AI总结部分:
这篇论文提出了 EgoMAN 项目,核心是解决 "从语义推理到运动生成" 的 3D 手部轨迹预测问题 ------ 通过大规模场景交互数据集和模块化推理 - 运动框架,实现基于意图的长时程、高精度 6 自由度(6DoF)手部轨迹预测,适用于机器人操作、语言驱动的运动合成等场景。以下是分模块的详细解析:
一、研究背景与核心挑战
1. 研究意义
预测未来 3D 手部运动是人机交互、主动辅助系统的关键能力(例如机器人预判人类意图并配合操作)。人类能自然结合 "任务语义(为何做)、空间几何(在哪里做)、时间动态(怎么做)" 进行预判,但计算层面需同时解决这三者的联合推理。
2. 现有方法的两大瓶颈
- 数据局限 :
- 受控数据集(如实验室场景):3D 标注精准但场景单一,缺乏真实世界多样性;
- 大规模第一视角视频数据集:场景丰富但轨迹噪声大、无明确交互阶段(如 "靠近目标""操作目标"),且缺乏语义 - 运动的强关联标注。
- 模型缺陷 :
- 基于可用性(Affordance)的方法:依赖目标检测和可用性估计,易传播检测误差,计算开销大;
- 端到端运动预测模型(扩散、变分模型等):聚焦短时运动,语义关联性弱;
- 视觉 - 语言 - 动作(VLA)系统:推理能力强,但难以生成平滑、高频的连续 3D 运动,且推理与运动的接口低效(如长推理链、隐式特征映射)。
二、核心贡献:EgoMAN 数据集 + EgoMAN 模型
(一)EgoMAN 数据集:解决 "数据瓶颈"
首个大规模、带交互阶段标注的第一视角手部轨迹数据集,为 "推理 - 运动对齐" 提供强监督。
| 数据集关键特征 | 具体细节 |
|---|---|
| 数据规模 | 300+ 小时视频、1500+ 场景、219K 条 6DoF 手部轨迹(3D 位置 + 6D 旋转)、300K+ 第一视角片段 |
| 数据来源 | 整合三大数据集:EgoExo4D(真实日常活动)、Nymeria(日常任务)、HOT3D-Aria(结构化操作) |
| 核心标注 1:交互阶段 | 明确划分两阶段,覆盖手部运动的关键过渡:- 接近阶段(Approach):手部向目标操作区域移动;- 操作阶段(Manipulation):手部与目标交互(如抓取、转动) |
| 核心标注 2:结构化 QA 对 | 300 万条 QA,覆盖三类推理,建立语义 - 空间 - 运动的关联:- 语义推理(21.6%):如 "下一步要操作什么物体?""动作的目的是什么?";- 空间推理(42.6%):如 "左手完成操作时的 3D 位置在哪里?";- 运动推理(35.8%):如 "基于过去 0.5 秒的手部运动,右手何时完成接近阶段?" |
| 数据集划分 | 预训练集(64%,低质量标注)、微调集(31%,高质量标注)、测试集(5%,含 "未见场景" 和 "分布外场景") |
(二)EgoMAN 模型:解决 "推理 - 运动衔接"
模块化框架,核心是通过 轨迹令牌接口(Trajectory-Token Interface) 连接高层推理与低层运动生成,配合渐进式训练实现对齐。
模型整体架构分为两部分,流程为:输入(图像+历史运动+意图查询)→ 推理模块 → 轨迹令牌 → 运动专家 → 6DoF 未来轨迹
1. 推理模块(Reasoning Module):从输入到关键令牌
-
基础架构:基于 Qwen2.5-VL(视觉 - 语言模型),输入包括:第一视角图像、自然语言意图查询(如 "拿起绿色杯子")、过去的手部轨迹序列。
-
核心创新:4 个轨迹令牌(Token),将抽象推理转化为结构化、可解释的中间表示:
令牌类型 功能描述 <ACT>(语义令牌)解码动作语义嵌入(如 "左手抓取绿色杯子"),关联意图与动作类型 <START>(waypoint 令牌)标记 "接近阶段起始点",预测该时刻的 3D 位置、6D 旋转和时间戳 <CONTACT>(waypoint 令牌)标记 "接近阶段结束→操作阶段开始"(手部接触目标),预测关键状态 <END>(waypoint 令牌)标记 "操作阶段结束",预测最终状态 -
训练目标:
- 文本损失(\(L_{text}\)):优化 QA 生成的自然语言回答;
- 动作语义损失(\(L_{act}\)):通过对比学习(InfoNCE 或余弦相似度)对齐预测与真实动作嵌入;
- 关键点损失(\(L_{wp}\)):通过 Huber 损失优化 3D 位置、6D 旋转和时间戳的预测精度。
2. 运动专家(Motion Expert):从令牌到连续轨迹
- 核心任务:基于推理模块输出的令牌,生成平滑、物理一致的长时程 6DoF 轨迹(最长 5 秒,10 FPS)。
- 技术选型:Flow Matching(流匹配)生成模型,优势是比扩散模型更高效,能生成高频、平滑的运动序列。
- 输入设计:
- 时序令牌:历史运动点 + 推理模块预测的 3 个 waypoint 令牌(按时间戳排序);
- 非时序上下文:图像特征(DINOv3 提取)+
<ACT>语义嵌入;
- 训练:先单独预训练(使用真实关键点和动作语义作为监督),再与推理模块联合微调,避免训练不稳定。
3. 联合训练:推理 - 运动对齐
- 核心问题:推理模块预训练时基于 "真实标注" 生成令牌,而运动专家预训练时基于 "真实令牌" 生成轨迹;推理时需用 "预测令牌" 驱动运动生成,存在分布不匹配。
- 解决方案:联合训练阶段,推理模块输出的预测令牌直接作为运动专家的输入,同时优化两个目标:
- 推理模块的令牌预测损失(保持令牌准确性);
- 运动专家的流匹配损失(\(L_{FM}\)),确保轨迹与令牌对齐且物理合理。
三、实验验证
1. 实验设置
- 测试集:EgoMAN-Bench(含两类场景):
- EgoMAN-Unseen:未见的同分布场景(评估泛化性);
- HOT3D-OOD:分布外场景(新物体、新环境,评估鲁棒性);
- 评估指标:
- 轨迹精度:平均位移误差(ADE)、最终位移误差(FDE)、动态时间规整(DTW)(单位:米);
- 旋转精度: geodesic 旋转误差(单位:度);
- 关键点精度:接触点距离(Contact)、轨迹匹配距离(Traj);
- 语义对齐:Recall@3(运动与动作动词的关联召回率)、FID(运动嵌入分布相似度)。
2. 核心结果
- 轨迹预测精度(SOTA 性能):在 EgoMAN-Unseen 测试集上,EgoMAN 模型较最强基线(HandsOnVLM*)降低 27.5% 的 ADE(\(K=10\) 时,ADE=0.124m vs 0.171m),旋转误差降低 6.8%(32.75° vs 35.22°);在分布外的 HOT3D-OOD 上仍保持优势,证明跨场景泛化能力。
- 关键点预测效率与精度:EgoMAN-WP(仅推理模块的关键点预测)比传统可用性方法(如 VRB*、VidBot)快 2 个数量级(3.45 FPS vs <0.05 FPS),同时接触点误差降低 33.8%。
- 语义 - 运动对齐:Recall@3 达 43.9%(远超基线的 27.9%),FID 仅 0.04,证明生成的轨迹与意图描述高度一致。
3. 消融实验:关键组件的贡献
| 消融配置 | ADE(m) | FDE(m) | 旋转误差(°) | 结论 |
|---|---|---|---|---|
| 无推理预训练 + 无运动预训练 | 0.273 | 0.308 | 51.79 | 预训练对性能至关重要 |
| 有运动预训练 + 无关键点令牌 | 0.162 | 0.225 | 36.24 | 关键点令牌能提升轨迹精度 |
| 有推理 + 运动预训练 + 6DoF 令牌 | 0.151 | 0.206 | 33.88 | 完整配置最优 |
四、定性结果与应用价值
1. 定性表现
- 轨迹平滑性:生成的轨迹无漂移、无过度伸展,符合人类操作习惯(如 "拿起杯子" 时先靠近再抓取,而非直接瞬移);
- 意图可控性:同一图像 + 历史运动下,不同意图查询会生成截然不同的轨迹(如 "打开烤箱""取出叉子""戳食物");
- 场景适应性:在厨房、办公室、维修等多样场景中均能准确预测,对遮挡、 clutter 鲁棒。
2. 应用场景
- 机器人操作:为机械臂提供意图驱动的轨迹规划(如根据 "倒水" 意图生成手部 / 机械臂的运动路径);
- 辅助系统:预判残障人士的手部动作,提前触发辅助设备(如轮椅控制、智能假肢);
- 运动合成:基于文本生成 3D 手部动画(如游戏、虚拟人交互)。
五、局限性与未来方向
- 局限性:
- 仅建模手腕轨迹,未考虑手指关节的精细运动;
- 交互阶段仅划分 "接近 - 操作",缺乏更细粒度的子阶段(如 "预接触调整""多步操作");
- 数据集存在传感器噪声和标注误差,无人工验证环节。
- 未来方向:
- 扩展到全手姿态(手指关节)的预测;
- 引入更细粒度的交互阶段解析;
- 提升数据集标注质量(如人工验证、更高精度的 3D 扫描);
- 部署到真实机器人系统,验证物理世界中的迁移能力。
总结
EgoMAN 项目的核心突破是 "用结构化令牌打通推理与运动":通过数据集提供 "语义 - 空间 - 运动" 的强关联监督,再通过 4 个轨迹令牌将抽象的视觉 - 语言推理转化为运动生成可直接利用的中间表示,最终实现 "意图明确、轨迹平滑、泛化性强" 的 3D 手部轨迹预测。该方法既解决了传统模型 "语义与运动脱节" 的问题,又克服了 VLA 系统 "运动生成低效" 的缺陷,为 embodied AI 中的人机交互提供了新范式。
自己的总结:
论文里面提到了"流匹配",我之前一直以为流匹配和扩散模型没什么区别,其实区别是有的:
在训练的时候,扩散模型是以真实数据为出发点,给他加噪声,然后训练模型去给他去噪;流匹配则是直接用噪声做起点。只考虑推理阶段的话,虽然大家都是以噪声为起点,但扩散模型直接预测噪声来去噪,而流匹配预测的是一个速度,预测应该往哪个方向变化,天然更平滑。
一、论文背景:需求、瓶颈与动机
1. 核心需求:从 "被动响应" 到 "主动预判" 的交互升级
在人机交互、机器人辅助、虚拟人控制等场景中,系统需要提前预判人类手部的 3D 运动轨迹,才能实现 "主动配合"(而非被动响应)。例如:
- 机器人助手预判人类要 "拿起杯子",提前调整自身姿态;
- 辅助设备预判残障人士的手部动作,提前触发功能;
- 虚拟人根据文本指令,生成符合意图的手部操作轨迹。
人类完成这类预判时,会自然融合三大信息:语义意图(为何做,如 "喝水")、空间几何(在哪里做,如 "杯子在桌面左侧")、时间动态(怎么做,如 "先伸手再抓取") 。但计算层面,要让模型同时实现这三者的联合推理,面临两大核心瓶颈。
2. 数据瓶颈:缺乏 "语义 - 运动 - 阶段" 强关联的大规模数据
现有数据集无法同时满足 "规模、多样性、强监督" 三大要求,导致模型学习不到 "意图 - 轨迹" 的精准映射:
- 受控数据集(如 HOT3D 早期版本、H2O):3D 标注精准,但场景单一(多为实验室结构化操作),缺乏真实世界的噪声、 clutter 和多样化任务,泛化能力差;
- 大规模第一视角视频数据集(如 EgoExo4D、Nymeria):包含丰富的日常交互(做饭、修车、办公),但存在三大缺陷:
- 轨迹噪声大:手部轨迹标注粗糙,缺乏高精度 6DoF(3D 位置 + 6D 旋转)信息;
- 无交互阶段:未划分 "接近(Approach)- 操作(Manipulation)" 等关键阶段,无法区分 "有目的的运动" 和 "无意义的背景动作";
- 语义弱关联:缺乏 "意图 - 轨迹 - 空间" 的结构化标注,模型难以理解 "动作为何发生""轨迹为何这样规划"。
3. 模型瓶颈:推理与运动生成 "脱节",难以兼顾精度、平滑性与泛化性
现有模型分为三类,均存在明显缺陷:
- (1)基于可用性(Affordance)的方法(如 VRB、VidBot):依赖目标检测和可用性估计(如 "杯子的'抓取区域'在哪里"),但检测误差会逐级传播,且计算开销大,无法适配实时场景;
- (2)端到端运动预测模型(如扩散模型、状态空间模型 USST、Mamba 双扩散 MMTwin):聚焦短时运动动态(如预测未来 1 秒轨迹),缺乏语义 grounding(如无法根据 "倒水" 意图调整轨迹),且生成的长时轨迹易漂移、卡顿;
- (3)视觉 - 语言 - 动作(VLA)系统(如 HandsOnVLM、RT-2、PaLM-E):推理能力强(能理解文本意图),但直接用视觉 - 语言模型(VLM)生成连续 3D 运动时,存在两大问题:
- 运动不平滑:VLM 输出离散特征,难以生成高频、连续的运动序列(如手部操作的细腻动作);
- 接口低效:VLM 与运动模块的衔接依赖 "隐式特征" 或 "长推理链",导致泛化差、推理慢,无法适配细粒度动作生成。
4. 论文动机:填补 "数据缺口" 与 "模型缺口"
针对上述瓶颈,论文提出 "EgoMAN 项目":
- 数据层面:构建 EgoMAN 数据集,补充 "大规模 + 交互阶段标注 + 结构化 QA 监督" 的第一视角手部轨迹数据;
- 模型层面:设计 "推理 - 运动" 模块化框架,通过 "轨迹令牌接口" 打通 VLM 推理与运动生成,实现 "语义意图→关键阶段→平滑轨迹" 的端到端映射。
二、相关工作:三大方向的研究现状与不足
论文的相关工作围绕 "手部轨迹预测""人类交互视频学习""VLA 模型" 展开,既肯定了现有研究的基础,也明确了自身的创新点:
1. 手部轨迹预测(Hand Trajectory Prediction)
这是论文的核心任务领域,现有研究可分为两类:
- (1)目标中心(Object-Centric)+ 可用性驱动方法:代表工作:VRB、HAMSTER、VidBot;核心思路:先检测场景中的物体和 "可用操作区域"(如杯子的把手),再基于这些区域预测手部轨迹;不足:依赖检测精度,误差传播严重;计算效率低(检测 + 可用性估计耗时);
- (2)端到端运动预测方法:代表工作:USST(状态空间 Transformer)、MMTwin(Mamba + 双扩散)、Madiff(运动感知 Mamba 扩散)、HandsOnVLM(VLM+CVAE);核心思路:直接从视频 + 历史运动中预测未来轨迹,部分融入语言意图;不足:
- 短时预测局限:多聚焦 1-2 秒短时轨迹,长时预测易漂移;
- 语义弱:即使融入语言,也只是 "浅度结合"(如用文本嵌入作为条件),无法深度对齐意图与轨迹;
- 运动质量:扩散模型生成的轨迹易卡顿,状态空间模型泛化性差;
- 论文创新点:首次将 "交互阶段标注" 和 "结构化 QA 推理" 融入轨迹预测,通过 "轨迹令牌" 实现语义与运动的强对齐,且用流匹配(Flow Matching)替代传统扩散 / 状态空间模型,保证长时轨迹的平滑性。
2. 从人类视频学习交互(Learning Interactions from Human Videos)
这类工作为手部轨迹预测提供数据与方法灵感,核心是 "从人类演示中学习操作模式":
- 受控演示数据集(如 HOT3D 早期、H2O):优势:3D 标注精准,交互流程清晰;不足:场景单一、任务有限(如仅包含 "抓取""放置"),泛化到真实世界差;
- 机器人模仿学习数据集(如 EgoMimic、Track2Act):优势:结构化演示(如分步骤操作),适配机器人落地;不足:场景狭窄、脚本化(如仅针对特定机器人任务),缺乏日常交互的多样性;
- 大规模第一视角视频数据集(如 EgoExo4D、Nymeria):优势:场景丰富(日常活动、专业技能)、数据量大;不足:轨迹噪声大、无交互阶段划分、语义标注薄弱(仅简单文本描述,无 QA 推理);
- 论文创新点:整合三大数据集(EgoExo4D+Nymeria+HOT3D-Aria),通过 LLM(GPT-4.1)标注 "交互阶段" 和 "语义 - 空间 - 运动 QA",将 "原始视频数据" 升级为 "推理级监督数据",解决了现有数据集 "监督弱" 的问题。
3. 视觉 - 语言模型在具身 AI 中的应用(Vision-Language Models for Embodied AI)
这类工作是论文 "推理模块" 的技术基础,核心是 "用 VLM 打通感知 - 推理 - 动作":
- 基础 VLM(如 Qwen2.5-VL、InternVL、LLaVA):优势:强视觉理解和语言推理能力(如回答 "杯子在哪里""下一步该做什么");不足:无动作生成能力,仅能输出文本或离散特征;
- VLA 系统(如 RT-2、PaLM-E、OpenVLA、π0):优势:将 VLM 与动作模块结合,支持机器人操作(如 "拿起红色方块");不足:
- 动作生成粗糙:多输出低维动作指令(如机器人关节角度),无法生成细粒度的 3D 手部轨迹;
- 接口低效:VLM 与运动模块的衔接依赖 "隐式特征路由"(如直接将 VLM 输出喂给运动解码器)或 "长推理链"(如分多步生成动作描述),导致泛化差、推理慢;
- 改进型 VLA(如 HandsOnVLM、MolmoAct):优势:尝试生成手部相关动作(如 HandsOnVLM 预测 2D 手部轨迹,再通过 CVAE 升级为 6DoF);不足:
- 运动质量差:CVAE 解码易产生噪声,轨迹不平滑;
- 语义 - 运动对齐弱:仅通过 "动作短语嵌入" 衔接,未考虑 "交互阶段" 的结构化约束;
- 论文创新点:设计 "4 个轨迹令牌(<ACT>+<START>+<CONTACT>+<END>)" 作为 VLM 与运动模块的接口,将抽象的 VLM 推理(意图、关键阶段)转化为结构化、可解释的中间表示,既解决了 VLM 与运动模块 "衔接低效" 的问题,又通过 "阶段约束" 保证了轨迹的合理性。
总结:相关工作与论文的核心差异
论文的创新并非孤立,而是针对三大相关方向的 "痛点" 进行突破:
- 数据上:弥补了 "大规模数据" 与 "强推理监督" 的缺口(现有数据要么大但监督弱,要么监督强但规模小);
- 模型上:解决了 "VLM 推理" 与 "运动生成" 的衔接问题(现有 VLA 要么推理强但运动差,要么运动强但推理弱);
- 任务上:实现了 "长时程 + 语义可控 + 平滑" 的 3D 手部轨迹预测(现有方法难以同时满足这三点)。
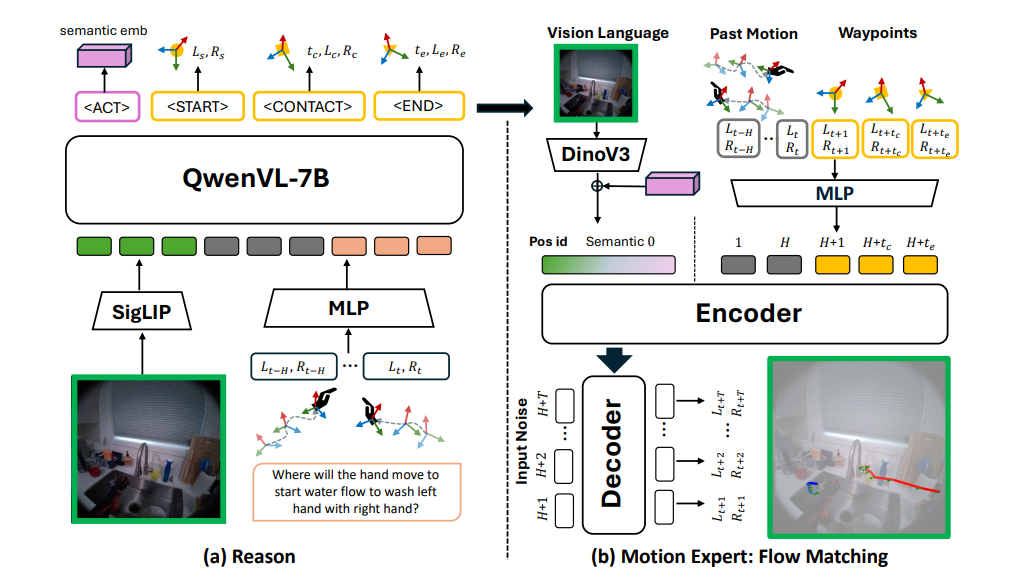
论文的主图怎么解析呢?其实可以分成两个部分:推理阶段与动作生成阶段。
推理阶段,输入obs,任务文本与历史动作,输出动作令牌(用来生成动作)与过程理解令牌(start,contact那些,用来表示当前轨迹运行到了什么状态的令牌)。这些令牌与obs都会输入到右边的动作生成部分中,用来辅助流匹配动作生成。
论文的局限性:
- 局限性:
- 仅建模手腕轨迹,未考虑手指关节的精细运动;
- 交互阶段仅划分 "接近 - 操作",缺乏更细粒度的子阶段(如 "预接触调整""多步操作");
- 数据集存在传感器噪声和标注误差,无人工验证环节。
- 未来方向:
- 扩展到全手姿态(手指关节)的预测;
- 引入更细粒度的交互阶段解析;
- 提升数据集标注质量(如人工验证、更高精度的 3D 扫描);
- 部署到真实机器人系统,验证物理世界中的迁移能力。
总结
EgoMAN 项目的核心突破是 "用结构化令牌打通推理与运动":通过数据集提供 "语义 - 空间 - 运动" 的强关联监督,再通过 4 个轨迹令牌将抽象的视觉 - 语言推理转化为运动生成可直接利用的中间表示,最终实现 "意图明确、轨迹平滑、泛化性强" 的 3D 手部轨迹预测。该方法既解决了传统模型 "语义与运动脱节" 的问题,又克服了 VLA 系统 "运动生成低效" 的缺陷,为 embodied AI 中的人机交互提供了新范式。