文章目录
-
- [1. 深度学习与PyTorch简介](#1. 深度学习与PyTorch简介)
- [2. 环境配置与数据准备](#2. 环境配置与数据准备)
-
- [2.1 环境检查](#2.1 环境检查)
- [2.2 数据加载与预处理](#2.2 数据加载与预处理)
- [2.3 数据可视化](#2.3 数据可视化)
- [2.4 数据批量加载](#2.4 数据批量加载)
- [3. 神经网络模型设计](#3. 神经网络模型设计)
-
- [3.1 设备选择](#3.1 设备选择)
- [3.2 神经网络架构](#3.2 神经网络架构)
- [3.3 模型实例化](#3.3 模型实例化)
- [4. 训练与评估流程](#4. 训练与评估流程)
-
- [4.1 训练函数](#4.1 训练函数)
- [4.2 测试函数](#4.2 测试函数)
- [5. 损失函数配置](#5. 损失函数配置)
- [6. 模型训练与评估](#6. 模型训练与评估)
-
- [6.1 优化器配置](#6.1 优化器配置)
- [6.2 单次训练与测试](#6.2 单次训练与测试)
- [6.3 多轮训练(可选)](#6.3 多轮训练(可选))
- [7. 提高准确率的优化方式](#7. 提高准确率的优化方式)
1. 深度学习与PyTorch简介
深度学习作为机器学习的重要分支,已在计算机视觉、自然语言处理等领域取得了显著成果。PyTorch是由Facebook开源的深度学习框架,以其动态计算图和直观的API设计而广受欢迎。本文以经典的MNIST手写数字数据集为例,展示如何利用PyTorch框架构建并训练深度学习模型。
2. 环境配置与数据准备
2.1 环境检查
首先检查PyTorch及相关库的版本,确保环境配置正确:
python
import torch
import torchvision
import torchaudio
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from matplotlib import pyplot as plt
print(torch.__version__)
print(torchaudio.__version__)
print(torchvision.__version__)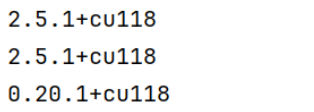
2.2 数据加载与预处理
MNIST数据集包含60,000个训练样本和10,000个测试样本,每个样本为28×28像素的灰度手写数字图像。
python
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)参数:
root:数据存储路径train:是否为训练集download:是否自动下载transform:数据预处理转换,ToTensor()将PIL图像转换为张量并归一化到0,1
2.3 数据可视化
我们可以查看数据集的样本分布:
python
print(len(training_data))
figure = plt.figure()
for i in range(9):
img, label = training_data[i + 59000]
figure.add_subplot(3, 3, i + 1)
plt.title(label)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

2.4 数据批量加载
使用DataLoader实现数据的批量加载和随机打乱:
python
# 增加批次大小
train_dataloader = DataLoader(training_data, batch_size=128) # 增大batch size
test_dataloader = DataLoader(test_data, batch_size=128)
for X, y in test_dataloader:
print(f"Shape of X[N,C,H,W]:{X.shape}")
print(f"Shape of y:{y.shape} {y.dtype}")
break
3. 神经网络模型设计
3.1 设备选择
根据可用硬件选择计算设备:
python
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
3.2 神经网络架构
设计一个包含多个全连接层的深度神经网络:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.a = 10
self.flatten = nn.Flatten()
原始架构
self.hidden1 = nn.Linear(28 * 28, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
# 原始前向传播
x = self.flatten(x)
x = self.hidden1(x)
x = torch.sigmoid(x)
x = self.hidden2(x)
x = torch.sigmoid(x)
return x3.3 模型实例化
python
model = NeuralNetwork().to(device)
print(model)
4. 训练与评估流程
4.1 训练函数
python
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
if batch_size_num % 100 == 0:
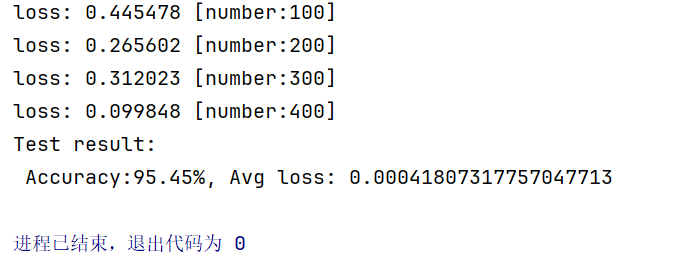
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1训练步骤:
model.train():设置为训练模式(启用Dropout)- 前向传播计算预测值
- 计算损失函数值
optimizer.zero_grad():清空梯度loss.backward():反向传播计算梯度optimizer.step():更新模型参数
4.2 测试函数
python
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss = loss_fn(pred, y)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y)
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
print(f"Test result:\n Accuracy:{(100 * correct):.2f}%, Avg loss: {test_loss}")测试要点:
model.eval():设置为评估模式(禁用Dropout)torch.no_grad():禁用梯度计算,节省内存pred.argmax(1):获取预测类别
5. 损失函数配置
python
loss_fn = nn.CrossEntropyLoss()损失函数说明:
- 使用
CrossEntropyLoss,适用于多分类问题 - 结合了LogSoftmax和NLLLoss,直接输出分类概率
6. 模型训练与评估
6.1 优化器配置
python
# 原始优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)6.2 单次训练与测试
python
train(train_dataloader, model, loss_fn, optimizer)
test(train_dataloader, model, loss_fn)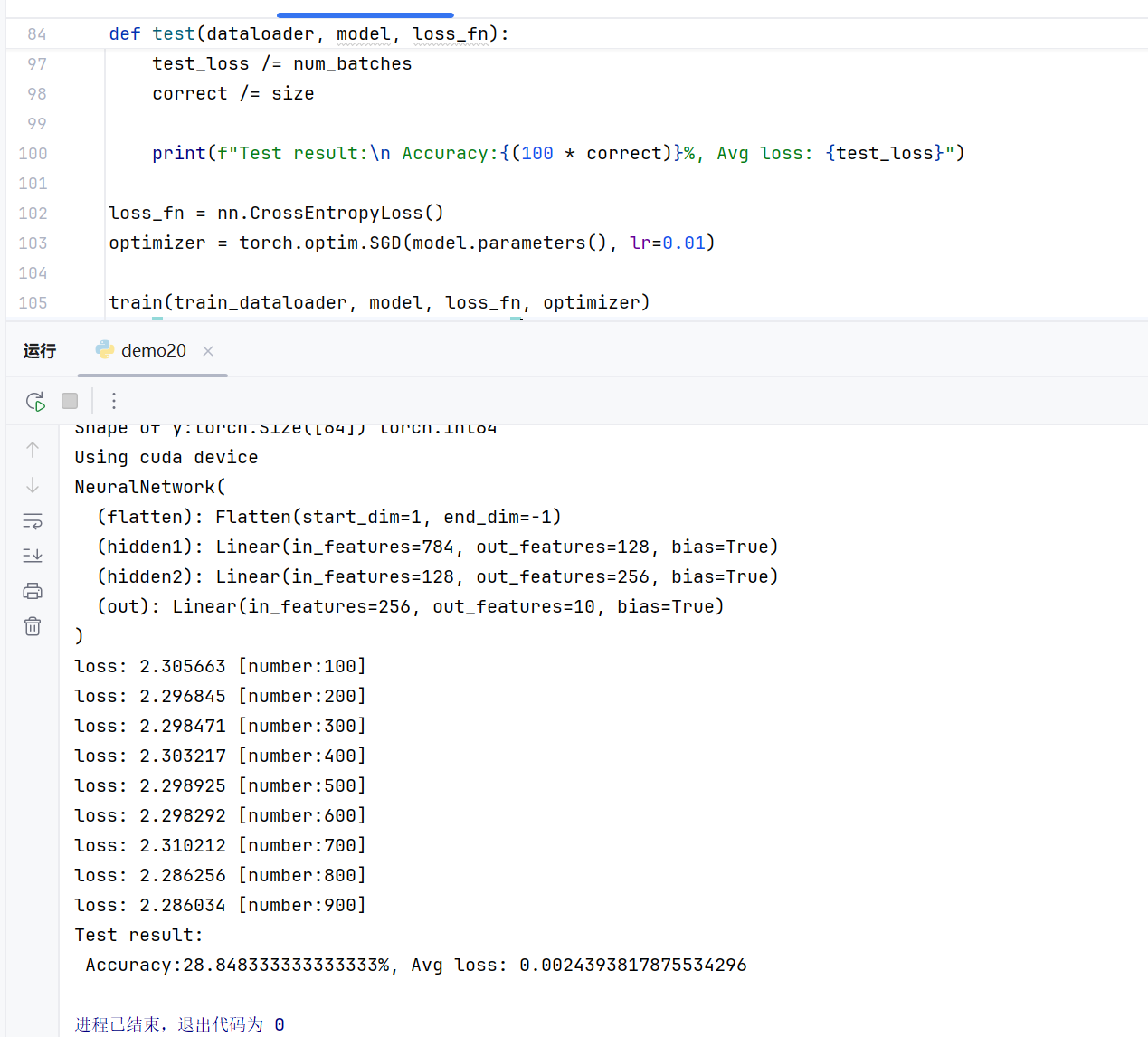
6.3 多轮训练(可选)
python
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n----------------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)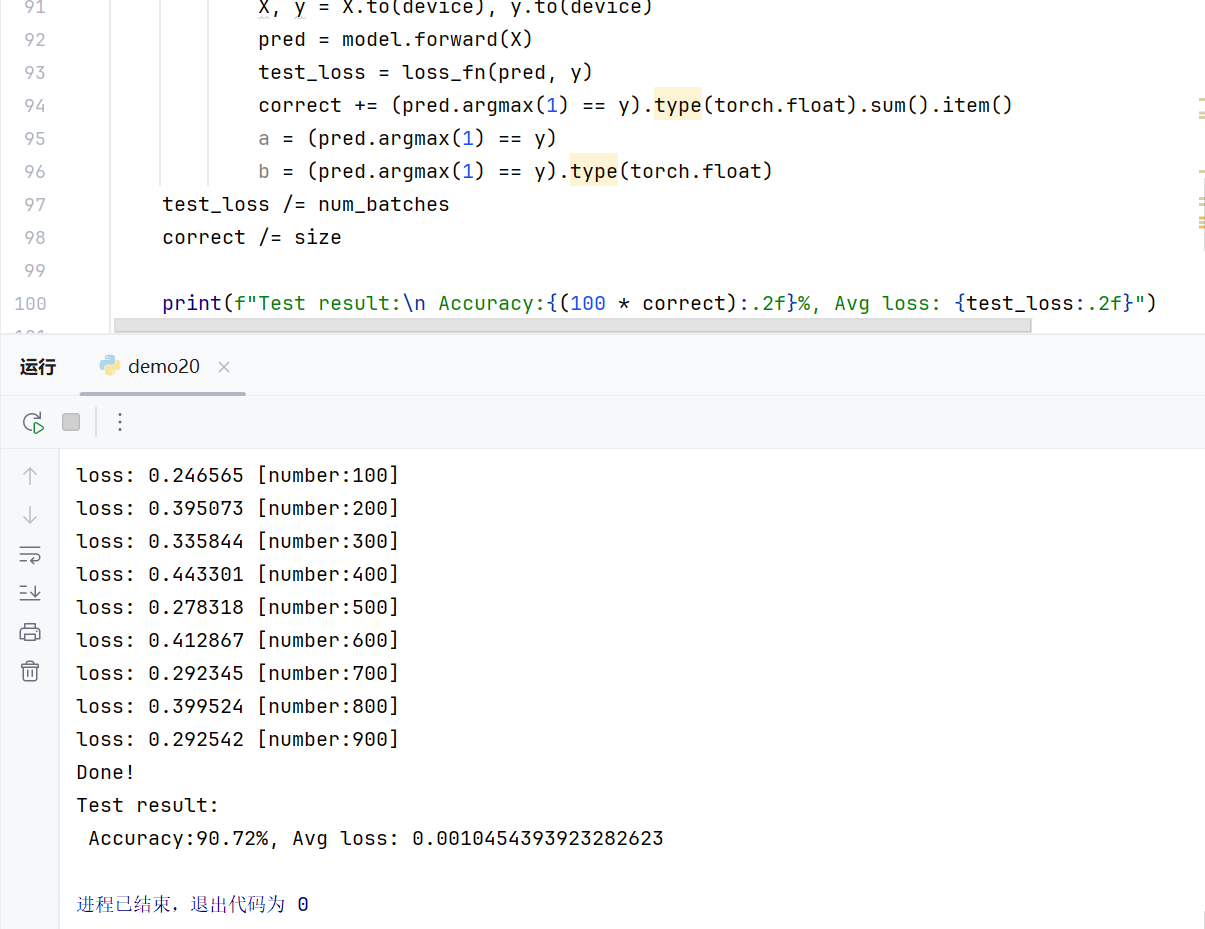
7. 提高准确率的优化方式
- 层数增加:从2层隐藏层增加到3层,增强模型表达能力
- 神经元增加:第一层从128个神经元增加到512个
- 激活函数:用ReLU替代sigmoid,缓解梯度消失问题
- 正则化:添加Dropout层(0.2丢弃率),防止过拟合
- 改进优化器:降低学习率
python
# 改进架构
self.hidden1 = nn.Linear(28 * 28, 512) # 增加神经元
self.dropout1 = nn.Dropout(0.2) # 添加Dropout
self.hidden2 = nn.Linear(512, 256)
self.dropout2 = nn.Dropout(0.2) # 添加Dropout
self.hidden3 = nn.Linear(256, 128) # 增加一层
self.out = nn.Linear(128, 10)
python
# 改进的前向传播
x = self.flatten(x)
x = self.hidden1(x)
x = torch.relu(x) # 使用ReLU替代sigmoid
x = self.dropout1(x) # 训练时随机丢弃
x = self.hidden2(x)
x = torch.relu(x) # 使用ReLU替代sigmoid
x = self.dropout2(x) # 训练时随机丢弃
x = self.hidden3(x)
x = torch.relu(x)
x = self.out(x)
python
# 改进优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 降低学习率