
2024
1.摘要
background
问题:自动语音识别(ASR)系统在嘈杂环境中性能会显著下降 。虽然引入视觉信息的视听语音识别(AVSR)可以提高鲁棒性,但目前的研究主要集中在融合已经充分学习的模态特征(即编码器的最终输出),而忽略了在模态特征学习过程中的上下文关系 。
目标:旨在通过在特征学习阶段融合多模态信息来提升系统性能。
innovation
核心创新 :提出了基于多层交叉注意力融合的 AVSR(MLCA-AVSR)方法 。
好处 :该方法将改进的交叉注意力模块集成到音频和视觉编码器的多个中间层中 。这允许每个模态从另一个模态学习互补的上下文信息(从低级细节到高级抽象模式),从而促进更详尽的表征学习 。同时引入了 Inter-CTC 损失来指导中间层的输出 。
- 方法 Method
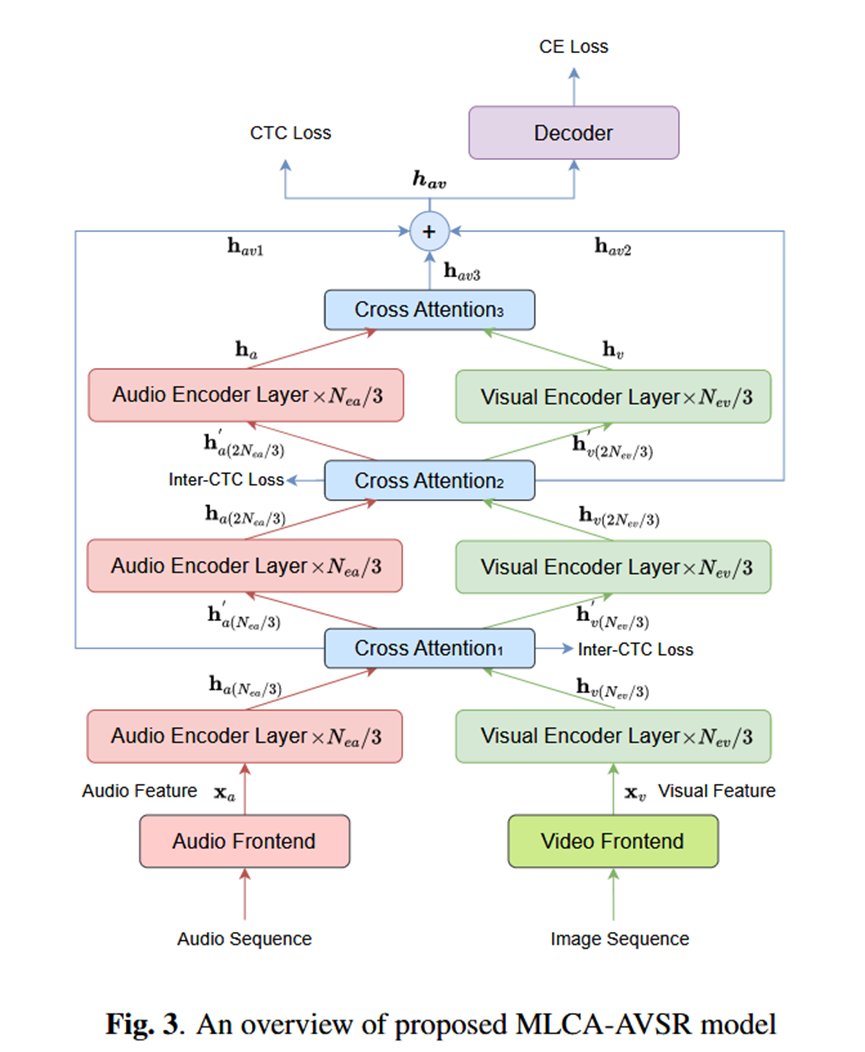
总分结构汇报 (Pipeline)
模型主要由四个部分组成:音频/视觉前端(Frontends)、音频/视觉编码器(Encoders)、融合模块(Fusion Module)和解码器(Decoder)15。
整体架构基于 E-Branchformer 编码器和 Transformer 解码器,采用联合 CTC/Attention 训练策略 16。
详细部分及具体做法
- 前端 (Frontends):
音频:2层卷积下采样网络 17。
视觉:ResNet3D 网络 18。
- 编码器 (Encoders):
采用 E-Branchformer 架构,相比 Branchformer 性能更优 19。
输入:音频序列 x_a 和 图像序列 x_v 20。
- MLCA 融合模块 (Fusion Module):
位置:在编码器内部均匀分布引入两个额外的交叉注意力模块,加上编码器末端的一个,共三个融合点 21。
改进的交叉注意力 (Improved Cross Attention):
包含音频流和视觉流。首先通过多头自注意力(MHSA)处理各自特征 h_a, h_v 22。
AMMA (Audio Multi-Headed Modal-Attention):Query 来自音频,Key/Value 来自视频 23。
VMMA (Visual Multi-Headed Modal-Attention):Query 来自视频,Key/Value 来自音频 24。
输出:融合后的特征 h_{av} 是音频流输出 h'_a 和视频流输出 h'_v 的和 25252525。
层级传递:中间层交叉注意力的音频/视频输出会被送入下一层编码器继续学习 26。
- 损失函数设计:
除了最终的 CTC 和 CE Loss,还利用中间层交叉注意力的输出 (h_{av1}, h_{av2}) 计算 Inter-CTC Loss,以指导中间层的融合 27。
- 实验 Experimental Results
实验数据集
MISP2022-AVSR 数据集:大规模中文视听对话语料库,包含远场/中场/近场音频和视频 28。
规模:训练集包含约 106.09 小时 29。数据增强后(包括速度扰动和模拟噪声)训练数据约为 1300 小时 30。
实验结论
-
- 单模态编码器比较:E-Branchformer 在 ASR 和 VSR 任务上均优于 Conformer 和 Branchformer 31。
- 融合策略比较:MLCA(多层交叉注意力)优于简单的 Add(相加)和 MLP 融合。相比 Add 方法,MLCA 在 Eval 集上实现了 2.4% 的相对 CER 提升 32。
- 消融实验:移除编码器内部的交叉注意力模块会导致性能下降。保留较浅层的交叉注意力模块(让融合发生得更早)比仅保留深层模块更有效 33。
- SOTA 对比:MLCA-AVSR 在 Eval\^{sd} 集合上取得了 30.57% 的 cpCER,优于之前的第二名 SLCA-AVSR 系统。结合 ROVER 多系统融合后,cpCER 降至 29.13%,刷新了该数据集的 SOTA 34。
-
总结 Conclusion
Take home message
在视听语音识别中,仅仅在编码结束时融合特征是不够的。在表征学习的中间阶段(Intermediate layers)引入交叉注意力机制,让音频和视觉模态在早期就开始交互和互补,可以显著提升系统在复杂声学环境下的鲁棒性 。