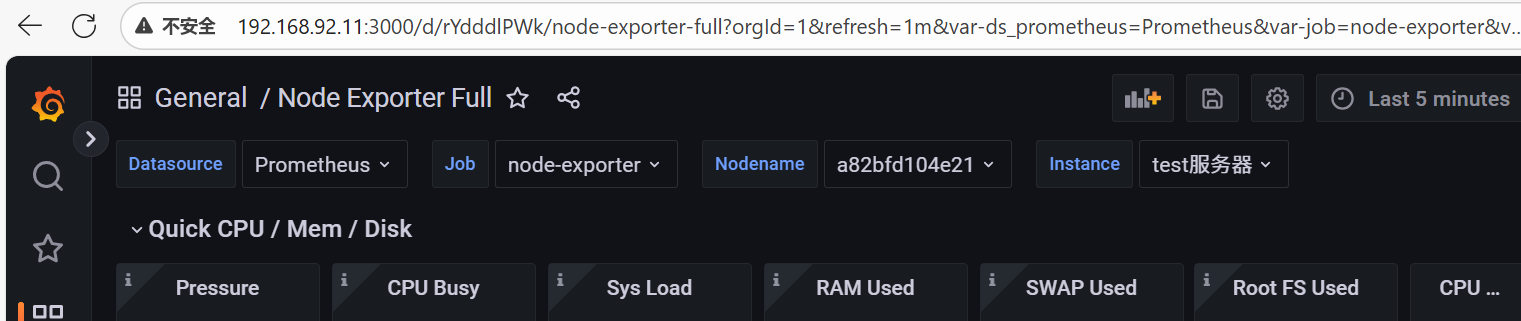
**监控Linux操作系统,Prometheus监控栈:**Prometheus + Alertmanager + Grafana
一、环境介绍
1.1 主机清单
| 职责 | ip地址 | 备注 |
|---|---|---|
| Prometheus服务器 | 192.168.92.11 | docker模式的prometheus |
| 待监控Linux | 192.168.92.12 | 待准备组件:docker+compose+node exporter |
1.2 调用链路图
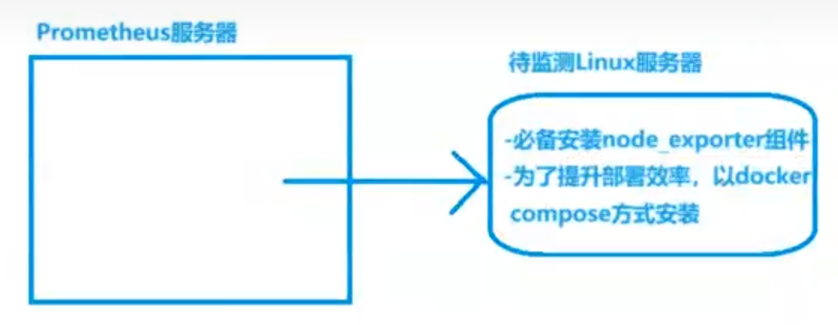
二、待监控Linux机准备
2.1 rockylinux9.6安装
略
2.2 调整ip地址
vi /etc/NetworkManager/system-connections/ens160.nmconnection
[ipv4]
method=manual
address=192.168.92.12/24,192.168.92.2 # IP 地址和子网掩码,网关
dns=114.114.114.114,8.8.8.8 # DNS 服务器
ipv6部分不用改2.3 调整host名称
#修改hosts文件
cd /etc
vi hosts
#录入以下内容,:x保存并退出
192.168.92.11 prometheus
192.168.92.12 test #待检测的linux服务器2.4 安装docker环境
配置yum的docker源
略
安装docker
略
检查docker服务是否启动且开机自启动
systemctl start docker
systemctl enable docker
systemctl status docker查看docker版本能运行出,版本号说明安装成功
docker -v2.5 安装docker-compose环境
#从github中拉取下载docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-Linux-x86_64" -o /usr/local/bin/docker-compose
#设置文件具备执行权限
sudo chmod +x /usr/local/bin/docker-compose
#查看已安装的版本,如果能正常输出版本号说明安装compose完毕
docker-compose -v 三、安装node_exporter
192.168.92.12的test上,以docker-compose方式快速安装node_exporter
3.1 创建node_exporter文件夹
mkdir /data/node_exporter -p
cd /data/node_exporter3.2创建docker-compose.yaml文件
root@test node_exporter# vi docker-compose.yaml
version: '3.3'
services:
node-exporter: #node-exporter 配置是用于收集宿主机硬件和操作系统指标的核心部分
image: prom/node-exporter:v1.8.0 #指定使用官方 node-exporter 镜像的 v1.8.0 版本。
container_name: node-exporter # 将容器命名为 node-exporter,便于管理。
restart: always # 容器退出时自动重启,确保监控持续不间断。
volumes:
- /proc:/host/proc:ro #挂载 /proc 虚拟文件系统。这是内核和进程信息的宝库,用于获取CPU使用率、内存详情、进程列表等。
- /sys:/host/sys:ro #挂载 /sys 虚拟文件系统。这里暴露了硬件设备、驱动和内核参数,用于获取磁盘I/O、网络统计、温度传感器等数据。
- /:/rootfs:ro #挂载 根文件系统。主要用于计算整个主机及各磁盘分区的使用情况。
command:
- '--path.procfs=/host/proc' # 指定进程信息系统的路径为容器内的 /host/proc(即我们挂载的位置)。
- '--path.sysfs=/host/sys' # 指定系统文件系统的路径为容器内的 /host/sys。
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host)' #优化参数。使用正则表达式忽略虚拟文件系统的挂载点(如 /sys, /proc, /dev),避免采集无用的磁盘指标,减少数据干扰。
ports: #端口映射。将容器内的 9100 端口(node-exporter 的默认指标暴露端口)映射到宿主机的 9100 端口。
- '9100:9100' 3.3 docker-compose方式部署Node_exporter
cd /data/node_exporter
docker-compose up检查
#查看docker的images镜像列表
docker images
#查看docker的实例容器列表
docker ps -a访问node_exporter的监控url
http://192.168.92.12:9100/metrics
四、Prometheus的服务器上添加待监控的Linux机器
192.168.92.11的prometheus上,修改prometheus的配置文件
#进入docker-prometheus目录
cd /data/docker-prometheus
#修改prometheus.yml
vi prometheus/prometheus.yml添加待监控的Linux服务器(test)
# 4. Node Exporter 主机监控,监控Linux主机指标的工具
- job_name: 'node-exporter'
scrape_interval: 15s
static_configs:
- targets: ['node-exporter:9100']
labels:
instance: 'Prometheus服务器'
#添加待监控的linux服务器
- targets: ['192.168.92.12:9100']
labels:
instance: 'test服务器'保存配置后,让配置生效
#prometheus的虚拟机上执行
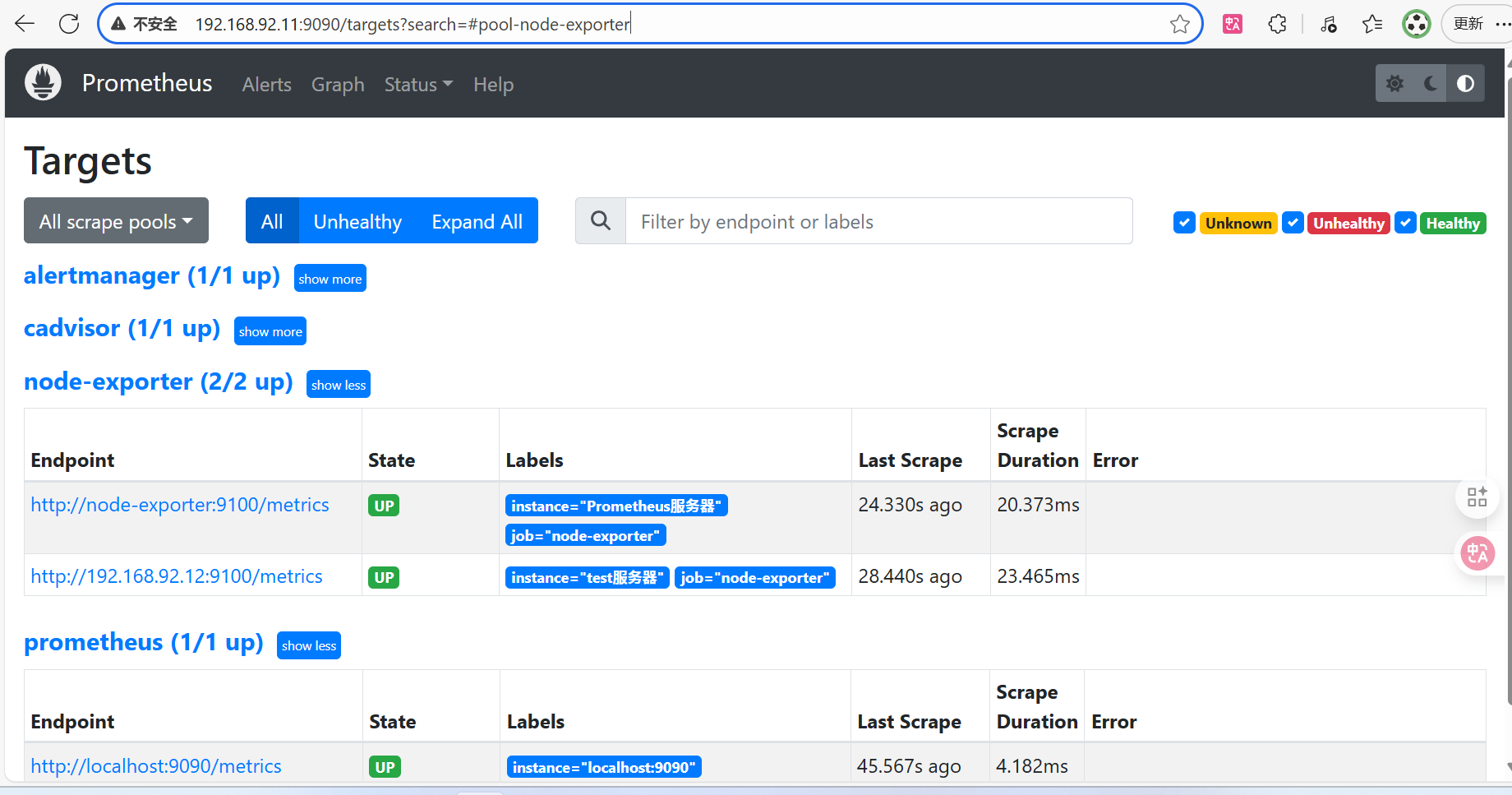
curl -X POST http://localhost:9090/-/reload刷新访问http://192.168.92.11:9090/targets?search=,确认新监控的test服务器是否生效
五、常用的Linux服务器监控指标
。CPU
。内存
。硬盘
。网络流量
。文件描述符
。系统负载
。系统服务
5.1 cpu监控
CPU的监控项名称是:node_cpu_seconds_total,使用总量
直接执行node_cpu_seconds_total查询后会出现很多监控指标,显然不是想要的
node_cpu_seconds_total执行后会出现很多监控指标,其中各种类型的比如系统态、用户态都会由mode标签来区分
我们想要查询CPU的使用率的思路是:
。查出当前空闲的CPU百分比,最后用100减去,mode标签值idle就表示当前空闲的CPU值
node_cpu_seconds_total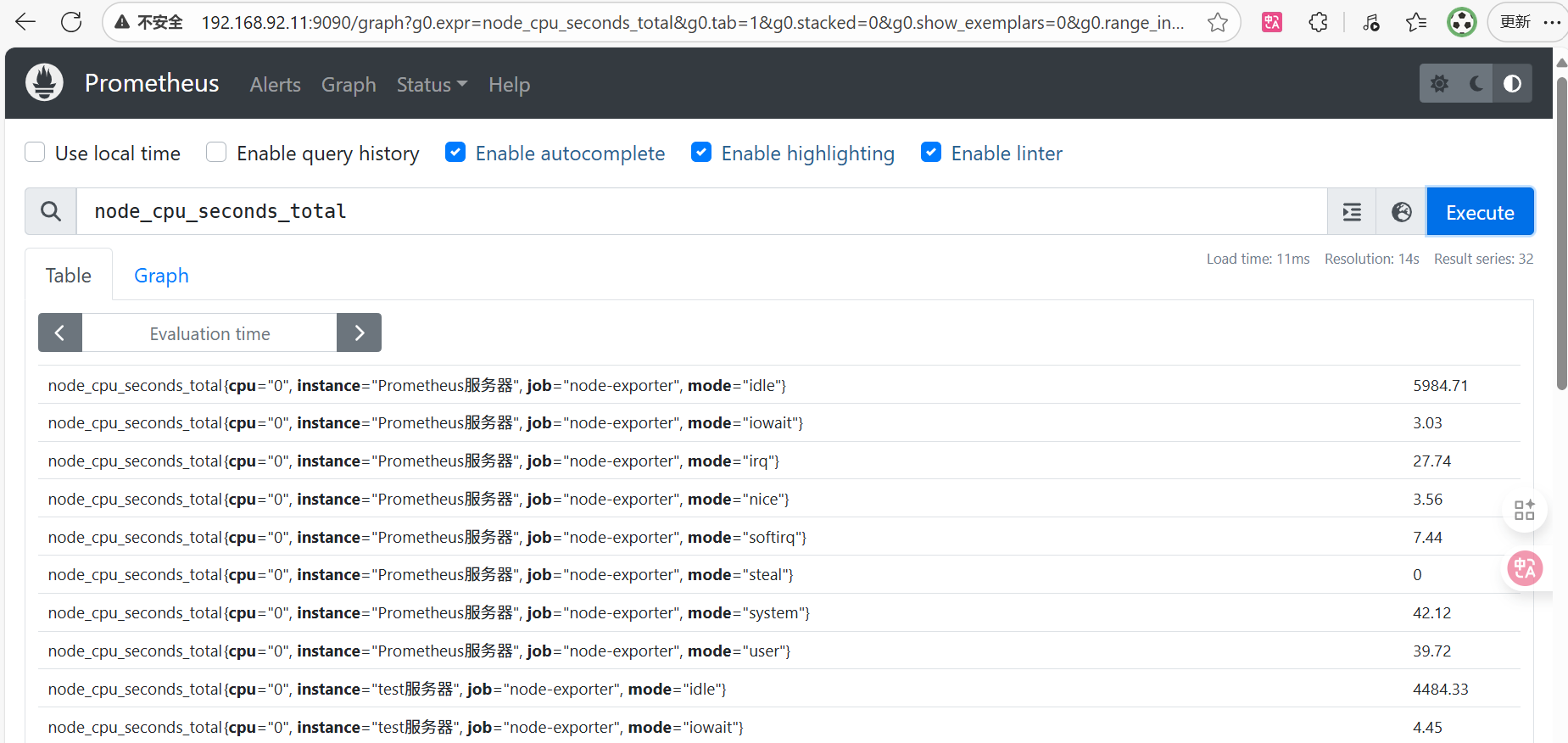
cpu="0"代表第1核cpu
cpu="1"代表第2核cpu
。获取空闲cpu监控数据
mode标签值为idle的为空闲(user代表mode为用户,system代表mode为系统...)
node_cpu_seconds_total{mode='idle'}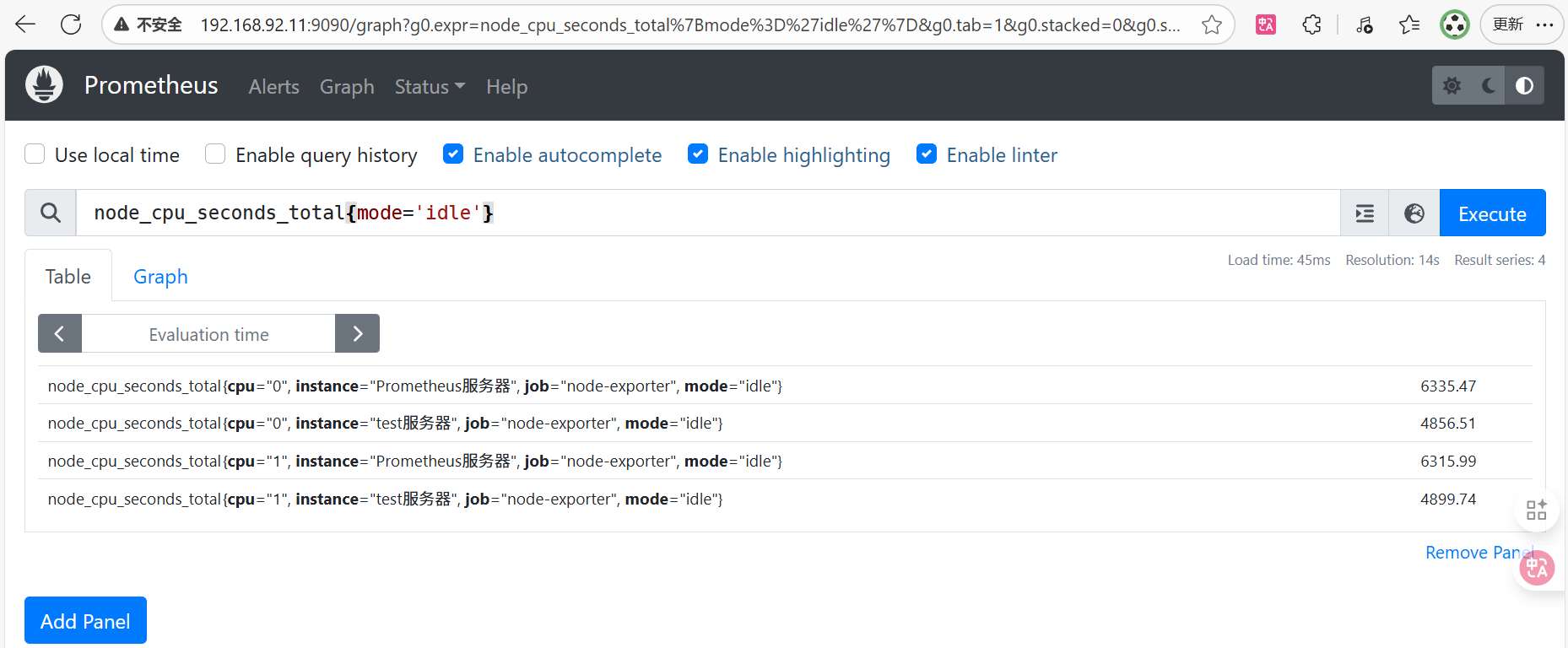
。获取某台监控机器的cpu数据 instance标签值为test服务器的cpu数据
node_cpu_seconds_total{instance='test服务器'}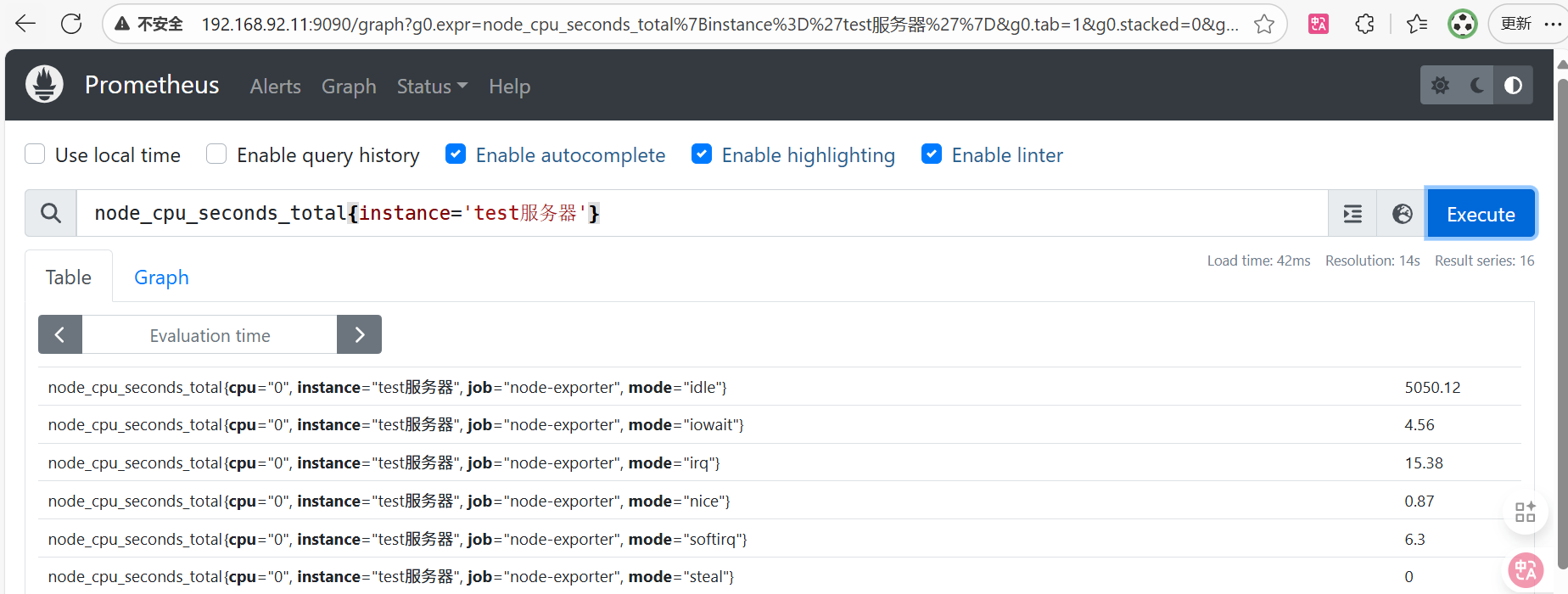
。获取1分钟/5分钟/15分钟的cpu负载
node_load1
node_load5
node_load15。获取5分钟内的监控数据
之前虽然可以查出来结果,但是不太理想,因为CPU是不断波动的,我们可以在增加一个条件,查询5分钟内的一个CPU使用情况
node_cpu_seconds_total{mode='idle'}[5m]。获取5分钟内的cpu平均空闲状况
我们可以使用irare和avg函数结合刚才查询出5分钟内数据做一个平均情况展示 函数的使用方法:函数(指标获取方式)
avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)
#by(instance)表示以instance标签进行分组。获取cpu5分钟内的使用率 最后我们可以*100得出一个百分比的空闲率,再由100-可得到CPU的使用率
100 -(avg(irate(node_cpu_seconds_total{mode='idle'}[5m]))by(instance)*100)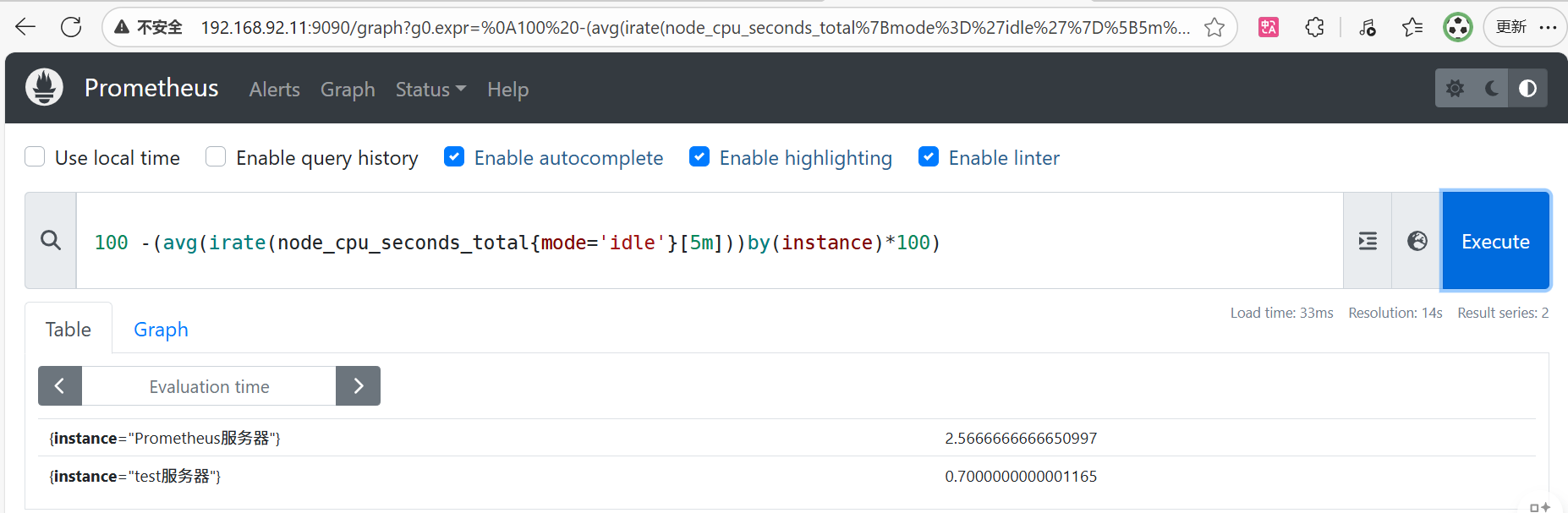
5.2 内存监控
由于内存的监控项没有像C9一样区分了很多标签,因此内存监控相较于CPU则需要结合很 多个监控项
node_memory_MemFree_bytes//空闲内存 node_memory_MemTotal_bytes//总内存 node_memory_Cached_bytes //缓存 node_memory_Buffers_bytes //缓冲区内存
监控内存使用的思路:
1.空闲内存+绥存+绥冲区内存得出空闲总内存
2.得出的空闲总内存再除总内存大小再乘100,得出空闲率
3.再用100-空闲率就得出使用率
。首先是获取空闲内存
node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes。获取可用内存百分比
(node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)/node_memory_MemTotal_bytes *100。获取内存使用率
(100 - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100) 5.3 磁盘使用率
关于磁盘使用率,这里我们用到的主要有:
node_filesystem_free_bytes //剩余磁盘空间
node_filesystem_size_bytes //磁盘空间总大小
node_disk相关
这两个监控项中都有相同的标签可以关联,我们这里用到的标签有fstype,scype标签值是关于磁盘的文件系统类型,对于磁盘监控,我们主要对xfs、ext4等文件系统的磁盘进行监控,像tmpfs这种的不必要监控,另一个主要的标签是mountpoint,这个标签值主要用来储存磁盘的挂载点,我们可以通过标签来选择要对那个挂载点的磁盘进行监控
磁盘使用率实现思路:
1.由磁盘空闲容量除磁盘总容量乘100即可得到磁盘空闲率
2.用100减磁盘空闲率即可得到磁盘使用率
。首先是获取磁盘空闲率百分比,代表磁盘的剩余空间比例。
node_filesystem_free_bytes / node_filesystem_size_bytes * 100
#linux中获取磁盘空闲率命令
df -hT。获取磁盘使用率百分比
100 * (1 - node_filesystem_free_bytes / node_filesystem_size_bytes)5.4 网络采集
node_network_相关都属于网络采集数据
#网络流出流量
node_network_transmit_bytes_total
#网络流入流量
node_network_receive_bytes_total5.5 系统服务状态
监控服务的状态,例如nginx,docker这种服务器的启动状态
node exporter是根据systemd去监控的,因此只有能用systemctl启动的服务器才能被监控 到
配置非常简单,只需要在启动时开启system监控,并指定监控什么服务即可
配置system监控的参数:
--collector.systemd
--collector.systemd.unit-whitelist=".+"
5.5.1配置待监控Linux的node_exporter启动参数
Prometheus服务器(prometheus),以及待监控的Linux服务器(test)都要操作
vi /usr/lib/systemd/system/node-exporter.service
#添加以下内容
[Unit]
Description=Node Exporter
After=network.target
[Service]
Type=simple
User=root
Group=root
# Node Exporter可执行文件路径(根据实际情况修改)
ExecStart=/data/node_exporter/node_exporter \
--collector.systemd \
--collector.systemd.unit-whitelist="(ssh|docker|nginx|mysql|prometheus).service" \
--collector.textfile.directory=/var/lib/node_exporter/textfile_collector \
--web.listen-address=:9100 \
--web.telemetry-path=/metrics \
--log.level=info
# 如果需要限制内存使用
# MemoryMax=200M
# MemoryLimit=200M
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target重启服务
systemctl daemon-reload
systemctl restart node_exporter.service
systemctl status node-exporter5.5.2 查看服务的监控状态
以docker为例,我们查询docker存活状态
node_systemd_unit_state使用这个监控项查看,里面也有很多标签, name="docker.service",标签name表示服务的名称,state="active",state表示服务的状态,active表示活动的,对应的监控值也是1,如果为1则表示正常,不为1表示异常
node_systemd_unit_state{name="docker.service", state="active"}这里grafana可以看到两个虚拟机的node_exporter的信息