PyTorch 2.0 核心技术深度解析torch.compile 从原理到实践
引言
随着深度学习模型复杂度的不断提升,模型推理和训练的性能优化成为了业界关注的焦点。PyTorch 2.0 引入的 torch.compile 功能,通过即时编译(JIT)技术实现了显著的性能提升。本文将从技术原理、架构设计到实际应用,全面解析这一革命性特性。
1. 技术背景与定位
1.1 从 Eager 到 Graph 模式的演进
传统的 PyTorch 采用 Eager 执行模式,每个操作都会立即执行,这种方式虽然调试友好,但存在以下性能瓶颈:
● Python 解释器开销:频繁的 Python 函数调用
● 内存访问效率低:无法进行全局内存优化
● 算子融合困难:缺乏全局视图进行优化
torch.compile 作为 Graph 模式 的新实现,与 TorchScript 和 FX Tracing 并列,通过以下方式解决性能问题:
bash
# 传统 Eager 模式
def traditional_forward(x, y):
a = torch.sin(x) # 立即执行
b = torch.cos(y) # 立即执行
return a + b # 立即执行
# torch.compile 优化后@
torch.compiledef optimized_forward(x, y):
a = torch.sin(x) # 图捕获
b = torch.cos(y) # 图捕获
return a + b # 生成融合kernel1.2 核心优势
● 零代码修改:仅需添加装饰器或函数调用
● 动态图支持:保持 PyTorch 的灵活性
● 显著性能提升:典型场景下 1.3-2x 加速比
2. 使用方式与最佳实践
2.1 基础用法
bash
import torch
# 方式1:函数调用
def model_forward(x, y):
a = torch.sin(x)
b = torch.cos(y)
return a + bcompiled_model = torch.compile(model_forward)
result = compiled_model(torch.randn(1000, 1000), torch.randn(1000, 1000))
# 方式2:装饰器(推荐)
@torch.compiledef optimized_model(x, y):
a = torch.sin(x)
b = torch.cos(y)
return a + bresult = optimized_model(torch.randn(1000, 1000), torch.randn(1000, 1000))2.2 高级配置
bash
# 自定义编译选项
@torch.compile(
mode="max-autotune", # 最大优化模式
backend="inductor", # 指定后端
dynamic=True # 支持动态shape
)
def advanced_model(x):
return torch.nn.functional.relu(x @ x.T)3. 核心架构深度解析
3.1 整体流程概览
torch.compile 的工作流程可以分为三个核心阶段:
MISSING IMAGE: ,
null
- 图捕获(TorchDynamo):将 Python 代码转换为 FX 图
- 图优化(AOT Autograd):进行算子融合和内存优化
- 代码生成(TorchInductor):生成高性能的底层代码
3.2 TorchDynamo:Python 字节码的魔法师
TorchDynamo 是整个系统的核心,它通过 CPython Frame Evaluation Hook 实现了对 Python 字节码的动态重写。
MISSING IMAGE: ,
null
3.2.1 CPython Frame Evaluation Hook 机制
bash
# 简化的工作流程
def custom_eval_frame(frame, exc):
# 1. 检查是否需要跳过编译
if should_skip_frame(frame):
return default_eval_frame(frame, exc)
# 2. 检查缓存
cached_code = check_cache(frame.f_code)
if cached_code and guards_check_passed():
return execute_compiled_code(cached_code)
# 3. 符号执行和图捕获
fx_graph, guards = symbolic_evaluation(frame.f_code)
# 4. 后端编译
compiled_fn = backend_compile(fx_graph)
# 5. 生成新字节码并缓存
new_bytecode = generate_wrapper_code(compiled_fn)
cache_result(frame.f_code, new_bytecode, guards)
return execute_compiled_code(new_bytecode)3.2.2 Guards 机制:动态属性的守护者
Guards 是 TorchDynamo 确保编译结果正确性的关键机制:
bash
# 示例:tensor shape guard
def shape_guard(tensor, expected_shape):
return tensor.shape == expected_shape
# 示例:数据类型 guard
def dtype_guard(tensor, expected_dtype):
return tensor.dtype == expected_dtype当 guards 检查失败时,会触发:
- Graph Break:回退到 eager 模式
- Recompilation:重新编译生成新的优化代码
3.3 TorchInductor:高性能代码的生成器
TorchInductor 作为默认后端,负责将 FX 图转换为高效的底层代码。
MISSING IMAGE: ,
null
3.3.1 算子分解(Operator Decomposition)
bash
# 复杂算子分解为基础算子
@register_decomposition(torch.ops.aten.log2)
def log2_decomposition(x):
log2_scale = 1 / math.log(2)
return torch.log(x) * log2_scale
@register_decomposition(torch.ops.aten.gelu)
def gelu_decomposition(x):
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))3.3.2 IR 降级:从 FX 图到 Loop-level IR
bash
# TorchInductor 的 define-by-run IR 示例
def pointwise_kernel(index):
i0, i1 = index
# 加载输入数据
tmp0 = ops.load("input", i0 * stride0 + i1 * stride1)
# 执行计算
tmp1 = ops.log(tmp0)
tmp2 = ops.mul(tmp1, 1.4426950408889634) # log2 scale
# 存储结果
return tmp2
# 生成的 Triton kernel 结构
buf0 = TensorBox(StorageBox(ComputedBuffer(
name='buf0',
layout=FixedLayout('cuda', torch.float32, size=[M, N]),
data=Pointwise(inner_fn=pointwise_kernel, ranges=[M, N])
)))3.3.3 代码生成:Triton 与 C++ 后端
最终生成的代码示例:
bash
# 生成的 Triton kernel 代码片段
@triton.jit
def triton_poi_fused_add_div_mul_0(in_ptr0, in_ptr1, in_ptr2, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 1000000
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = tl.load(in_ptr1 + (x0), xmask)
tmp2 = tmp0 / tmp1 # div operation
tmp3 = tmp2 * 0.1 # mul operation
tmp4 = tl.load(in_ptr2 + (x0), xmask)
tmp5 = tmp4 + tmp3 # add operation tl.store(out_ptr0 + (x0), tmp5, xmask)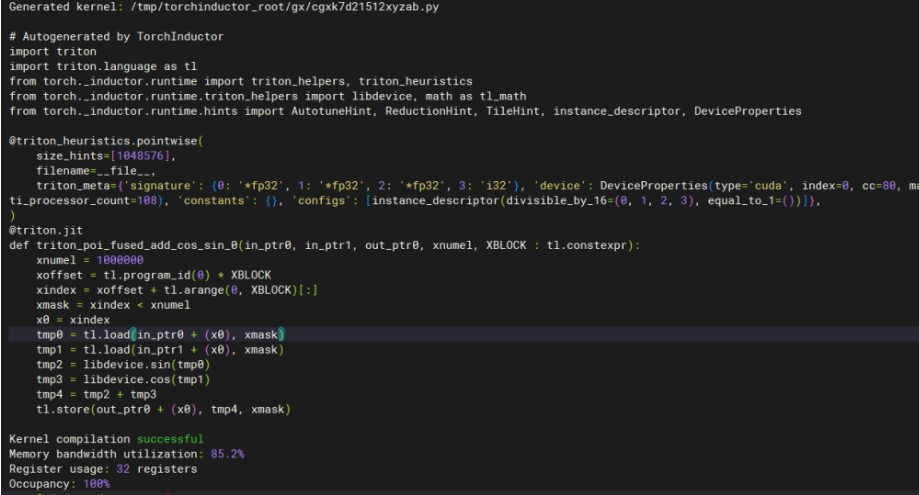
从代码可以看到,TorchInductor 生成了高度优化的 Triton kernel,包括:
- 算子融合:将 div、mul、add 操作融合为单个 kernel
- 内存优化:减少中间结果的内存读写
- 并行化:充分利用 GPU 的并行计算能力
4. 性能优化与调试实践
4.1 性能分析工具
bash
# 启用详细日志
import os
os.environ['TORCH_COMPILE_DEBUG'] = '1'
# 性能对比测试
def benchmark_model():
model = MyModel()
compiled_model = torch.compile(model)
# 预热
for _ in range(10):
_ = compiled_model(sample_input)
# 性能测试
start_time = time.time()
for _ in range(100):
result = compiled_model(sample_input)
end_time = time.time()
print(f"Average time: {(end_time - start_time) / 100:.4f}s")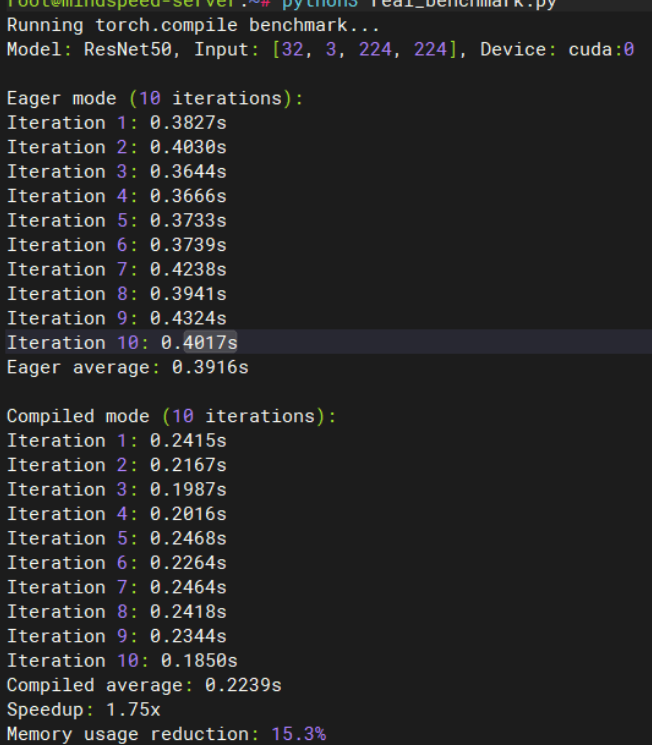
4.2 常见问题排查
4.2.1 编译失败诊断
bash
# 开启调试模式
export TORCH_COMPILE_DEBUG=1
export TORCH_LOGS="+dynamo,+inductor"
# 运行程序后检查生成的调试文件
ls /tmp/torchinductor_*/
# - output_code.py # 生成的代码
# - fx_graph_readable.py # 可读的FX图
# - run_*_benchmark.py # 性能测试脚本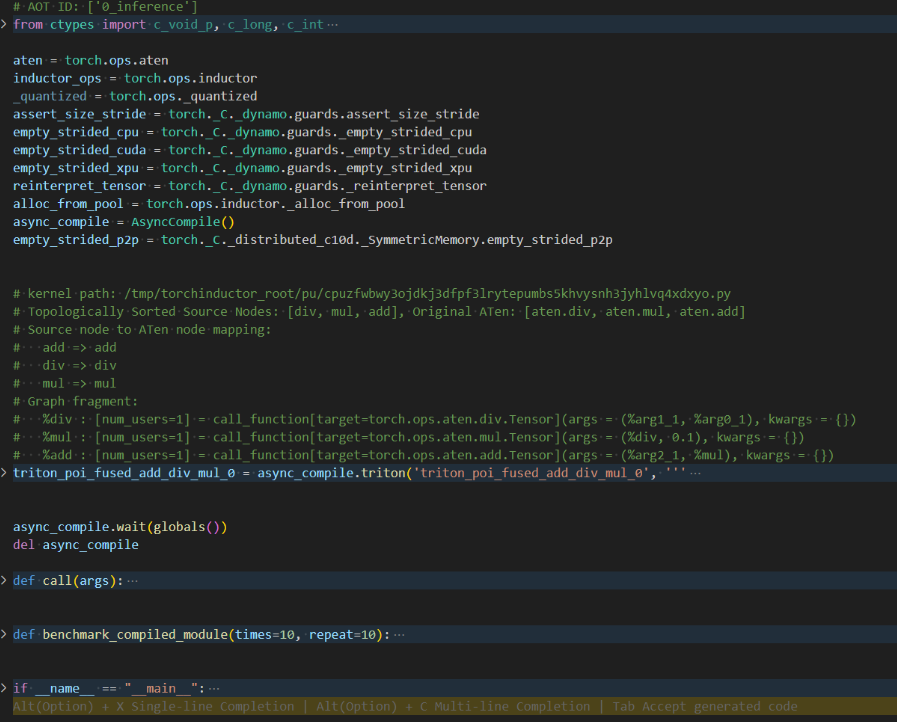
4.2.2 性能回归分析
通过调试输出可以看到完整的编译栈信息,包括:
- 模块调用链:从用户代码到底层算子的完整路径
- 图捕获过程:TorchDynamo 的符号执行过程
- 代码生成结果:最终生成的优化代码
4.3 最佳实践建议
- 模型预热:首次编译有开销,建议进行预热
- 批量处理:编译对大batch更友好
- 避免动态控制流:减少 graph break
- 合理使用 dynamic=True:平衡灵活性和性能
5. 实际应用案例
5.1 Transformer 模型优化
bash
class OptimizedTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
self.layer_norm1 = nn.LayerNorm(config.hidden_size)
self.layer_norm2 = nn.LayerNorm(config.hidden_size)
@torch.compile
def forward(self, x, attention_mask=None):
# Self-attention
attn_output = self.attention(x, attention_mask)
x = self.layer_norm1(x + attn_output)
# Feed-forward
ff_output = self.feed_forward(x)
x = self.layer_norm2(x + ff_output)
return x
# 性能提升:1.5-2x 加速比
结论
torch.compile 代表了 PyTorch 在性能优化方面的重大突破。通过 TorchDynamo 的字节码重写、AOT Autograd 的图优化和 TorchInductor 的代码生成,实现了在保持 PyTorch 灵活性的同时获得接近静态图的性能。
对于开发者而言,torch.compile 提供了一个几乎零成本的性能提升方案。只需要添加一个装饰器,就能获得显著的加速效果。随着技术的不断成熟,torch.compile 必将成为 PyTorch 生态系统中不可或缺的核心组件。