在医疗数字化与智慧医疗建设不断推进的背景下,稳定、准确的数据同步是数据平台能否长期运行的基础能力之一。医院信息系统复杂、历史数据体量大,一旦数据链路出现问题,影响的往往不仅是报表时效,还可能直接影响临床业务和监管统计。
某头部医疗数字化服务商长期服务于多家国内知名三甲医院,围绕智慧医疗建设需求,为多家医院构建了以实时数据同步和分层数仓为核心的数据平台。本文将分享该团队在数据架构设计与工具选型过程中的实践经验。
业务背景:多系统医疗数据的整合
在实际业务中,该医疗数字化服务商需要整合来自医院多个核心系统的数据,如 HIS 系统、电子病历系统、实验室信息系统等。这些数据是智慧医疗应用的重要数据基础,主要服务于两类场景:
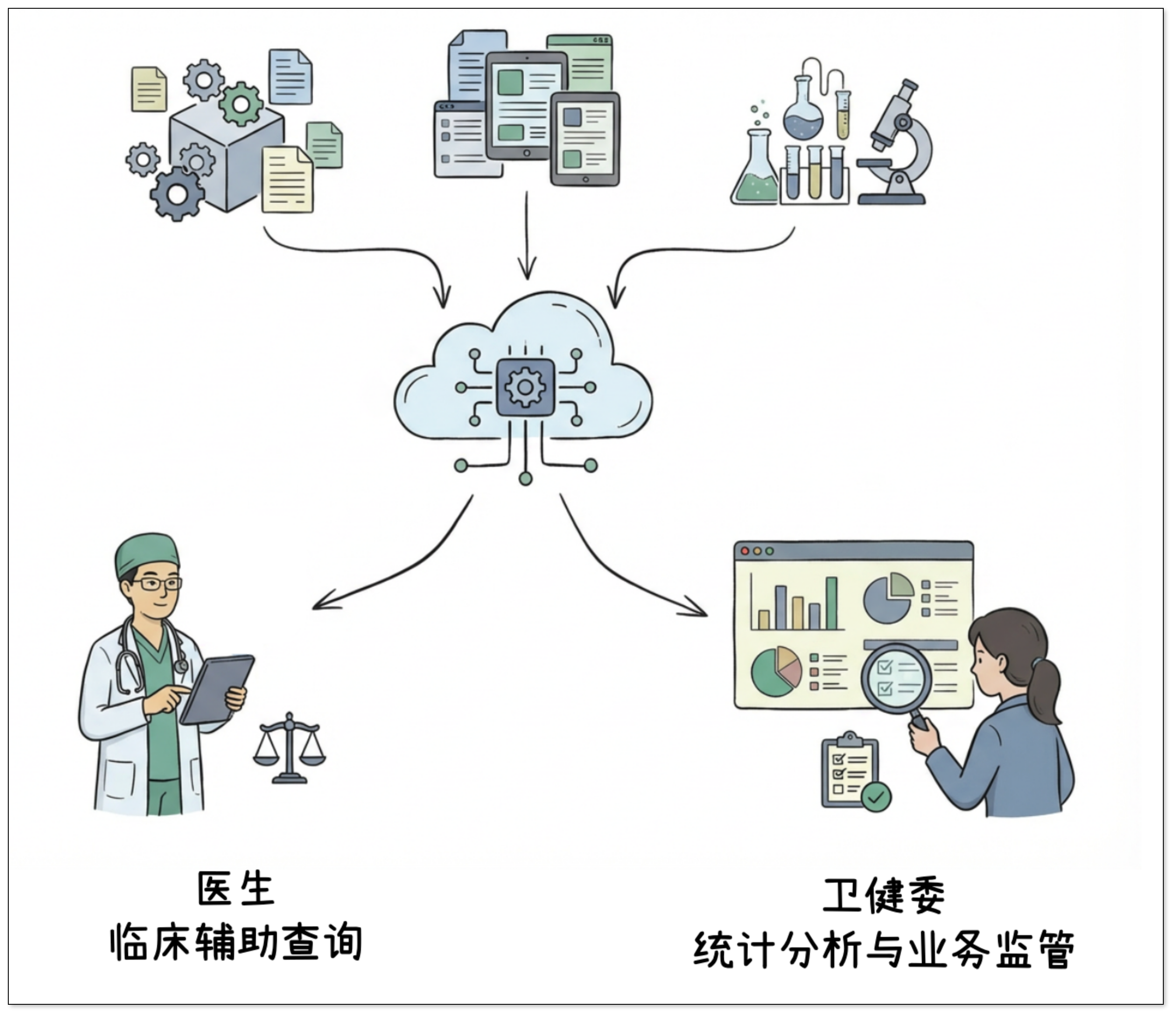
- 面向医生:临床辅助查询,如患者历史就诊记录整合、患者 360 视图等
- 面向卫健委:统计分析与业务监管报表,如药品使用统计、住院周转率等
这些医疗数据来源分散,既包括实时更新的业务信息,也包括体量庞大的历史数据。如何在不影响在线系统稳定运行的前提下,实现数据的持续汇聚和可分析,成为平台建设的首要目标。
整体数据架构
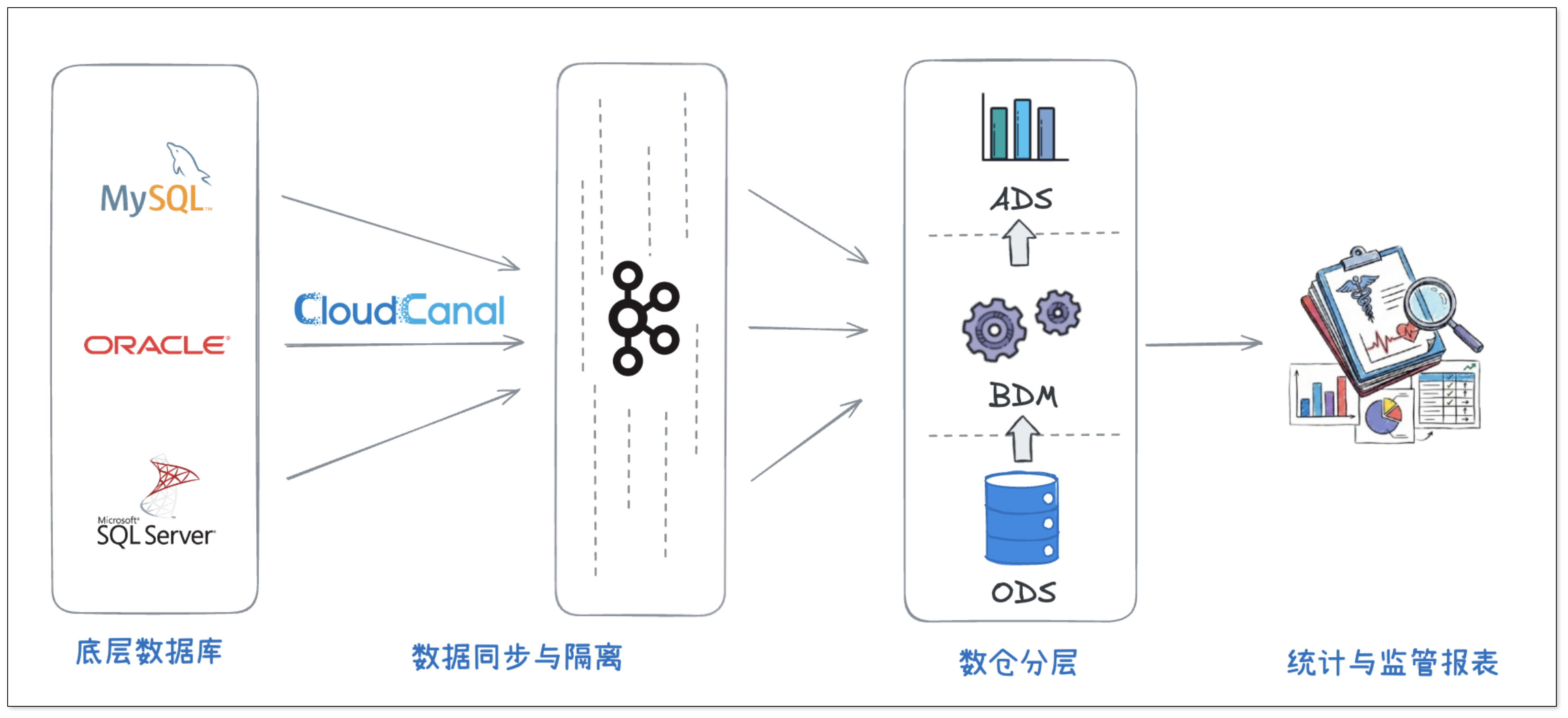
为应对复杂的业务和数据环境,并支撑智慧医疗场景的持续扩展,该团队采用了典型的分层数据架构,将数据采集、处理和应用解耦。
-
多源异构的底层数据源
底层数据主要来自医院各业务系统的在线数据库,数据库类型包括 Oracle、MySQL、SQL Server 等。这些数据库在系统版本、数据模型和数据质量上差异较大,对同步工具的兼容性和稳定性提出了较高要求。
-
中间层:基于 CDC 的数据同步与隔离
在数据同步层,该团队通过 CloudCanal 将源库数据准实时同步至 Kafka。
这一设计实现了源端业务系统与分析系统的有效隔离,既避免了分析任务对在线业务的直接影响,也为后续的数据清洗与加工提供了缓冲层。
-
数仓分层:ODS / BDM / ADS
在数据仓库层面,整体架构分为三层:
- ODS 层(操作数据存储):接入并保存原始数据,保留源系统结构,用于历史数据沉淀
- BDM 层(业务数据模型):围绕业务进行建模,对数据进行标准化和结构化处理
- ADS 层(应用数据服务):面向具体应用场景,提供高性能的指标计算与数据服务
最终,这些数据被用于构建患者 360 视图以及各类医疗统计与监管报表。
数据同步工具的选型
数据同步需求
在同步需求上,该团队的首要目标不是追求毫秒级的实时,而是优先保证数据的准确性 、链路的稳定性和可运维性,以满足智慧医疗场景对数据连续性和可靠性的长期要求。
结合实际业务,他们对同步工具提出了几项核心要求:
- 支持全量、增量一体化,历史数据可回溯
- 可验证数据同步的一致性
- 在异常情况下,问题可及时发现、定位、恢复
- 高可用架构设计,支持自动故障切换与容灾恢复
这些要求,对保障数据平台的稳定运行至关重要。
多款同步产品的实践表现对比
在最终选型之前,该团队曾在生产环境中使用并对比过多款数据同步产品,具体使用体验对比如下:
| 对比项 | CloudCanal | 某知名ETL工具 | 某实时同步工具 | |
|---|---|---|---|---|
| 资源要求 | 采集 1 亿数据,工作机器最低配置 | 4 核 8G | 8 核 32G | 8 核 32G |
| 资源要求 | 对工作机器的磁盘要求 | 无,一般 20G 即可 | 200G 以上 | 200G 以上 |
| 高可用 | 高可用部署 | ✅ | 部分支持 | ❌ |
| 分布式 | 任务分布式调度 | ✅ | ✅ | ❌ |
| 分布式 | 多任务运行,相互是否影响 | 不影响 | 不影响 | 影响 |
| 监控告警 | 延迟/中断告警;源端主备切换告警 | ✅ | ❌ | 部分支持 |
| 监控告警 | Prometheus 可视化监控 | ✅ | ❌ | 部分支持 |
| 实施情况 | 源端 Oracle 是否需要在宿主机安装代理软件 | 不需要 | 需要 | 需要 |
| 实施情况 | 源端 SQL Server 2008 企业版,高权限账号是否可以直接采集数据 | ✅ | 不支持采集 | 需要人为介入 |
| 实施情况 | 目标端为 Kafka/MQ,是否支持分区数自适配 | ✅ | ✅ | 固定分区数 |
| 实施情况 | MySQL/Oracle/SQL Server > StarRocks 同步性能 | 高 | 低,导致 StarRocks I/O 和 CPU 高 | 不支持 |
| 实施情况 | 添加自定义任务 | ✅(Java 代码) | 支持部分简单的配置(如虚拟列常量) | 支持部分简单的配置(如虚拟列常量) |
| 实施情况 | 自定义虚拟主键 | ✅ | ❌ | ✅ |
| 实施情况 | 数据校验及订正 | ✅ | ❌ | ❌ |
为什么选择 CloudCanal
由上表可见,在相同业务规模下,CloudCanal 在资源消耗、高可用能力、复杂结构支持等方面,具有更明显的优势:
- 在亿级数据规模下,对资源要求更低,具有成本优势,适合规模化部署
- 无需在源端数据库宿主机安装代理,部署与运维复杂度低
- 更完善的监控告警能力,便于长期运行和问题排查,有利于自主运维
- 在复杂场景下,对 Oracle、SQL Server 等数据源的支持能力更完整,同步性能更强
- 数据的完整性和一致性可验证,满足对医疗数据的质量要求。
最后,CloudCanal 顺利上线生产环境,平稳运行两年多时间,帮助团队准确、高效、稳定地同步各系统的医疗数据。
CloudCanal 带来的价值
运维复杂度显著下降
引入 CloudCanal 后,团队在运维方面的负担显著降低。平台可持续监控同步延迟、任务中断、主备切换等关键指标,一旦出现问题会及时收到告警信息并处理。同时,CloudCanal 整体使用起来很简便,团队的自主运维能力提升,减少了对外部技术支持的依赖。在需要支持时,专业的技术响应也非常及时。
据团队反馈,核心链路稳定后,日常运维成本下降了约 40%--50%。
数据准确性与稳定性提升
通过 CloudCanal 自动化的全量与增量同步链路,以及配套的数据校验与订正机制,平台在长期运行下能够保持数据结果的一致性与完整性。稳定的同步机制有效降低了数据丢失、重复等风险,为病史查询、监管统计等对准确性要求极高的场景,提供了更加可靠的数据基础。
业务扩展性强
随着服务医院数量和数据体量不断增长,该团队需要汇聚更多不同的医院系统数据。
通过 CloudCanal,在不显著增加硬件资源投入的前提下,该团队能够快速同步新的系统数据,并在高峰期依然保持秒级的数据延迟水平。这大大缩短了新医院系统的接入周期,也为更多业务分析和监管场景的上线预留了充足空间。
总结
在医疗数字化场景中,数据平台往往需要面对系统复杂、数据体量大、稳定性要求高等多重挑战。该头部医疗数字化服务商的实践表明,选择一款稳定、准确、易运维的数据同步工具,是构建长期可演进数据架构的重要基础。
通过 CloudCanal,该团队建立了一套更加稳健的数据同步与数仓体系,为医疗业务分析和监管支持提供了持续可靠的数据能力。