点云级融合
车载点云级感知融合算法概览
1. 融合层次划分
| 层次 | 关键特点 | 典型实现 |
|---|---|---|
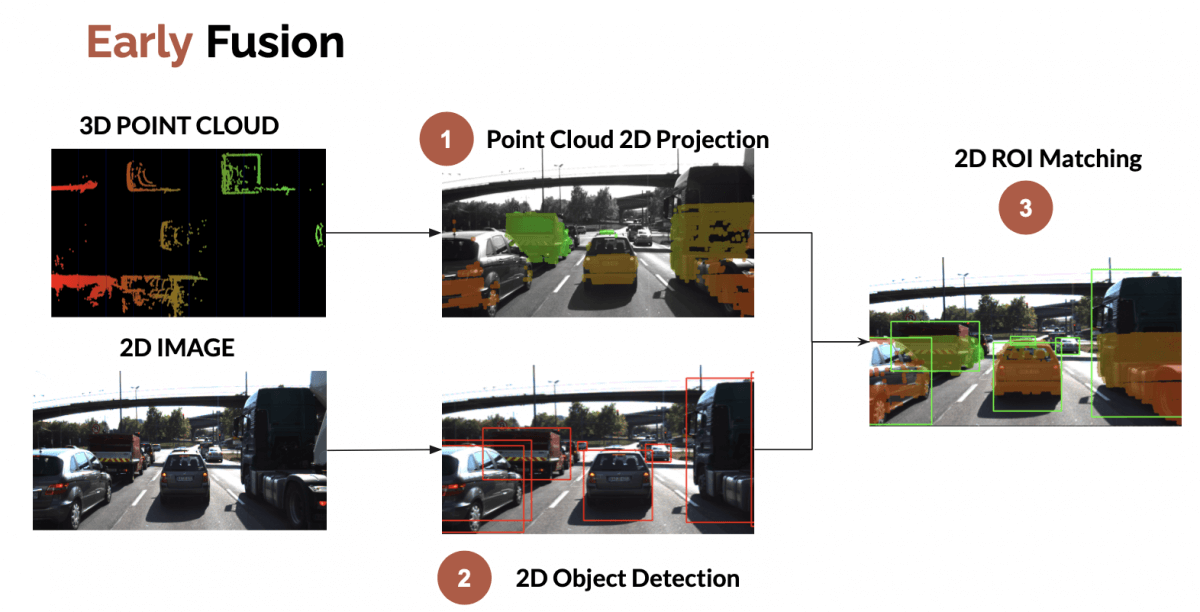
| 数据层融合(Early Fusion) | 直接在原始点云或图像像素上进行配准、投影,形成统一的输入(如点云‑图像混合体) | 将图像特征映射到点云坐标系后统一送入 3D 检测网络 |
| 特征层融合(Feature‑Level Fusion) | 分别提取点云特征(PointNet、VoxelNet 等)和图像特征(CNN),在中间层通过拼接、注意力或 Transformer 融合 | PointFusion、MV3D、BEVFusion 等均采用此思路 |
| 决策层融合(Late Fusion) | 各传感器独立完成检测后,对检测框进行概率级或几何级融合 | 传统多模态系统常用的 NMS 融合方式 |
点云级融合(Point-Level Fusion) 是"前融合(Early Fusion)"的一种深度形式,通常发生在目标检测之前。
它的核心思想是:与其让摄像头和激光雷达各自"猜"一遍再对答案,不如先把激光雷达的 3D 点云和摄像头的 2D 像素在原始数据层面结合起来,生成**"彩色点云"或"深度图像"**,然后再送入神经网络进行检测。
- 核心预处理:硬同步与投影
在进行算法融合前,必须完成极其精确的几何与时间对齐。
-
投影矩阵 (Projection):
-
利用联合标定外参,将 3D 点云 P(x,y,z)P(x,y,z) 投影到图像平面 p(u,v)p(u,v)。
-
公式:p=K×R∣T×Pp=K×R∣T×P(K为相机内参,R/T为外参)。
-
视锥过滤 (Frustum Filtering):
-
只保留投影在相机视场(FOV)内的点云,剔除相机看不到的后方/侧方点云,减少计算量。
- 主要的融合算法架构 A. 视锥点云融合 (Frustum PointNets) - 经典两阶段法
-
步骤 1 (2D Proposal): 先用 CNN 在图像上画出 2D 目标框。
-
步骤 2 (Frustum Extrusion): 将 2D 框沿视线向 3D 空间延伸,形成一个"视锥体(Frustum)",把落在里面的点云抠出来。
-
步骤 3 (PointNet): 对抠出来的这点点云进行 3D 实例分割和边框回归。
-
优势: 大大缩小了 3D 搜索范围,提高了小物体(如行人)的检测率。
B. 像素-点云对应融合 (PointPainting) - 工业界极常用 这是一个简单而极其有效的"给点云上色"的方法。
-
步骤 1 (Segmentation): 对图像进行语义分割,判断每个像素是"车"、"路"还是"树"。
-
步骤 2 (Painting): 将点云投影到分割后的图像上。
-
步骤 3 (Append Features): 将图像的类别分数(Class Scores)作为附加特征,拼接到点云数据上。
-
原始点云:(x,y,z,intensity)(x,y,z,intensity)
-
Painting后:(x,y,z,intensity,classcar,classpedestrian...)(x,y,z,intensity,classcar,classpedestrian...)
-
步骤 4: 将"增强版点云"送入标准的 LiDAR 检测网络(如 PointPillars 或 CenterPoint)。
-
效果: 激光雷达原本分不清什么是红绿灯,现在知道了;分不清是石头还是蹲着的人,现在知道了。
C. 特征级点云融合 (Feature-Level Fusion / Deep Fusion) 不直接拼接原始数据,而是在神经网络的中间层融合特征。
-
MV3D (Multi-View 3D Networks):
-
将点云转化为 BEV(俯视图)和 FV(前视图)特征图,将图像通过 CNN 提取特征图。
-
在网络的深层,通过 ROI Pooling 将对应位置的 LiDAR 特征和 Camera 特征进行拼接。
-
EPNet (Element-wise Point Fusion):
-
逐点融合。对于每一个 LiDAR 点,找到对应的图像特征向量,用来增强该点的表达能力,最后做检测。
D. 虚拟点云生成 (Pseudo-LiDAR) - 纯视觉模拟点云
-
步骤: 利用双目相机或单目深度估计网络(Depth Estimation),为图像中的每个像素生成深度值 (d)(d),从而反推 (x,y,z)(x,y,z) 坐标。
-
融合: 将生成的"伪点云"与真实的 LiDAR 点云合并(Densification,稠密化),或者直接替代 LiDAR(用于低成本方案)。
- 多模态 Transformer 融合 (当前 SOTA) 随着 Transformer 的兴起,基于 Query-Key-Value 的注意力机制成为了点云融合的新宠。
-
TransFusion / DeepInteraction:
-
不再需要严格的像素对齐(容忍一定的标定误差)。
-
Cross-Attention (交叉注意力): 让 LiDAR 的特征作为 Query,去图像特征(Key/Value)里"查询"相关的纹理信息。
-
网络会自动学习哪些图像特征对当前的 3D 检测有用。
- 4D 雷达与摄像头的点云融合 毫米波雷达的点云非常稀疏且噪点多,融合逻辑略有不同。
-
Radar-Camera Association Network:
-
由于雷达缺乏高度信息(3D 雷达),需要利用图像的纵向特征来约束雷达点的高度。
-
利用图像的语义信息过滤雷达的杂波(Clutter),例如:图像显示那是草地,那么该处雷达的反射点大概率是噪声。
- IMU 在点云融合中的角色
-
去畸变 (Deskewing):
-
LiDAR 扫描一圈需要 100ms。在这期间车在动。如果不处理,点云会"歪"。
-
融合算法利用 IMU 的高频角速度和加速度,通过插值计算每一束激光发射时的精确车身位姿,将扭曲的点云"拉直"回同一时刻。
- GNSS/SLAM 在点云融合中的角色
-
点云配准 (Registration / Scan Matching):
-
利用 GNSS 提供的初值,将当前帧点云与高精地图 (HD Map) 的点云进行匹配(ICP / NDT 算法)。
-
融合输出: 这不是为了检测障碍物,而是为了定位 (Localization) ------ 确定车在地图上的绝对位置。
总结:点云级融合的本质 点云级融合的核心在于**"互补"**:
-
LiDAR 提供准确的几何骨架(在哪、多大)。
-
Camera 提供丰富的语义皮肤(是什么颜色、是不是刹车灯)。
通过 PointPainting 或 Transformer 将两者结合,系统就能在夜间(视觉瞎)看清路,也能在远处(雷达稀疏)分清路牌。
2. 经典与主流算法
| 算法 | 融合方式 | 主要技术点 | 代表性成果 |
|---|---|---|---|
| PointFusion(CVPR 2018) | 特征层 | PointNet 提取点云特征、CNN 提取图像特征,后接全连接融合网络 | 直接输出 3D 边界框 |
| MV3D(CVPR 2017) | 特征层 | 采用点云俯视图 + 前视图 + 图像特征,3D Proposal + Region‑based Fusion | 在 KITTI 上取得领先性能 |
| AVOD / SECOND / PointPillars | 单模态(点云) | 体素化 + 轻量化卷积,适配实时部署 | 为后续融合提供高效点云特征骨干 |
| BEVFusion(地平线) | 特征层 + BEV 融合 | 将相机流和激光雷达流分别映射到 BEV,使用动态融合模块(attention → conv 替代)实现多任务感知 | NDS ≈ 0.64,FPS ≈ 31,已在征程 6 上部署 |
| MENet(武汉理工) | 特征层 | 将高精地图几何特征与点云深度信息统一到时空基准,实现尺度对齐,提升卡车/公交车检测精度 | |
| Adaptive Feature Fusion (Cooperative Perception) | 特征层 + 多车协同 | Pillar‑Feature‑Network → 2D CNN → 融合网络 → SSD 检测,支持跨车点云共享 | |
| CPD‑KD(2025) | 特征层 + 知识蒸馏 | 稀疏卷积 + 差异特征注意力,实现车‑路侧点云的高效融合,显著提升 DAIR‑V2X 上的检测精度 | |
| VRF (Vehicle‑Road‑side Fusion) | 特征层 + 离线对齐 | 将车载点云与路侧点云对齐到统一 3D 地图,预测对齐误差以降低延迟,端到端延迟 < 20 ms | |
| POINT CLUSTER(2025) | 特征层 + 通信高效 | 通过紧凑的点云消息单元实现协同感知,兼容 VoxelNet、Mask R‑CNN 等检测器 |
3. 最新研究趋势(2023‑2025)
-
BEV‑centric 融合:将所有传感器特征统一映射到俯视平面(BEV),便于多模态特征共享与后续任务(检测、分割、预测)统一处理。地平线的 BEVFusion 已在量产平台实现端到端 30 FPS。
-
差异特征注意力 & 知识蒸馏:CPD‑KD 通过注意力模块捕获车侧与路侧点云的差异信息,并利用知识蒸馏压缩模型体积,适配车载算力。
-
协同感知与通信效率:POINT CLUSTER 与 VRF 关注 V2X 场景下的点云压缩、对齐与低时延融合,推动车‑路协同感知向实际部署迈进。
-
多任务统一网络:BEVFusion 同时输出检测、占用预测(OCC)等多任务结果,提升感知系统的整体价值。
-
高精地图融合:MENet 将道路几何(车道曲率、路缘石)与点云深度统一,解决尺度不匹配问题,提升卡车等大目标检测鲁棒性。
4. 实际部署关键要点
| 环节 | 注意事项 | 常用技术 |
|---|---|---|
| 传感器标定 & 同步 | 必须保证时间戳对齐、外参精确;误差会导致特征错位 | Kalman‑filter 同步、硬件时间戳、ICP 精细对齐 |
| 点云预处理 | 地面去除、体素化、下采样以控制计算量 | VoxelGrid、Ground‑Segmentation、欧氏聚类 |
| 特征提取 | 轻量化稀疏卷积或 Pillar‑Net 兼顾精度与实时性 | SECOND、PointPillars、SparseConvNet |
| 融合策略 | 依据算力选取: ‑ 数据层 → 需要高精度标定 ‑ 特征层 → 更灵活、适配多任务 ‑ 决策层 → 可靠性高但延迟大 | Attention‑Fusion、Conv‑Fusion、Transformer‑Fusion |
| 模型压缩 & 加速 | 量产车端常采用 INT8 量化、网络剪枝、专用加速库 | Horizon HENet 替代 attention、TensorRT 优化 |
| 验证与安全 | 必须在真实道路、仿真平台(CARLA、V2X‑Set)进行端到端评估,确保 NDS、mAP 达标 | DAIR‑V2X、V2X‑Set 基准 |
小结:车载点云级感知融合已从最早的单模态点云检测,发展到多模态特征层融合、BEV‑centric 统一视图以及车‑路协同感知。当前主流方案在保证实时性的同时,借助注意力、Transformer、知识蒸馏等技术提升跨传感器特征互补性,并通过模型压缩与硬件加速实现量产部署。未来的研究重点仍将围绕 高效通信、跨车协同、以及更精准的地图‑点云融合 进行深入。