传统的 RAG, 引入了"早停机制"。如果系统认为现有的证据已经足够逻辑闭环,它会提前停止检索,从而减少冗余信息的干扰并提高效率。
传统的 RAG 是线性流,而 借鉴了 Self-RAG 和 Reflexion 的思想。
- Self-RAG/ReAct:让模型决定什么时候搜。
- ** 的进化**:它不仅决定"什么时候搜",还通过一个**显式的"证据-缺口状态"(Evidence-Gap State)**来量化当前的搜索进度。这就像给 AI 检索过程装了一个进度条和逻辑检查站。
是基于 LangGraph 构建的。这意味着它的每一个动作(检索、反思、回答)都是图中的一个节点。
- 透明度:你可以清楚地看到 AI 在得出"3个月"这个结论前,经历了多少次检索,每次检索补充了哪些 Evidence,又缩减了哪些 Gap。
- 鲁棒性:通过闭环控制,它能有效过滤掉检索回来的无关噪声,防止模型被误导。
unsetunset 的内部构造unsetunset
的核心在于它不把检索看作"一锤子买卖",而是看作一个有目的的探索过程。
系统每一步都会问自己两个问题:
- 我已知了什么?(Evidence, E) :从记忆中捞出来的、能支撑答案的事实。
- 我还缺什么?(Gap, G) :阻碍我给出最终答案的缺失信息。
就像一个拥有三个路径,由 Router(路由器) 决定何时换挡:
- 检索节点 (Retrieve) :当 (有缺口)时,生成新的查询词 。为了防止重复,它会**掩码(Mask)**掉已读过的记忆,确保每一轮都有新发现。
- 反思节点 (Reflect) :当搜不到新东西,或者需要逻辑推演时,进行内部思考。
- 回答节点 (Answer) :只有当 消失或达到最大步数时,才整合所有证据给出最终结论。
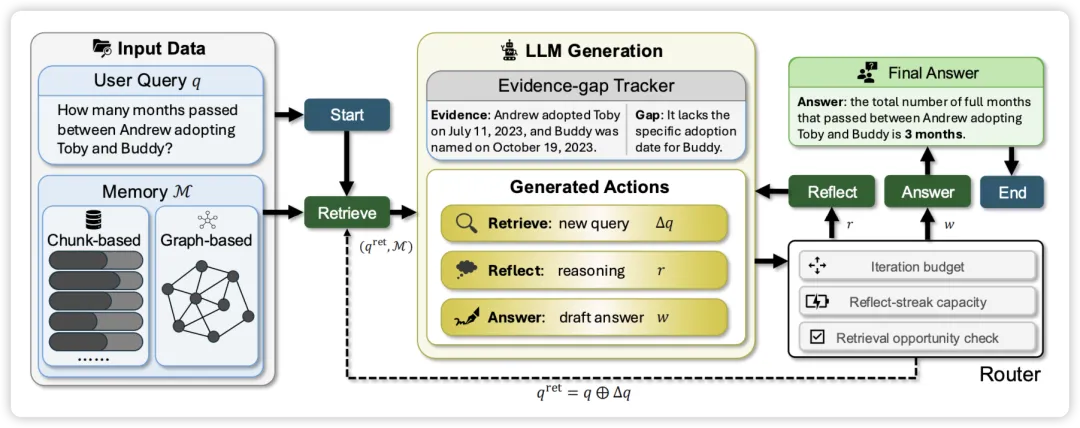
为了保证效率, 给路由器加了三道锁:
- 预算限制 :步数到了必须强制回答,防止无限搜索。
- 反思连击限制 :不能光想不干,想太多了就得去搜一下。
- 空检索跳转 :如果搜不到东西,自动转入"反思"模式。

unsetunset实验结果解析unsetunset
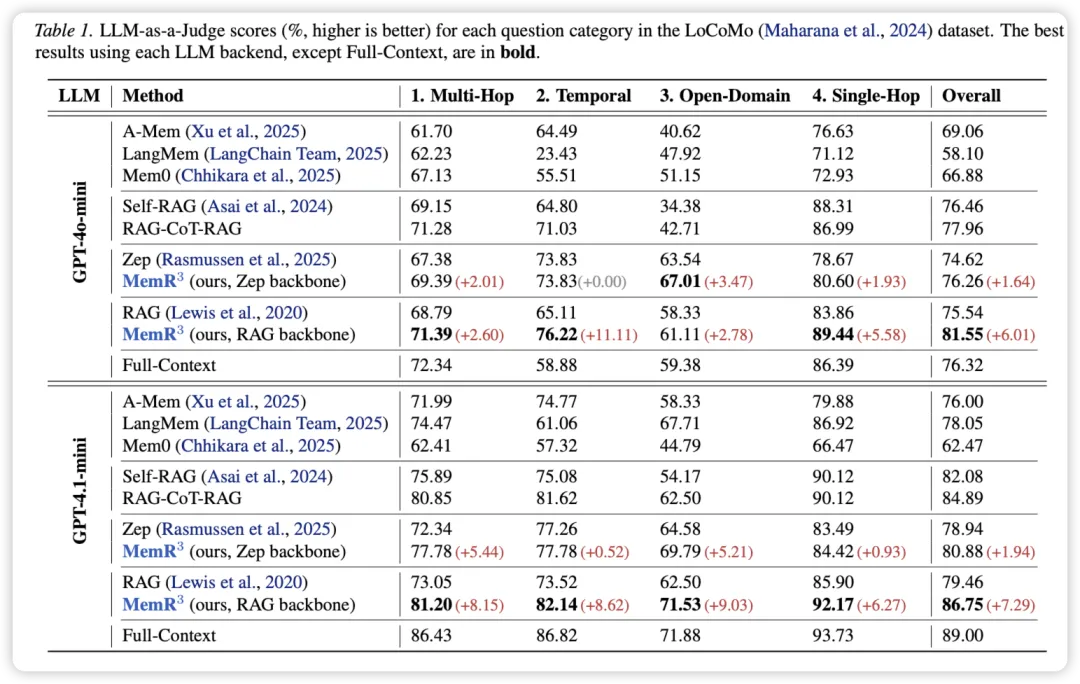
在 LoCoMo(长程对话记忆)基准测试中, 展示了统治级的表现:
- 全面超越基准 :无论底层用的是普通的 RAG (基于分块)还是 Zep(基于图谱),加上 控制器后,分数都有显著提升。
- 刷新上限:在 GPT-4o-mini 下, + RAG 的总分达到了 **81.55%**,甚至超过了把所有记忆都塞进上下文的 **Full-Context (76.32%)**。
- 后端兼容性 :数据证明 是"即插即用"的,它能显著修补传统 RAG 在处理时间推理 (Temporal) 和 多跳问题 (Multi-Hop) 上的短板。
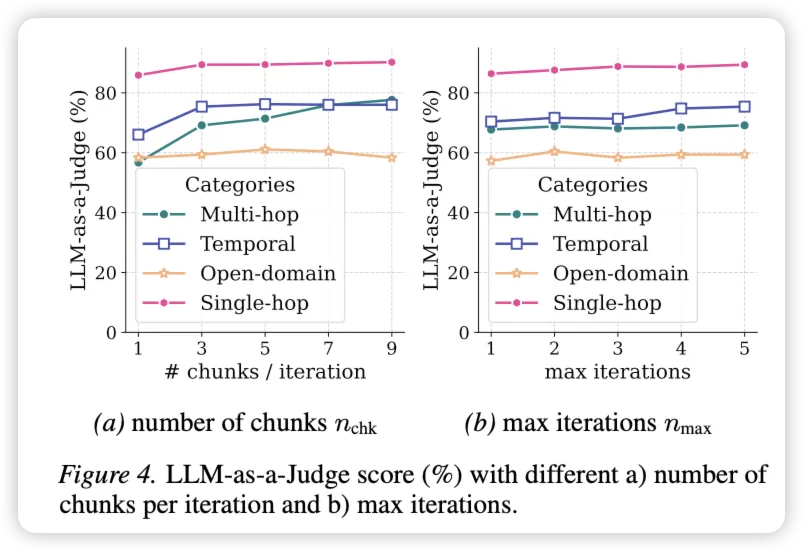
大家最担心的可能是"多轮检索太慢/太贵"。但实验数据说明了的高效性:
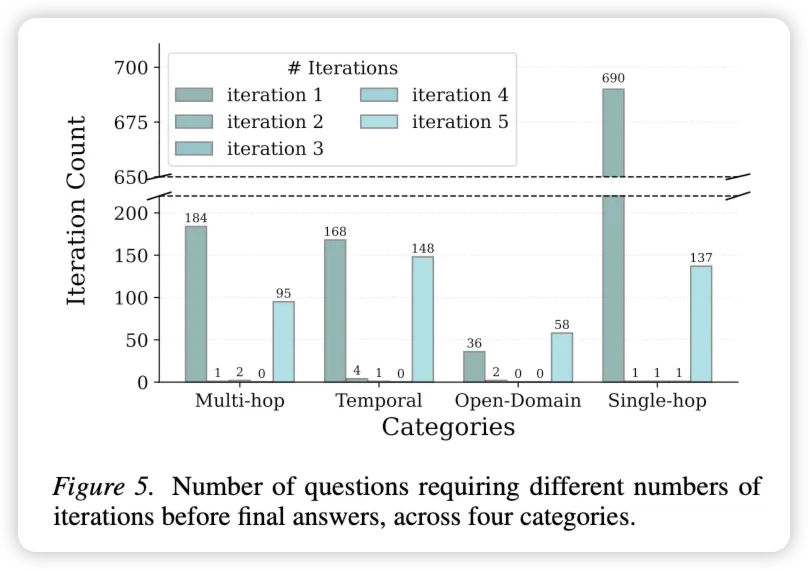
- 如图 5 所示,绝大多数问题(尤其是单跳问题)在第 1 次迭代时就解决了。
- 只有开放域 (Open-Domain) 问题会经常耗尽 5 次迭代预算。