第三节:多尺度脑模拟与树突计算模型
一、核心理念:为什么需要"多尺度"和"树突"?
传统的神经网络模型(包括许多SNN)将神经元视为一个点单元(Point Neuron),如经典的LIF(漏积分发放)模型。接收输入,进行加权求和,超过阈值就输出一个脉冲。但这极度简化了生物神经元的复杂结构。
- 多尺度脑模拟(Multi-scale Brain Simulation):
理念:智能的涌现依赖于大脑中跨尺度的协同工作。从微观的离子通道、介观的神经元与突触,到宏观的脑区与全脑,每个尺度都有其重要作用,且尺度间存在复杂的相互作用。
目标:构建一个能够整合不同尺度生物学细节的计算模型,从更底层的原理来模拟和理解智能的涌现。
- 树突计算(Dendritic Computation):
理念:神经元的树突(接收输入的部分)并非简单的"电线",而是强大的主动计算单元。其拥有丰富的离子通道和复杂的电生理特性,能够执行非线性运算,对输入进行筛选、整合和转换。
目标:将神经元模型从"点"升级为"体",将树突的主动计算能力引入人工网络,极大增强单个节点的信息处理能力。
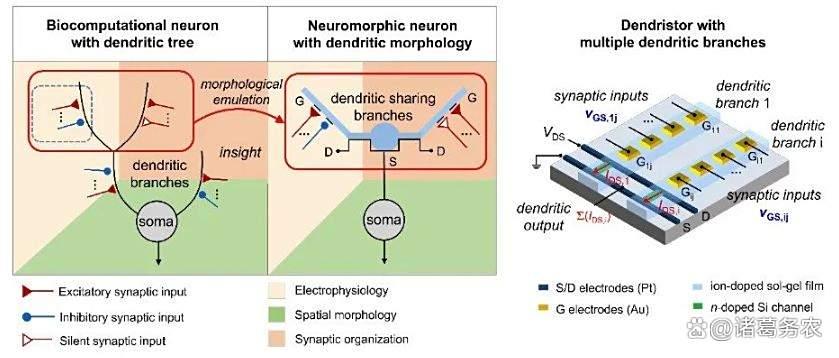
模拟树突形态的 Dendristor
二、多尺度脑模拟:从离子通道到全脑
- 系统框架
多尺度模拟试图将大脑的不同层次,整合到一个统一的框架中。
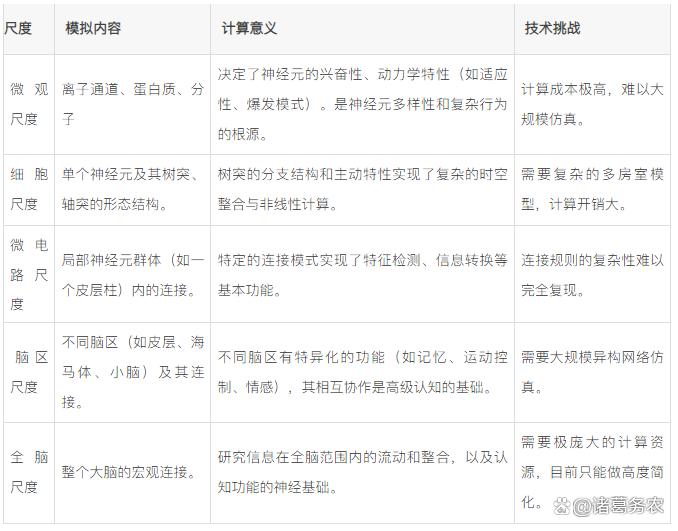
多尺度脑模拟对大脑不同层次的整合
- 前沿进展:
欧盟人脑计划(HBP):是最大规模的多尺度脑模拟项目,其最终目标之一就是构建全脑模型。开发了Brain Simulation Platform等工具,允许研究人员在不同尺度上进行仿真。
从模拟中提取原理:当前的重点并非1:1完美复制整个大脑(这不现实),而是通过多尺度仿真,识别出关键的计算原理(如特定的振荡模式、环路连接规则),并将其抽象化后应用到更高效的类脑算法中。
三、树突计算模型:从"点"到"体"的神经元革命
这是目前类脑计算中最为活跃的方向之一,因为能直接、显著地提升网络性能。
(一)树突的核心计算功能:
- 非线性整合:
树突上的NMDA受体等可产生局部的、非线性的"钙尖峰"(Calcium Spike),相当于在神经元内部增加了多层子网络。这使得单个神经元就能解决线性不可分问题(如XOR)。
- 时空滤波:
树突对不同时间、不同空间位置(远近)的输入有不同的响应特性,形成了一个复杂的时空滤波器。
模块化与专注性:不同的树突分支可以独立处理来自不同来源的输入(如来自不同模态的感觉信息),实现了"一台多区"的模块化计算。
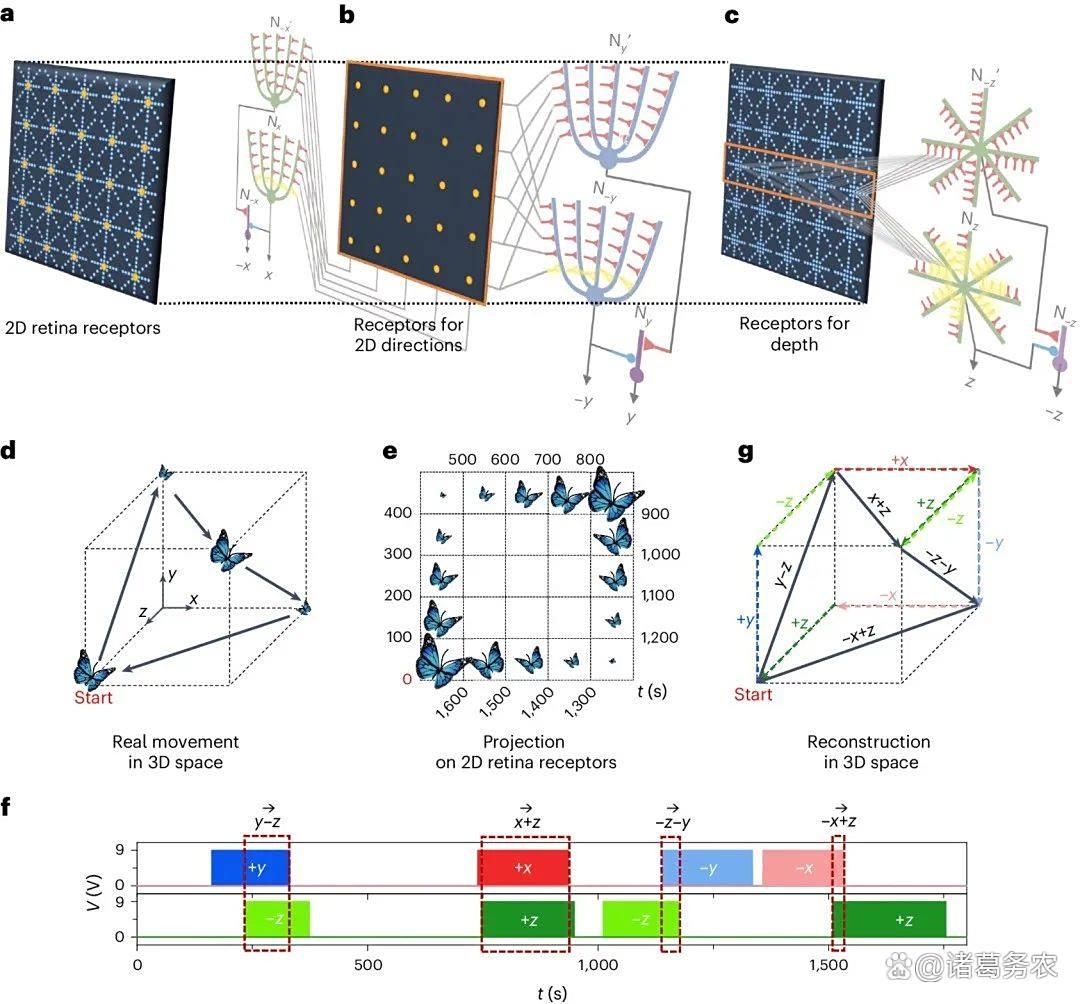
树突网络神经回路的 3D 视觉运动感知
(二)关键模型与进展:
- 多房室模型(Multi-Compartment Model):
将神经元拆解为多个电学房室(如胞体、主树突干、远端树突分支),每个房室都有其膜电位和动力学特性。
进展:研究者已成功将多房室神经元模型嵌入SNN中。例如,中科院自动化所等团队的工作表明,采用多房室神经元模型的SNN在长序列依赖、复杂时空模式识别等任务上表现显著优于传统点神经元模型。
- 基于树突的片上学习规则:
树突不仅是计算单元,也是可塑性的关键位点。突触可塑性(如STDP)的强度会受到树突局部活动(如钙离子浓度)的调制。
进展:提出了诸如Branch-specific STDP(分支特异性STDP)等更精细的学习规则,允许网络在不同树突分支上独立地学习不同的特征,极大地提升了学习效率和表征能力。
- 抽象为人工网络单元:
为了平衡生物合理性和计算效率,研究者将树突的核心计算功能抽象为一种新型的人工网络层。
进展:例如,Dendritic Cortical Microcircuit (DCM) 等模型被提出,在保持较高生物合理性的同时,计算效率远高于复杂的多房室模型,已可用于构建中等规模的类脑网络。
四、与类脑大模型的结合及前沿趋势
多尺度脑模拟和树突计算并非孤立的学术游戏,正被整合到类脑大模型的架构设计中,代表着最前沿的探索。
- 构建更强大的基础单元:
趋势:用树突增强的神经元(Dendrite-augmented Neuron) 替代传统SNN中的LIF神经元,作为构建大模型的新一代"晶体管"。
价值:单个神经元能力的提升,意味着用更少的神经元即可实现相同的功能,或者用相同规模的网络解决更复杂的问题,这直接关乎构建大模型的成本和效率。
- 实现更复杂的记忆与推理:
趋势:海马体中的神经元以其复杂的树突结构和可塑性而闻名,是记忆形成的核心。模拟这些结构是构建类脑记忆系统的关键。
价值:这可能为解决大模型的灾难性遗忘和实现情景记忆提供全新的解决方案。树突的分支特异性学习天然支持模块化记忆存储。
- 感知融合与注意力机制:
趋势:不同树突分支处理不同模态的信息,最后在胞体进行整合,这为多模态融合提供了极其神经科学的机制。
价值:可以开发出基于树突计算的神经形态注意力机制,替代或增强Transformer中的Attention,使其更高效、更符合生物机制。
- 硬件协同设计:
趋势:忆阻器(Memristor) 等新型神经形态器件因其模拟特性和存算一体能力,非常适合用来在硬件上直接实现树突的非线性整合和分支特异性可塑性。
价值:为最终在芯片上实现支持树突计算的低功耗类脑大模型铺平道路。
五、挑战与未来方向
-
计算复杂度:多房室模型和精细仿真的计算开销巨大,与"构建大模型"的需求存在矛盾。如何在生物合理性和计算可行性之间找到平衡是关键。
-
理论抽象:如何从复杂的生物学细节中,抽取出最核心、最关键的计算原理,并将其转化为简洁高效的算法,是核心科学问题。
-
训练算法:如何训练这种结构复杂、动态性极强的网络?需要开发全新的基于能量的学习算法或生物启发的局部优化规则。
-
跨学科壁垒:需要计算科学家、神经科学家、硬件工程师的深度无缝合作。
六、总结
多尺度脑模拟与树突计算模型代表了类脑智能向 "深度仿生" 迈进的关键一步。不再满足于皮毛的模仿,而是试图深入挖掘大脑这座"金矿"中最有价值的计算原理。
通过将神经元从"点"升级为"体",通过关注跨尺度的相互作用,这个方向有望为类脑大模型带来质的飞跃:更强的单节点能力,降低构建大模型的规模需求。更复杂、更鲁棒的时空信息处理能力。更高效、更灵活的多模态融合与记忆机制。
虽然前路充满挑战,但这无疑是通往更低功耗、更高智能、更接近人类认知能力的下一代人工智能的必经之路。其发展,很可能决定未来类脑智能所能达到的高度。
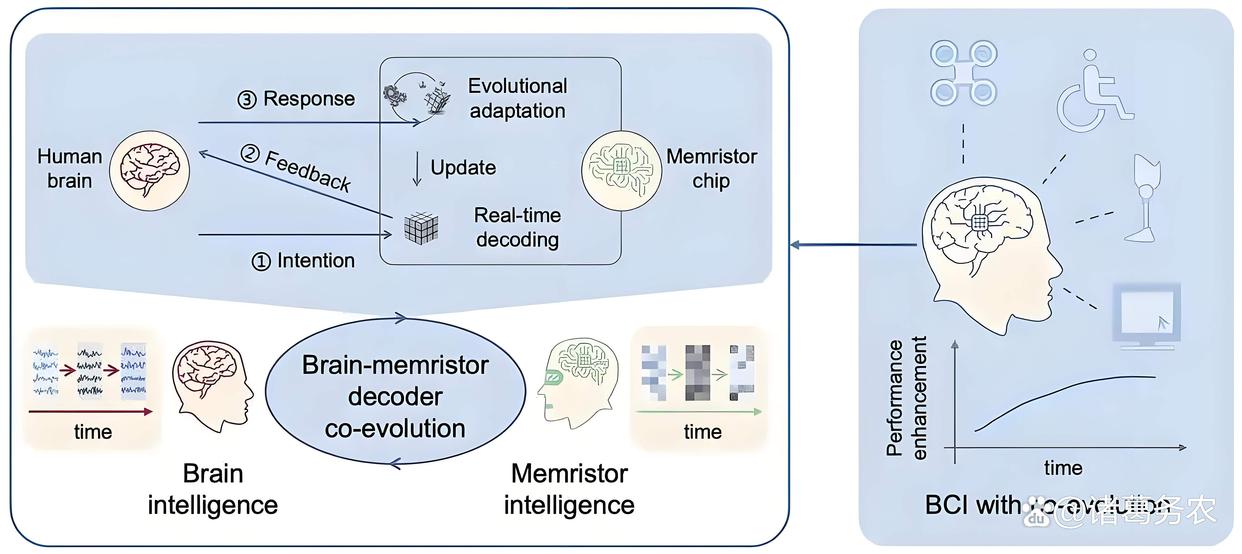
"双环路"脑机接口系统解决方案
第四节:异构融合架构:务实且极具前景的技术路径
一、什么是异构融合架构?核心理念是什么?
- 概念范畴
异构融合架构是指在同一个计算系统(从芯片到算法)中,同时集成和协调多种不同的计算范式,最典型的是同时支持人工神经网络(ANN) 和脉冲神经网络(SNN),让其各自处理最擅长的任务,并通过高效的交互机制协同工作,共同完成复杂的智能任务。
- 核心理念:
务实主义与优势互补:承认ANN和SNN各有优劣,不强行用一方替代另一方。
ANN的优势:训练成熟(反向传播)、软件生态强大、在静态图像处理和高精度输出任务上表现卓越。
SNN的优势:事件驱动、超低功耗、天生擅长处理时空动态信息(如视频、音频流)、生物合理性高。
任务驱动的计算范式分配:将复杂的智能任务分解,把适合ANN处理的子任务(如图像特征提取)分配给ANN单元,把适合SNN处理的子任务(如时序信息整合、低功耗感知)分配给SNN单元。
高效无缝的范式间通信:设计高效的接口和转换机制,实现ANN的连续激活值和SNN的离散脉冲序列之间的低损耗、高效率的信息交换。
二、为什么需要异构融合?要解决什么问题?
异构融合架构旨在解决类脑智能走向实际应用中的几个核心矛盾:
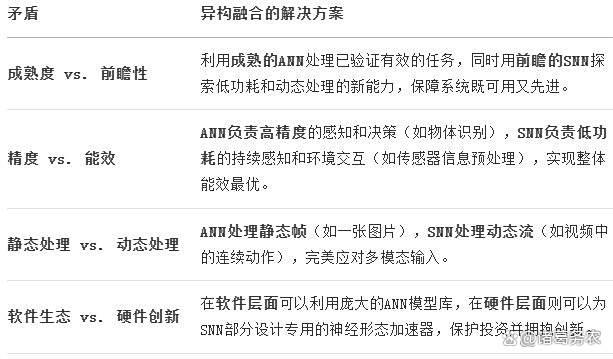
异构融合架构拟解决类脑智的核心矛盾
三、关键技术:如何实现融合?
实现异构融合的核心技术挑战在于 "桥接"两种不同的计算范式。主要方法有:
(一)算法层面的融合
- 网络内融合:
在一个大的网络中,某些层是ANN,某些层是SNN。例如,前端用SNN处理事件相机输入的稀疏脉冲流,后端用ANN进行分类决策。
- 转换法:
离线训练一个ANN模型,然后将其转换为等价的SNN模型进行部署。这是在ANN和SNN之间建立联系的最常用方法,但通常有精度损失和延迟问题。
- 联合训练:
探索如何同时训练包含ANN和SNN组分的混合网络,这是前沿难点。
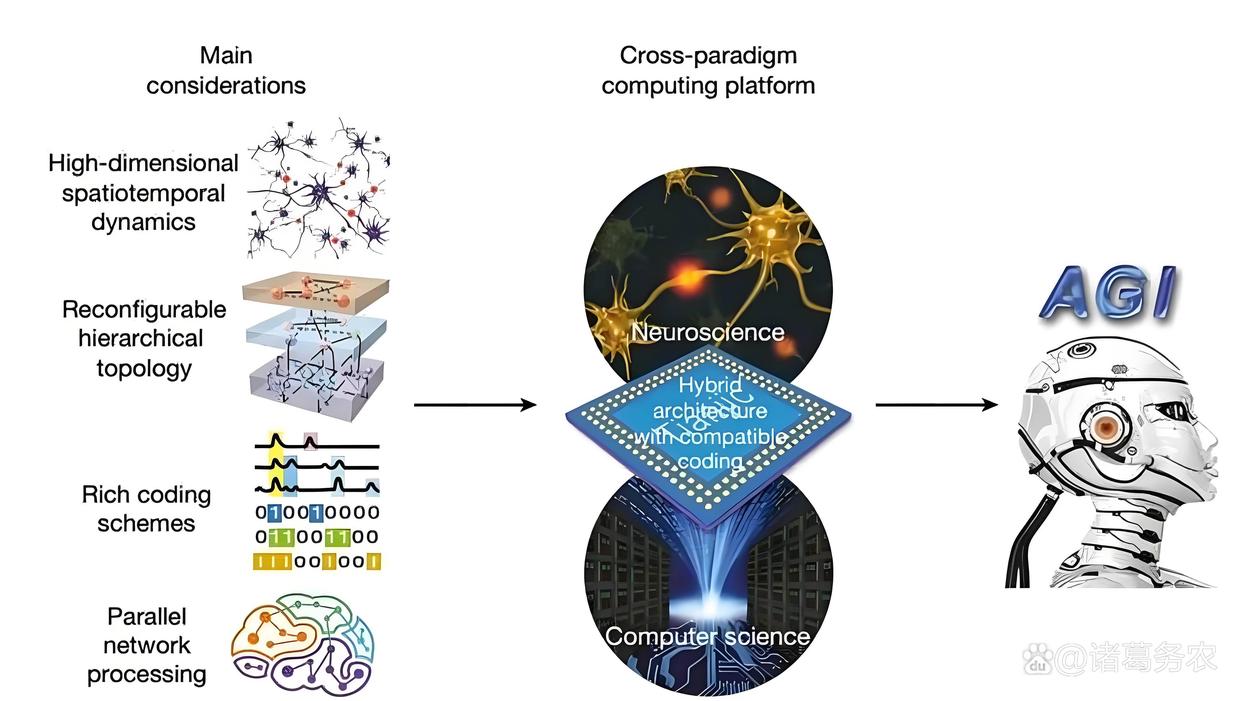
(二)芯片层面的融合(硬件级异构)
这是最彻底、性能潜力最大的融合方式,代表是清华大学的天机(Tianjic)芯片。
- 核心创新:
在同一块芯片上,设计了支持ANN和SNN两种模式的通用计算核心。
- 工作原理:
硬件抽象:天机芯片的底层硬件可以被配置为运行ANN的线性矩阵模式或运行SNN的非线性脉冲模式。
资源复用:通过巧妙的硬件设计,共享大部分计算和存储资源(如乘加器、内存),仅以3%的额外面积开销就实现了对两种范式的支持。
高效通信:ANN部分和SNN部分在芯片内部通过高速片上网络(NoC)进行通信,延迟极低,效率远高于片外通信。
全球首款异构融合类脑芯片
四、代表性进展与前沿案例
(二)清华大学 "天机(Tianjic)" 芯片与自动驾驶自行车
这是异构融合架构最著名的硬件实现和应用演示。
- 架构:
芯片包含156个核心,每个核心可灵活配置为ANN模式或SNN模式。
- 任务分配:
SNN部分:处理动态视觉传感器(DVS) 的异步脉冲流,用于快速目标检测和避障。
ANN部分:处理传统摄像头的图像,用于精确物体识别;同时处理语音命令识别和运动控制。
融合效果:所有感知、决策和控制任务都在单一天机芯片上完成,实现了无人自动驾驶自行车的实时、低功耗运行,展示了异构融合在处理复杂、多模态任务时的巨大优势。
(二)算法层面的异构融合研究
Hybrid SNN-ANN Networks:许多研究尝试构建混合网络。例如,用SNN编码层处理输入,将其输出转换为ANN可处理的表征,再送入ANN决策层。这在视频动作识别等领域显示出良好效果。
神经形态传感器与ANN处理器的融合:虽然不算严格的芯片内融合,但这是一种常见的系统级异构。例如,用事件相机(SNN范式输出) 作为传感器,将其输出的事件流进行预处理后,送入强大的ANN处理器(如GPU) 进行高级分析。这已在高速机器人、无人机上得到应用。
MIT PRefLexOR 框架
五、总结:前沿趋势与挑战
- 前沿趋势:
更精细的粒度与动态重构:未来的芯片可能支持更小粒度(如单个神经元级别)的范式动态配置,甚至可以根据任务需求在运行时动态重构,实现极致的灵活性和能效。
感存算一体融合:将异构融合架构与感存算一体技术结合。传感器本身输出脉冲信号(SNN范式),直接接入融合芯片的SNN部分进行处理,再根据需要与ANN部分交互,从源头消除数据搬运。
新兴器件赋能融合:利用忆阻器(Memristor) 等新型器件天然模拟突触行为的特性,来构建更高效、密度更高的SNN突触阵列,同时用传统CMOS逻辑实现控制和高精度ANN计算,形成异构异构(材料与范式皆异构)的融合。
软硬件协同设计:开发统一的编程框架和工具链,让开发者能够无需关心底层硬件细节,轻松地将任务分解和映射到ANN和SNN组件上。
- 核心挑战:
设计复杂性:设计能同时高效支持两种范式的硬件极具挑战性,需要跨领域的深厚知识。
编程与编译难题:如何为这种混合硬件编写程序?如何自动将算法分解并分配到不同的计算单元?这需要全新的编译器和软件栈。
内存架构:ANN和SNN对内存访问的模式不同,设计一个能同时满足两者需求的高效内存 hierarchy 是一大难题。
训练难题:如何端到端地联合训练一个包含ANN和SNN组分的网络,仍然是一个开放的学术问题。
- 总结
异构融合架构是一条非常务实且强大的技术路径。避免了"ANN派"和"SNN派"的路线之争,以一种工程师的智慧提出:"我们全都要"。
其核心价值在于:
实用性:最大化利用现有成熟的AI生态,同时稳步引入新型的类脑技术。
性能最大化:通过优势互补,在系统层面实现能效、速度、精度的最佳平衡。
平滑演进:为AI系统从传统范式向未来类脑范式的平滑过渡提供了可行的路径。
天机芯片的成功演示证明了这条道路的可行性。这不仅是类脑智能的一个里程碑,更是为未来的人工智能计算架构提供了一个全新的、充满想象力的发展方向:未来的AI芯片,或许是多种计算范式共存的"异构计算乐园"。
Transformer架构大模型
(全文结束)
【免责声明】本文主要内容均源自公开信息和资料,部分内容引用了Ai,仅作参考,不作任何依据,责任自负。